
HDFS联合集群的发展史
文章目录
HDFS原始架构
不管是之后的 NN与secondary namenode还是standby namenode其实实际运行的时候都是都可以抽象成以下的架构,因为active NN是唯一的。
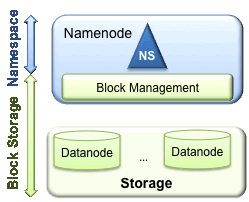
HDFS拥有两个层
- Namespace- 由目录、文件和块组成。- 它支持所有与命名空间相关的文件系统操作,例如创建、删除、修改和列出文件和目录。
- Block Storage Service- 块管理(在Namenode中执行) - 通过处理注册和定期心跳来提供 Datanode 集群成员资格- 处理块报告并维护块的位置。- 支持块相关操作,如创建、删除、修改和获取块位置。- 管理副本放置、复制不足的块的块复制以及删除复制过度的块。- 存储 - 由 Datanodes 通过在本地文件系统上存储块并允许读/写访问来提供。
HDFS联合集群的目的是为了支持子集群进行横向联合。
方案一 HDFS Federation
之前的HDFS架构只允许整个集群有一个命名空间。 在原始架构中,由单个 Namenode 管理命名空间。 HDFS Federation 通过向 HDFS 添加对多个 Namenode/命名空间的支持来解决此限制。
多个namspaces/NNs
为了水平扩展名称服务,联合使用多个独立的Namenodes/namespaces。 Namenodes是联合的; Namenodes是独立的,不需要相互协调。 Datanodes 被所有 Namenodes 用作块的公共存储。 每个Datanode向集群中的所有Namenode注册。 数据节点定期发送心跳和块报告。 它们还处理来自Namenodes的命令。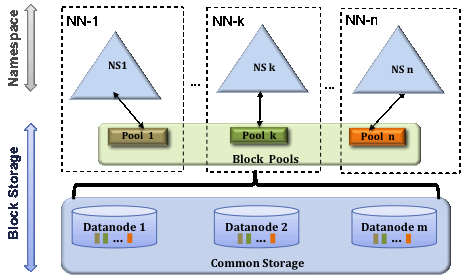
Block Pool
HDFS Federation 引入了块池特性,每个块池有一个唯一的ID,块池与NN是一一对应的,等于一个子集群拥有一个块池。
块池是属于单个命名空间的一组块。块池的块分散存储在整个Datanodes中,每个块池都是独立管理的。 这允许命名空间为新块生成块 ID,而无需与其他命名空间协调。 Namenode故障不会阻止Datanode为集群中的其他Namenode提供服务。
命名空间及其块池一起称为命名空间卷。 它是一个独立的管理单位。 当删除Namenode/namespace时,Datanode上相应的块池也会被删除。 在集群升级期间,每个命名空间卷都会作为一个单元进行升级。
ClusterID 标识符用于标识集群中的所有节点。 当 Namenode 被格式化时,该标识符要么被提供,要么自动生成。 该 ID 应用于将其他 Namenode 格式化到集群中。
命名空间可扩展性 - 联合添加了命名空间水平扩展。 通过允许将更多 Namenode 添加到集群,大型部署或使用大量小文件的部署受益于命名空间扩展。
性能——文件系统吞吐量不受单个Namenode的限制。 向集群添加更多 Namenode 可扩展文件系统读/写吞吐量。
隔离 - 单个 Namenode 在多用户环境中不提供隔离。 例如,实验性应用程序可能会使 Namenode 过载并减慢生产关键应用程序的速度。 通过使用多个Namenode,可以将不同类别的应用程序和用户隔离到不同的命名空间。
缺陷:
- 不同NN之间是无法感知的。不是真正NN上的扩容,属于一个伪NN扩展。
- 引入一个新的NN之后,并没有直接降低原来NN的压力,类似新搭建一个集群,然后需要做手动迁移,分担压力。
- 客户端访问不同的NN,需要自行维护映射关系。
每个集群的
core-site.xml
都有一个配置属性,用于将默认文件系统设置为该集群的
namenode
:
这样的配置属性允许使用斜杠相对名称来解析相对于集群名称节点的路径。 例如,路径 /foo/bar 使用上述配置引用
hdfs://namenodeOfClusterX:port/foo/bar
。
<property><name>fs.default.name</name><value>hdfs://namenodeOfClusterX:port</value></property>
路径名的使用模式
