
一.Flink****中的状态
1.1 概述
在Flink中,算子任务可以分为有状态和无状态两种状态。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。例如Map、Filter、FlatMap都是属于无状态算子。
而有状态的算子任务,就是除了当前数据外,还需要一些其他的数据来得到计算结果。这里的其他数据就是所谓的“状态”。例如聚合函数、窗口函数都属于有状态算子。
**1.2 **状态的分类
1.2.1 托管状态(Managed State)和原始状态(Raw State)
Flink的状态有两种,托管状态(Managed State)和原始状态(Raw State)。托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,我们只要调接口就可以;而原始状态则是自定义的,所有的状态具体管理则需要自行实现。
一般使用托管状态即可。后面的所有内容也仅是基于托管状态的。
1.2.2 算子状态(Operator State)和按键分区状态(Keyed State)
在Flink中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
而很多有状态的操作(比如聚合、窗口)都是要先做keyBy进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前key有效,所以状态也应该按照key彼此隔离。在这种情况下,状态的访问方式又会有所不同。
基于这样的想法,又可以将托管状态分为两类:算子状态和按键分区状态。经过KeyBy操作后的状态则被称为"按键分区状态(Keyed State)",否则就是“算子状态(Operator State)”。
算子状态
算子状态的状态作用范围为当前算子任务实例-即每个task(分区)间状态不共享。
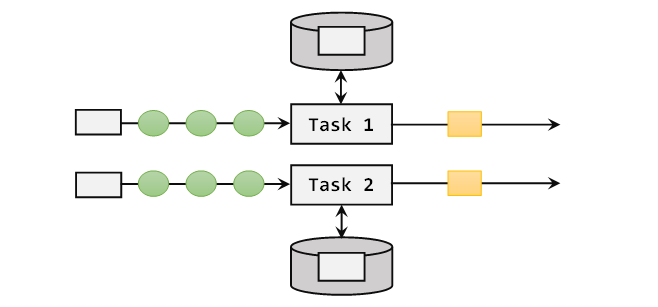
算子状态可以用在所有算子上,使用时与本地变量没什么区别,在使用时需实现checkpoint接口。假如使用新的Source架构,则需要继承SourceReaderBase抽象类。
按键分区状态
按键分区状态只有在KeyBy后才能使用,因为状态是根据输入流中定义的键(Key)来维护和访问的。每个Key分区间状态不共享。
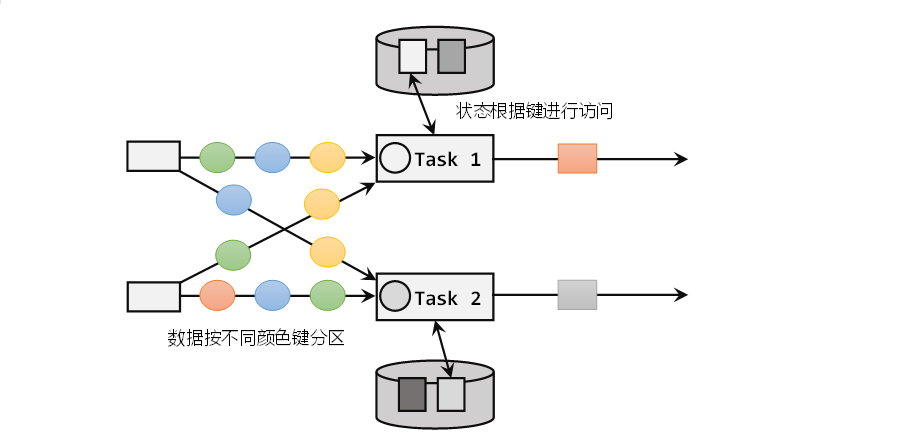
二.按键分区状态(Keyed State)
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以key为作用范围进行隔离。
2.1 值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。ValueState<T>本身是一个接口,源码如下:
@PublicEvolving
public interface ValueState<T> extends State {
T value() throws IOException;
void update(T var1) throws IOException;
}
这里的T是泛型,表示值状态数据类型。
对值的操作主要有以下:
// 获取当前状态值
T value()
// 更新/覆盖状态值
update(T value)
在具体使用时,为了让运行时上下文清楚到底是哪个状态,我们还需要创建一个“状态描述器”(StateDescriptor)来提供状态的基本信息。例如源码中,ValueState的状态描述器构造方法如下:
public ValueStateDescriptor(String name, Class<T> typeClass) {
super(name, typeClass, null);
}
这里需要传入状态的名称和类型——这跟我们声明一个变量时做的事情完全一样。
案例:检测每种传感器的水位值,如果连续的两个水位值差值超过10,就输出报警。
public class KeyedValueStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
.withTimestampAssigner((SerializableTimestampAssigner<WaterSensor>) (waterSensor, l) -> waterSensor.getTs() * 1000L)
);
// 对传感器做KeyBy
SingleOutputStreamOperator<String> process = sensorDS.keyBy(r -> r.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
// 定义状态,用于每组当前的水位线
ValueState<Integer> lastVcState;
// 必须在open方法中,初始化状态
@Override
public void open(Configuration parameters) throws Exception {
// 初始化值状态,需传入值状态描述器(唯一的名称,值的类型)
lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<>("lastVc", Types.INT));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 1.取出上一条水位线
int lastVc = lastVcState.value() == null ? value.getVc() : lastVcState.value();
// 2.判断是否超过10
if (Math.abs(value.getVc() - lastVc) > 10) {
out.collect("传感器:" + value.getId() + ",上一次水位线:" + lastVc + ",当前水位线:" + value.getVc() + ",触发报警(相差超过10)!!!");
}
// 更新当前状态
lastVcState.update(value.getVc());
}
});
process.print();
env.execute();
}
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,13
s1,5,9
s1,6,22
