
持续更新中!!!
一、RDD的创建
从文本、JSON、SequenceFile、分布式文件系统、集合、数据库等创建
1.从本地创建
(1)本地文件
sc.textFile(file:/// ) (这一步是转换操作,只记录不执行,所以如果是一个不存在的文件也不会报错,只有在执行执行操作时才报错)
例:
rdd=sc.textFile("file:///home/hadoop/sparksj/word.txt")
rdd.foreach(print)
Spark is better
Hadoop is good
Spark is fast
(2)hdfs文件(先提前创建目录并上传文件)
sc.textFile("地址") 例:sc.textFile("/usr/hadoop/ ")
rdd = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
rdd = sc.textFile("/user/hadoop/word.txt")
rdd = sc.textFile("word.txt")
三条语句是完全等价的,可以使用其中任意一种方式
注意:
1.可以从多个数据集文件中通过读取文件夹来读取多个文件
例如:在home/hadoop/sparksj/mycode目录下有多个文件,读取其中的所有文件
rdd2=sc.textFile("file:///home/hadoop/sparksj/mycode")
2.可以读取多种类型的数据
rdd2=sc.textFile("file:///home/hadoop/sparksj/people.json")
rdd2.foreach(print)
{"name":"Justin", "age":19}
{"name":"Michael"}
{"name":"Andy", "age":30}
3.lambda表达式
rdd3=rdd2.filter(lambda line:"Andy" in line) (filter(func):过滤,从所给数据集中所有数据中过滤出来,即筛选出满足函数func的元素,并返回一个新的数据集)
rdd3.foreach(print)
{"name":"Andy", "age":30}
2.从集合创建(通过并行集合(列表)创建RDD)
调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(列表)上创建:
a = [1,2,3,4,5]
rdd = sc.parallelize(a)
rdd.foreach(print)
3
2
4
5
1
rdd.collect()
[1, 2, 3, 4, 5]
rdd.reduce(lambda a,b:a+b) (求和)
15
b=["Spark","bbb","MongoDB","Spark"]
rdd2=sc.parallelize(b)
rdd2.foreach(print)
Spark
MongoDB
bbb
Spark
二、RDD的写回
写回本地:数据集.saveAsTextFile("file:/// ")
写回HDFS:数据集.saveAsTextFile("/user/hadoop/ 或直接是文件名") #同写入文件一样,三条语句
三、转换操作(Transformation)
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用
转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作
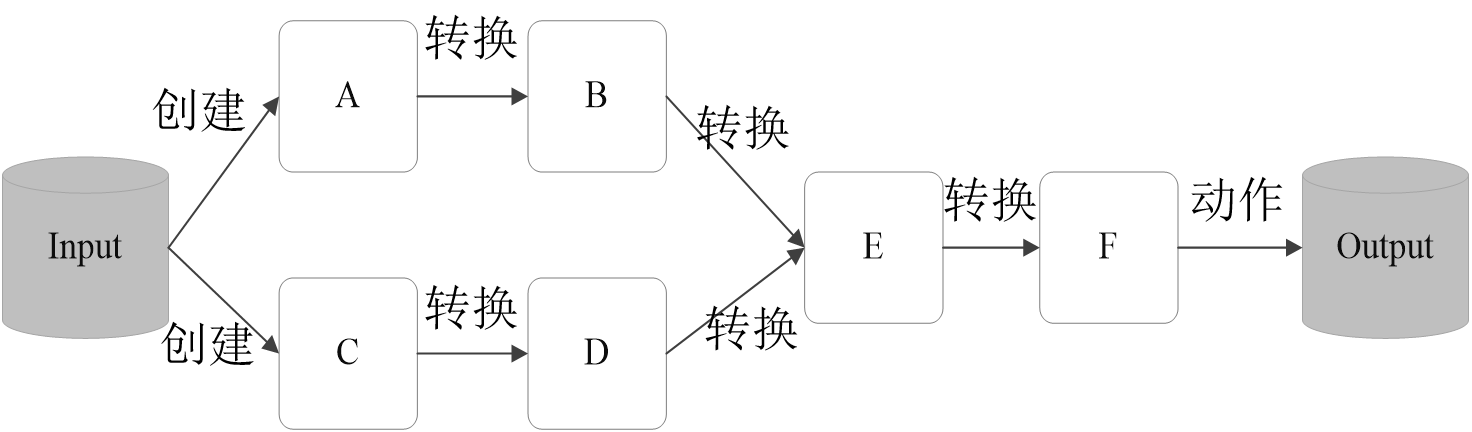
转换操作并不会产生真正的计算,所以说需要把转换后的内容赋值给对象,而行为操作则不需要赋值给对象,直接执行。
(每一个func都是一个匿名函数)
1.filter(func)
筛选出满足函数func的元素,并返回一个新的数据集
例:rdd3=rdd2.filter(lambda line:"Andy" in line)
2.map(func)
将每个元素传递到函数func中,并将结果返回为一个新的数据集
例:>>> rdd3=rdd2.map(lambda x:(x,1)) #转换为键值对
rdd3.foreach(print)
('Spark', 1)
('bbb', 1)
('Spark', 1)
('MongoDB', 1)
3.flatMap(func)
与map()相似,但每个输入元素都可以映射到0或多个输出结果
map(func)与flatMap(func)的区别:把map()操作得到的数据集中的每个元素“拍扁”(flat),就得到了flatMap()操作的结果
rdd=sc.textFile("file:///home/hadoop/sparksj/word.txt")
rdd1=rdd.map(lambda line:line.split(" ")) #split(" "):按空格分隔
rdd1.foreach(print)
['Hadoop', 'is', 'good']
['Spark', 'is', 'fast']
['Spark', 'is', 'better']
rdd2=rdd.flatMap(lambda line:line.split(" "))
rdd2.foreach(print)
Spark
is
better
Hadoop
is
good
Spark
is
fast
rdd3=rdd2.map(lambda x:(x,1)) #变成键值对
rdd3.foreach(print)
('Spark', 1)
('is', 1)
('better', 1)
('Hadoop', 1)
('is', 1)
('good', 1)
('Spark', 1)
('is', 1)
('fast', 1)
rdd4=rdd1.map(lambda x:(x,1))
rdd4.foreach(print)
(['Spark', 'is', 'better'], 1)
(['Hadoop', 'is', 'good'], 1)
(['Spark', 'is', 'fast'], 1)
4.groupByKey()
应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
例:>>> rdd5=rdd3.groupByKey()
rdd5.foreach(print)
('is', <pyspark.resultiterable.ResultIterable object at 0x7fe2ce9e5900>)
('good', <pyspark.resultiterable.ResultIterable object at 0x7fe2ce9e76d0>)
('Spark', <pyspark.resultiterable.ResultIterable object at 0x7fe2ce9e5900>)