/foo/bar(最佳使用方式)- 等价于hdfs://namenodeOfClusterX:port/foo/bar.hdfs://namenodeOfClusterX:port/foo/bar- 虽然这是一个有效的路径名,但最好使用/foo/bar,因为它允许应用程序及其数据在需要时透明地移动到另一个集群。hdfs://namenodeOfClusterY:port/foo/bar- 它是一个 URI,用于引用另一个集群(例如集群 Y)上的路径名。具体来说,将文件从集群 Y 复制到集群 Z 的命令如下所示:distcp hdfs://namenodeClusterY:port/pathSrc hdfs://namenodeClusterZ:port/pathDestwebhdfs://namenodeClusterX:http_port/foo/bar和hftp://namenodeClusterX:http_port/foo/bar- 这些是分别用于通过WebHDFS文件系统和HFTP文件系统访问文件的文件系统URI。 请注意,WebHDFS 和 HFTP 使用名称节点的 HTTP 端口,但不使用 RPC 端口。http://namenodeClusterX:http_port/webhdfs/v1/foo/bar和http://proxyClusterX:http_port/foo/bar- 这些是分别用于通过 WebHDFS REST API 和 HDFS 代理访问文件的 HTTP URL。
假设有多个集群。 每个集群都有一个或多个NN。 每个NN都有自己的名称空间。 一个NN属于一个且仅一个集群。 同一集群中的NN共享该集群的物理存储。 跨集群的命名空间和以前一样是独立的。
操作根据存储需求决定集群中每个NN上存储的内容。 例如,他们可能将所有用户数据(
/user/<username>
)放在一个NN中,将所有提要数据(
/data
)放在另一个NN中,将所有项目(
/projects
)放在另一个NN中,等等。
方案二 ViewFs
ViewFs主要目的为了解决 HDFS Federation中多NN访问难的问题
查看文件系统 (ViewFs) 提供了一种管理多个HDFS子集群的方法。 ViewFs 类似于某些 Unix/Linux 系统中的客户端挂载表。 ViewFs 可用于创建个性化命名空间视图以及每个集群的映射。
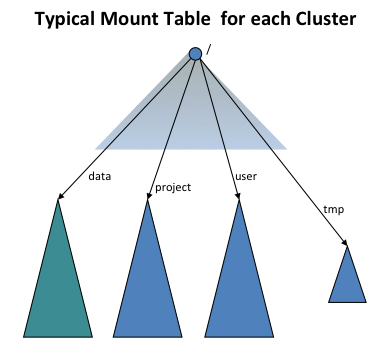
使用 ViewFs 为每个集群提供一个全局命名空间
为了提供与旧版本的透明度(用户无感),使用ViewFs文件系统(即客户端挂载表)为每个集群创建独立的集群命名空间视图,这与旧版本中的命名空间类似。 客户端挂载表与 Unix 挂载表类似,它们使用旧的命名约定挂载新的命名空间卷。 下图显示了挂载四个命名空间卷
/user
、
/data
、
/projects
和
/tmp
的挂载表:
ViewFs 实现了 Hadoop 文件系统接口,就像 HDFS 和本地文件系统一样。 从某种意义上说,它是一个普通的文件系统,它只允许链接到其他文件系统。 由于 ViewFs 实现了 Hadoop 文件系统接口,因此它可以透明地工作于 Hadoop 工具。 例如,所有 shell 命令都可以与 ViewFs 一起使用,就像与 HDFS 和本地文件系统一样。
<property><name>fs.defaultFS</name><value>viewfs://clusterX</value></property>
路径名使用模式
/foo/bar(最佳使用方式)- 这相当于viewfs://clusterX/foo/bar。 如果在旧的非联合集群中使用这样的路径名,则到联邦的过渡是透明的。viewfs://clusterX/foo/bar- 虽然这是一个有效的路径名,但最好使用/foo/bar,因为它允许应用程序及其数据在需要时透明地移动到另一个集群。viewfs://clusterY/foo/bar- 它是一个 URI,用于引用另一个集群(例如集群 Y)上的路径名。具体来说,将文件从集群 Y 复制到集群 Z 的命令如下所示:distcp viewfs://clusterY/pathSrc viewfs://clusterZ/pathDestviewfs://clusterX-webhdfs/foo/barandviewfs://clusterX-hftp/foo/bar- 这些分别是用于通过WebHDFS文件系统和HFTP文件系统访问文件的URI。http://namenodeClusterX:http_port/webhdfs/v1/foo/barandhttp://proxyClusterX:http_port/foo/bar- 这些是分别用于通过 WebHDFS REST API 和 HDFS 代理访问文件的 HTTP URL。 请注意,它们与以前相同。