s2,9,10
s2,10,23
输出:
传感器:s1,上一次水位线:1,当前水位线:13,触发报警(相差超过10)!!!
传感器:s1,上一次水位线:9,当前水位线:22,触发报警(相差超过10)!!!
传感器:s2,上一次水位线:10,当前水位线:23,触发报警(相差超过10)!!!
如果不使用状态存储,则需要定义HashMap存储每个Key的水位线,没有状态高效。
2.2 列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在ListState<T>接口中同样有一个类型参数T,表示列表中数据的类型。ListState也提供了一系列的方法来操作状态,使用方式与一般的List非常相似。
对 List 状态的操作主要有以下:
// 获取当前的列表状态,返回的是一个可迭代类型Iterable<T>
Iterable<T> get()
// 传入一个列表values,直接对状态进行覆盖
update(List<T> values)
// 向列表中添加多个元素,以列表values形式传入
addAll(List<T> values)
类似地,ListState的状态描述器就叫作ListStateDescriptor,用法跟ValueStateDescriptor完全一致。
案例:针对每种传感器输出最高的3个水位值。
public class KeyedListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
.withTimestampAssigner((SerializableTimestampAssigner<WaterSensor>) (waterSensor, l) -> waterSensor.getTs() * 1000L)
);
// 对传感器做KeyBy
SingleOutputStreamOperator<String> process = sensorDS.keyBy(r -> r.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
// 定义 ListState
ListState<Integer> vcListState;
// 初始化 ListState
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcListState = getRuntimeContext().getListState(new ListStateDescriptor<>("vcListState",Types.INT));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 将当前水位线存入 ListState
vcListState.add(value.getVc());
// 将 ListState (迭代器)中的值取出,拷贝到 List 中,
List<Integer> vcList = new ArrayList<Integer>();
for (Integer vc : vcListState.get()) {
vcList.add(vc);
}
// 排序
vcList.sort(((o1, o2) -> o2 - o1));
// 取前三
if (vcList.size() > 3) {
vcList.remove(3);
}
out.collect("当前传感器:"+value.getId()+",最大的3个水位线为:"+vcList.toString());
// 更新 ListState
vcListState.update(vcList);
}
});
process.print();
env.execute();
}
}
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,4,4
s1,5,3
s1,6,6
s2,5,6
s3,6,5
s2,4,7
输出:
当前传感器:s1,最大的3个水位线为:[1]
当前传感器:s1,最大的3个水位线为:[4, 1]
当前传感器:s1,最大的3个水位线为:[4, 3, 1]
当前传感器:s1,最大的3个水位线为:[6, 4, 3]
当前传感器:s2,最大的3个水位线为:[6]
当前传感器:s3,最大的3个水位线为:[5]
当前传感器:s2,最大的3个水位线为:[7, 6]
2.3 Map状态(MapState****)
把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组key-value映射的列表。使用与Map非常类似。
对Map状态的操作主要有以下:
// 根据key查询mapState中的value
UV get(UK key)
// 向mapState中put一个键值对
put(UK key, UV value)
// 向mapState中put多个键值对
putAll(Map<UK, UV> map)
// 将指定key对应的键值对删除
remove(UK key)
// 判断是否存在指定的key
boolean contains(UK key)
// 获取映射状态中所有的键值对
Iterable<Map.Entry<UK, UV>> entries()
// 获取映射状态中所有的键(key),返回一个可迭代Iterable类型
Iterable<UK> keys()
// 获取映射状态中所有的值(value),返回一个可迭代Iterable类型
Iterable<UV> values()
// 判断映射是否为空
boolean isEmpty()
案例:统计每种传感器每种水位值出现的次数。
public class KeyedMapStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
.withTimestampAssigner((SerializableTimestampAssigner<WaterSensor>) (waterSensor, l) -> waterSensor.getTs() * 1000L)
);
// 对传感器做KeyBy
SingleOutputStreamOperator<String> process = sensorDS.keyBy(r -> r.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
