
1.文章信息
本次介绍的文章是发表在EUSIPCO 2021的一篇基于计算机视觉的火灾检测文章。
2.摘要
当今世界面临的环境危机是对人类的真正挑战。对人类和自然的一个显著危害是森林火灾的数量不断增加。由于传感器和技术以及计算机视觉算法的快速发展,提出了新的火灾探测方法。然而,这些方法面临着一些需要精确解决的限制,如类火灾物体的存在、高误报率、小尺寸火灾物体的检测和高推断时间。基于视觉的火灾分析的一个重要步骤是火灾像素的分割。因此,在本文提出了一种新的架构,将YOLOv5和U-net架构相结合,用于火灾检测和分割。使用野火数据集和类火目标图像,实验结果证明,该结构在森林火灾检测中是可靠的,不会出现误报。
3.介绍
森林火灾是当今威胁人类和环境的最危险和最具挑战性的自然灾害之一。不受控制的森林植被会造成巨大的破坏,对人类财产和植被区域造成灾难性影响。全球每年有超过3.5亿公顷的森林火灾发生。为了避免这种危险的灾难,在早期阶段探测和监测森林火灾的系统非常重要。最早的火灾探测系统使用多种传感器来探测火灾,如气体探测器、烟雾探测器、火焰探测器和温度探测器,但这些技术在森林或荒地火灾探测中并不有效。事实上,它们的覆盖范围较小,并且不会实时响应。为了克服这些限制,视觉传感器(嵌入式或固定式)最适用于高精度、高覆盖面积和误差较小的火灾探测。多年来,研究人员提出了许多技术,使他们能够利用图像处理和计算机视觉方法高精度地检测和分割火灾。首先,火的颜色特征被广泛用于区分火。这些技术将图像转换为另一个颜色空间,如YCbCr或YUV,然后通过将像素值与一些阈值进行比较,将其像素分为火或非火。然而,这些方法受到识别图像中火灾特征的复杂性的限制。机器学习技术也被用来提高火灾探测系统的可靠性。使用了许多模型,如SVM和神经网络。近年来,由于深度学习(DL)方法在检测和识别目标方面的优异性能,人们开始研究它来检测和定位森林火灾。深度学习技术在很大程度上帮助研究人员提取最能代表待描述火灾的相关特征。事实上,这些模型已成功应用于多个领域,如图像分类、自动驾驶汽车、语音识别、行人检测、人脸识别、癌症检测等。对于所有这些应用,DL证明了其在检测和分割不同类别对象方面的效率。对于检测任务,新引入的名为YOLOv5的算法证明了在准确性和推理时间之间的良好折衷。对于分割任务,U-Net在医学图像分割方面取得了优异的结果和性能。在本文提出了一种基于DL的新型火灾探测系统,该系统使用预先训练好的YOLOv5和U-Net模型依次串联。为此,首先将带有注释的原始火灾图像提供给YOLOv5模型,然后使用通过检测获得的边界框裁剪火灾类别。最后,使用原始图像及其注释将这些裁剪后的图像输入到经过训练的U-Net模型中,并获得在同一图像中具有边界线的分割图像。更具体地说,本文有两个主要贡献。首先,文章提出了一种新的架构,能够以操作和时间高效的方式检测和分割火灾,旨在克服现有技术的局限性。其次,本文的模型在大小火灾物体上表现出了很高的性能,并且能够区分火灾和类火灾物体。
最近,许多基于区域的CNN被用于检测和定位图像/视频中的火灾。有学者使用更快的R-CNN实时检测和定位火灾。使用12620幅图像(森林火灾、蜡烛火灾、煤气灶火灾)的数据集,在检测精度和精确度方面取得了良好的性能,但由于该解决方案响应时间长,因此不适合实时应用。同样,有学者利用另一种基于区域的CNN模型Yolo从视频中检测火灾。在准确度、精密度和响应时间方面都取得了良好的效果,与更快的R-CNN相比,响应速度更快,超过3倍。有学者使用Yolo v3探索了如何使用航空图像检测火灾。识别率达到83%,速度达到每秒3.2帧,证明了该模型在无人机森林火灾探测中的可靠性。还有学者使用了各种基于区域的CNN模型(Yolo、SSD和更快的R-CNN)来识别森林。SSD模型利用多分辨率特征地图对不同尺度的目标进行定位,在速度和精度上显示了其实时检测森林火灾的效率。
4.模型
提出的火灾检测体系结构基于两种深度学习模型的结合,以实现对野火的检测和定位。文章的整体框架将图像作为输入并输出局部火焰。模型的第一步是YOLOv5,第二步是U-Net。在所提出的体系结构中,这两个网络是集成的。首先,将森林火灾的RGB彩色图像反馈给网络,由YOLOv5对图像进行处理,得到火灾区域周围的边界框。一旦得到这些,裁剪层将应用于从YOLOv5结果获得的图像,以便仅获得图像中受边界框限制的部分。然后,将这些裁剪后的图像输入U-Net,以确认火焰的存在并检测火灾的精确位置。结果是一个二进制掩码,表示图像中的火灾像素。最后,获取得到的边界线,并将其放在原始图像上。值得一提的是,文章离线训练U-Net,然后使用训练后的权重分割裁剪的图像。模型如下图所示。文章提出的方法的新颖之处在于,它不仅可以检测火灾所在的包围盒,还可以检测火灾的形状。
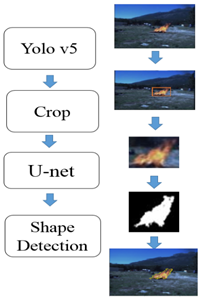
A. YOLOv5
YOLOv5是一个单阶段物体检测器,它有三个重要部分:
•模型主干:这一部分用于从给定的输入图像中提取重要特征。交叉阶段部分网络(CSPN)用作主干,从输入的火灾图像中提取丰富的信息特征
•模型颈部:它主要由生成特征金字塔组成。使用特征金字塔可以很好地概括对象缩放。它有助于检测具有不同比例和大小的相同对象。这有助于在看不见的数据上表现良好
•模型头:这是最终检测部分。YOLO在特性上使用锚定框,并开发最终输出,即具有类分数的边界框。
B.U-Net
U-Net网络是一种深度卷积网络,已成功应用于医学图像分割。与传统DL模型不同,传统DL模型需要大量数据,而UNet仍然可以使用少量数据进行训练。U-Net是一个两阶段的深度学习模型。其体系结构包括编码器模型和解码器模型。它包含九个区块,每个阶段四个区块和一个共享区块。每个块由两个2D卷积层组成,使用33核和校正的线性单元激活函数,然后是2D最大池层。在每个下采样阶段,特征通道的数量是重复的。最后,一个11层构造一个二进制掩码。该模型使用一组输入的火灾图像及其相应的二进制掩码。在训练过程中,基于二进制掩码作为所需输出,该模型学习如何将图像的每个像素分类到不同的对象标签中。根据任务,文章创建了两个类,即fire和non-fire。
5.实验分析
A. 数据准备
对于火灾探测问题,没有基准数据集,这使得在该领域对DL方法进行比较研究有点关键。文章创建了数据集,其中包含科西嘉火灾数据集和类火灾对象图像。科西嘉火灾数据库是从世界上不同研究团队收集的森林火灾图像数据集。它包括在气候条件、燃烧植被类型、火灾距离和火灾亮度等多种条件下,在不同地区采集的野火图像序列。为了使数据集多样化并提高模型区分火和类火对象的能力,文章在科西嘉火灾数据库中添加了大量图像,这些图像包括各种分辨率的类火彩色对象,如灯光、日出、日落和消防服。新创建的数据集包含大约1300幅图像。它们包括具有不同分辨率和大小的火图像、非火图像和类火图像。