跨命名空间重命名路径名
在旧版本中,用户无法跨NN或集群重命名文件或目录。 此版本也是如此,但有一些额外的变化。 例如,在旧版本中,人们可以执行以下命令。
rename /user/joe/myStuff /data/foo/bar
如果
/user
和
/data
实际上存储在集群内的不同NN上,这在联合集群中将不起作用。
方案三 HDFS Router-based Federation
HDFS Router-based Federation主要目的为了解决 HDFS Federation中多NN访问难的问题(取代ViewFS),实现客户端访问多个子集群之间的负载均衡,支持跨子集群均衡数据,让数据可以实现冷热子集群之间的迁移。
由于以下原因会限制NN的可扩展性:
- 元数据的开销
- DN的心跳检测
- HDFS RPC客户端的数量
之前HDFS扩展方案:
- 采用联合视图(ViewFS),问题在于如何维护子集群的分割(例如命令空间的分区),这迫使用户连接到多个子集群上管理文件夹和文件的分配。
基于路由的联合
在子集群之上建立了一个的软件层,用来负责联合的命名空间的工作。这个额外的联合层,使得用户访问的访问子集群是透明的,子集群独立管理自己的本身的块池,还支持子集群之间的数据均衡。
使用基于路由的联合集群的子集群可以是独立的HDFS集群,也可以是federation集群,还可以是混合集群(独立的HDFS集群+federation集群)。
联合层的核心组件:
- Router :属于无状态服务,全局的NN接口,转发客户端的请求到子集群的NN中;与NN 心跳检测,管理NN信息到状态存储器,同时可以缓存Mount Table和子集群的状态信息。路由器与状态存储之间的通信将被缓存,用来提升性能。
- State Store:在逻辑上是集中式,但是物理是分散式的。主要用户数据存储,包含远程挂载表(Mount Table)、子集群的负载和容量信息、路由的信息。 状态存储的后端是可插拔的。 我们利用后端实现的容错能力。 State Store中存储的主要信息及其实现: Membership:成员资格信息会对联合集群中的NN进行编码,路由器会定期检测这些子集群的NN并汇报信息。 Mount Table:此表管理了文件夹/文件与子集群之间的映射。
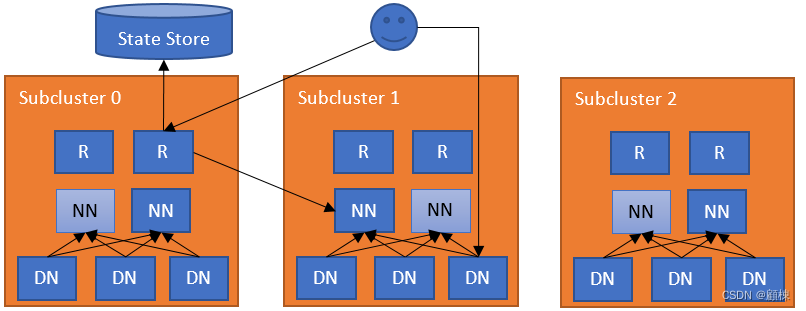
最简单的部署,在NN的服务器上部署Router,一个NN对应一个Router。
#mermaid-svg-8jTUO47Xsg3hKh1r {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r .error-icon{fill:#552222;}#mermaid-svg-8jTUO47Xsg3hKh1r .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-8jTUO47Xsg3hKh1r .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-8jTUO47Xsg3hKh1r .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-8jTUO47Xsg3hKh1r .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-8jTUO47Xsg3hKh1r .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-8jTUO47Xsg3hKh1r .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-8jTUO47Xsg3hKh1r .marker{fill:#333333;stroke:#333333;}#mermaid-svg-8jTUO47Xsg3hKh1r .marker.cross{stroke:#333333;}#mermaid-svg-8jTUO47Xsg3hKh1r svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-8jTUO47Xsg3hKh1r .