// 定义Map状态,键为vc(Integer),值为count(Integer)
MapState<Integer,Integer> vcCountMapState;
// 初始化Map状态
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcCountMapState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer,Integer>("vcCountMapState",Types.INT,Types.INT));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 判断map状态中是否存在该vc,存在则count+1,否则put进map状态
Integer vc = value.getVc();
if(vcCountMapState.contains(value.getVc())){
Integer vcCount = vcCountMapState.get(vc);
vcCountMapState.put(vc , ++vcCount);
}else{
vcCountMapState.put(vc , 1);
}
StringBuilder outStr = new StringBuilder();
outStr.append("传感器:"+value.getId()+",下的所有水位线及出现次数:\n");
// 遍历该key下的所有键值
for (Map.Entry<Integer, Integer> entry : vcCountMapState.entries()) {
outStr.append("vc="+entry.getKey()+",count="+entry.getValue()+"\n");
}
outStr.append("------------------------------------------------------");
out.collect(outStr.toString());
}
});
process.print();
env.execute();
}
}
输入:
[root@VM-55-27-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,1
s2,1,1
s1,4,1
输出:
传感器:s1,下的所有水位线及出现次数:
vc=1,count=1
------------------------------------------------------
传感器:s1,下的所有水位线及出现次数:
vc=1,count=1
vc=2,count=1
------------------------------------------------------
传感器:s1,下的所有水位线及出现次数:
vc=1,count=2
vc=2,count=1
------------------------------------------------------
传感器:s2,下的所有水位线及出现次数:
vc=1,count=1
------------------------------------------------------
传感器:s1,下的所有水位线及出现次数:
vc=1,count=3
vc=2,count=1
------------------------------------------------------
2.4 归约状态(ReducingState)
类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。
与之前不同的是,在归约状态描述器中需要传入ReduceFunction实现具体的归约逻辑。
对归约状态的操作主要有以下:
// 把新数据和之前的状态进行归约,并用得到的结果更新状态。
add(IN)
// 获取归约状态中的值
OUT get()
案例:计算每种传感器的水位和。
public class KeyedReducingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
.withTimestampAssigner((SerializableTimestampAssigner<WaterSensor>) (waterSensor, l) -> waterSensor.getTs() * 1000L)
);
// 对传感器做KeyBy
SingleOutputStreamOperator<String> process = sensorDS.keyBy(r -> r.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
// 定义Reducing状态
ReducingState<Integer> vcSumReducingState;
// 初始化Reducing状态(需要传入ReduceFunction实现具体的归约逻辑)
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcSumReducingState = getRuntimeContext().getReducingState(
new ReducingStateDescriptor<>(
"vcSumReducingState",
// 归约逻辑 (两数相加)
(v1, v2) -> v1+v2,
Types.INT
)
);
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
vcSumReducingState.add(value.getVc());
out.collect("传感器:"+value.getId()+",水位线总值为:"+vcSumReducingState.get());
}
});
process.print();
env.execute();
}
}
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,3,3
s2,4,4
s2,5,5
s1,6,6
s3,7,7
输出:
传感器:s1,水位线总值为:1
传感器:s1,水位线总值为:3
传感器:s1,水位线总值为:6
传感器:s2,水位线总值为:4
