
目录
基于百度智能云平台的情感倾向计算
1.百度智能云平台直接搜索“情感分析”进入平台,要登录个人百度账号;
2.新手可以免费领取资源测试,在页面的接口选择“情感倾向”即可:
3.领取资源后点击创建应用,获取AppleID、API Key、Secret Key,后面要用到;
在线调试or线下调用
在线调试
打开API文档,这个access_token是在线调试必须的参数。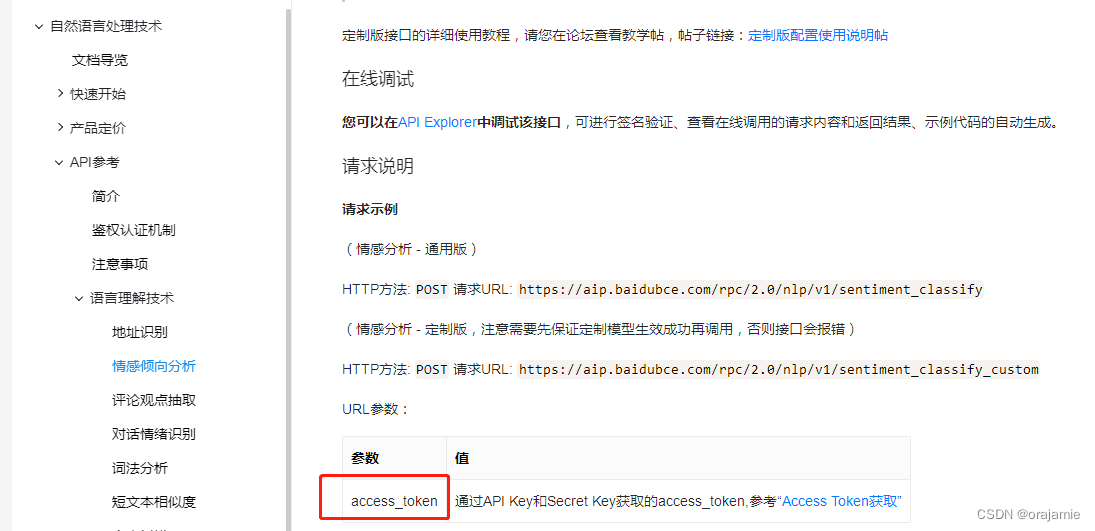
点击上图的“Access Token获取”进入“鉴权认证机制”文档:
根据这个流程操作,获取access_token参数,注意红框内的服务地址,待会要用;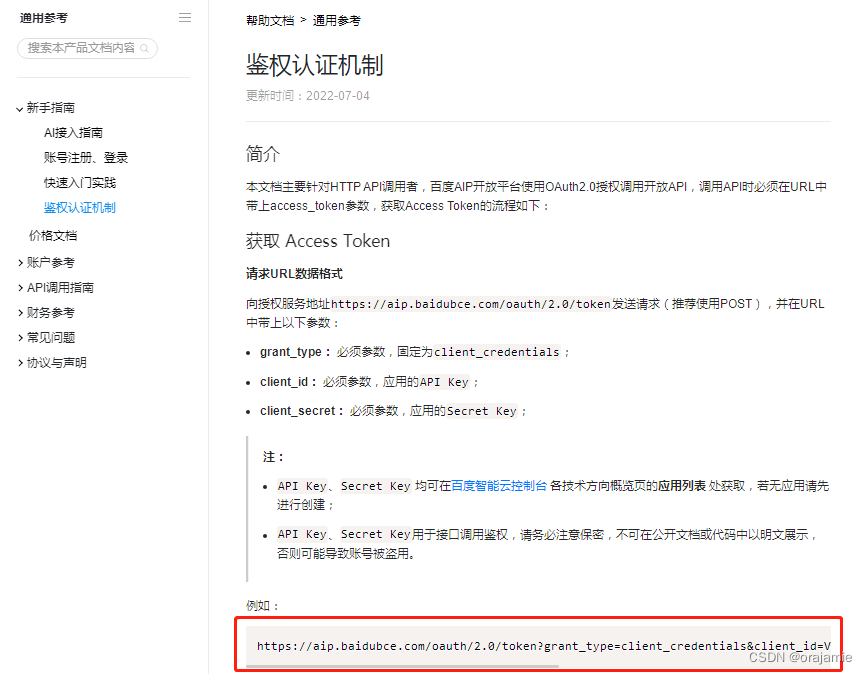
可以查看教学视频,自己跟着做

没兴趣看的就按以下操作:
1.点击链接下载安装postman:postman安装网址
2.在网页中找到Postman on the web,进行网页端安装
我这里已经安装了所以看不到流程,按着提示走就行。
3.进入自己的主页,点击My Workspace:
4.点击以下位置: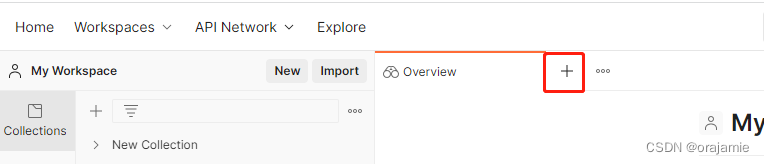
5.在1处选择POST,在2处填入刚才的服务地址(忘记了就向上翻),
3处就填这个:client_credentials,4处填自己的API Key,5处填自己的Secret Key(在创建应用中可以找到);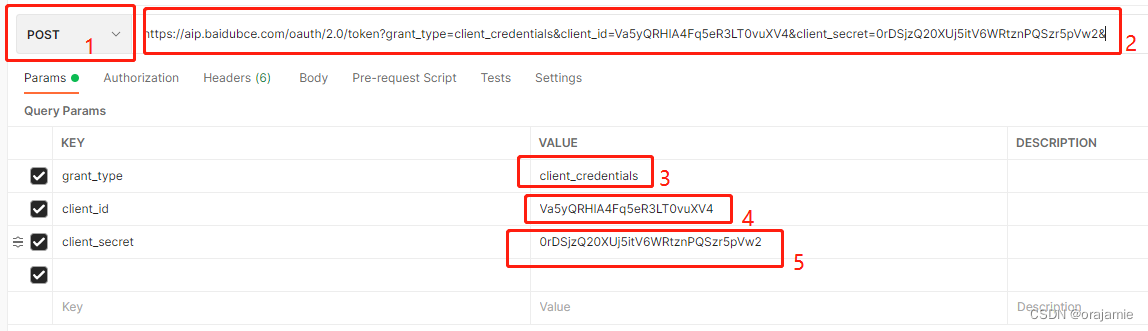
6.填完点击send,下面就会出来access_token;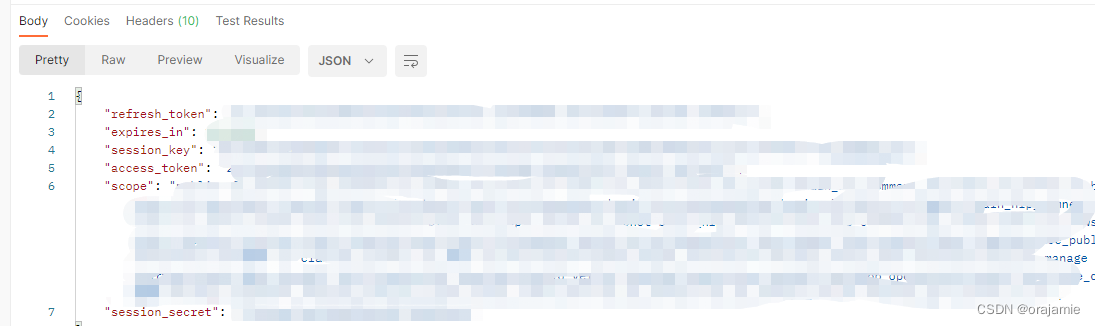
