
爬虫如何应对流式加载页面,这100行代码请收藏!
前篇学委弄了一篇把网站拍照留存,发现截屏的页面是一个流式页面,就截了一部分怎么办?
所谓的流式加载的页面,页面高度是不断变长的,这种页面无法一次加载就获取到整个页面的真实高度!
身边有没有哪些流式加载的页面呢? 比如 CSDN的热榜 没跑了。
这种流式加载窗口就开打开水龙头一样,内容哗啦啦的展示出来,关掉了就不加载。
经常冲榜的朋友就知道,打开热榜,发现就几条Top 5,需要浏览器往下拉,才会继续动态加载更多内容出来。一直往下拉,慢慢拉整个热榜就出来了。
本文实现流程概括如下图:
第一个问题:这这个获取流式窗口高度的操作怎么实现呢?
爬虫怎么开始设置,在前一篇文章,请自行阅读。
下面直击重点,我们怎么样获取动态流式内容窗口的高度。
'''
雷学委应对流式页面的爬虫解决秘诀
核心代码:
'''defresolve_height(driver, pageh_factor=5):
js ="return action=document.body.scrollHeight"
height =0
page_height = driver.execute_script(js)
ref_pageh =int(page_height * pageh_factor)
step =150
max_count =15
count =0while count < max_count and height < page_height:#scroll down to page bottomfor i inrange(height, ref_pageh, step):
count+=1
vh = i
slowjs='window.scrollTo(0, {})'.format(vh)print('exec js: %s'% slowjs)
driver.execute_script(slowjs)
