
前言
使用过mysql的同学对join的用法应该不陌生,使用join可以完成多个表的关联查询,而在spark中,也提供了基于join的算子,通过join,可以将不同的k/v类型的数据进行关联;
**join **
函数说明
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的
(K,(V,W))的 RDD
join使用说明补充:
- 两个不同数据源的数据,相同的key的value会连接在一起,形成元组;
- 如果两个数据源中key没有匹配上,那么数据不会出现在结果中;
- 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低
案例展示
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object JoinTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - (Key - Value类型)
val rdd1 = sc.makeRDD(List(
("a", 1), ("a", 2), ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 5), ("c", 6),("a", 4)
))
// join : 两个不同数据源的数据,相同的key的value会连接在一起,形成元组
// 如果两个数据源中key没有匹配上,那么数据不会出现在结果中
// 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
sc.stop()
}
}
运行上面的代码,观察控制台输出效果,
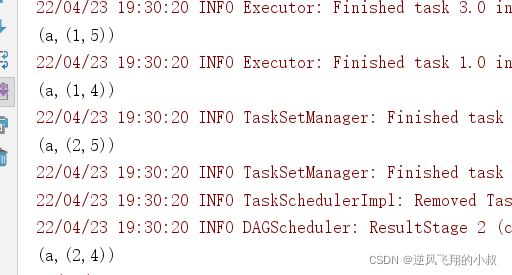
leftOuterJoin
函数签名
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
函数说明
类似于 SQL 语句的左外连接
案例展示
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object JoinLeftTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5) //,("c", 6)
))
val leftJoinRDD = rdd1.leftOuterJoin(rdd2)
leftJoinRDD.collect().foreach(println)
//val rightJoinRDD = rdd1.rightOuterJoin(rdd2)
//rightJoinRDD.collect().foreach(println)
sc.stop()
}
}
运行上面的程序,观察控制台输出效果,这个和sql中的左连接效果类似

本文转载自: https://blog.csdn.net/congge_study/article/details/124368759
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。