
1. 介绍
- 完全分布式和高可用是在分布式系统中常见的两种架构概念。
- 完全分布式(Fully Distributed)架构: 完全分布式架构是指在分布式系统中,每个节点都是相同的,没有单一节点负责所有的任务或数据。每个节点具有完整的功能和数据副本,可以处理请求并参与计算,存储和传输数据。这种架构通常用于大规模的分布式系统,例如Hadoop集群,其中每个节点都可以独立运行任务和存储数据,以提供高并发和容错能力。
- 高可用(High Availability)架构:高可用架构是指系统能够在面临硬件或软件故障时保持连续性和可用性。在高可用架构中,系统设计了冗余的组件和备用机制,以防止单点故障,并能够快速恢复。常见的高可用性技术和策略包括故障转移,自动切换,持久性存储和监控系统。高可用架构在关键业务系统和服务中十分重要,以确保系统的持续性和可用性,防止业务中断和数据丢失。
在实际应用中,可以将完全分布式和高可用架构结合起来,以构建具有高性能和高可用性的分布式系统。例如,一个完全分布式的Hadoop集群可以使用高可用技术来确保各个节点和关键组件的持续性和可用性,从而提供可靠的大数据处理和存储解决方案。
- Hadoop 3.x与Hadoop 2.x和Hadoop 1.x在架构和功能方面有一些区别:
- 架构升级:Hadoop 1.x采用了单点故障的架构,整个框架的稳定性和扩展性受到限制。Hadoop 2.x引入了YARN作为资源管理器,将资源管理和作业调度分离,架构更加灵活。而Hadoop 3.x在Hadoop 2.x的基础上进行了进一步的演进,提供了更好的可扩展性和高可用性。
- 高可用:Hadoop 1.x未提供内置的高可用性功能,需要依赖第三方工具来实现。Hadoop 2.x引入了HA NameNode来解决HDFS的单点故障问题。而Hadoop 3.x在HA NameNode的基础上引入了热故障切换(Hot Failover)和自动故障转移(Automatic Failover)功能,提供了更高级的高可用机制。
- 资源管理:Hadoop 1.x使用JobTracker来处理资源管理和作业调度,整个集群资源的分配比较简单。Hadoop 2.x引入了YARN作为资源管理器,将资源管理和作业调度分离开来,能够更好地支持多个应用程序共享集群资源。而Hadoop 3.x对YARN进行了一些改进和优化,提供了更高的资源利用率和性能。
- 存储层:Hadoop 2.x和Hadoop 3.x都支持HDFS作为分布式存储系统,但Hadoop 3.x引入了Hadoop Ozone来提供分布式对象存储的解决方案,适用于处理非结构化数据。
总的来说,Hadoop 3.x相对于之前的版本在架构升级、高可用性、资源管理和存储层等方面进行了很多改进和优化,提供了更好的性能和可靠性,更适合处理大规模数据和复杂的数据处理任务。
Hadoop 3.x是一个开源的分布式存储和处理大规模数据的框架,它的架构由以下几个核心组件组成:
- HDFS(Hadoop Distributed File System):HDFS是Hadoop的分布式文件系统,它用于存储和管理海量数据。它将数据划分成多个块,并将这些块分布在集群中的不同节点上,以实现数据的高可靠性和可扩展性。
- YARN(Yet Another Resource Negotiator):YARN是Hadoop的集群资源管理系统,负责分配和管理集群中的计算资源。它允许多个应用程序共享集群资源,并根据应用程序的需求动态分配资源。
- MapReduce:MapReduce是一种用于处理大规模数据的计算模型。它通过将任务拆分为多个Map和Reduce阶段,实现了数据的并行处理和分布式计算。Map阶段将输入数据映射为键值对,而Reduce阶段对这些键值对进行聚合和计算。
- Hadoop Common:Hadoop Common是Hadoop框架的基础模块,包含了许多共享的工具和库,用于支持Hadoop的其他组件。它提供了一些通用的功能,如安全认证、日志记录和网络通信等。
- Hadoop Ozone:Hadoop Ozone是Hadoop 3.x引入的新组件,它提供了一种分布式对象存储的解决方案。它可以在Hadoop集群上提供可靠的、高性能的对象存储服务,适用于处理大规模的非结构化数据。
这些核心组件共同工作,使Hadoop 3.x能够以高可靠性和可扩展性处理和存储大规模数据。通过将数据分布在集群中的多个节点上,并利用分布式计算模型,Hadoop 3.x能够快速处理海量数据,并实现数据的高可用和容错性。
- 操作系统:
- Ubuntu18
- 软件:
- jdk1.8
- hadoop-3.1.0
- zookeeper3.8.2
- 四台服务器:
ubuntu01、ubuntu02、ubuntu03、ubuntu04
2. 基础环境
- 关闭防火墙
- 修改主机名,主机名和ip地址映射
- ssh免密登录
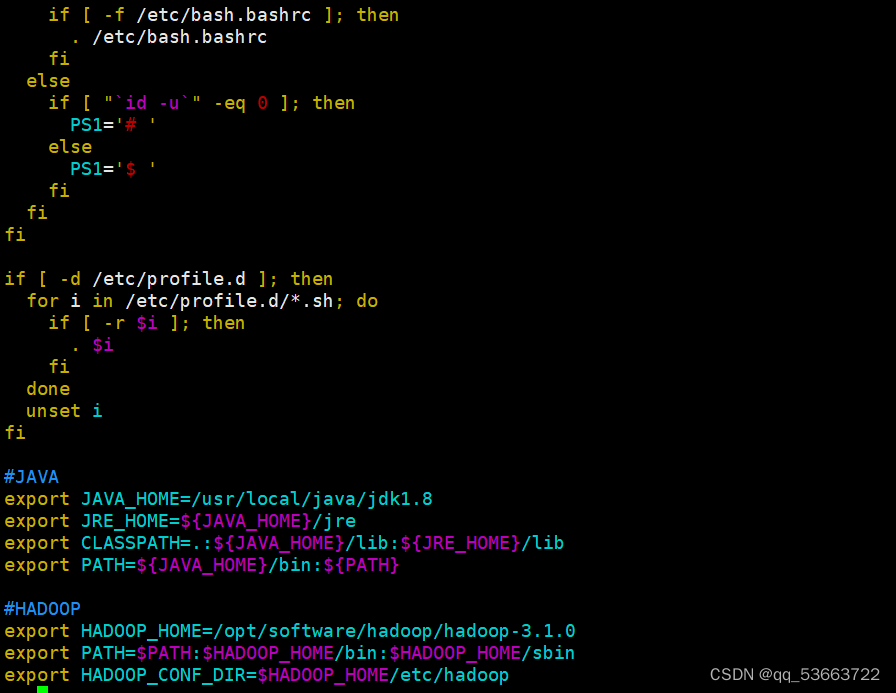
- 安装jdk
2.1 关闭防火墙
ufw stop
或
sudo systemctl stop ufw.service
sudo systemctl disable ufw.service
2.2 修改主机名和主机映射
vi /etc/hostname
vi /etc/hosts
2.3 免密登录
- 三台机器分别生成各自的公钥、私钥
ssh-keygen -t rsa
- 检查公钥生成是否正确
less /root/.ssh/id_rsa.pub
- 拷贝三台机器的公钥到第一台机器
ssh-copy-id node01
- 检查拷贝情况
less /root/.ssh/authorized_keys
或cat ~/.ssh/authorized_keys
- 复制node01的认证到其他机器
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
2.4 安装jdk
下载包地址:
https://www.oracle.com/java/technologies/downloads/archive/
分别四台服务器:ubuntu01、ubuntu02、ubuntu03、ubuntu04都装上
- 创建文件目录和上传jdk包
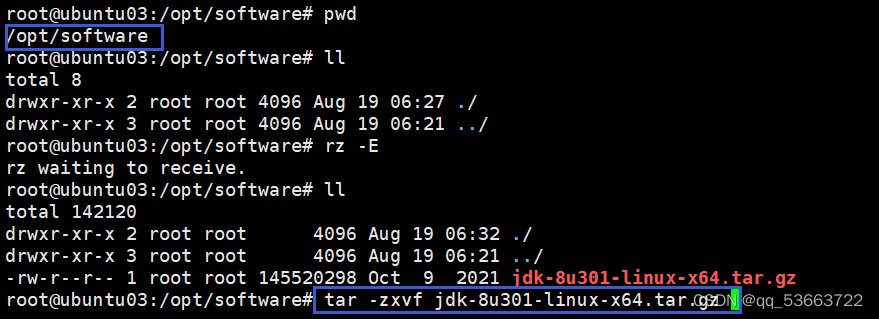
- 解压jdk包并重命名
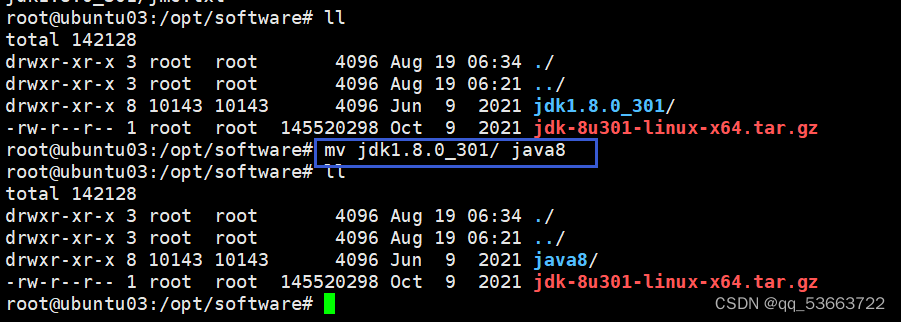
- 配置环境变量
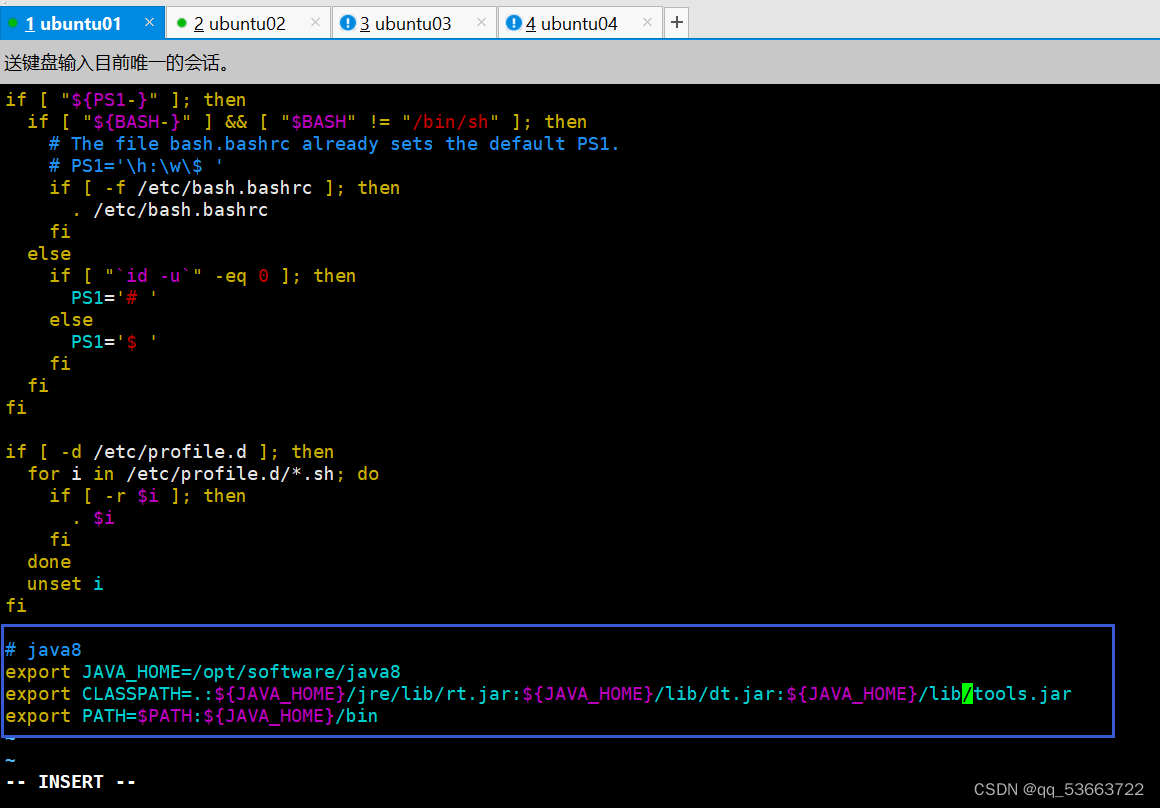
- 更新环境变量和查看是否安装成功
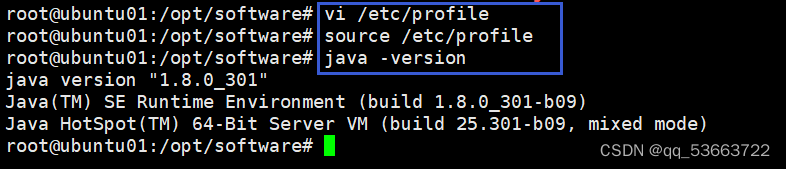
3. 搭建完全分布式
3.1 下载包地址
hadoop包下载地址
Apache Hadoophttps://hadoop.apache.org/releases.html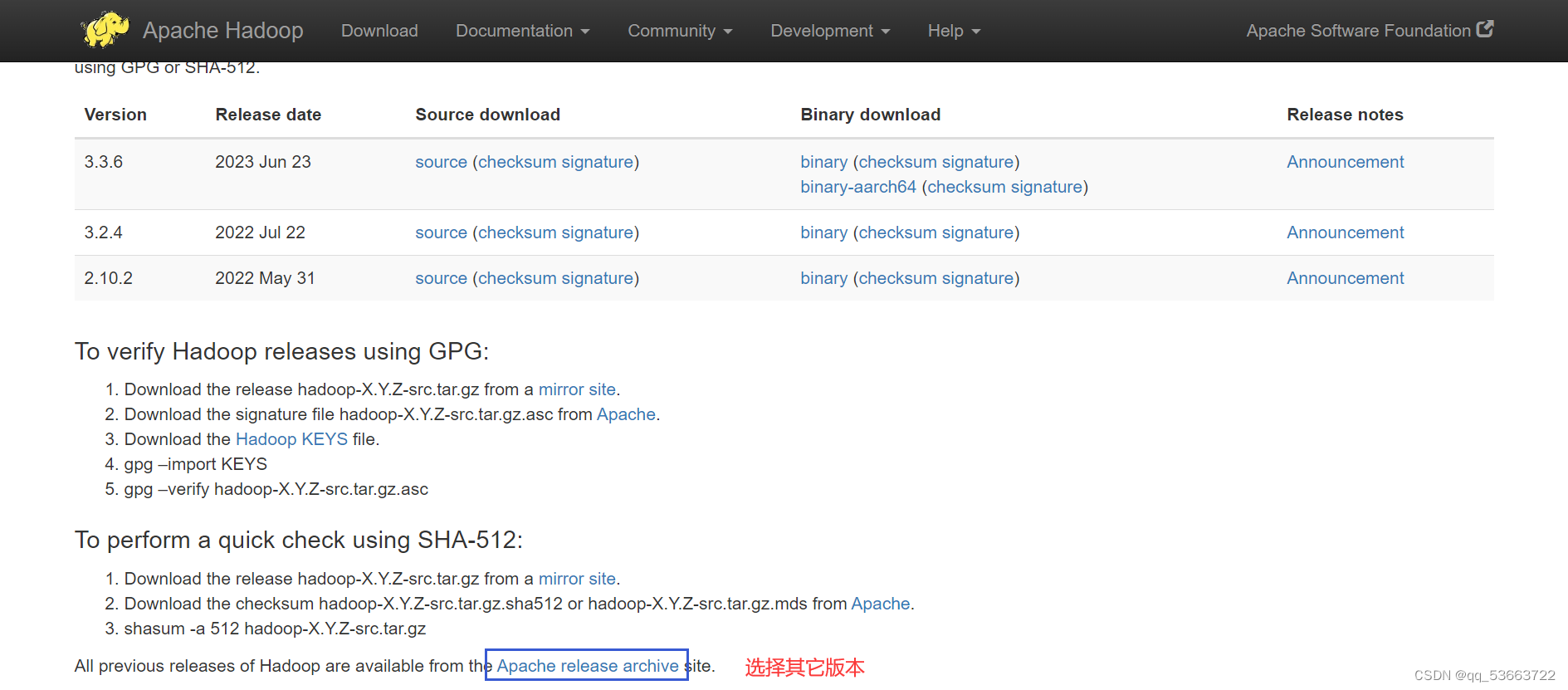
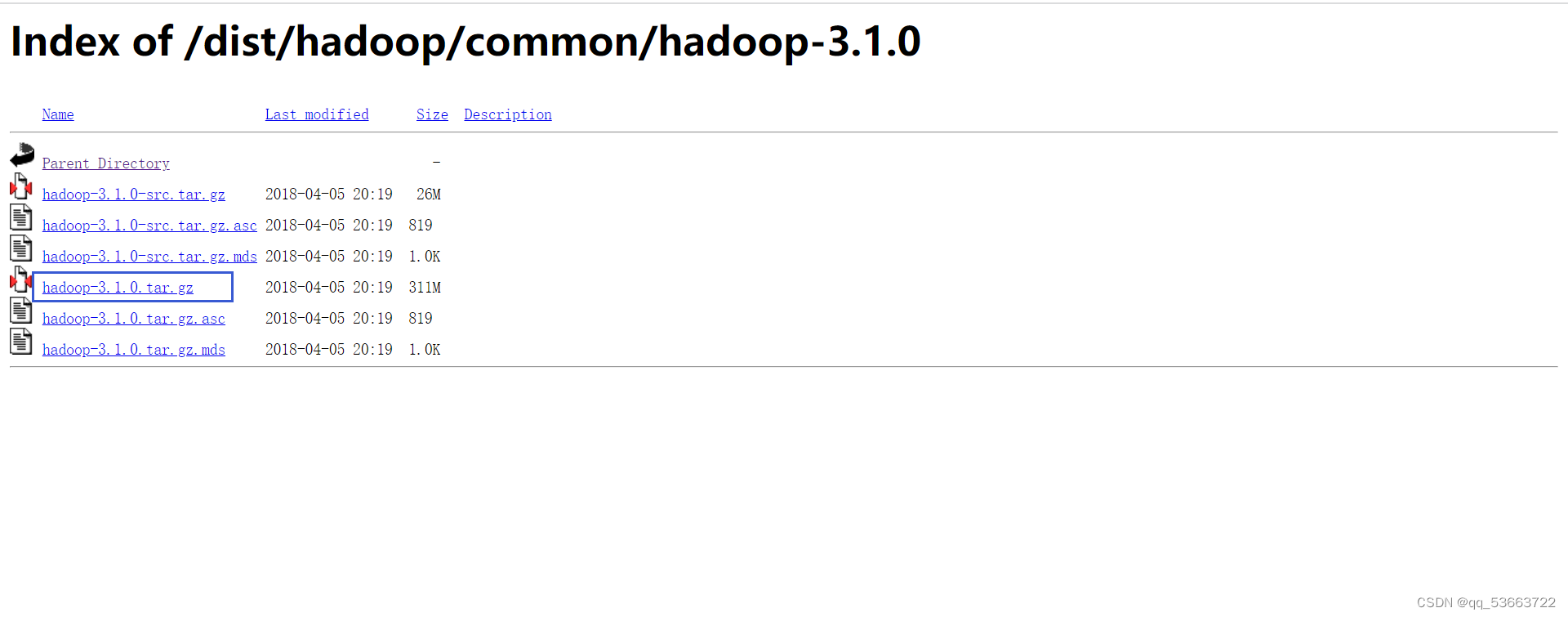
3.2 上传并解压
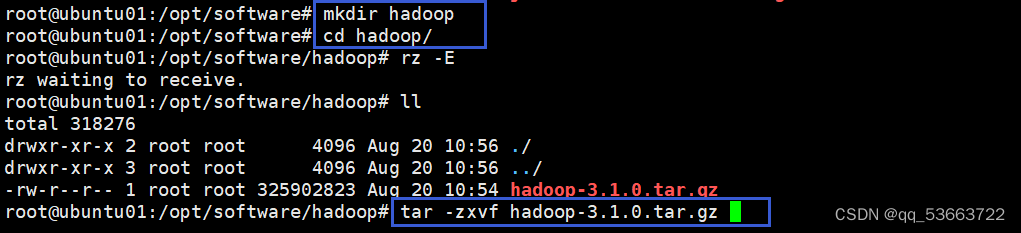
- 把下载好的包上传到/opt/software/hadoop,没有的需要提前创建,然后进行解压
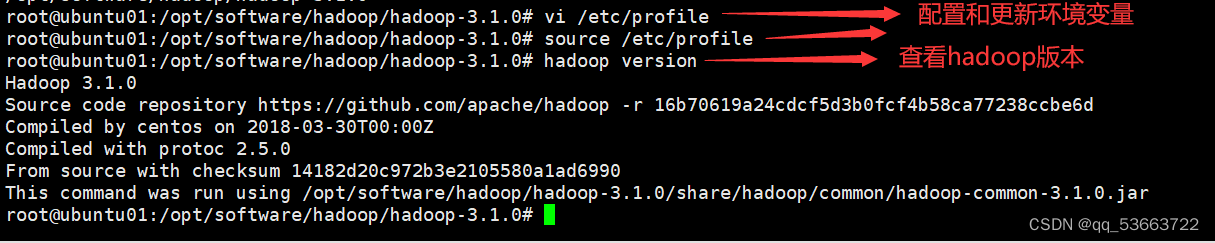
- 配置环境变量