上图描绘了科西嘉岛火灾数据集和类火对象图像的示例,其中包含具有日落、日出和灯光等火灾特征的对象。
B. 数据增强
使用数据扩充技术来提高模型的性能并避免过度拟合非常重要。它主要包括在图像上应用变换,如几何变换(旋转、缩放、填充、裁剪、图像平移和翻转平移)、光度变换(亮度、对比度和剪切)、图像遮挡技术(合成)和马赛克数据增强,这些技术结合了单个图像的多种变换。针对问题,文章选择了基于火焰特性的数据增强技术。例如,文章没有考虑使用颜色空间调整来保持火的颜色信息的技术。此外,排除了旋转,因为在现实生活中找不到90度旋转的火。此外,水平翻转火灾图像是合理的,但垂直翻转则不合理。就像在现实世界中一样,不会看到很多火焰倒转的图像。总之,文章使用了图像平移、图像缩放、马赛克、混合和水平翻转作为增强技术。
C. 训练
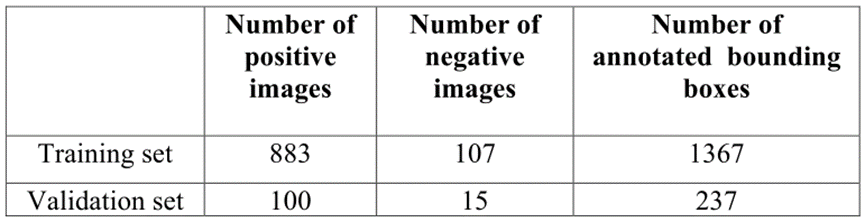
在带有GPU NVIDIA Tesla P100 16 GB的机器上使用Pytorch框架对这两个模型进行了培训。此外,文章将数据集分为两个子集,如下表所示。
1)检测训练
为了训练YOLOv5,输入数据是PNG图像和TXT文件,其中包含注释对象的详细信息。文章的训练是使用PyTorch的二元交叉熵和Logits损失函数进行的,用于损失类概率和对象分数的计算,学习率设置为0.01,批量大小为8,历代数设置为300,图像大小设置为416x416或1024×1024。请注意,由于训练了小YOLO和大YOLO,训练时间会根据模型的不同而变化。
2)细节训练
为了训练U-Net,输入数据是PNG图像及其相应的二进制掩码。文章使用的损失(LS)是骰子系数(DC)和二进制交叉熵(BCE)的损失函数的组合,如下所示:
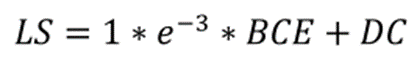
大小为256x256的图像用于不同的训练时期。学习率为0.0001,Adam作为优化器,批量大小为4。
D. 测试时间延长
测试时间扩充是另一种数据扩充方法。虽然数据扩充是在模型训练之前或训练期间进行的,但这一过程是在推理期间进行的。这是一种避免过度拟合和优化结果的简单而有效的方法。其思想是向同一模型显示同一图像的不同版本,获取不同的输出并提取检测到的边界框,然后合并结果。这是一种非常快速的方法,可以提高模型性能(输出的可信度),而不会浪费宝贵的数据扩充时间。
E. 评估指标
本工作中使用的评估指标分为检测指标和分割指标。
1) 火灾探测指标
召回率是正确分类的总相关结果百分比的值。
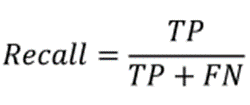
其中TP:真阳性,FN:假阴性。
MAP(平均精度)是AP的平均值。不同等级的AP值计算如下:
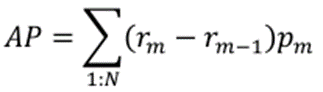
其中,r和p是在m等级阈值下的召回率和精度。
2) 火灾分割指标
骰子系数(DC):骰子系数是衡量两幅图像(预测图像和地面真实图像)相似性的统计指标。
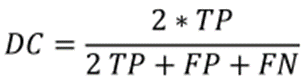
其中TP:真阳性,FP:假阳性,FN:假阴性。
准确率:是正确预测数与网络实现的总预测数之比。
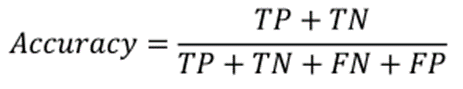
其中TP:真阳性,TN:真阴性,FP:假阳性,FN:假阴性。
F. 实验结果
1)检测结果
在下表中,文章展示了YOLOv5s(小型版本)和YOLOv5x(超大版本)在有无TTA的情况下的性能。
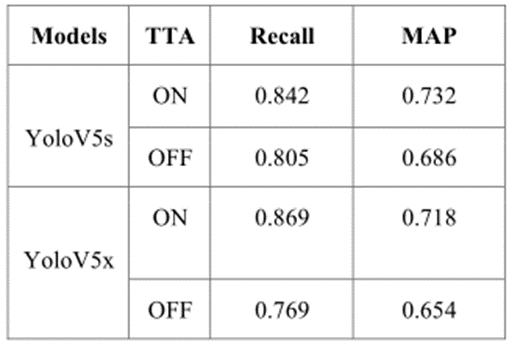
可以看到,YOLOv5的两个版本在使用TTA技术和数据增强技术进行火灾探测方面取得了巨大的成果。由于输入图像的分辨率很高,与YOLOv5s相比,YOLOv5 xlarge的效果最好。