('Hadoop', <pyspark.resultiterable.ResultIterable object at 0x7fe2ce9e5900>)
('fast', <pyspark.resultiterable.ResultIterable object at 0x7fe2ce9e76d0>)
('better', <pyspark.resultiterable.ResultIterable object at 0x7fe2ce9e5900>)
即变成("is",(1,1,1))
5.reduceByKey(func)
应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果
例:>>> rdd6=rdd3.reduceByKey(lambda a,b:a+b) #词频统计
rdd6.foreach(print)
('Hadoop', 1)
('fast', 1)
('better', 1)
('is', 3)
('good', 1)
('Spark', 2)
6.join()
join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集
rdd1=sc.parallelize([(1001,"zhangsan"),(1002,"lisi"),(1003,"wangwu")])
rdd2=sc.parallelize([(1001,"student"),(1002,"teather")])
rdd1.join(rdd2).collect()
[(1001, ('zhangsan', 'student')), (1002, ('lisi', 'teather'))]
rdd1.leftOuterJoin(rdd2).collect() #左外连接
[(1001, ('zhangsan', 'student')), (1002, ('lisi', 'teather')), (1003, ('wangwu', None))]
rdd1.rightOuterJoin(rdd2).collect() #右外连接
[(1001, ('zhangsan', 'student')), (1002, ('lisi', 'teather'))]
rdd1.fullOuterJoin(rdd2).collect() #全连接
[(1001, ('zhangsan', 'student')), (1002, ('lisi', 'teather')), (1003, ('wangwu', None))]
7.subtractByKey()
删掉 RDD1 中键与 RDD2 中的键相同的元素
rdd1.subtractByKey(rdd2).collect()
[(1003, 'wangwu')]
8.distinct()
去重
r1=sc.parallelize([1,2,2,3,3,3])
r1.distinct().collect()
[1, 2, 3]
9.union()、intersection()、subtract()
r1=sc.parallelize([1,2,3]) #键值对同理
r2=sc.parallelize([1,2,4,5,6])
r12=r1.union(r2) #并集
r12.collect()
[1, 2, 3, 1, 2, 4, 5, 6]
r21=r1.intersection(r2) #交集
r21.collect()
[1, 2]
r121=r1.subtract(r2) #差集
r121.collect()
[3]
四、行动操作(Action)
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
1.count()
返回数据集中的元素个数
2.collect()
以数组的形式返回数据集中的所有元素
3.first()
返回数据集中的第一个元素
4.take(n)
以数组的形式返回数据集中的前n个元素
5.reduce(func)
通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
6.foreach(func)
将数据集中的每个元素传递到函数func中运行
rdd=sc.textFile("file:///home/hadoop/sparksj/word.txt")
rdd.count()
3
rdd.collect()
['Hadoop is good', 'Spark is fast', 'Spark is better']
rdd.first()
'Hadoop is good'
rdd.take(2)
['Hadoop is good', 'Spark is fast']
rdd.reduce(lambda a,b:a+b)
'Hadoop is goodSpark is fastSpark is better'
rdd.foreach(print)
Spark is better
Hadoop is good
Spark is fast
练习:
rdd=sc.textFile("file:///home/hadoop/sparksj/y.txt")
rdd.foreach(print)
one,two,two,three,three,three
rdd1=rdd.flatMap(lambda line: line.split(","))
rdd2=rdd1.map(lambda x:(x,1))
rdd2.foreach(print)
('one', 1)
('two', 1)
('two', 1)
('three', 1)
('three', 1)
('three', 1)
rdd3=rdd2.reduceByKey(lambda a,b:a+b)
rdd3.foreach(print)
('one', 1)
('two', 2)
('three', 3)
rdd4=rdd1.map(lambda s:len(s))
rdd4.foreach(print)
3
3
3
5
5
5
rdd4.reduce(lambda a,b:a+b)
24
rdd5=rdd1.map(lambda x:"BigData:"+x)
rdd5.foreach(print)
BigData:one
BigData:two
BigData:two
BigData:three
BigData:three
BigData:three
rdd6=sc.parallelize([2,6,1,4,8])
rdd7=rdd6.map(lambda x:x+10)
rdd7.collect()
[12, 16, 11, 14, 18]
rdd7.filter(lambda x:x>15).collect()
[16, 18]
五、持久化
在了解持久化之前先了解什么是惰性机制?