sleep(0.3)if i >= ref_pageh- step:print('not fully read')break
height = page_height
sleep(2)
page_height = driver.execute_script(js)print("finish scroll")return page_height
代码不多哦。
核心思想
- 持续滚动学习窗口内容
- 然后直到一个页面不再加载或者页面加载到限定值
- 停止更新(因为有些流式页面是没有下限的,你只要一直拉下,总会看到新东西)
看看效果图: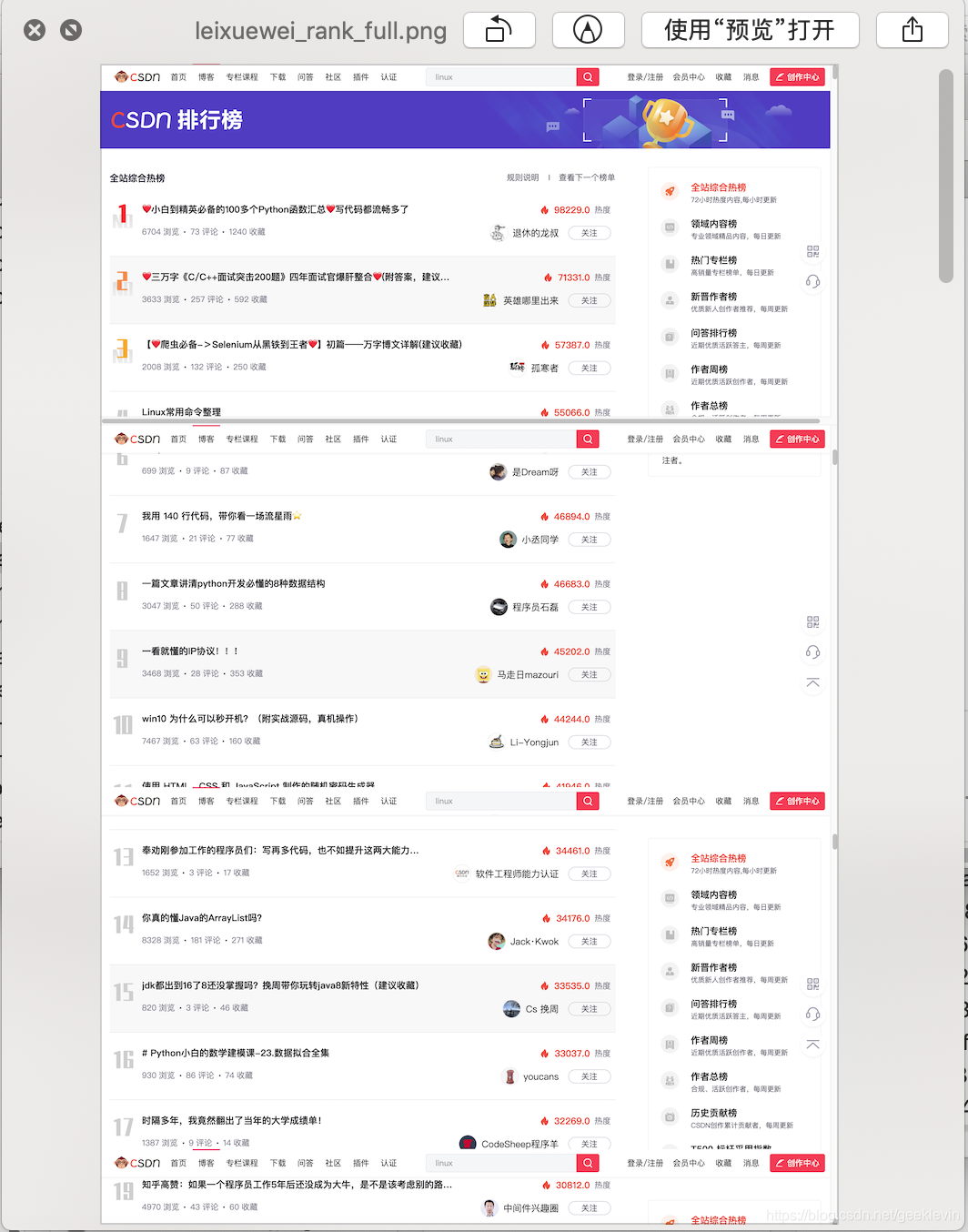
'''
雷学委应对流式页面的爬虫解决秘诀
截屏的核心代码:
'''defresolve_height(driver, pageh_factor=5):
js ="return action=document.body.scrollHeight"
height =0
page_height = driver.execute_script(js)
ref_pageh =int(page_height * pageh_factor)
step =150
max_count =15
count =0while count < max_count and height < page_height:#scroll down to page bottomfor i inrange(height, ref_pageh, step):
count+=1
vh = i
slowjs='window.scrollTo(0, {})'.format(vh)print('[雷学委 Demo]exec js: %s'% slowjs)
driver.execute_script(slowjs)
sleep(0.3)if i >= ref_pageh- step:print('[雷学委 Demo]not fully read')break