传感器:s2,水位线总值为:9
传感器:s1,水位线总值为:12
传感器:s3,水位线总值为:7
2.5 聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。并且允许输入、输出、中间累加器类型可以不一致。
对聚合状态的操作主要有以下:
// 向聚合状态中添加元素
add(IN)
// 从聚合状态中获取结果
OUT get()
案例:计算每种传感器的平均水位。
public class KeyedAggregatingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
.withTimestampAssigner((SerializableTimestampAssigner<WaterSensor>) (waterSensor, l) -> waterSensor.getTs() * 1000L)
);
// 对传感器做KeyBy
SingleOutputStreamOperator<String> process = sensorDS.keyBy(r -> r.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
// 定义聚合状态
AggregatingState<Integer,Double> vcAvgAggState;
// 初始化聚合状态
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcAvgAggState =
getRuntimeContext()
.getAggregatingState(new AggregatingStateDescriptor<>(
"vcAvgAggState",
// 聚合逻辑
new AggregateFunction<Integer, Tuple2<Integer, Integer>, Double>() {
// 初始化累加器
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
// 累加逻辑 (水位相加,次数+1)
@Override
public Tuple2<Integer, Integer> add(Integer integer, Tuple2<Integer, Integer> accumulator) {
return Tuple2.of(accumulator.f0 + integer , accumulator.f1 + 1);
}
// 结果 水位 / 次数
@Override
public Double getResult(Tuple2<Integer, Integer> accumulator) {
return (accumulator.f0 * 1D) / accumulator.f1;
}
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> integerIntegerTuple2, Tuple2<Integer, Integer> acc1) {
return null;
}
},
Types.TUPLE(Types.INT, Types.INT)
));
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
vcAvgAggState.add(value.getVc());
out.collect("传感器:"+value.getId()+",平均水位为:"+vcAvgAggState.get());
}
});
process.print();
env.execute();
}
}
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
s1,4,4
s2,5,5
s2,6,6
s1,7,7
输出:
传感器:s1,平均水位为:1.0
传感器:s1,平均水位为:1.5
传感器:s1,平均水位为:2.3333333333333335
传感器:s2,平均水位为:5.0
传感器:s2,平均水位为:5.5
传感器:s1,平均水位为:3.5
2.6 状态生存时间(TTL)
随着Flink程序的运行,状态所消耗的存储空间也会随之增长,如果不限制则可能会导致存储空间耗尽。可以使用 .clear() 方法清除状态,但是不够灵活。
可以在状态描述器中通过**.enableTimeToLive()方法启动TTL功能,并创建一个StateTtlConfig**配置对象。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("my state", String.class);
// 开启TTL
stateDescriptor.enableTimeToLive(ttlConfig);
主要的配置项:
.newBuilder() :状态TTL配置的构造器方法,需传入Time参数,设定状态过期时间
.setUpdateType():设置更新类型,什么时机进行更新失效时间(重置失效时间)OnCreateAndWrite :创建状态和更改状态(写操作)时更新失效时间 OnReadAndWrite:无论读写操作都会更新失效时间.setStateVisibility():设置状态的可见性
NeverReturnExpired:表示从不返回过期值 ReturnExpireDefNotCleanedUp:如果过期状态还存在,则返回
示例代码:
public class StateTTLDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl())
.assignTimestampsAndWatermarks(WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 设置最大等待时间为3s
.withTimestampAssigner((SerializableTimestampAssigner<WaterSensor>) (waterSensor, l) -> waterSensor.getTs() * 1000L)
);
SingleOutputStreamOperator<String> process = sensorDS.keyBy(r -> r.getId())
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