7.进入API在线调试页面: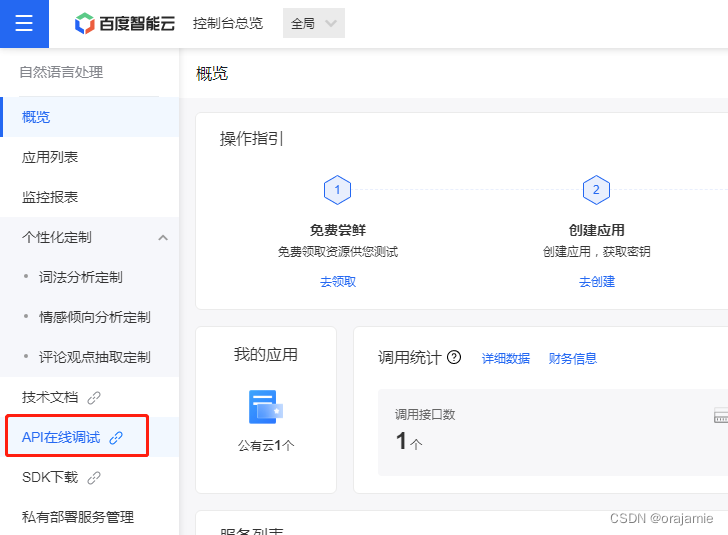
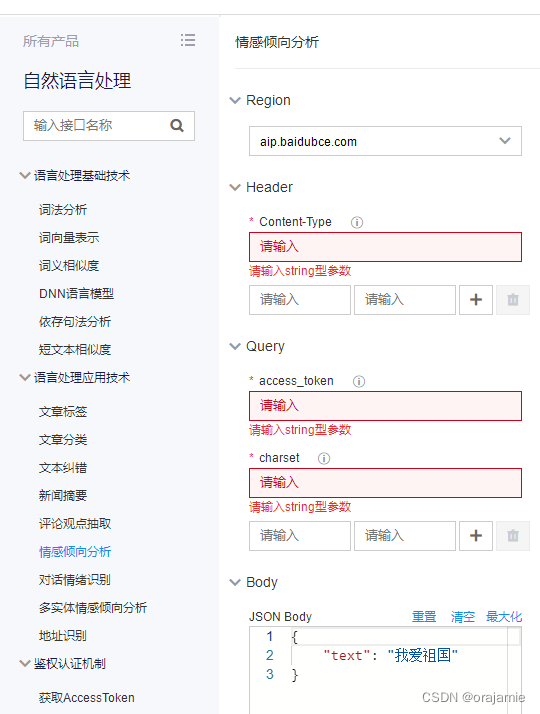
Content-Type:application/x-www-form-urlencoded
access_token:刚才获取的
charset:中文写UTF-8,其他的自己查一下
Body:就可以根据自己的需求改写text进行测试了
线下调用
我这里根据自己的需求改过代码,将结果存储到csv中,原代码可在百度智能云找到。
import pandas as pd
from aip import AipNlp
import time
""" 你的 APPID AK SK """
APP_ID ='xxxxxx'
API_KEY ='xxxxxxxxxxxxxxxxxxxxxx'
SECRET_KEY ='xxxxxxxxxxxxxxxxxxxxxxxxx'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)# 要读取的文本数据
textdf = pd.read_excel(r'F:\Main\data\hd.xlsx', usecols=['date','text'])for i inrange(len(textdf)):
text = textdf['text'][i]# 使用的是中文文本,存在不可见字符,根据报错结果排查出来的。
text = text.replace('\u200b','')
text = text.replace('\u2003','')""" 调用情感倾向分析 """print(i)
analy_result = client.sentimentClassify(text)
positive_prob.append(analy_result['items'][0]['positive_prob'])
confidence.append(analy_result['items'][0]['confidence'])
negative_prob.append(analy_result['items'][0]['negative_prob'])
sentiment.append(analy_result['items'][0]['sentiment'])dict={'hd':text,'positive_prob':positive_prob,'confidence':confidence,'negative_prob':negative_prob,'sentiment':sentiment}
data = pd.DataFrame(dict,index=[i])
data.to_csv(r'F:\Main\baidu_senti\bd_senti.csv',mode='a+',index=False,header=False,encoding='UTF-8')# 注意!!!!!!!!!# 当循环超过3个文本就会报错,报错原因是并发数过高# 所以在这里加了个线程休眠,设置的是休眠1秒后再继续,这个时间可以看着改
time.sleep(1)
好像这个免费额度是50万次。
本文转载自: https://blog.csdn.net/orange997/article/details/125792462
版权归原作者 importorange 所有, 如有侵权,请联系我们删除。
版权归原作者 importorange 所有, 如有侵权,请联系我们删除。