所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算
持久化:
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据
- 可以通过持久化(缓存)机制避免这种重复计算的开销
- 可以使用persist()方法对一个RDD标记为持久化
- 之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
- 持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
persist()的圆括号中包含的是持久化级别参数:
- persist(MEMORY_ONLY):表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容(只持久化到内存)
- persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上
- 一般而言,使用**cache()**方法时,会调用persist(MEMORY_ONLY)
- 可以使用unpersist()方法手动地把持久化的RDD从缓存中移除
六、RDD分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
分区的作用 :(1)增加并行度 (2)减少通信开销
- 分区是RDD数据存储的最小单位
- RDD所有的操作都会作用在所有的分区之上
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下: sc.textFile(path, partitionNum) 其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
r1=sc.parallelize([1,2,3,4,5,6],3) #设置三个分区
r1.glom().collect() #显示r1中三个分区的内容
[[1, 2], [3, 4], [5, 6]]
len(r1.glom().collect()) #显示r1这个RDD的分区数量
3
r1.map(lambda x:x+10).glom().collect()
[[11, 12], [13, 14], [15, 16]]
使用reparititon方法(重分区)重新设置分区个数:
data = sc.parallelize([1,2,3,4,5],2)
len(data.glom().collect()) #显示data这个RDD的分区数量
2
rdd = data.repartition(1) #对data这个RDD进行重新分区
len(rdd.glom().collect()) #显示rdd这个RDD的分区数量
1
思考:
rdd1=sc.parallelize(range(10),3)
print(rdd1.glom().collect())
r2=rdd1.reduce(lambda x,y:x-y)
print(r2)
写出结果,并解释
输出:[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
21
解释:(0-1-2)-(3-4-5)-(6-7-8-9)=-3+6+18=21
七、键值对RDD(转换操作)
1.reduceByKey(func)
2.groupByKey()
比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),采用groupByKey()后得到的结果是:("spark",(1,2))和("hadoop",(3,5))
3.keys()
keys只会把Pair RDD(一个键值对(key-value pairs)的RDD)中的key返回形成一个新的RDD
4.values()
values只会把Pair RDD中的value返回形成一个新的RDD
5.sortByKey()
返回一个根据键排序的RDD
6.mapValues(func)
对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化
7.join()
join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集
8.combineByKey()
自定义对每个键的值进行聚合的方式
r1=sc.parallelize([("Spark",10),("Bigdata",5),("Flink",3)])
r1.foreach(print)
('Spark', 10)
('Bigdata', 5)
('Flink', 3)
r1.keys().collect() #输出键(collect():列表形式)
['Spark', 'Bigdata', 'Flink']
r1.values().collect() #输出值(列表形式)
[10, 5, 3]
r1.sortByKey().collect() #sortByKey()按键排序(默认升序:B,F,S)
[('Bigdata', 5), ('Flink', 3), ('Spark', 10)]
r1.sortByKey(False).collect() #按键降序排序
[('Spark', 10), ('Flink', 3), ('Bigdata', 5)]
r1.sortBy(lambda x:x).collect() #sortBy()默认按键升序排序
[('Bigdata', 5), ('Flink', 3), ('Spark', 10)]
r1.sortBy(lambda x:x,False).collect() #按键降序排序
[('Spark', 10), ('Flink', 3), ('Bigdata', 5)]
r1.sortBy(lambda x:x[0],False).collect() #x[0],False指定按键降序排序
[('Spark', 10), ('Flink', 3), ('Bigdata', 5)]
r1.sortBy(lambda x:x[1],False).collect() #x[1],False指定按值降序排序
[('Spark', 10), ('Bigdata', 5), ('Flink', 3)]
r1.sortBy(lambda x:x[1],True).collect() #x[1],True指定按值升序排序
[('Flink', 3), ('Bigdata', 5), ('Spark', 10)]
r1.mapValues(lambda x:x+1).collect() #mapValues对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化
[('Spark', 11), ('Bigdata', 6), ('Flink', 4)]
版权归原作者 哇咔咔哇咔 所有, 如有侵权,请联系我们删除。