在上图中,可以看到Yolov5准确地检测并定位了森林火灾,精确地说是小型火灾。因此,该模型克服了与日出和日落等类火对象的混淆。
2)细节结果
下表显示了文章模型的最佳得分。

可以看到,U-Net模型在分割森林火灾方面取得了很好的性能(dice系数为92%,准确率为99.6%)。应用于数据库的YOLO v3提供了96.8%的准确率。可以证明,U-Net的力量在于它的能力,它不仅能够确认森林火灾的存在,而且能够检测火焰的精确形状。在下图中,可以看到网络准确、精确地检测到火灾及其形状。通过将这两种体系结构相结合,实现了一种鲁棒而精确的森林火灾探测器,以解决森林火灾的检测和识别问题。

作为一个例子,可以在下图中看到,文章提出的模型在检测火灾像素和分割火灾表面,特别是小区域(中间的图)方面表现得非常好,并且它成功地克服了与类火灾对象的混淆(右图)。这些结果优于最先进的火灾探测技术。

6.结论
本文介绍了一种基于YOLOv5和U-net的森林火灾检测与分割新方法。使用科西嘉岛火灾数据集和各种类似火灾的物体图像,文章评估了提出的方法。实验结果表明,该方法能够在不同的采集条件下准确地检测森林火灾小火(含小火)。未来的工作方向为,引入一种基于CNN的烟雾/火灾探测方法,以便在没有虚假警报的情况下识别和定位火灾和烟雾。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!

版权归原作者 当交通遇上机器学习 所有, 如有侵权,请联系我们删除。