
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀**对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的动物识别系统
设计思路
一、课题背景与意义
动物识别一直是生态学、生物学以及计算机视觉领域的重要课题。随着深度学习技术的快速发展,基于深度学习的动物识别系统为动物种类的自动化、准确识别提供了新的解决方案。该系统能够广泛应用于野生动物保护、生态监测、动物行为研究等多个领域,对于推动相关学科的发展和实际应用具有重要意义。
二、算法理论原理
2.1 卷积神经网络
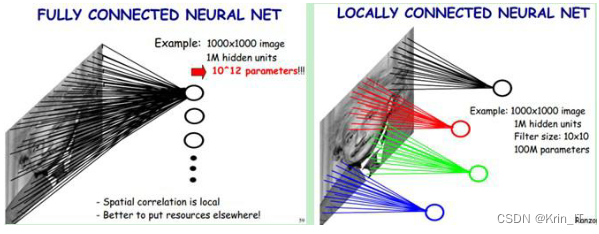
卷积神经网络在动物识别系统中具有广泛应用。CNN是一种专门设计用于处理图像和视觉数据的深度学习模型。其在动物识别中的应用可以帮助实现自动化的动物分类、识别和监测。动物识别系统可以自动化地对动物图像进行分类和识别,实现对动物群体、物种分布和行为模式的监测和分析。这对于野生动物保护、生态研究、农业监测等领域具有重要意义。为了模拟人类视觉系统的工作方式,卷积神经网络(CNN)中引入了卷积层和池化层。卷积层通过局部感受野和卷积操作来提取图像中的局部特征,而池化层则通过对局部区域进行下采样来降低特征图的维度。这样的设计使得网络能够更好地捕捉到图像中的局部结构和细节信息,从而提高分类和识别的准确性。
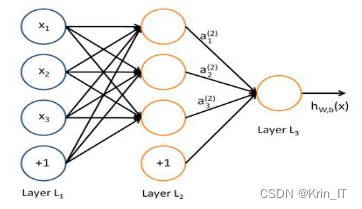
局部感受野(Local Receptive Field)是指神经元对输入数据中的局部区域进行感知和响应的范围。在视觉系统中,神经元的感受野是指其在感知过程中所接收到的视觉输入的局部区域。局部感受野的重要性体现在信息的传递和浓缩过程中。神经网络的层级结构中,低层的神经元对输入数据的局部感受野进行处理和提取特征,将这些局部特征传递给高层神经元,逐渐形成对更高级别的特征和整体信息的感知。这种逐层传递和浓缩的过程使得网络能够逐渐学习和提取出物体的层次性特征。
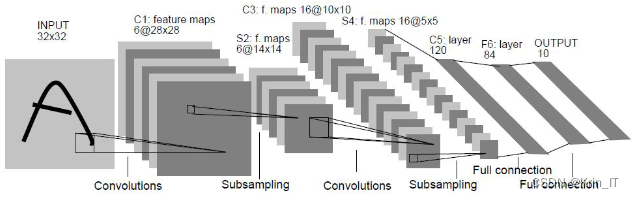
LeNet是一种经典的卷积神经网络结构是第一个成功应用于手写数字识别任务的卷积神经网络,为后来的深度学习研究奠定了基础。LeNet网络结构包含了卷积层、池化层和全连接层,通过层层堆叠和组合这些层来实现图像的特征提取和分类。
2.2 SMOTE 算法
SMOTE是一种用于处理类别不平衡问题的合成过采样算法。在机器学习中,类别不平衡指的是训练数据中不同类别的样本数量差异较大,这可能导致模型对少数类别的学习效果较差。SMOTE算法通过生成合成样本来增加少数类别的样本数量,从而平衡不同类别之间的样本分布。它的基本思想是对于少数类别中的每个样本,通过在其最近邻样本之间进行插值,生成一些新的合成样本。具体步骤如下:
- 对于少数类别中的每个样本,计算其k个最近邻样本(通常选择k=5或10)。
- 从k个最近邻样本中随机选择一个样本,并计算其与原始样本之间的差值。
- 基于差值,生成一个新的合成样本,即在原始样本和最近邻样本之间进行插值。
- 重复步骤2和3,直到生成所需数量的合成样本。
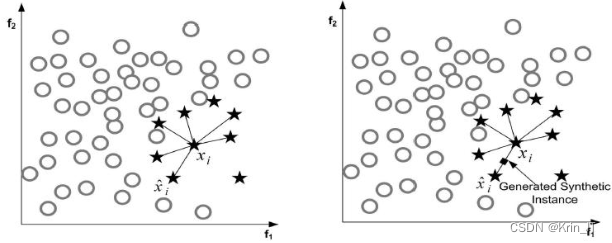
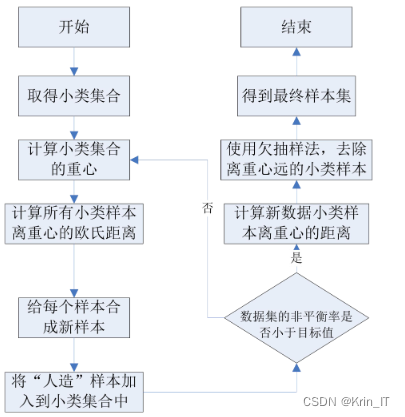
改进后的算法围绕少数类重心产生样本,首先计算小类集合的重心,然后遍历每个小类样本,计算其与重心的欧氏距离。接着使用SMOTE算法在小类中生成新样本,并将这些"人造"样本添加到小类集合中。算法会计算数据集的非平衡率是否小于预定的阈值,根据结果判断是否继续添加样本或使用欠抽样方法去除新样本,最终得到扩充后的数据集。C_SMOTE算法的设计旨在解决SMOTE算法中k值选择和边缘样本问题,提高数据集的平衡性和分类器的设计难度。
相关代码示例:
def generate_samples(X, y, minority_class_label, imbalance_threshold):
# 将数据集分为少数类和多数类
minority_X = X[y == minority_class_label]
majority_X = X[y != minority_class_label]
# 计算少数类集合的重心
minority_centroid = np.mean(minority_X, axis=0)
# 遍历每个少数类样本,计算其与重心的欧式距离
distances = np.linalg.norm(minority_X - minority_centroid, axis=1)
# 使用SMOTE算法在少数类中生成新样本
smote = SMOTE(sampling_strategy=imbalance_threshold)
