
1,前期准备
使用 root 用户完成相关配置,已安装配置Hadoop 及前置环境
2,spark上传解压到master服务器
3,修改环境变量
/etc/profile末尾添加下面代码
export SPARK_HOME=.../spark-3.1.1-bin-hadoop3.2(注意:需要替换成你自己得路径)
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
4,环境变量生效
source /etc/profile
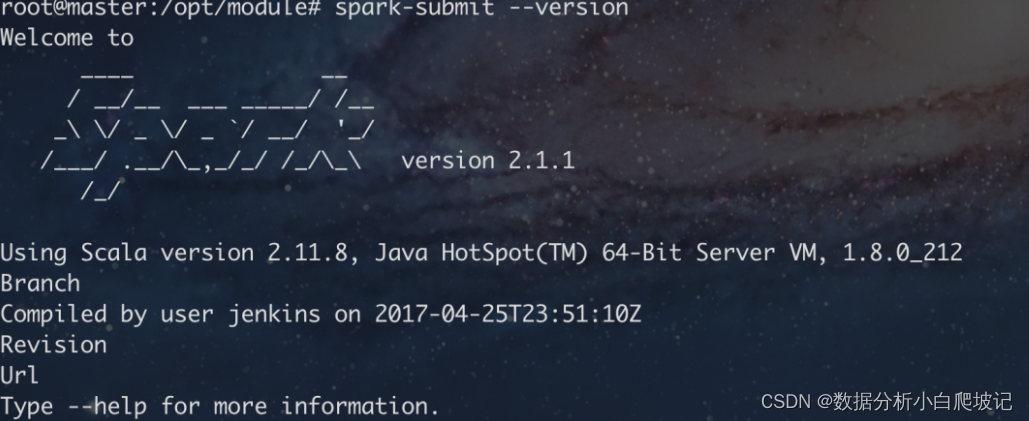
5,运行spark-submit --version
显示如下
6,修改saprk-env.sh文件
在.../spark-3.1.1-bin-hadoop3.2/conf目录下,将下面两行添加至spark-env.sh文件末尾:
HADOOP_CONF_DIR=.../hadoop-3.1.3/etc/hadoop
YARN_CONF_DIR=.../hadoop-3.1.3/etc/hadoop
7,运行计算Pi的jar包
命令如下:
spark-submit --master yarn --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-example_2.11-2.1.1.jar
结果显示如下:

8,注意
如果报内存大小错误,修改yarn-site.xml,设置虚拟内存,至少是物理内存的4倍

本文转载自: https://blog.csdn.net/m0_67447926/article/details/135437696
版权归原作者 数据爬坡ing 所有, 如有侵权,请联系我们删除。
版权归原作者 数据爬坡ing 所有, 如有侵权,请联系我们删除。