3.3 创建目录
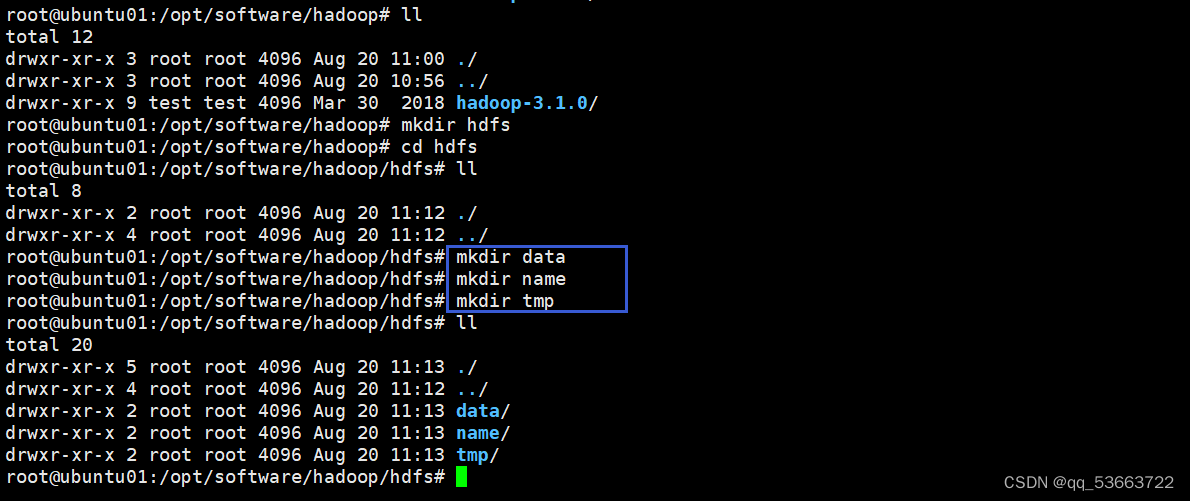
cd /opt/software/hadxuoop/hdfs/
mkdir hdfs
cd hdfs
mkdir data
mkdir name
mkdir tmp
3.4 修改配置文件
需要修改的配置文件都有:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers、hadoop-env.sh
cd /opt/software/hadoop/hadoop-3.1.0/etc/hadoop
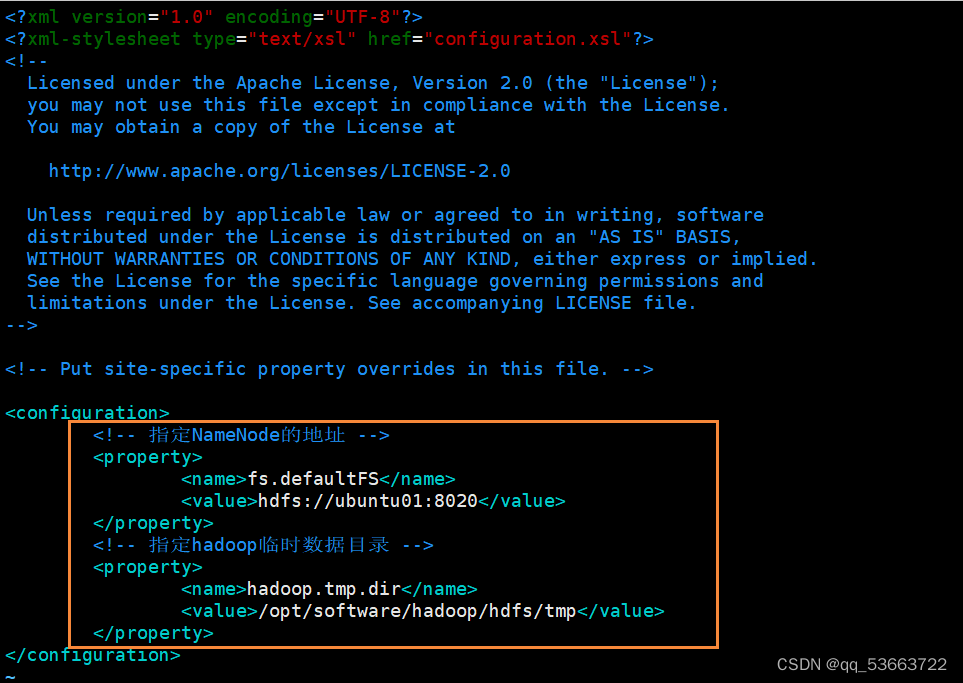
3.4.1 core.site.xml
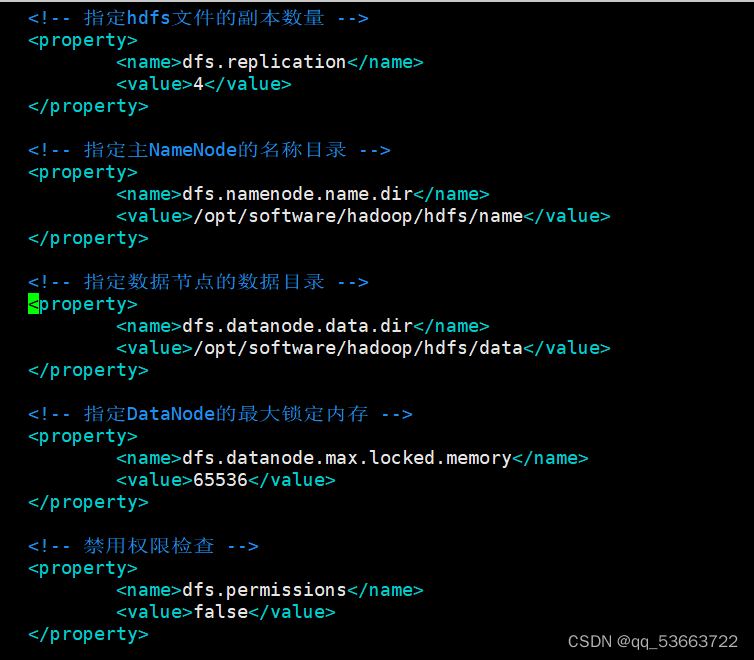
3.4.2 hdfs-site.xml
3.4.3 yarn-site.xml
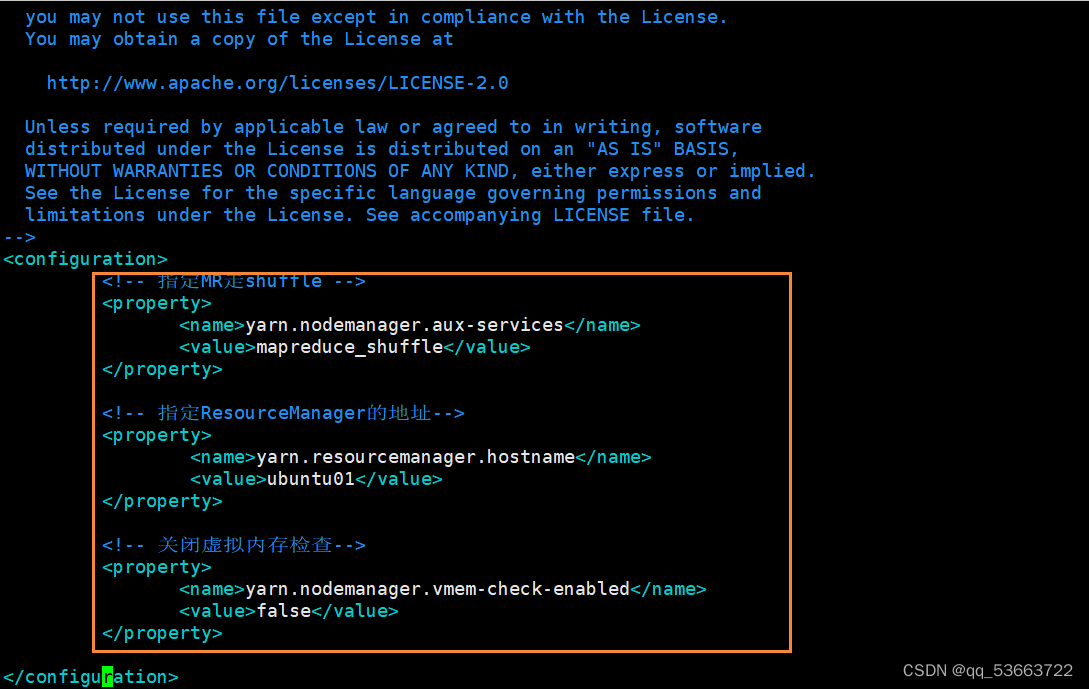
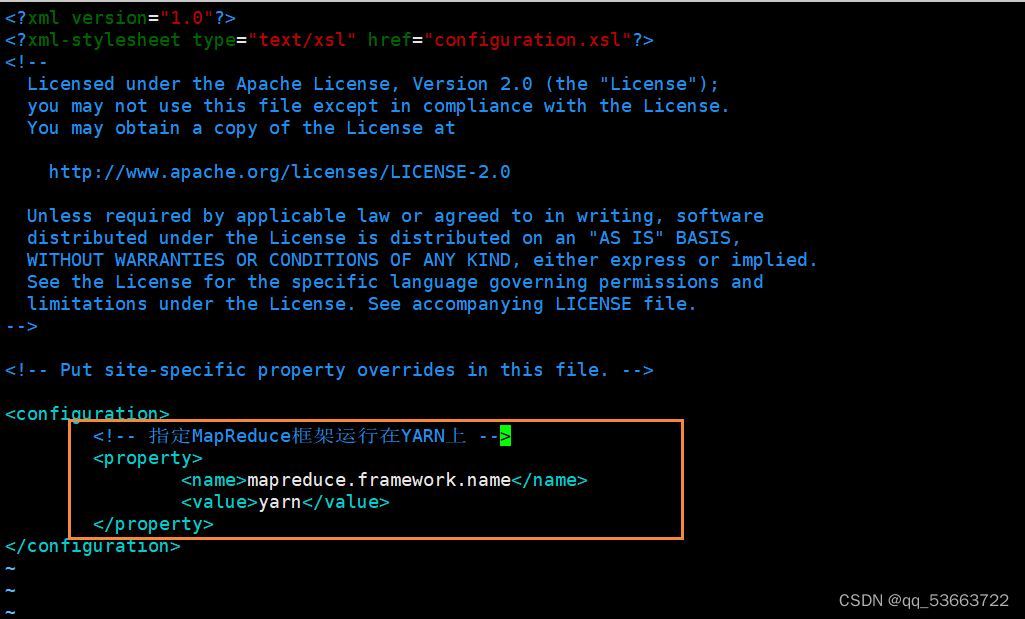
3.4.4 mapred-site.xml
3.4.5 workers