synthetic_samples, _ = smote.fit_resample(minority_X, np.zeros(len(minority_X)))
# 将生成的"人造"样本添加到少数类集合中
augmented_minority_X = np.concatenate((minority_X, synthetic_samples), axis=0)
# 计算扩充后的数据集的非平衡率
augmented_X = np.concatenate((augmented_minority_X, majority_X), axis=0)
augmented_y = np.concatenate((np.ones(len(augmented_minority_X)) * minority_class_label, np.zeros(len(majority_X))), axis=0)
imbalance_ratio = len(augmented_minority_X) / len(majority_X)
三、检测的实现
3.1 数据集
现有的公开数据集并不能完全满足我的研究需求。为了提高系统的识别准确性和泛化能力,我决定自己收集并整理一套动物图像数据集。我通过网络搜索、动物园拍摄、公开数据集扩充等多种途径,收集了大量不同种类、不同姿态、不同环境下的动物图像。然后对这些图像进行了预处理、标注和分类,构建了一个包含丰富动物种类和样本的数据集。这个数据集不仅覆盖了常见的动物种类,还包含了一些稀有和濒危动物的图像样本。通过这个自制的数据集进行训练和测试,我能够更准确地评估系统的性能并不断优化模型。我相信这个自制的数据集将为动物识别领域的研究提供有力的支持,并为该领域的发展做出积极贡献。

3.2 实验环境搭建
应用开发使用的是Android Studio 2.0 Beta 5作为开发IDE,测试环境为小米MI 6手机。类别输出放置在名为synset_words.txt的文档中。在应用开发中,我们考虑到不同移动终端在硬件设备上的差异性。为了充分利用移动终端的性能,我们首先对安装的移动终端进行判断,确定是否具有GPU图形处理器。如果移动终端具有GPU功能,我们将开启GPU加速网络的计算;否则,我们将使用CPU进行网络的计算。
3.3 实验及结果分析
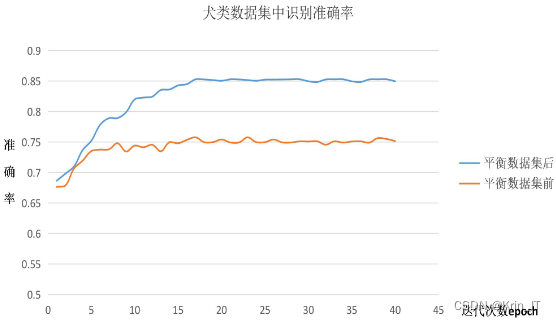
数据集经过边缘增强SMOTE算法处理后,包括23类台湾海域的鱼类图片,每类图片数量为5000张。数据集被划分为4000张训练集和1000张测试集。实验的目的是找到在这个数据集上表现最佳的训练参数,以获得更好的模型性能和准确性。
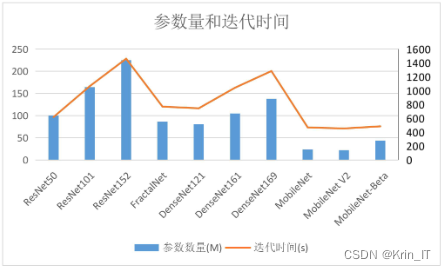
网络参数量和迭代时间的比较直方图可以提供有关不同网络模型的信息。这样的直方图可以对比和分析不同模型的规模和训练效率,从而帮助研究人员和从业者选择适合特定任务的网络模型。网络参数量是指模型中需要学习的可调整参数的数量。通常情况下,参数量越多,模型的容量越大,可以更好地拟合训练数据,但也增加了模型的复杂度和计算资源的需求。迭代时间是指训练模型所需的时间。它受到多个因素的影响,包括网络结构、数据集大小、硬件设备等。通过比较不同模型的迭代时间,可以了解模型的训练效率和速度。

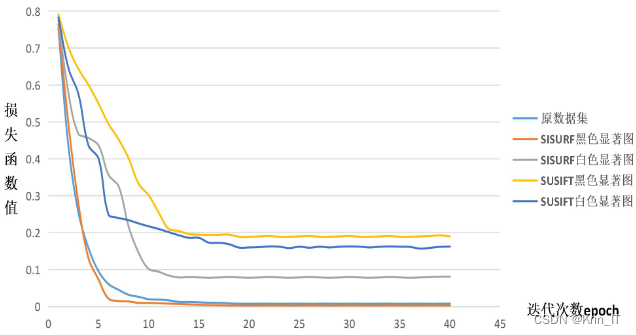
SISURF特征显著图能够突出图像中最具区分度和重要性的特征区域,例如目标对象或关键结构。通过预训练网络使用这些显著图,模型可以更加专注于学习这些关键特征,从而提高分类或识别的准确性。
相关代码如下:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
train_images, train_labels = load_train_data()
test_images, test_labels = load_test_data()
train_images = preprocess(train_images)
test_images = preprocess(test_images)
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('Test accuracy:', test_acc)
predictions = model.predict(test_images)
实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/136050411
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。