height = page_height
sleep(2)
page_height = driver.execute_script(js)print("finish scroll")return page_height
#获取窗口实际高度
page_height = resolve_height(driver)print("[雷学委 Demo]page height : %s"%page_height)
sleep(5)
driver.execute_script('document.documentElement.scrollTop=0')
sleep(1)
driver.save_screenshot(img_path)
page_height = driver.execute_script('return document.documentElement.scrollHeight')# 页面高度print("get accurate height : %s"% page_height)if page_height > window_height:
n = page_height // window_height #floorfor i inrange(n):
driver.execute_script(f'document.documentElement.scrollTop={window_height*(i+1)};')
sleep(1)
driver.save_screenshot(f'./leixuewei_rank_{i}.png')
代码还是不多哦。
核心思想
- 持续滚动截屏窗口内容
- 保持为图片(带上下标记)
下面是中间截取的一个图片: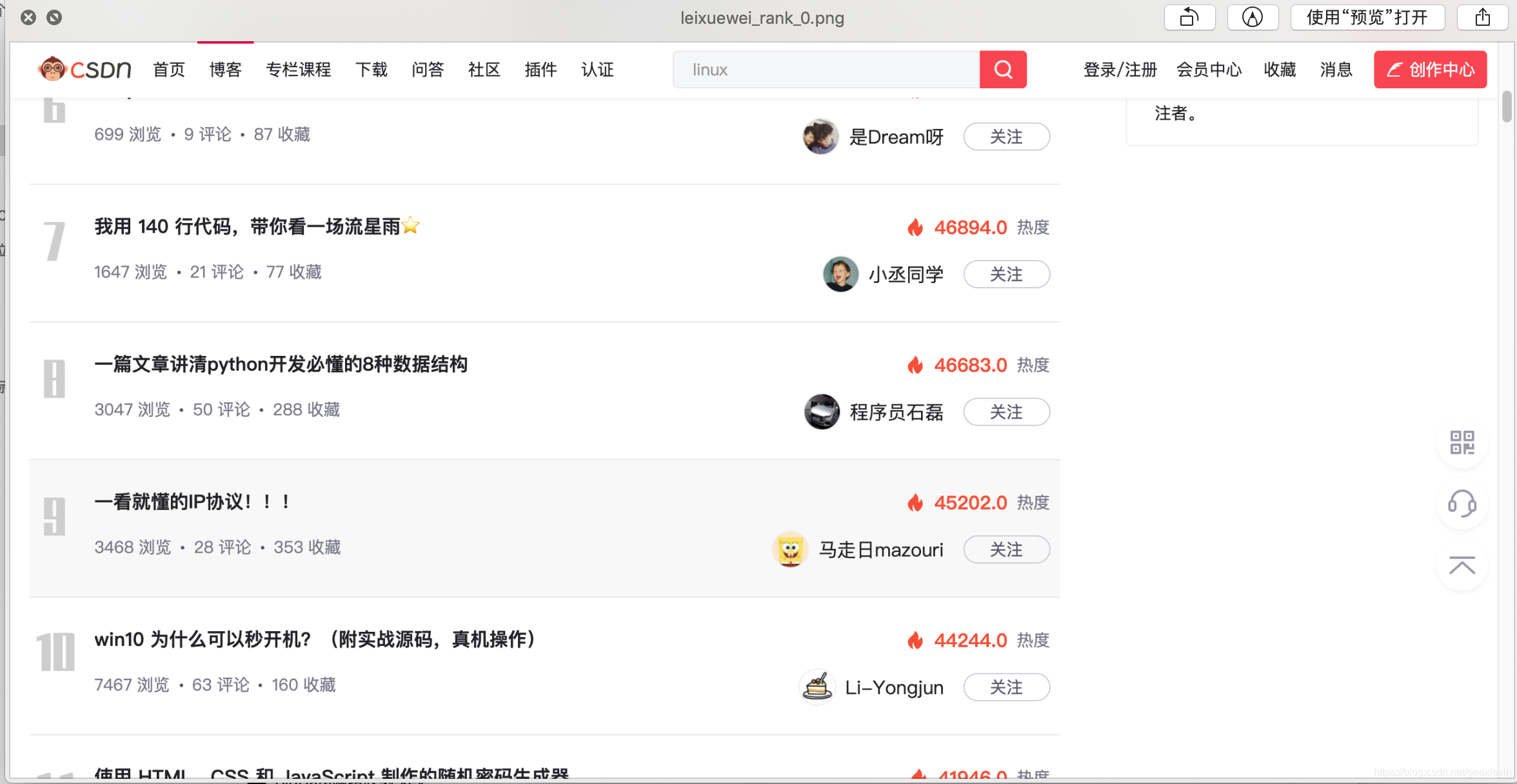
那么多个图怎么合成一张呢?
我们在代码项目目录中,可以看到这里生成了(如下图的)多张图片。总不能自己动手PS吧?