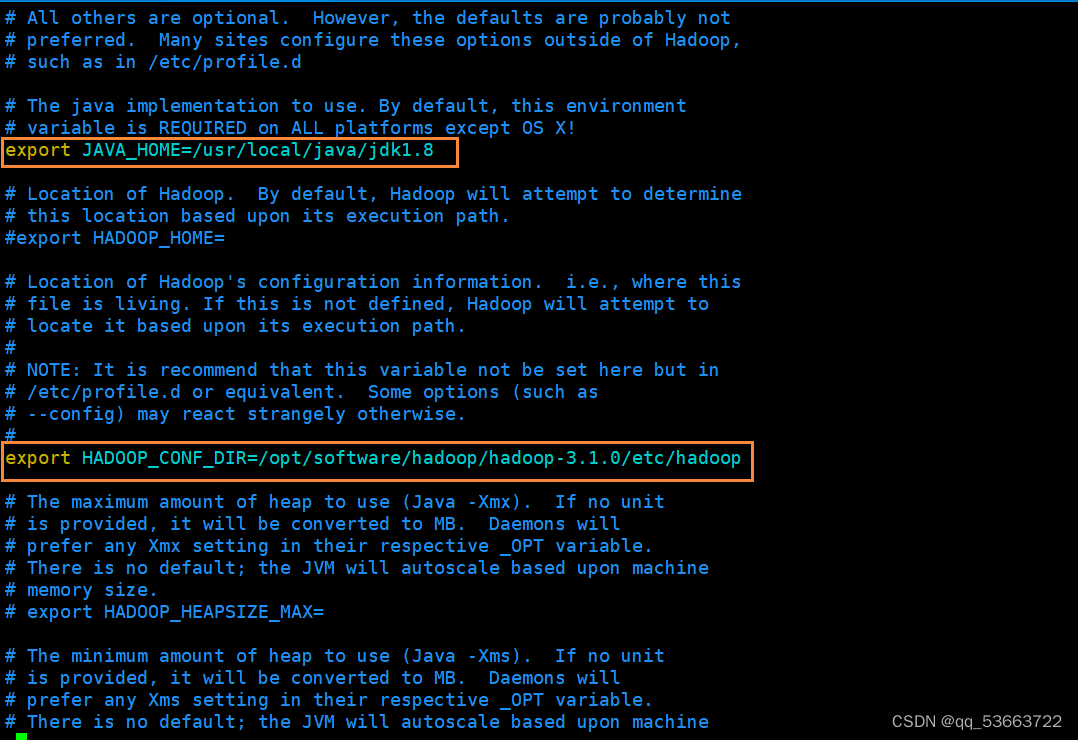
3.4.6 hadoop-env.sh
修改内容
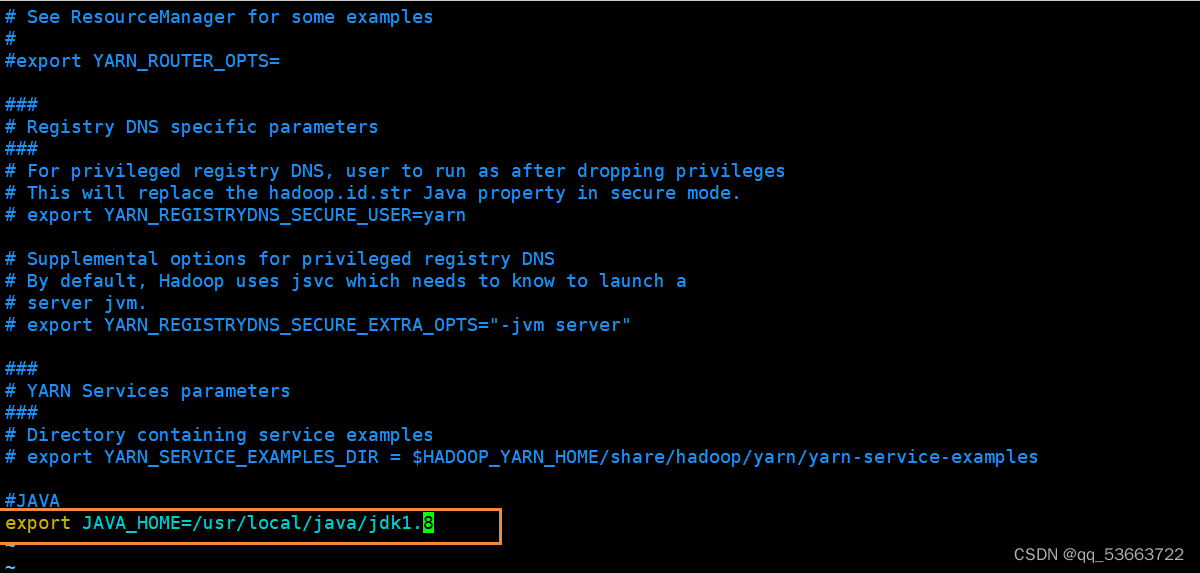
3.4 7 yarn.env.sh
添加以下配置
export JAVA_HOME=/usr/local/java/jdk1.8