ValueState<Integer> lastVcState;
@Override
public void open(Configuration parameters) throws Exception {
// 创建 StateTtlConfig
StateTtlConfig stateTtlConfig = StateTtlConfig
.newBuilder(Time.seconds(10)) // 状态存活时间为10s
.updateTtlOnCreateAndWrite() // 创建/更新状态时重置存活时间
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 不返回过期状态
.build();
// 启用 TTL
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("lastVc", Types.INT);
stateDescriptor.enableTimeToLive(stateTtlConfig);
lastVcState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
out.collect("传感器:"+value.getId()+",当前状态值:"+lastVcState.value());
lastVcState.update(value.getVc());
}
});
process.print();
env.execute();
}
}
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
...间隔10s
s1,2,2
s1,3,3
s1,4,4
s1,5,5
输出:
传感器:s1,当前状态值:null
传感器:s1,当前状态值:1
传感器:s1,当前状态值:null
传感器:s1,当前状态值:3
传感器:s1,当前状态值:4
三.算子状态(Operator State)
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。(每个算子子任务共享一个算子状态,子任务间不共享)
算子状态的实际应用场景不如Keyed State多,一般用在Source或Sink等与外部系统连接的算子上,一般使用不多。
当算子并行度发生变化时,算子状态也支持在并行的算子子任务实例间做重新分配,根据状态的类型不同,重组分配的方案也会不同。
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState和BroadcastState。
3.1 列表状态(ListState)
与Keyed State中的ListState一样,将状态表示为一组数据的列表。
与Keyed State中的列表状态的区别是,在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的状态列表将会被全部收集收集起来,再通过轮询的方式重新依次分配给新的所有并行任务。
算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
案例:在map算子中计算数据的个数。
/**
* 在map算子中计算数据的个数
*/
public class OperatorListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 全局算子并行度为2
env.setParallelism(2);
env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyCountMapFunction())
.print();
env.execute();
}
// 实现 CheckPointedFunction 接口
public static class MyCountMapFunction implements MapFunction<String,Long>, CheckpointedFunction {
// 定义本地变量
private Long count = 0L;
// 定义算子状态
private ListState<Long> state;
// Map算子逻辑
@Override
public Long map(String s) throws Exception {
return ++count;
}
/**
* 状态快照:用于将本地变量持久化至算子状态中,,开启checkpoint时才会调用
* @param context the context for drawing a snapshot of the operator
* @throws Exception
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
System.out.println("调用了snapshotState方法...");
// 清空状态
state.clear();
// 将本地变量存入状态中
state.add(count);
}
/**、
* 初始化本地变量:程序启动和恢复时,从状态中把数据添加到本地变量,每个子任务调用一次
* @param context the context for initializing the operator
* @throws Exception
*/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("调用了initializeState方法...");
// 从上下文中获取算子状态
state = context
.getOperatorStateStore()
.getListState(new ListStateDescriptor<Long>("list-state", Types.LONG));
// 从算子状态中将数据拷贝至本地变量
if (context.isRestored()) { // 判断是否初始化成功
for (Long v : state.get()) {
count += v;
}
}
}
}
}
输入:
[root@VM-55-24-centos ~]# nc -lk 1234
a
b
c
d
e
f
g
输出:
调用了initializeState方法...