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r .cluster-label text{fill:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r .cluster-label span{color:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r .label text,#mermaid-svg-8jTUO47Xsg3hKh1r span{fill:#333;color:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r .node rect,#mermaid-svg-8jTUO47Xsg3hKh1r .node circle,#mermaid-svg-8jTUO47Xsg3hKh1r .node ellipse,#mermaid-svg-8jTUO47Xsg3hKh1r .node polygon,#mermaid-svg-8jTUO47Xsg3hKh1r .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-8jTUO47Xsg3hKh1r .node .label{text-align:center;}#mermaid-svg-8jTUO47Xsg3hKh1r .node.clickable{cursor:pointer;}#mermaid-svg-8jTUO47Xsg3hKh1r .arrowheadPath{fill:#333333;}#mermaid-svg-8jTUO47Xsg3hKh1r .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-8jTUO47Xsg3hKh1r .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-8jTUO47Xsg3hKh1r .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-8jTUO47Xsg3hKh1r .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-8jTUO47Xsg3hKh1r .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-8jTUO47Xsg3hKh1r .cluster text{fill:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r .cluster span{color:#333;}#mermaid-svg-8jTUO47Xsg3hKh1r div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-8jTUO47Xsg3hKh1r :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}
1
2
3
4
5
6
7
8
HDFS Client
Router
StateStore
active NN
DataNode
联合层需要满足可扩展性,高可用性,和容错性。
路由器的故障容错
由于路由器是无状态的,那么也就是每个路由器的权重应该是一样的,当其中一个路由器不可用,其他路由器可以接替它继续服务。hdfs客户端在联合集群中配置时,需要将所有的路由器作为连接断点,来实现路由器的HA。
状态存储不可用
如果状态存储不可用,或者路由器连接不到对应的状态存储,则路由器会进入安全模式,将不处理任何请求。对于客户端来说,会把安全模式的路由器当做备用NN,然后尝试连接其他路由器。可以通过以下手动命令控制安全模式的路由器。可以将状态存储存放到ZK上,来保证高可用。
$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -safemode enter | leave | get
NN心跳的高可用
多个路由器会监听同一个NN,并将信息心跳传至状态存储。当路由器发生故障,导致状态存储的NN信息的冲突,会由每一个路由器通过仲裁来决定。投票选主?