4. 分发配置
- 把ubuntu01的hadoop配置使用scp命令发送到ubuntu02/ubuntu03/ubuntu04
cd /opt/software/
scp -r hadoop/ ubuntu01:$PWD
scp -r hadoop/ ubuntu02:$PWD
scp -r hadoop/ ubuntu03:$PWD
scp -r hadoop/ ubuntu04:$PWD

- 其它三台也需要配置环境变量,步骤同上
5. 启动集群
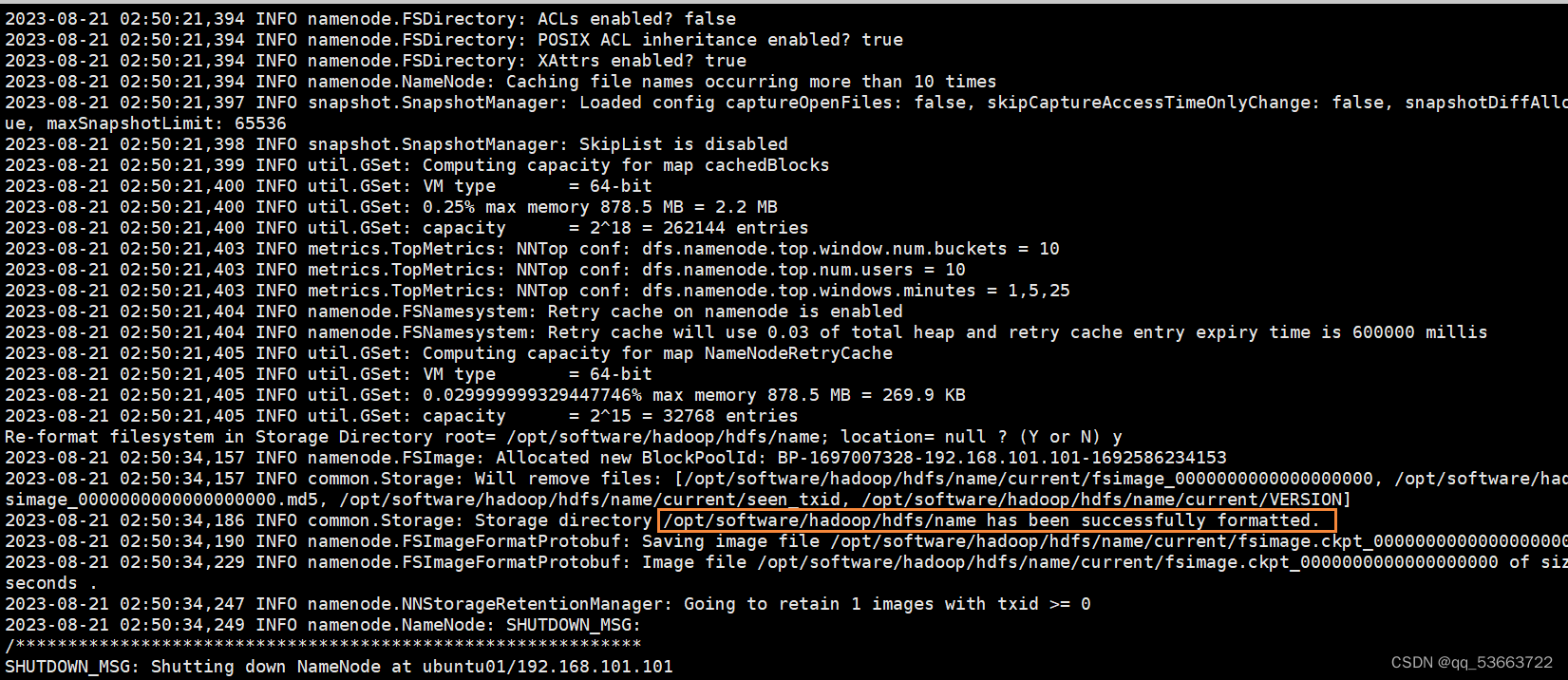
- 在ubuntu01上格式化
hdfs namenode -format
- 在ubuntu01上启动
start-dfs.sh