调用了initializeState方法...
1> 1
2> 1
1> 2
2> 2
1> 3
2> 3
1> 4
*3.2 联合列表状态(UnionListState*)
与ListState类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
在并行度进行缩放调整时,联合列表与普通列表不同,联合列表会将所有并行子任务的列表状态收集起来,并直接向所有并行子任务广播完整的列表。如果列表中状态项太多则不推荐使用联合里欸包状态。
使用上也与ListState类似,只需要在实现CheckpointedFunction类的initializeState方法时,通过上下文获取算子状态使用 **.getUnionListState() **即可,其他与ListState无异。
state = context
.getOperatorStateStore()
.getUnionListState(new ListStateDescriptor<>("list-state", Types.LONG));
3.3 广播状态(BroadcastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
在并行度进行缩放操作时,由于是全局状态,也不会造成影响。
案例:水位超过指定的阈值发送告警,阈值可以动态修改。
/**
* 水位超过指定的阈值发送告警,阈值可以动态修改。
*/
public class OperatoBroadcastStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 数据流
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("xxx.xxx.xxx.xxx", 1234)
.map(new MyMapFunctionImpl());
// 配置流:用于广播配置(阈值配置将发往这条流)
DataStreamSource<String> configDS = env.socketTextStream("xxx.xxx.xxx.xxx", 4321);
// 将配置流进行广播
MapStateDescriptor<String, Integer> broadcastMapState = new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT);
BroadcastStream<String> configBS = configDS.broadcast(broadcastMapState);
// 将数据流和广播后的配置流使用connect进行连接
BroadcastConnectedStream<WaterSensor, String> sensorBCS = sensorDS.connect(configBS);
// 调用process
sensorBCS
.process(new BroadcastProcessFunction<WaterSensor, String, String>() {
/**
* 数据流的处理逻辑,可以通过上下文读取广播状态(只读)
* @param value The stream element.
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void processElement(WaterSensor value, BroadcastProcessFunction<WaterSensor, String, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
// 通过上下文获取广播状态的值(阈值)
ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
// 未从广播状态中读到值则设置默认值
Integer threshold = broadcastState.get("threshold") != null ? broadcastState.get("threshold"): 0;
if(value.getVc() > threshold){
out.collect("传感器:"+ value.getId()+",当前水位为:"+ value.getVc()+",触发了阈值:"+threshold);
}
}
/**
* 配置广播流的处理逻辑,可以通过上下文可以往广播状态写入值
* @param value The stream element.
