
本页介绍了 Flink 的数据源 API 及其背后的概念和架构。如果你对 Flink 中的数据源工作原理感兴趣,或者你想实现一个新的数据源,请阅读这篇文章。
如果您正在寻找预定义的源连接器,请查看连接器文档。
数据源概念#
核心部件
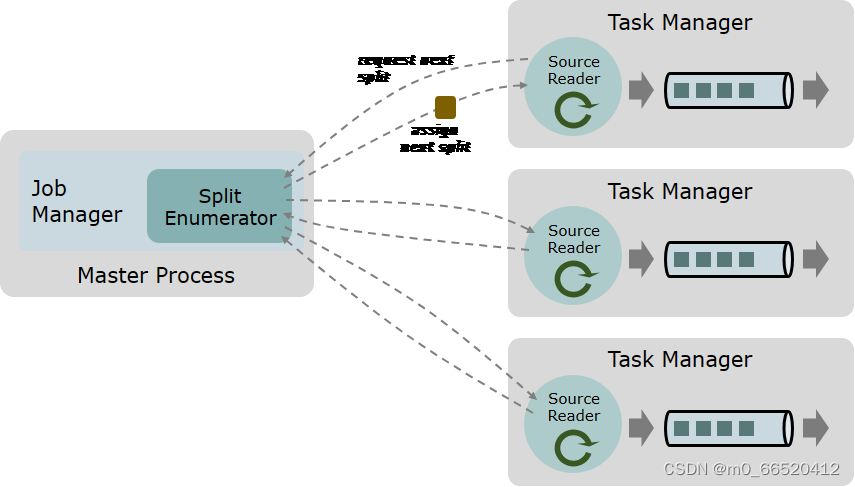
数据源有三个核心组件:Splits、SplitEnumerator 和 SourceReader。
- 拆分是源使用的数据的一部分,如文件或日志分区。拆分是源分配工作并并行化数据读取的粒度。
- SourceReader 请求 Split 并对其进行处理,例如,通过读取 Split 表示的文件或日志分区。SourceReader 在任务管理器上并行运行,并生成事件/记录的并行流。
SourceOperators - SplitEnumerator 生成 Splits 并将其分配给 SourceReaders。它在作业管理器上作为单个实例运行,并负责维护待处理拆分的积压工作,并以平衡的方式将它们分配给读取器。
Source 类是将上述三个组件绑定在一起的 API 入口点。
跨流式处理和批处理统一
数据源 API 以统一的方式支持无界流式处理源和有界批处理源。
这两种情况之间的差异很小:在有界/批处理情况下,枚举器会生成一组固定的拆分,并且每个拆分必然是有限的。在无界流式处理情况下,两者之一不成立(拆分不是有限的,或者枚举器不断生成新的拆分)。
例子#
下面是一些简化的概念示例,用于说明数据源组件在流式处理和批处理情况下的交互方式。
请注意,这并不能准确描述 Kafka 和 File 源实现的工作原理;部分被简化,用于说明目的。
有界文件源
源具有要读取的目录的 URI/路径,以及定义如何分析文件的 Format。
- 拆分是一个文件或文件的一个区域(如果数据格式支持拆分文件)。
- SplitEnumerator 列出给定目录路径下的所有文件。它将 Splits 分配给下一个请求 Split 的读取器。分配所有 Splits 后,它将使用 NoMoreSplits 响应请求。
- SourceReader 请求 Split 并读取分配的 Split(文件或文件区域),并使用给定的 Format 对其进行解析。如果它没有收到另一个 Split,而是收到 NoMoreSplits 消息,则它完成。
无界流式处理文件源
此源的工作方式与上述相同,只是 SplitEnumerator 从不响应 NoMoreSplits,并定期列出给定 URI/Path 下的内容以检查新文件。一旦找到新文件,它就会为它们生成新的拆分,并可以将它们分配给可用的 SourceReaders。
无界流式处理 Kafka 源
源具有 Kafka 主题(或主题列表或主题正则表达式)和用于解析记录的反序列化程序。
- 拆分是 Kafka 主题分区。
- SplitEnumerator 连接到代理以列出订阅主题中涉及的所有主题分区。枚举器可以选择重复此操作以发现新添加的主题/分区。
- SourceReader 使用 KafkaConsumer 读取分配的拆分(主题分区),并使用提供的反序列化程序反序列化记录。拆分(主题分区)没有结束,因此读取器永远不会到达数据的末尾。
有界 Kafka 源
与上述相同,只是每个 Split(主题分区)都有一个定义的结束偏移量。一旦 SourceReader 达到 Split 的结束偏移量,它就会完成该 Split。完成所有分配的拆分后,SourceReader 将完成。
版权归原作者 m0_66520412 所有, 如有侵权,请联系我们删除。