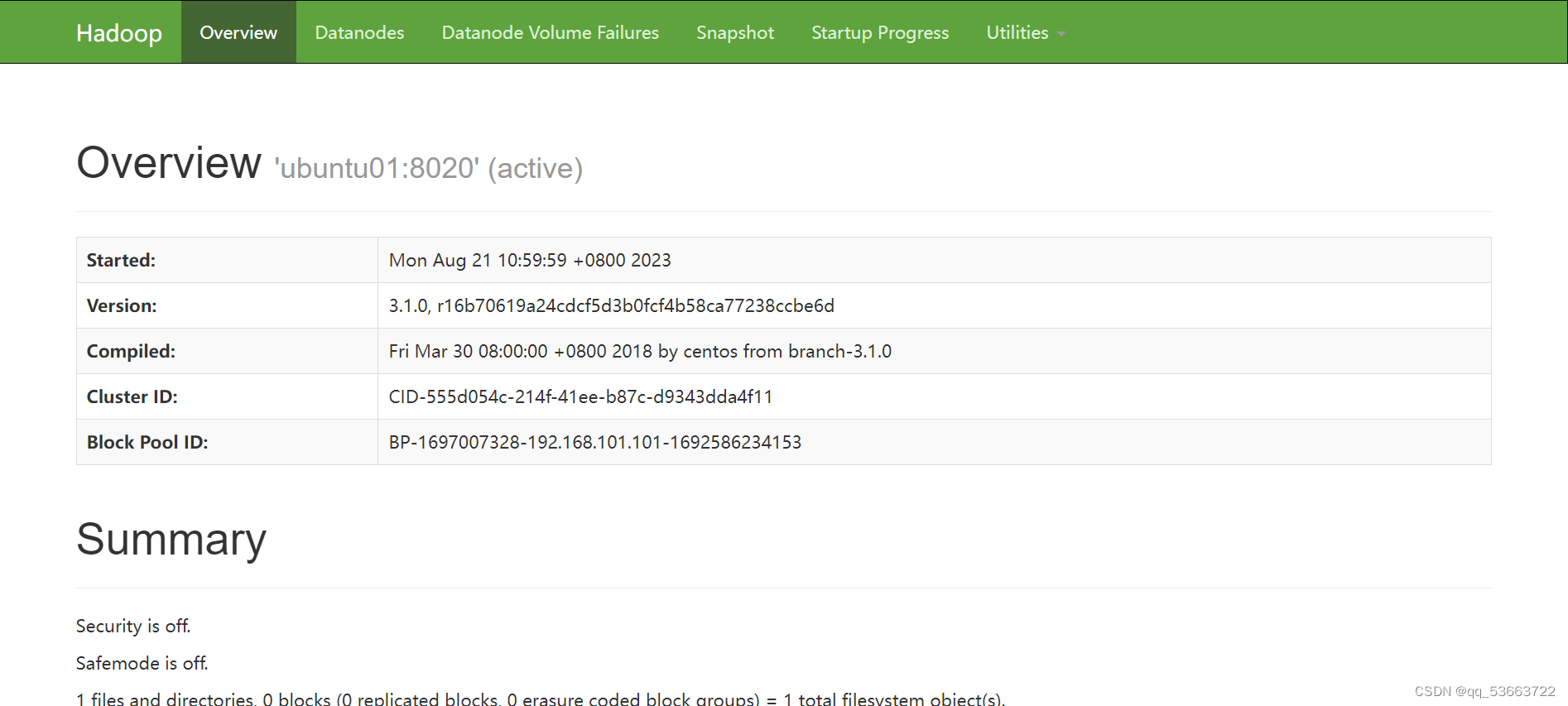
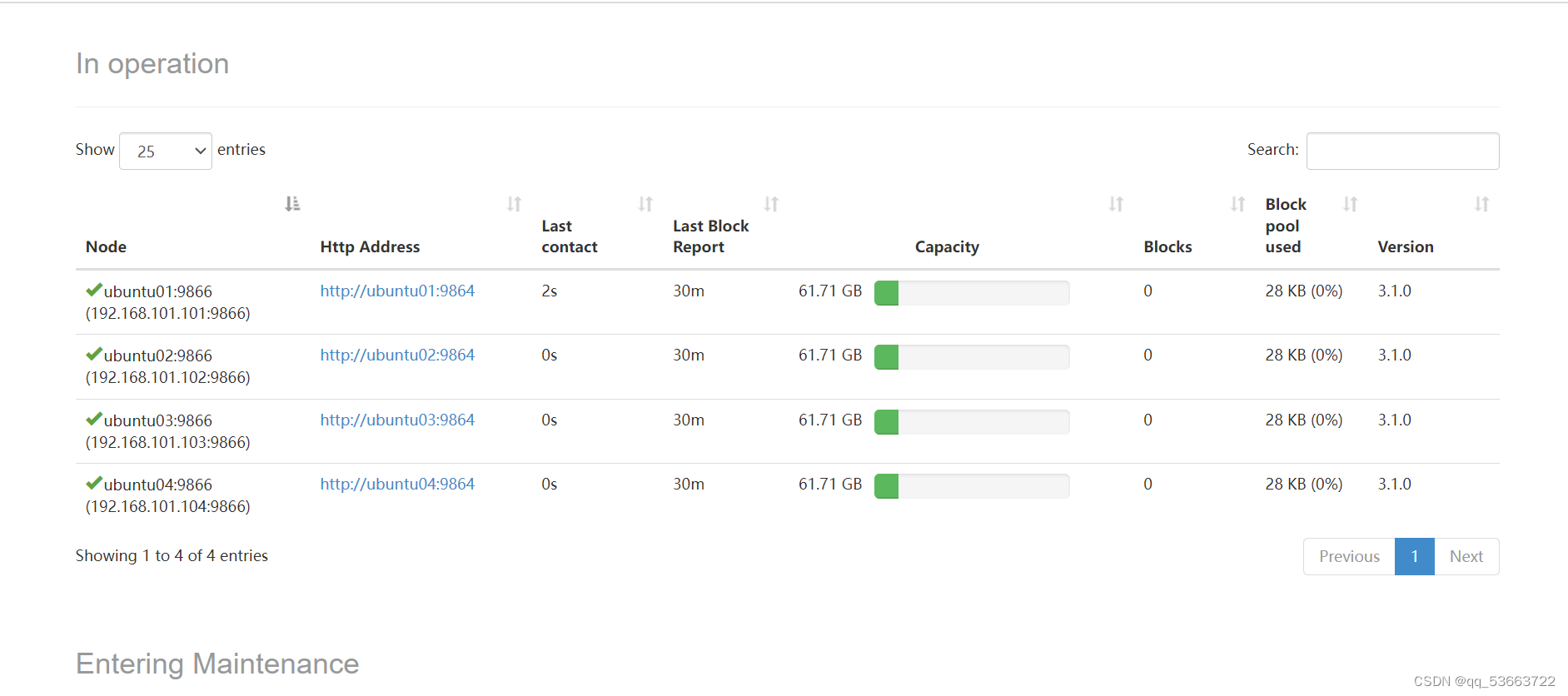
- 访问ubuntu01的web端
http://192.168.101.101:9870/
- 启动yarn
start-yarn.sh

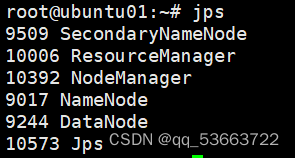
- 查看进程:jps
ubuntu01上
ubuntu02、ubuntu03、ubuntu04

4. 搭建高可用
4.1 安装zookeeper
4.1.1 下载并解压包
- 下载zookeeper地址
Apache ZooKeeperhttps://zookeeper.apache.org/releases.html
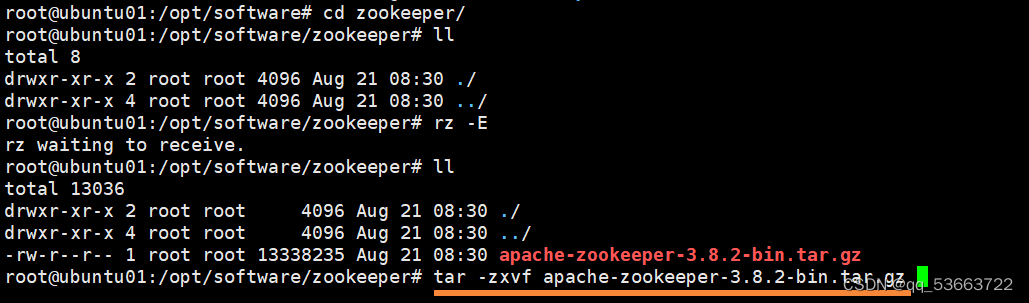
- 上传压缩包并进行解压
cd /opt/software/zookeeper
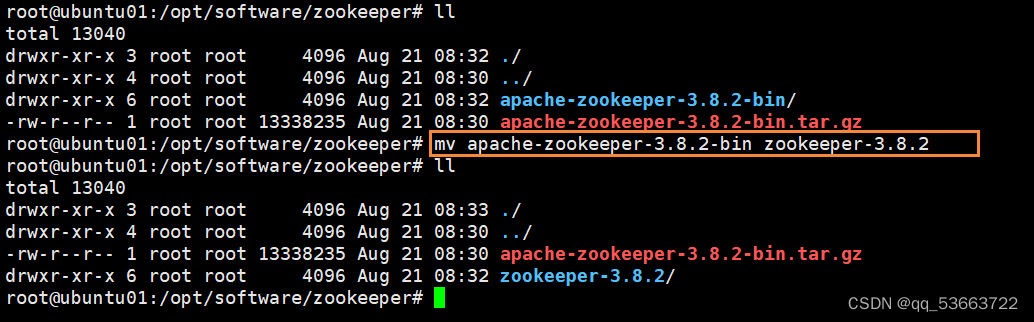
- 修改解压后的目录名称
4.1.2 配置环境变量
vi /etc/profile