不可用的NN
如果路由器无法与子集群的activeNN进行通信,会尝试联系备用NN,若NN都不可用,会报错。
过期的NN
如果NN的心跳检测出现过期,那么监控路由器会将此NN识别为过期状态的NN,在NN恢复心跳检测之前,所有的请求将不会发给过期NN。若NN心跳恢复了合理时间区间,Router会将NN的过期状态变更掉。
常用命令
启动与关闭
$ $HADOOP_PREFIX/bin/hdfs --daemon start dfsrouter
$ $HADOOP_PREFIX/bin/hdfs --daemon stop dfsrouter
远程挂载表操作
# 将目录/tmp 挂载到子集群ns1的 /tmp上[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /tmp ns1 /tmp
# 将目录/data/app1 挂载到子集群ns2的 /data/app1上[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /data/app1 ns2 /data/app1
# 将目录/data/app2 挂载到子集群ns3的 /data/app2上[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /data/app2 ns3 /data/app2
# 删除目录/data/app2[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -rm /data/app2
# 查询所有的挂载目录信息[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -ls
# 挂载只读文件夹[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /readonly ns1 / -readonly
# 设置挂载的权限(用户 用户组 权限编码)[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /tmp ns1 /tmp -owner root -group supergroup -mode 0755
常用配置
路由的配置增加在hdfs-site.xml
RPC server
RPC 服务器接收来自客户端的连接。
PropertyDefaultDescriptiondfs.federation.router.default.nameserviceId要监视的默认子集群的名称服务标识符。dfs.federation.router.rpc.enable
true
If
true
, 路由器中处理客户端请求的 RPC 服务已启用。dfs.federation.router.rpc-address0.0.0.0:8888处理所有客户端请求的 RPC 地址。dfs.federation.router.rpc-bind-host0.0.0.0RPC 服务器将绑定到的实际地址。dfs.federation.router.handler.count10路由器处理来自客户端的 RPC 请求的服务器线程数。dfs.federation.router.handler.queue.size100处理 RPC 客户端请求的处理程序数量的队列大小。dfs.federation.router.reader.count1路由器处理 RPC 客户端请求的reader数量。dfs.federation.router.reader.queue.size100路由器处理 RPC 客户端请求的读取器数量的队列大小。
Connection to the Namenodes
Router 将客户端请求转发到 NameNode。 它使用连接池来减少创建连接的延迟。
PropertyDefaultDescriptiondfs.federation.router.connection.pool-size1从路由器到NN节点的连接池的大小dfs.federation.router.connection.clean.ms10000检查连接池是否应删除未使用的连接的时间间隔(以毫秒为单位)dfs.federation.router.connection.pool.clean.ms60000检查连接管理器是否应删除未使用的连接池的时间间隔(以毫秒为单位)。
Admin server
管理挂载表的管理服务器。
PropertyDefaultDescriptiondfs.federation.router.admin.enable
true
If
true
, 启用了路由器中用于处理客户端请求的 RPC 管理服务。dfs.federation.router.admin-address0.0.0.0:8111处理管理请求的 RPC 地址。dfs.federation.router.admin-bind-host0.0.0.0RPC 管理服务器将绑定到的实际地址。dfs.federation.router.admin.handler.count1路由器处理来自管理员的 RPC 请求的服务器线程数。
HTTP Server
HTTP 服务器为客户端提供 Web UI 和 HDFS REST 接口 (WebHDFS)。 默认 URL 为
http://router_host:50071
。
PropertyDefaultDescriptiondfs.federation.router.http.enable
true
If
true
, 路由器中处理客户端请求的 HTTP 服务已启用。dfs.federation.router.http-address0.0.0.0:50071处理对路由器的 Web 请求的 HTTP 地址。dfs.federation.router.http-bind-host0.0.0.0HTTP 服务器将绑定到的实际地址。dfs.federation.router.https-address0.0.0.0:50072处理对路由器的 Web 请求的 HTTPS 地址。dfs.federation.router.https-bind-host0.0.0.0HTTPS 服务器将绑定到的实际地址。
