
- 💂 个人网站:【 海拥】【萌怪大冒险】【2048】
- 🤟 风趣幽默的前端学习课程:👉28个案例趣学前端
- 💅 想寻找共同学习交流、摸鱼划水的小伙伴,请点击【摸鱼大军】
- 💬 免费且实用的计算机相关知识题库:👉进来逛逛
给大家安利一个免费且实用的前端刷题(面经大全)网站,👉点击跳转到网站。
深度学习是机器学习的一个分支,其中编写了模仿人脑功能的算法。深度学习中最常用的库是 Tensorflow 和 PyTorch。由于有各种可用的深度学习框架,人们可能想知道何时使用 PyTorch。以下是人们可能更喜欢将 Pytorch 用于特定任务的原因。
Pytorch 是一个开源深度学习框架,带有 Python 和 C++ 接口。Pytorch 位于 torch 模块中。在 PyTorch 中,必须处理的数据以张量的形式输入。
安装 PyTorch
如果您的系统中安装了 Anaconda Python 包管理器,那么通过在终端中运行以下命令来安装 PyTorch:
conda install pytorch torchvision cpuonly -c pytorch
如果您想使用 PyTorch 而不将其显式安装到本地计算机中,则可以使用 Google Colab。
PyTorch 张量
Pytorch 用于处理张量。张量是多维数组,例如 n 维 NumPy 数组。但是,张量也可以在 GPU 中使用,但在 NumPy 数组的情况下则不然。PyTorch 加速了张量的科学计算,因为它具有各种内置功能。
向量是一维张量,矩阵是二维张量。在 C、C++ 和 Java 中使用的张量和多维数组之间的一个显着区别是张量在所有维度上应该具有相同的列大小。此外,张量只能包含数字数据类型。
张量的两个基本属性是:
形状:指数组或矩阵的维数
Rank:指张量中存在的维数
代码:
# 导入 torchimport torch
# 创建张量
t1=torch.tensor([1,2,3,4])
t2=torch.tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]])# 打印张量:print("Tensor t1: \n", t1)print("\nTensor t2: \n", t2)# 张量的秩print("\nRank of t1: ",len(t1.shape))print("Rank of t2: ",len(t2.shape))# 张量的形状print("\nRank of t1: ", t1.shape)print("Rank of t2: ", t2.shape)
输出:

在 PyTorch 中创建张量
在 PyTorch 中有多种创建张量的方法。张量可以包含单一数据类型的元素。我们可以使用 python 列表或 NumPy 数组创建张量。Torch 有 10 种用于 GPU 和 CPU 的张量变体。以下是定义张量的不同方法。
- torch.Tensor() :它复制数据并创建其张量。它是 torch.FloatTensor 的别名。
- torch.tensor() :它还复制数据以创建张量;但是,它会自动推断数据类型。
- torch.as_tensor() :在这种情况下,数据是共享的,在创建数据时不会被复制,并接受任何类型的数组来创建张量。
- torch.from_numpy() :它类似于 tensor.as_tensor() 但它只接受 numpy 数组。
代码:
# 导入 torch 模块import torch
import numpy as np
# 存储为张量的值列表
data1 =[1,2,3,4,5,6]
data2 = np.array([1.5,3.4,6.8,9.3,7.0,2.8])# 创建张量和打印
t1 = torch.tensor(data1)
t2 = torch.Tensor(data1)
t3 = torch.as_tensor(data2)
t4 = torch.from_numpy(data2)print("Tensor: ",t1,"Data type: ", t1.dtype,"\n")print("Tensor: ",t2,"Data type: ", t2.dtype,"\n")print("Tensor: ",t3,"Data type: ", t3.dtype,"\n")print("Tensor: ",t4,"Data type: ", t4.dtype,"\n")
输出:

在 Pytorch 中重构张量
我们可以在 PyTorch 中根据需要修改张量的形状和大小。我们还可以创建一个 nd 张量的转置。以下是根据需要更改张量结构的三种常用方法:
.reshape(a, b) :返回一个大小为 a,b 的新张量
.resize(a, b) :返回大小为 a,b 的相同张量
.transpose(a, b) :返回在 a 和 b 维中转置的张量
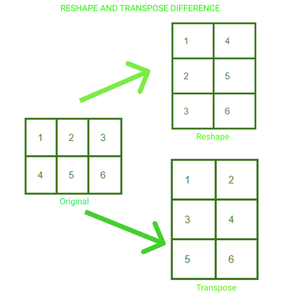
一个 23 矩阵已被重新整形并转置为 32。在这两种情况下,我们都可以可视化张量中元素排列的变化。
代码:
# 导入 torch 模块import torch
# 定义张量
t = torch.tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]])# 重塑张量print("Reshaping")print(t.reshape(6,2))# 调整张量的大小print("\nResizing")print(t.resize(2,6))# 转置张量print("\nTransposing")print(t.transpose(1,0))

PyTorch 中张量的数学运算
我们可以使用 Pytorch 对张量执行各种数学运算。执行数学运算的代码与 NumPy 数组的代码相同。下面是在张量中执行四种基本操作的代码。
# 导入 torch 模块import torch
# 定义两个张量
t1 = torch.tensor([1,2,3,4])
t2 = torch.tensor([5,6,7,8])# 添加两个张量print("tensor2 + tensor1")print(torch.add(t2, t1))# 减去两个张量print("\ntensor2 - tensor1")print(torch.sub(t2, t1))# 将两个张量相乘print("\ntensor2 * tensor1")print(torch.mul(t2, t1))# 将两个张量相除print("\ntensor2 / tensor1")print(torch.div(t2, t1))
输出:

Pytorch 模块
PyTorch 库模块对于创建和训练神经网络至关重要。三个主要的库模块是 Autograd、Optim 和 nn。
- Autograd 模块: autograd 提供了轻松计算梯度的功能,无需显式手动实现所有层的前向和后向传递。
为了训练任何神经网络,我们执行反向传播来计算梯度。通过调用 .backward() 函数,我们可以计算从根到叶的每个梯度。
代码:
# 导入 torchimport torch
# 创建张量
t1=torch.tensor(1.0, requires_grad =True)
t2=torch.tensor(2.0, requires_grad =True)# 创建变量和渐变
z=100* t1 * t2
z.backward()# 打印渐变print("dz/dt1 : ", t1.grad.data)print("dz/dt2 : ", t2.grad.data)
输出:

- Optim Module: PyTorch Optium Module,有助于实现各种优化算法。该软件包包含最常用的算法,如 Adam、SGD 和 RMS-Prop。要使用 torch.optim,我们首先需要构造一个 Optimizer 对象,该对象将保留参数并相应地更新它。首先,我们通过提供我们想要使用的优化器算法来定义优化器。我们在反向传播之前将梯度设置为零。然后为了更新参数,调用 optimizer.step()。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) #定义优化器
optimizer.zero_grad() #将梯度设置为零
optimizer.step() #参数更新
- nn 模块:这个包有助于构建神经网络。它用于构建图层。
为了创建一个单层模型,我们可以简单地使用 nn.Sequential() 来定义它。
model = nn.Sequential(nn.Linear(in, out), nn.Sigmoid(), nn.Linear(_in,
_out), nn.Sigmoid())
对于不在单个序列中的模型的实现,我们通过继承 nn.Module 类来定义模型。
classModel(nn.Module):def__init__(self):super(Model, self).__init__()
self.linear = torch.nn.Linear(1,1)defforward(self, x):
y_pred = self.linear(x)return y_pred
PyTorch 数据集和数据加载器
torch.utils.data.Dataset 类包含所有自定义数据集。我们需要实现两个方法,
__len__()
和
__get_item__()
,来创建我们自己的数据集类。
PyTorch 数据加载器具有一个惊人的特性,即与自动批处理并行加载数据集。因此,它减少了顺序加载数据集的时间,从而提高了速度。
语法: DataLoader(dataset, shuffle=True, sampler=None,
batch_sampler=None, batch_size=32)
PyTorch DataLoader 支持两种类型的数据集:
地图样式数据集:数据项映射到索引。在这些数据集中,
__get_item__()
方法用于检索每个项目的索引。
可迭代式数据集:在这些数据集中实现了
__iter__()
协议。数据样本按顺序检索。
使用 PyTorch 构建神经网络
我们将在逐步实现中看到这一点:
1.数据集准备:由于 PyTorch 中的一切都以张量的形式表示,所以我们应该首先使用张量。
2.构建模型:为了构建中性网络,我们首先定义输入层、隐藏层和输出层的数量。我们还需要定义初始权重。权重矩阵的值是使用torch.randn()随机选择的。Torch.randn() 返回一个由来自标准正态分布的随机数组成的张量。
3.前向传播:将数据馈送到神经网络,并在权重和输入之间执行矩阵乘法。这可以使用手电筒轻松完成。
4.损失计算: PyTorch.nn 函数有多个损失函数。损失函数用于衡量预测值与目标值之间的误差。
5.反向传播:用于优化权重。更改权重以使损失最小化。
现在让我们从头开始构建一个神经网络:
# 导入 torchimport torch
# 训练 input(X) 和 output(y)
X = torch.Tensor([[1],[2],[3],[4],[5],[6]])
y = torch.Tensor([[5],[10],[15],[20],[25],[30]])classModel(torch.nn.Module):# defining layerdef__init__(self):super(Model, self).__init__()
self.linear = torch.nn.Linear(1,1)# 实施前向传递defforward(self, x):
y_pred = self.linear(x)return y_pred
model = torch.nn.Linear(1,1)# 定义损失函数和优化器
loss_fn = torch.nn.L1Loss()
optimizer = torch.optim.Adam(model.parameters(), lr =0.01)for epoch inrange(1000):# 使用初始权重预测 y
y_pred = model(X.requires_grad_())# 损失计算
loss = loss_fn(y_pred, y)# 计算梯度
loss.backward()# 更新权重
optimizer.step()
optimizer.zero_grad()# 测试新数据
X = torch.Tensor([[7],[8]])
predicted = model(X)print(predicted)
输出:
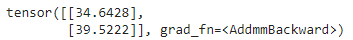
🎁参与评论送书
本次送书 8 本,以后每周新文评论区至少抽三位朋友送书,大家可持续关注我:海拥

内容简介
本书主要介绍人工智能研究领域中神经网络的PyTorch架构,对其在多个领域的应用进行系统性的归纳和梳理。书中的案例有风景图分类、人像前景背景分割、低光照图像增法、动漫头像生成、画风迁移、风格转换等,对每项视觉任务的研究背景、应用价值、算法原理、代码实现和移动端部署流程进行了详细描述,并提供相应的源码,适合读者从0到1构建移动端智能应用。
本书适合对人工智能实际应用感兴趣的本科生、研究生、深度学习算法工程师、计算机视觉从业人员和人工智能爱好者阅读,书中介绍的各项视觉任务均含有相应的安卓平台部署案例,不仅对学生参加比赛、课程设计具有参考意义,对相关从业人员的软件架构和研发也具有启发价值。
觉得自己抽不到,想自己买的也可以参考此链接:https://item.jd.com/13176891.html
【抽奖方式】关注博主、点赞收藏文章后,评论区留言:人生苦短,我爱AI!!!博主会用爬虫代码随机抽取 8 人送书!
【开奖时间】:截止到周日晚8点
本期中奖名单:
📣尾注:
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。在这里,我们只讨论了人工智能的基本知识,想要获取更多人工智能相关的知识,或者就是想每周参与抽奖白嫖一本书,你可以私信我加入CSDN官方人工智能交流群
💌 欢迎大家在评论区提出意见和建议!💌
版权归原作者 海拥✘ 所有, 如有侵权,请联系我们删除。