- 更新环境变量
source /etc/profile
4.1.3 修改配置文件
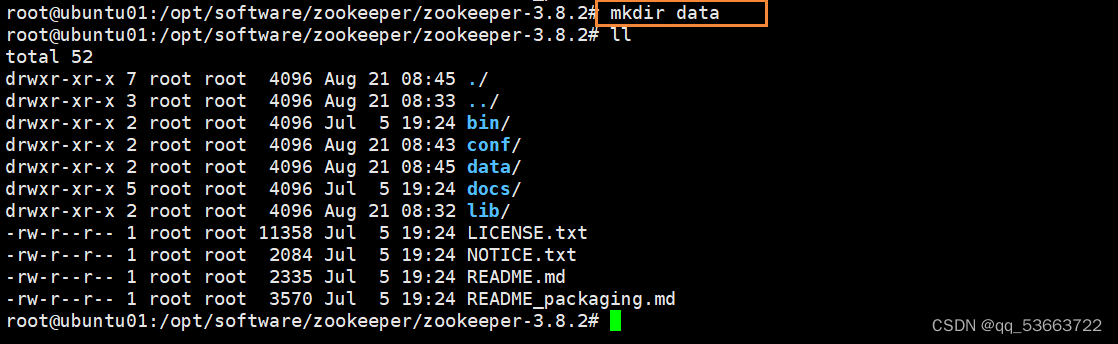
在/opt/software/zookeeper/zookeeper-3.8.2目录下创建目录data用来存放ZK数据,此路径需要在zoo.cfg配置 文件里面使用
4.1.4 配置zoo.cfg
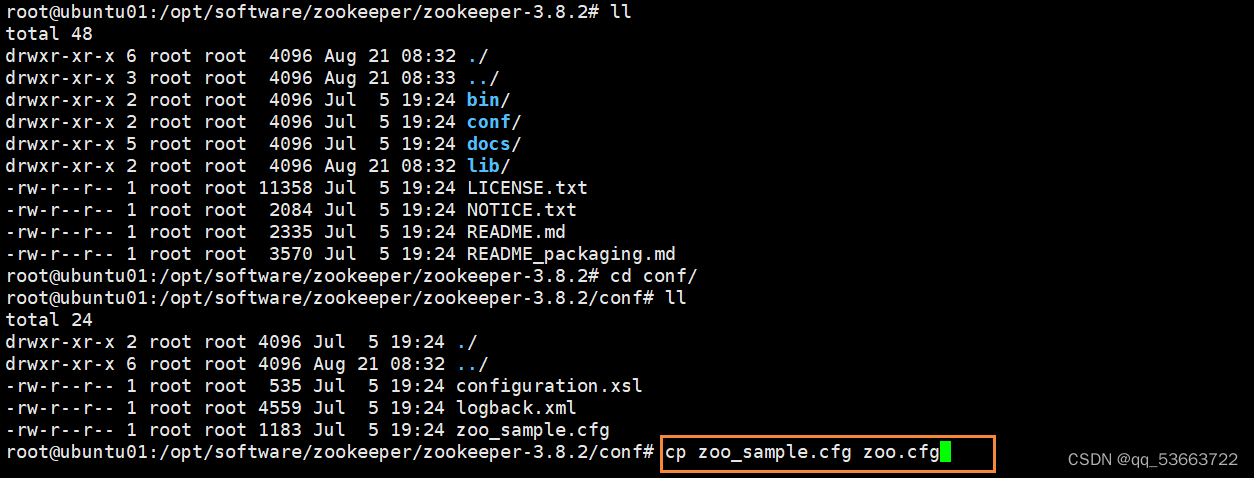
- conf目录下没有zoo.cfg,需要复制出来
cp zoo_sample.cfg zoo.cfg
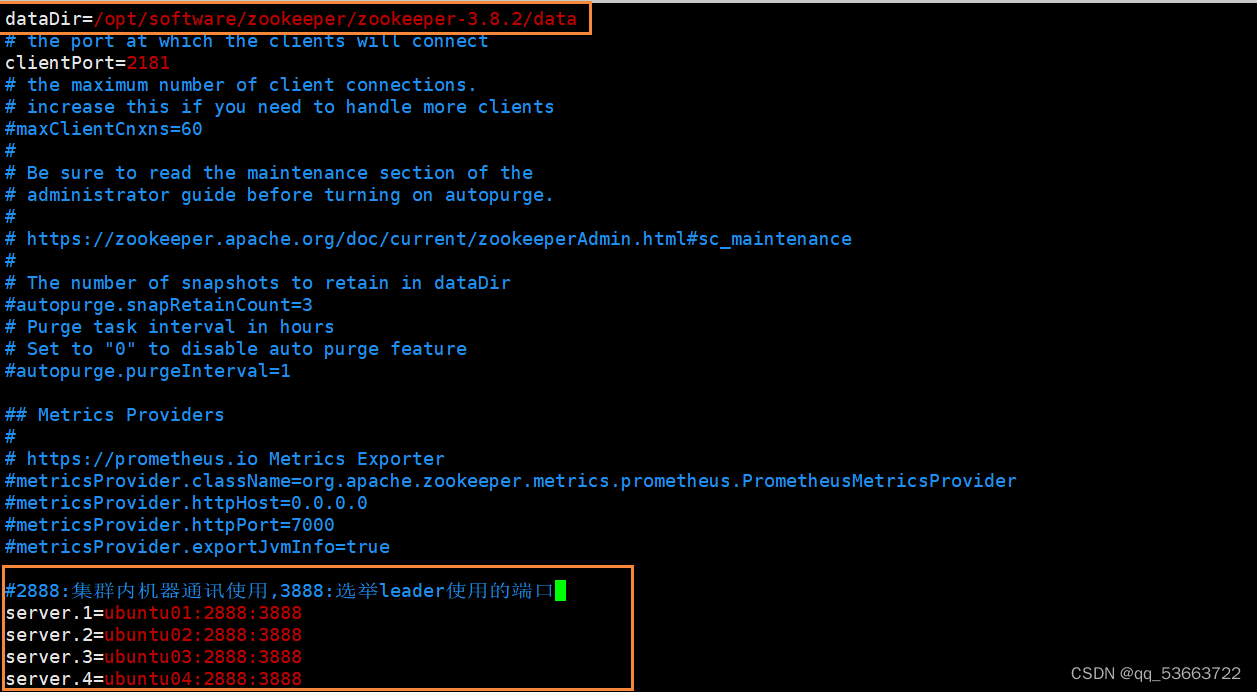
- 修改配置
#dataDir配置是修改
dataDir=/opt/software/zookeeper/zookeeper-3.8.2/data
#以下内容添加在文件末尾,需要注意配置后面不能有空格
server.1=ubuntu01:2888:3888
server.2=ubuntu02:2888:3888
server.3=ubuntu03:2888:3888
server.3=ubuntu04:2888:3888
4.1.5 配置myid文件
- 在/opt/software/zookeeper/zookeeper-3.8.2/data/目录下创建myid文件
cd /opt/software/zookeeper/zookeeper-3.8.2/data/
- 当前主机是ubuntu01,就配1

4.1.6 分发配置
分发zookeeper文件
scp -r zookeeper-3.8.2/ root@ubuntu02:$PWD
scp -r zookeeper-3.8.2/ root@ubuntu02:$PWDscp -r zookeeper-3.8.2/ root@ubuntu04:$PWD
将ubuntu02的myid修改为2,将ubuntu03的myid修改为3,将ubuntu04的myid修改为4
分发/etc/profile
scp /etc/profile root@ubuntu02:/etc/
scp /etc/profile root@ubuntu03:/etc/scp /etc/profile root@ubuntu04:/etc/
然后在两个从节点执行source /etc/profile

4.1.7 启动zookeeper服务
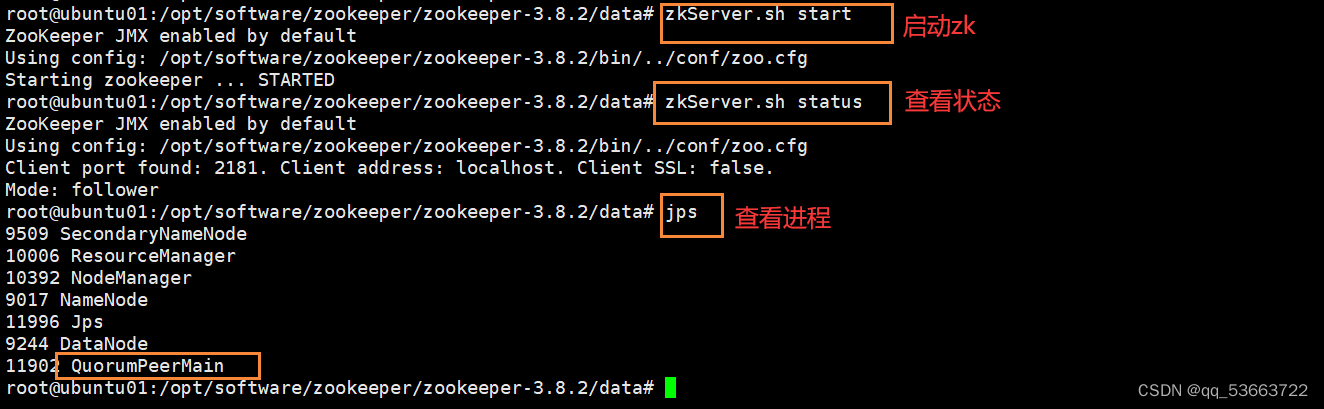
- 四台都执行启动命令
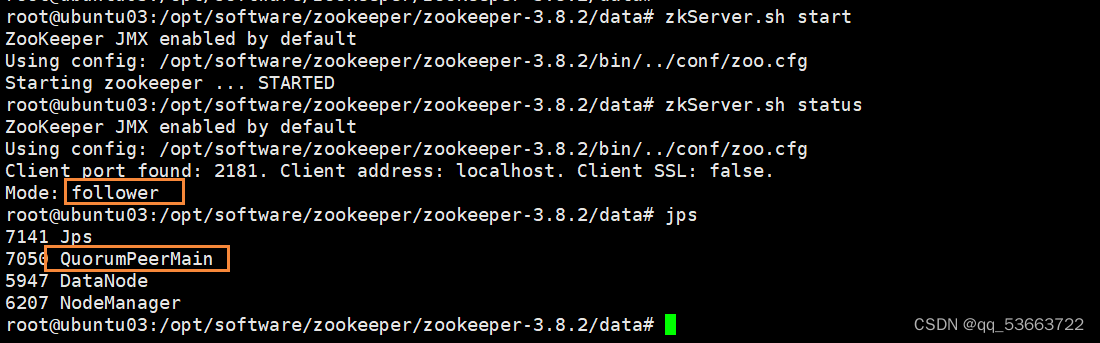
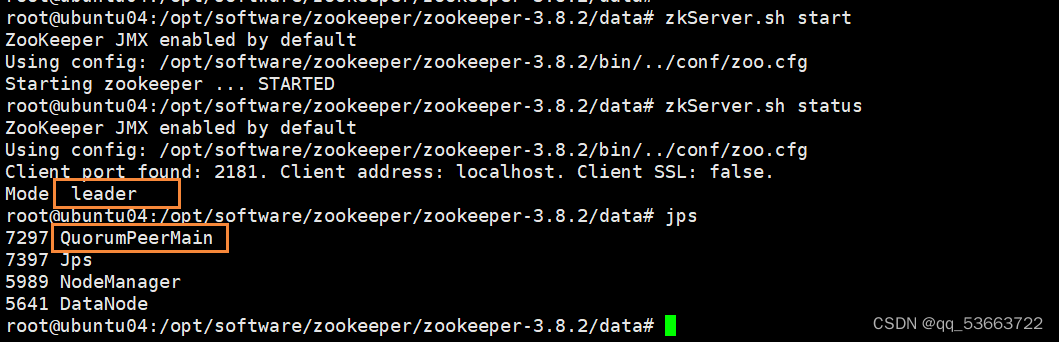
zkServer.sh start
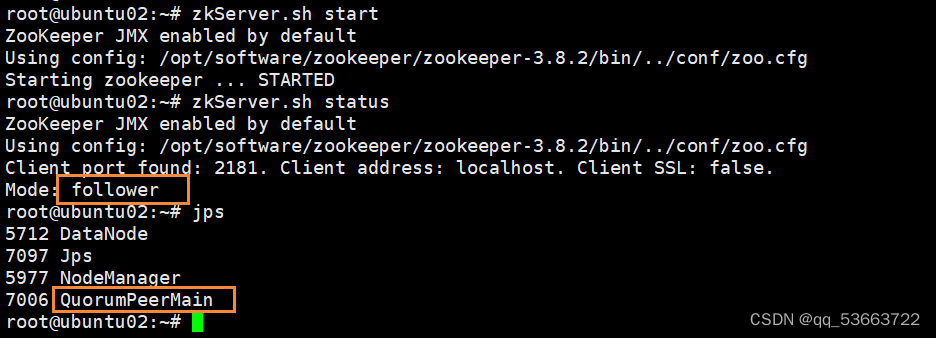
这是ubuntu01,四台里面ubuntu04是leader,其它均为follower
下面是ubuntu02、ubuntu03、ubuntu04
4.2 修改配置文件
4.2.1 hdfs-site.xml
- 在分布式基础上新增以下内容
<!-- 指定hdfs的nameservices为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>ubuntu01:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>ubuntu01:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>ubuntu02:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>ubuntu02:9870</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ubuntu01:8485;ubuntu02:8485;ubuntu03:8485;ubuntu04:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/software/hadoop/hdfs/journalnode/data</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<!-- 开启NameNode故障转移自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
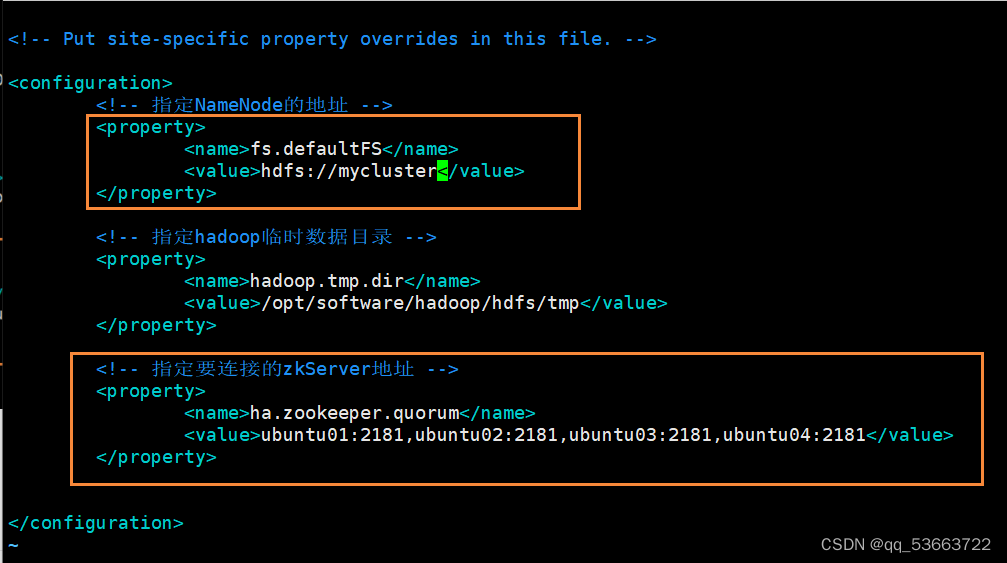
4.2.2 core-site.xml
- 修改hdfs标识和新增zkServer地址
4.2.3 hadoop-env.sh
- 新增以下内容