State Store
与状态存储的连接以及路由器的内部缓存。
PropertyDefaultDescriptiondfs.federation.router.store.enable
true
如果为
true
,则路由器连接到状态存储。dfs.federation.router.store.serializer
org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreSerializerPBImpl
用于序列化状态存储记录的类。dfs.federation.router.store.driver.class
org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreZooKeeperImpl
实现状态存储的类dfs.federation.router.store.connection.test60000检查状态存储连接的频率(以毫秒为单位)。dfs.federation.router.cache.ttl60000刷新状态存储缓存的频率(以毫秒为单位)。dfs.federation.router.store.membership.expiration300000成员资格记录的到期时间(以毫秒为单位)。
Routing
将客户端请求转发到正确的子集群。
PropertyDefaultDescriptiondfs.federation.router.file.resolver.client.class
org.apache.hadoop.hdfs.server.federation.resolver.MountTableResolver
将文件解析到子集群的类。dfs.federation.router.namenode.resolver.client.class
org.apache.hadoop.hdfs.server.federation.resolver.MembershipNamenodeResolver
用于解析子集群的NN节点的类。
Namenode monitoring
监视子集群中的NN节点以转发客户端请求。
PropertyDefaultDescriptiondfs.federation.router.heartbeat.enable
true
如果为“true”,则路由器会向状态存储中发送心跳。dfs.federation.router.heartbeat.interval5000路由器应以毫秒为单位向状态存储发送心跳的频率。dfs.federation.router.monitor.namenode要监视和检测信号的NN节点的标识符。dfs.federation.router.monitor.localnamenode.enable
true
如果为“true”,则路由器应监视本地计算机中的NN节点。
注意:如果启用*
dfs.federation.router.monitor.localnamenode.enable
,建议配置
dfs.nameservice.id
*。 这将允许路由器直接找到本地节点。 否则,它将通过将
namenode RPC
地址与本地节点地址进行匹配来找到
nameservice Id
。 如果匹配多个地址,路由器将无法启动。 另外,如果本地节点是HA模式,建议配置*
dfs.ha.namenode.id
*。
版本
HADOOP-V2
版本号主要变化HDFS 2.9.0基于 HDFS 路由器的联合添加了一个 RPC 路由层,提供多个 HDFS 命名空间的联合视图。 这与现有的 ViewFS 和 HDFS 联合功能类似,只不过挂载表由路由层在服务器端而不是客户端进行管理。 这简化了现有 HDFS 客户端对联合集群的访问。HDFS 2.9.11.将默认状态存储从本地文件更改为 ZooKeeper。 这将需要配置额外的 zk 地址。
2.挂载表支持ACL,用户将无法修改自己的条目(我们假设这些旧的(之前没有权限)挂载表的所有者:超级用户,组:超级组,权限:755作为默认权限)。 修复方法是以超级用户身份登录来修改这些挂载表条目。HDFS 2.10.01.将默认状态存储从本地文件更改为 ZooKeeper。 这将需要配置额外的 zk 地址。
2.挂载表支持ACL,用户将无法修改自己的条目(我们假设这些旧的(之前没有权限)挂载表的所有者:超级用户,组:超级组,权限:755作为默认权限)。 修复方法是以超级用户身份登录来修改这些挂载表条目。
3.联合在挂载表级别支持和控制全局配额。
在联合环境中,一个文件夹可以分布在多个子集群中。 路由器聚合从这些子集群查询的配额,并将其用于配额验证。
HADOOP-V3
版本号主要变化HDFS 3.0.0基于 HDFS 路由器的联合添加了一个 RPC 路由层,提供多个 HDFS 命名空间的联合视图。 这与现有的 ViewFS 和 HDFS 联合功能类似,只不过挂载表由路由层在服务器端而不是客户端进行管理。 这简化了现有 HDFS 客户端对联合集群的访问。HDFS 3.0.31.将默认状态存储从本地文件更改为 ZooKeeper。 这将需要配置额外的 zk 地址。 2.挂载表支持ACL,用户将无法修改自己的条目(我们假设这些旧的(之前没有权限)挂载表的所有者:超级用户,组:超级组,权限:755作为默认权限)。 修复方法是以超级用户身份登录来修改这些挂载表条目。HDFS 3.1.01.将默认状态存储从本地文件更改为 ZooKeeper。 这将需要配置额外的 zk 地址。 2.挂载表支持ACL,用户将无法修改自己的条目(我们假设这些旧的(之前没有权限)挂载表的所有者:超级用户,组:超级组,权限:755作为默认权限)。 修复方法是以超级用户身份登录来修改这些挂载表条目。
相关issues
版权归原作者 顧棟 所有, 如有侵权,请联系我们删除。