
Hive数据类型
支持的类型
hive支持两种数据类型:
原始数据类型、
复杂数据类型
原始数据类型
原始数据类型包括数据型,布尔型,字符串型,具体如下表:
类型描述示例TINYINT(tinyint)一个字节(8位)有符号整数, -1281271SMALLINT(smallint)2字节(16位)有符号整数,-32768327671INT(int)4字节(32位)有符号整数1BIGINT(bigint)8字节(64位)有符号整数1FLOAT(float)4字节(32位)单精度浮点数1.0DOUBLE(double)8字节(64位)双精度浮点数1.0DECIMAL(decimal)任意精度的带符号小数1.0BOOLEAN(boolean)true/falsetrue/falseSTRING(string)字符串,变长‘a’,‘b’,‘1’VARCHAR(varchar)变长字符串‘a’CHAR(char)固定长度字符串‘a’BINANY(binany)字节数组无法表示TIMESTAMP(timestamp)时间戳,纳秒精度122327493795DATE(date)日期‘2016-03-29’
各类型详解
DATE类型
虽然我们上表写出了DATE类型,但是hive是不支持真正的日期类型的,而常用的日期格式转化操作则是通过从具有标准时间格式的字符串中提取,也就是
从具有标准时间格式的字符串中提取进行操作,比如这位仁兄的笔记:
Hive 时间相关函数汇总
整数类型
hive有四种带符号的整数类型,
TINYINT,SMALLINT,INT,BIGINT,他们分别对应java里面的
byte,short,int,long,字节长度分别为1字节,2字节,4字节,8字节,在使用整数字面量的时候,默认使用INT,如果需要使用其他,需要加对应的后缀名,如下表:
类型后缀例子TINYINTY100YSMALLINTS100SBIGINTL100L
小数、Boolean、二进制
hive中的
FLOAT、DOUBLE类型对应java中的
FLOAT、DOUBLE,32位,64位;
hive中的BOOLEAN类型对应java中的
BOOLEAN类型
BINANY用于存储变长的二进制数据
文本类型
hive有三种类型用于存储文本
STRING存储变长的文本,对长度没有限制,理论上可以存储大小为2GB,但是存储特别大 的对象时效率可能会收到影响
VARCHAR于STRING类似,但是最大长度为1-65355之间
CHAR则用固定长度来存储数据
时间类型
TIMESTAMP类型则存储纳秒级别的时间戳,同时hive提供了一些内置函数用于再TIMESTAMP与Unix时间戳(秒)和字符串之间做转换,如:
cast(date as date)
cast(timestamp as date)
cast(string as date)
cast(date as string)
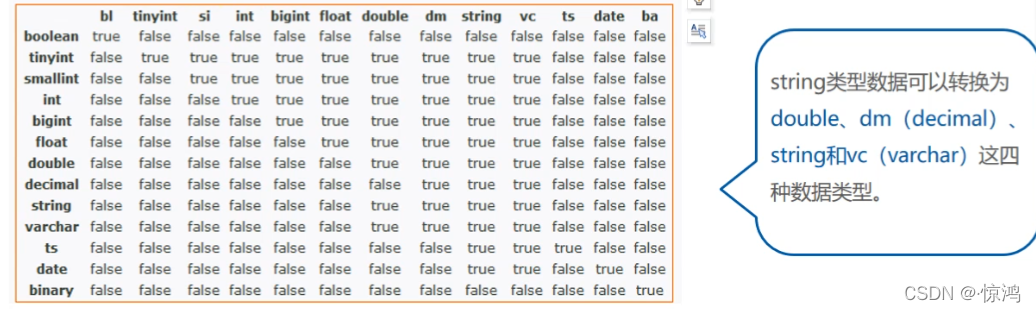
类型转换
隐式转换
hive支持基本数据类型的转换
- 任意数据类型都可以转换为更宽的数据类型(通俗讲就是低转高,且不会导致精度丢失)或者文本类型
- 所有的文本类型都可以隐式的转换为另一种文本类型,也可以转换为DOUBLE或者DECIMAL,转换失败会抛出异常
- BOOLEAN不能做任何的类型转换
- 时间戳和日期可以隐式的转换为文本类型
低字节的基本类型可以转换为
高字节的数据类型,例如TINYINT,SMALLINT,INT可以转换为FLOAT,而所有的整数类型INT和FLOAT类型、STRING类型都可以转换为DOUBLE类型
显示转换(CAST函数)
高字节的类型也可以转换为
低字节的数据类型
Hive中CAST()函数用法
复杂数据类型
类型描述示例ARRAY有序数组,字段的类型必须相同Array(1,2)MAP一组无序的键值对,键的类型必须是原始数据类型,他的值可以是任何类型,同一个映射的键的类型必须相同,值得类型也必须相同Map(‘a’,1)STRUCT一组命名的字段,字段类型可以不同Struct(‘a’,1,2.0UNIONUNION则类似于C语言中的UNION结构,在给定的任何一个时间点,UNION类型可以保存指定数据类型中的任意一种
详解
ARRAY和MAP
数组的类型声明格式为ARRAY<data_type>,元素的访问可以通过0开始下标,例如array[1]访问第二个元素。
Map通过Map<key_type,data_type>,key只能是基本数据类型,值可以值任意数据类型,元素的访问使用[],例如:map[“key1”]
STRUCT
STRUCT则封装一组带有名字的字段,他可以是任意的数据类型,
元素的访问可以通过点号,表结构字段名.struct字段名
UNION
UNION则类似于C语言中的UNION结构,在给定的任何一个时间点,UNION类型可以保存指定数据类型中的任意一种。类型声明语法为UNIONTYPE<data_type,data_type,…>。每个UNION类型的值都通过一个整数来表示其类型,这个整数位声明时的索引,从0开始。例如:
CREATE TABLE union_test(foo UNIONTYPE<int,double,array,strucy<a:int,b:string>>);
foo的一些取值如下:
{0:1}
{1:2.0}
{2:[“three” , “four”]}
{3:[“a”:5,b:“five”]}
{0:9}其中冒号左边的整数代表数据类型,必须在预先定义的范围类,通过0开始的下标表示。冒号右边是该类型的取值。
下面的这个CRATE语句用到了这4中复杂类型:
CREATE TABLE complex (
c1 ARRAY,
c2 MAP<STRING,INT>,
c3 STRUCT<a:STRING,b:INT,c:DOUBLE>,
c4 UNIONTYPE<STRING,INT>
);
通过下面的SELECT语句查询相应的数据:
SELECT c1[0] , c2[‘b’],c3.c , c4 FROM complex
结果类似:
1 2 1.0 {1:63}
实例
Create table complex(col1 ARRAY<INT>,
Col2 MAP<STRING,INT>,
Col3 STRUCT<a:STRING,b :INT,c:DOUBLE>);
查询
Select col1[0],col2[‘b’],col3.c fromcomplex;
版权归原作者 ·惊鸿 所有, 如有侵权,请联系我们删除。