
目录
写在前面
由于笔者目前用的是VMware下的Ubuntu20.04,曾经也尝试过安装GPU版本的Pytorch,但虚拟机下安装英伟达驱动一直困扰着我。于是安装了cpu版本的Pytorch,凑合着跑通了深度学习项目(QAQ)
后来了解到需要安装vSphere Bitfusion Client客户端,但由于时间与精力有限就没有去尝试。如果有其他小伙伴在VM 下的ubuntu中成功配置好深度学习环境,有待指点迷津呀~~
最近,我的小伙伴慕笙需要跑深度学习项目,于是帮助TA在双系统下的Ubuntu配置了深度学习环境。在此过程中遇到了许多坑,主要是安装CUDA。听说这一过程可以劝退很多人,因此将详细的步骤以及采坑的经历记录下来,以示后来者!!
Dependency
- 双系统win10 + ubuntu 20.04
- Anaconda 3
- CUDA 11.3
- cuDNN v8.2.1
- Pytorch 1.10.2
1.安装Anaconda
1.1 下载安装包
官网or清华镜像源
建议大家选择后者,即使这样我也要把前者贴出来~~(有点专业的样子😂😂)
1.2 进入安装文件夹,执行安装脚本。
bash Anaconda3-5.3.0-Linux-x86.sh
然后一路yes就欧克,但到后面要注意,可能会推送vscode,根据需求选择呀~
1.3 环境变量的配置与更新
echo 'export PATH="/home/thebin/anaconda3/bin:$PATH"' >>~/.bashrc
更新:(一定记得!否则不生效!😡)
source ~/.bashrc # 或者 source /etc/profile
1.4 测试安装
conda -V或conda --version
1.5 创建虚拟环境
①查看当前环境
conda env list
②创建虚拟环境
conda create -n your_name
③激活创建的虚拟环境
conda activate your_name
④安装需要的包
conda install 或 pip install,对了,如果觉得用pip安装第三方库慢或者超时报错,可以采用豆瓣源,个人觉得相当好用❤❤❤
pip install your_package -i https://pypi.douan.com/simple
2.安装英伟达驱动
法一: 命令行安装
终端执行如下指令,列出可支持的所有驱动以及推荐驱动。
ubuntu-drivers devices

一般选择推荐**(recommand)**驱动,安装命令如下:
sudo apt install nvidia-driver-460
重启ubuntu:
sudo reboot
法二:GUI界面
操作步骤:搜索driver,选择additional drivers,选择所需的驱动,安装,重启。
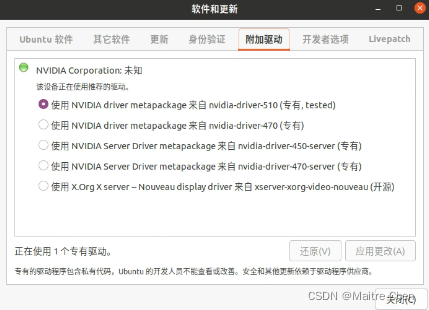
Tips:不论是哪种方法,安装完重启后要用nvidia-smi命令查看图形卡状态,可以看到驱动版本以及nvidia driver API 的cuda版本!
3.安装CUDA
3.1 简介
CUDA,全称ComputeUnified Device Architecture,是一种NVIDIA推出的通用的计算架构,该架构能够使GPU解决复杂的计算问题。
3.2 注意
安装CUDA前一定记得在官网查看一下驱动支持的CUDA版本!