4.2.4 yarn-site.xml
- 总的配置内容
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ubuntu01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ubuntu02</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ubuntu01:2181,ubuntu02:2181,ubuntu03:2181,ubuntu04:2181</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
4.2.5 mapred-site.xml
- 总的配置内容
<configuration>
<!-- 指定运行MapReduce作业的运行时框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定JobHistory Server的监听地址和端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>ubuntu01:10020</value>
</property>
<!-- 指定JobHistory Web UI的访问地址和端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ubuntu01:19888</value>
</property>
</configuration>
4.3 分发配置
- 分发到ubuntu02 、ubuntu03 、ubuntu04,可以删除其它三台原来的hadoop目录,也可以只拷贝修改的文件,我这里是删除了
cd /opt/software/
scp -r hadoop/ root@ubuntu02:$PWD
scp -r hadoop/ root@ubuntu03:$PWD
scp -r hadoop/ root@ubuntu04:$PWD
4.4 启动高可用集群
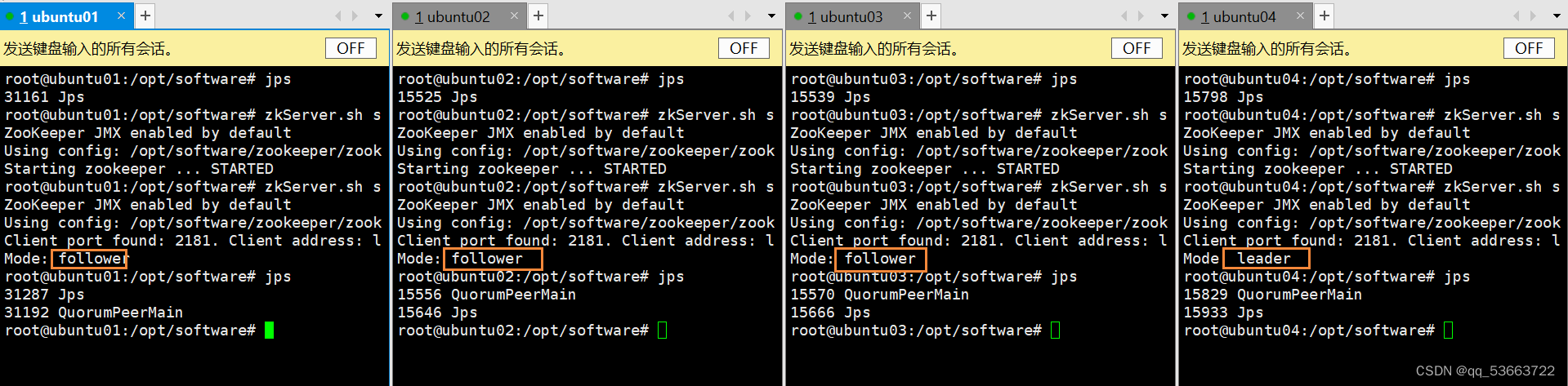
4.4.1 启动zookeeper
- 初始化前需要打开zk服务
zkServer.sh start
4.4.2 *启动JN*节点 **
- 四台机器分别启动JN节点,第一次启动的时候需要在格式化之前分别启动四台,后面重启时则不需要
hadoop-daemon.sh start journalnode

**4.4.3 hdfs格式化 **
- 格式化之前需要把/opt/software/hadoop/hdfs下的目录data、name、tmp进行数据清空
rm -rf *
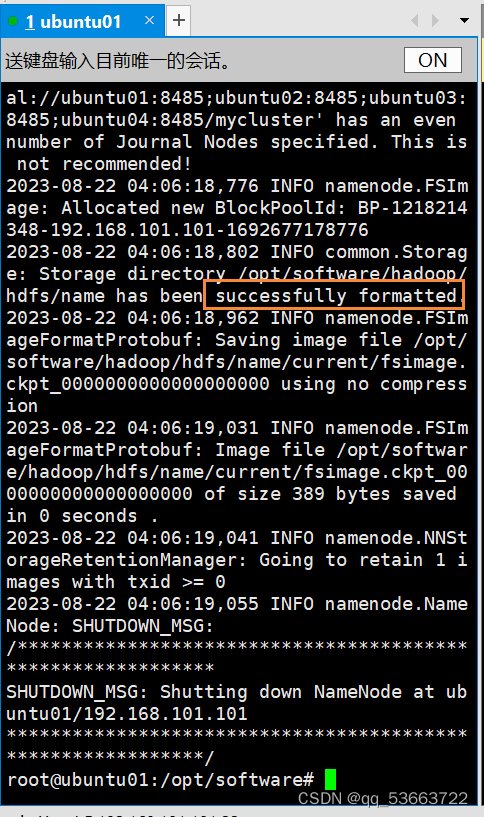
- 在ubuntu01上进行hdfs格式化,
hdfs namenode -format
**4.4.4 ****复制元数据 **
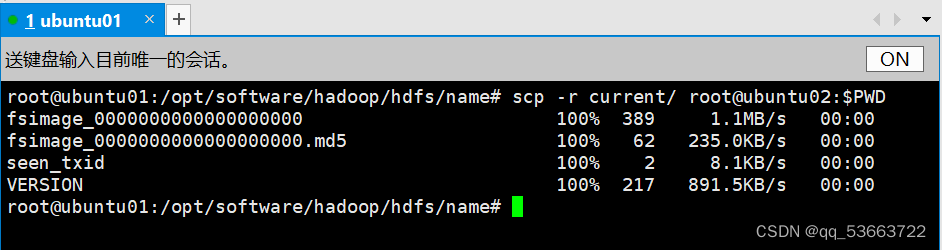
- 从ubuntu01的hdfs/name/目录下复制元数据到ubuntu02的对应目录
cd /opt/software/hadoop/hdfs/name/
scp -r current/ root@ubuntu02:$PWD
*4.4.5 ZKFC***格式化 **
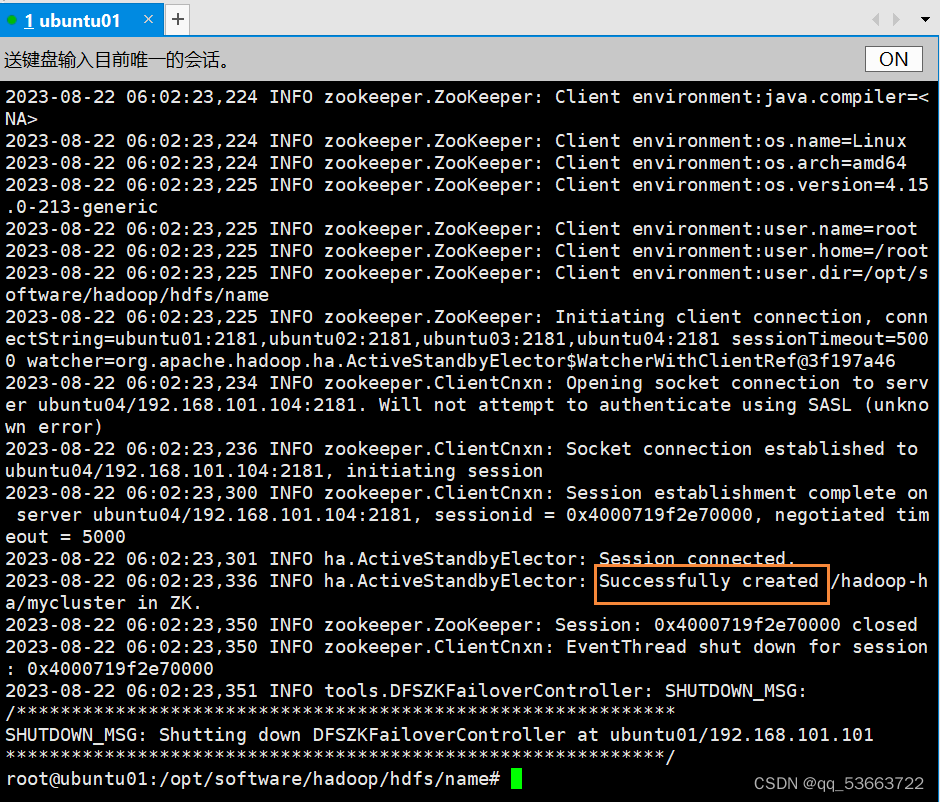
- 在ubuntu01上进行zkfc格式化
hdfs zkfc -formatZK
4.4.6 启动hdfs集群
start-dfs.sh
- 出现以下进程