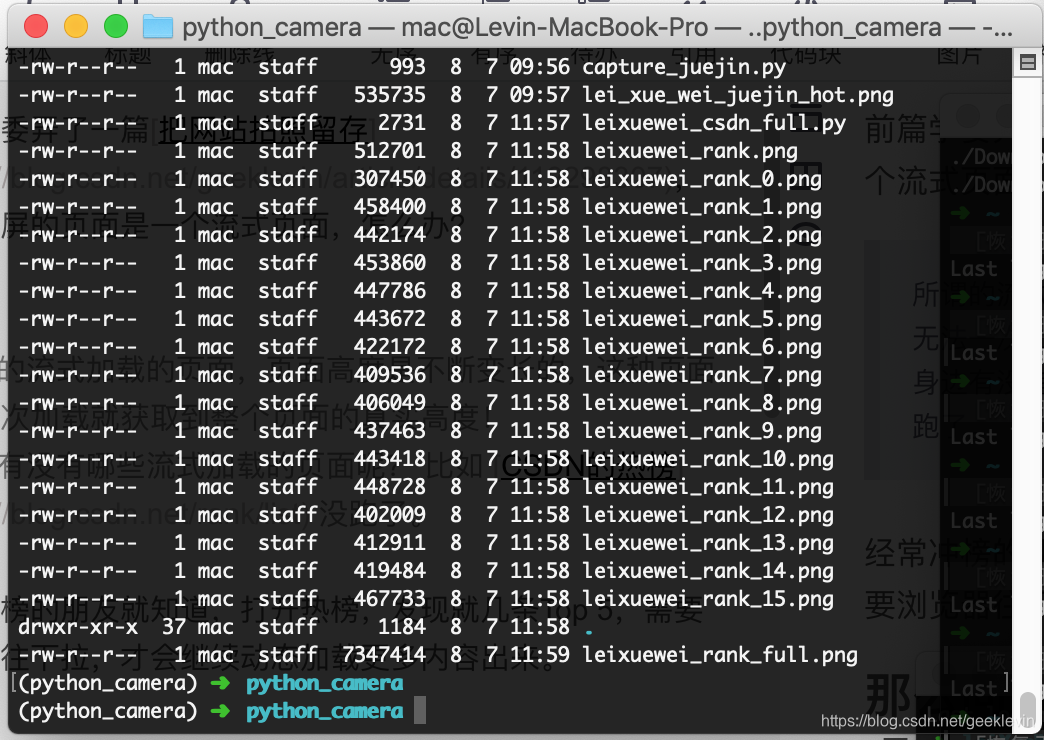
首先要理解图片是什么?
图片本质上就是一个2d的像素点的一个矩阵。
我们看到的每张图片,其实就是很多的像素分横向纵向排列,显示出来就是图片了。
好办,合并的思路有了,用numpy库直接来
我们拿上面的代码改造一下:
'''
雷学委应对流式页面的爬虫解决秘诀
截屏的核心代码:
'''import numpy as np
if page_height > window_height:
n = page_height // window_height #floor
base_matrix = np.atleast_2d(Image.open(img_path))for i inrange(n):
driver.execute_script(f'document.documentElement.scrollTop={window_height*(i+1)};')
sleep(1)
driver.save_screenshot(f'./leixuewei_rank_{i}.png')
delta_matrix = np.atleast_2d(Image.open(f'./leixuewei_rank_{i}.png'))#concentrate the image
base_matrix = np.append(base_matrix, delta_matrix, axis=0)
Image.fromarray(base_matrix).save('./leixuewei_rank_full.png')
牛比吧,就加一点点代码,关键是思路。
代码解析
这里其实就是在截屏循环中不断的吧图片转换为2d矩阵。
然后把多个2d矩阵再追加,这样横向长度不变,但纵向内容追加,形成了一张完整的图片了。
这里就是热榜列表的全屏截图展示了。
总结
整个思路还是很流畅的,代码不到一百行,但是思路不对就做不了, 主要用了下面几个库。
selenium
numpy
Pillow
最后使用爬虫必须谨慎,不要当做儿戏去爬机构网站。你学习也不能拿严肃的网络来刷,这个行为迟早会让你吃上LAO饭!
本文仅作展示目的,对于演示网站有任何异议,请告知修改。
持续学习持续开发,我是雷学委!
编程很有趣,关键是把技术搞透彻讲明白。
创作不易,请多多支持,点赞收藏支持学委吧!
本文转载自: https://blog.csdn.net/geeklevin/article/details/119303683
版权归原作者 雷学委 所有, 如有侵权,请联系我们删除。
版权归原作者 雷学委 所有, 如有侵权,请联系我们删除。