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<WaterSensor, String, String>.Context ctx, Collector<String> out) throws Exception {
// 读取流中的阈值,写入广播状态中
BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
broadcastState.put("threshold" , Integer.valueOf(value));
}
})
.print();
env.execute();
}
}
输入:
// 数据流:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,1,1
s1,2,2
输出:
2> 传感器:s1,当前水位为:1,触发了阈值:0
1> 传感器:s1,当前水位为:2,触发了阈值:0
输入:
// 广播配置流:
[root@VM-55-24-centos ~]# nc -lk 4321
10
// 数据流:
[root@VM-55-24-centos ~]# nc -lk 1234
s1,7,7
s1,11,11
输出:
1> 传感器:s1,当前水位为:11,触发了阈值:10
简单来说,就是一条流广播后专门读取配置,与普通的数据流进行连结,然后广播流将配置加载到广播状态中,这样普通的数据流就能够在不重启程序的情况下通过上下文动态读取配置。
应用场景:MySQL定义中一张配置表,定义一条配置流读取MySQL中的binlog,配置表如有修改,就将相应的配置广播出去,更改数据库即可实现线上程序动态配置。
四.状态后端(State Backends)
在Flink中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backend)。状态后端主要负责管理本地状态的存储方式和位置。
4.1 状态后端的分类(HashMapStateBackend/RocksDB)
状态后端是一个“开箱即用”的组件,可以在不改变应用程序逻辑的情况下独立配置。Flink中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌RocksDB状态后端”(EmbeddedRocksDBStateBackend)。如果没有特别配置,系统默认的状态后端是HashMapStateBackend。
4.1.1 哈希表状态后端(HashMapStateBackend)
HashMapStateBackend是把状态存放在内存里。具体实现上,哈希表状态后端在内部会直接把状态当作对象(objects),保存在Taskmanager的JVM堆上。普通的状态,以及窗口中收集的数据和触发器,都会以键值对的形式存储起来,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。
4.1.2 内嵌RocksDB状态后端(EmbeddedRocksDBStateBackend)
RocksDB是一种内嵌的key-value存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend后,会将处理中的数据全部放入RocksDB数据库中,RocksDB默认存储在TaskManager的本地数据目录里。
RocksDB的状态数据被存储为序列化的字节数组,读写操作需要序列化/反序列化,因此状态的访问性能要差一些。另外,因为做了序列化,key的比较也会按照字节进行,而不是直接调用.hashCode()和.equals()方法。
EmbeddedRocksDBStateBackend始终执行的是异步快照(快照时不会阻塞任务),所以不会因为保存检查点而阻塞数据的处理;而且它还提供了增量式保存检查点的机制,这在很多情况下可以大大提升保存效率。
4.2 如何选择正确的状态后端
HashMapStateBackend****EmbeddedRocksDBStateBackend存储介质Taskmanager的JVM堆内存Taskmanager的JVM的文件磁盘读写速度快慢
- 由此可以看出,虽然HashMapStateBackend的读写速度快,但是使用的是Taskmanager的JVM堆内存,如果存储的状态较大,则可能会将Taskmanager的内存耗尽。
- EmbeddedRocksDBStateBackend则存在Taskmanager的本地磁盘中,可以存储大的状态,不过牺牲了一定的读写速度。
4.3 状态后端的配置
在默认配置下,应用程序使用的默认状态后端是由集群配置文件flink-conf.yaml中指定的配置名称为state.backend,可修改为hashmap或rocksdb。除此之外,还可以在提交作业时通过参数设置状态后端、以及在代码中指定。
4.3.1 配置默认的状态后端
在flink-conf.yaml中,可以使用state.backend来配置默认状态后端。
配置项的可能值为hashmap,这样配置的就是HashMapStateBackend;如果配置项的值是rocksdb,这样配置的就是EmbeddedRocksDBStateBackend。
# 默认状态后端
state.backend: hashmap
4.2.2 为每个作业(Per-job/Application)单独配置状态后端
- 通过执行环境设置 hashMapStateBackend
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置状态后端为HashMap
HashMapStateBackend hashMapStateBackend = new HashMapStateBackend();
env.setStateBackend(hashMapStateBackend);
- 通过执行环境设置 EmbeddedRocksDBStateBackend
在IDE使用EmbeddedRocksDBStateBackend则需要导入以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
设置 EmbeddedRocksDBStateBackend 状态后端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置状态后端为RocksDB
EmbeddedRocksDBStateBackend embeddedRocksDBStateBackend = new EmbeddedRocksDBStateBackend();
env.setStateBackend(embeddedRocksDBStateBackend);
4.2.3 提交参数设置状态后端
[root@VM-55-24-centos flink-1.17.0]#
bin/flink run -m localhost:1234 -D state.backend=rocksdb -c com.xxx.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
-D :指定状态后端
版权归原作者 - Hola - 所有, 如有侵权,请联系我们删除。