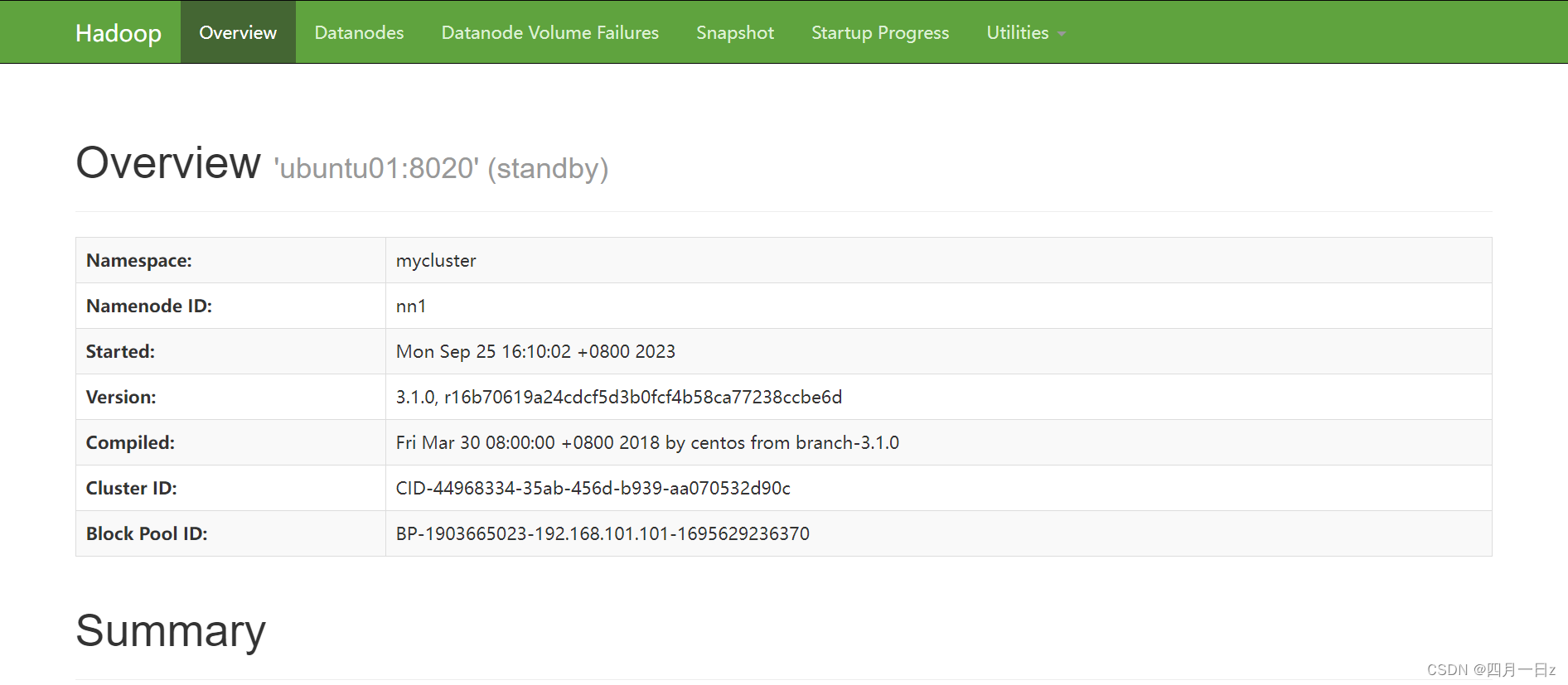
- 查看web端
ubuntu01服务器:
ubuntu02服务器:
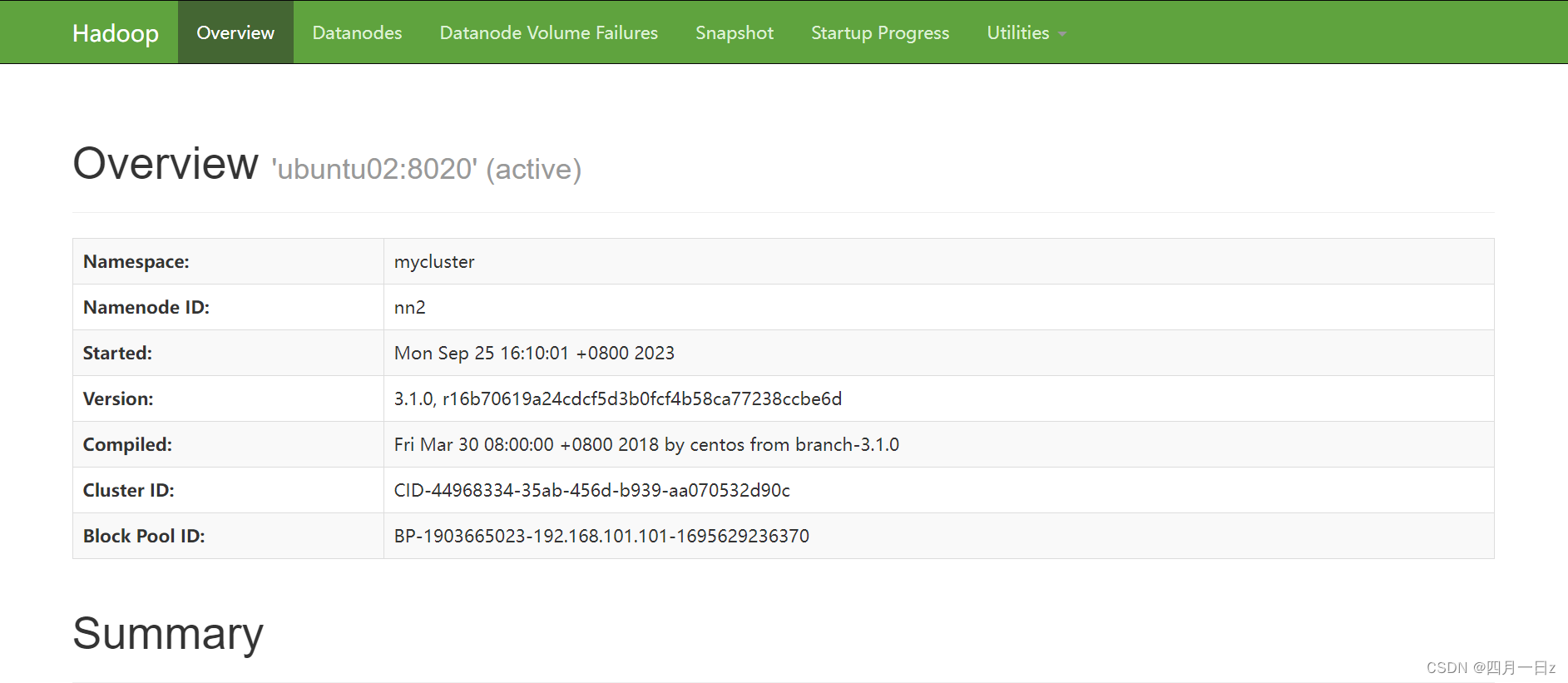
4.6.7 启动yarn集群

4.6.8 启动历史服务
./mr-jobhistory-daemon.sh --config /opt/software/hadoop/hadoop-3.1.0/etc/hadoop start historyserver

5. 问题:
5.1 复制三台虚拟机然后打开另外两个虚拟机时出现以下错误
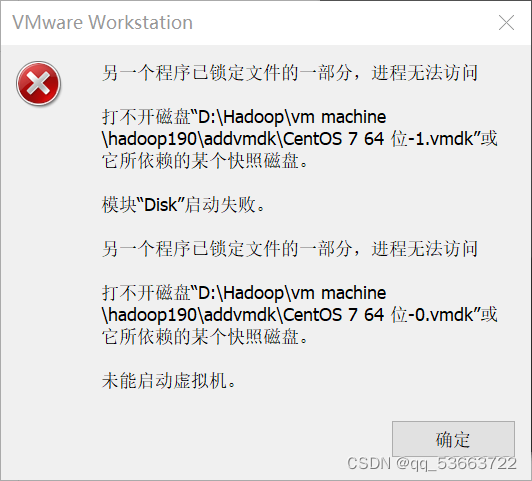
- 原因:这是虚拟机的保护机制
- 解决方法:在磁盘虚拟机安装目录下,把lck后缀的文件夹删除就好了
5.2 搭建完全分布式时格式化以后启动ubuntu01报错
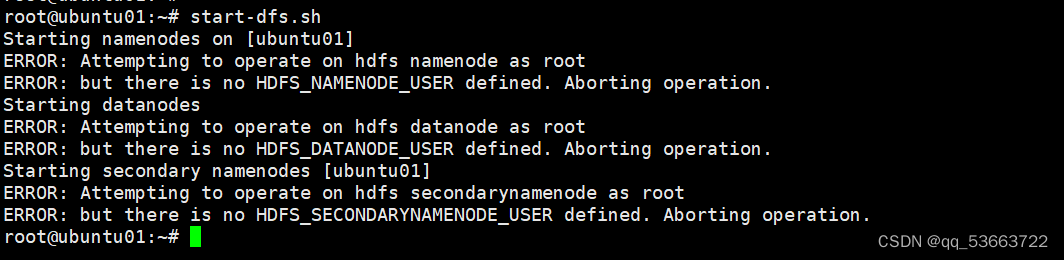
- 这个错误是因为我正在以
root用户身份尝试启动Hadoop进程,但是没有定义相应的用户环境变量。在安全配置下,Hadoop要求用不同的用户身份来运行不同的进程,以增加集群的安全性。 - 要解决此问题,可以按照以下步骤进行操作:
cd /opt/software/hadoop/hadoop-3.1.0/sbin
- 在
start-dfs.sh、stop-dfs.sh文件开头添加以下内容:HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
- 在
start-yarn.sh、stop-yarn.sh文件开头添加以下内容:YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 现在,重新启动hdfs:
start-dfs.sh
- 查看进程
ubuntu01上

ubuntu02 、ubuntu03 、ubuntu04

版权归原作者 四月一日z 所有, 如有侵权,请联系我们删除。