这里贴一张CUDA 11的相关表: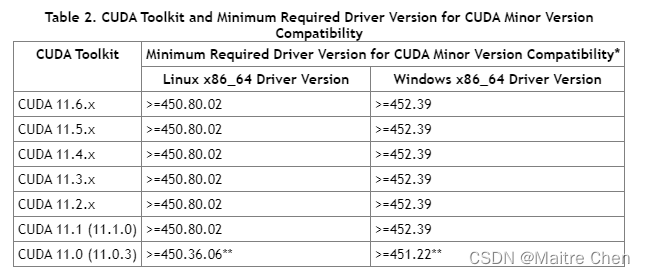
3.3 安装流程
进入CUDA官网,选择对应的安装平台,安装类型选择runfile,参考如下:
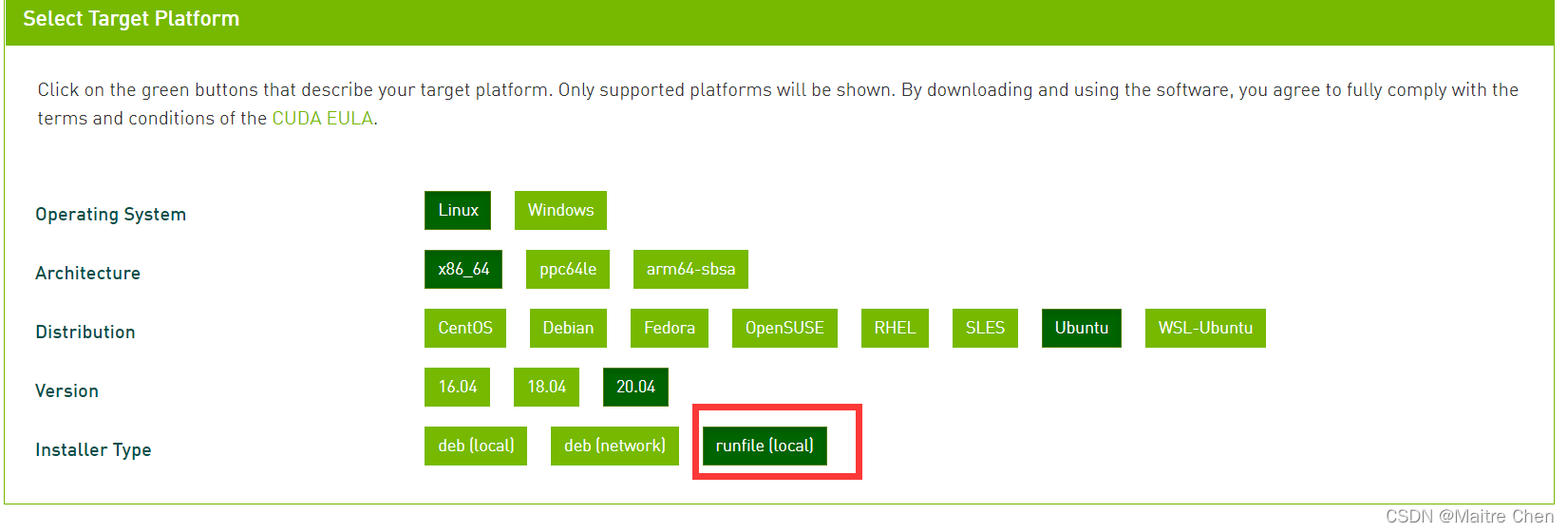
信息确认后会提示安装指令。(wget会默认下载到当前目录 )
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
sudo sh cuda_11.3.0_465.19.01_linux.run
如果安装顺利😆进行,在一路yes后记得在NVIDIA Accelerated Graphics Driver时选择否,就没必要再安装英伟达驱动啦 那么如果不顺利😣咧,请往下看:
Error:执行安装脚本以后可能会提示系统有多个驱动需要移除,提示如下:

Method1:执行sudo apt install nvidia-cuda-toolkit,安装CUDA工具包(下面会讲到Method2)
Test:
nvcc -V
实际上,执行该命令出现CUDA的release以及version就证明runtime API cuda安装完毕~~而且也不需要按照下面的步骤配置环境变量。但这不一定就是最终的版本,因为CUDA与cuDNN之间存在依赖关系!
3.4 配置环境变量
如果能够成功执行脚本,安装CUDA驱动,那么就需要手动配置环境变量,参考如下:
法一
终端输入以下指令:
# 需指定CUDA加速版本,如cuda-10.1
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"
法二
执行以下指令,然后在UI界面添加法一中的两条指令。
sudo gedit ~/.bashrc
该方法与法一并无本质区别,由于笔者用法一配置变量时无法奏效,或许是因为没有更新环境变量,目前尚不明确,如有小伙伴遇到了同样的经历,欢迎讨论~
3.5 更新环境变量
source ~/.bashrc
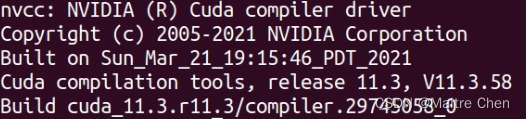
3.6 验证安装
nvcc -V
Attention!!!
①关于nvcc -V与nvidia-smi命令显示的CUDA版本不一致问题。❗❗
由于cuda存在runtime API 与 nvidia drive API两个版本,前者是CUDA Toolkit安装的,称之为CUDA加速版本;而后者是Nvidia driver安装的,成为CUDA驱动版本,因此通常情况下,两者的版本不一致,前者版本都会低于后者。但在实际使用中,cuda版本是基于前者的,也就是runtime CUDA,这个CUDA才是用于深度学习的加速计算的。
②由于本次开发环境系统是ubuntu20.04,而只有CUDA 11.0以上版本才支持。但通过nvcc -V查看发现CUDA已经安装好了,原因是在执行sudo apt install nvidia-cuda-toolkit时默认安装了CUDA 10.1版本,(一个不被ubuntu 20.04支持的版本就这么诞生了,天哪!)。因此我们依然需要通过执行CUDA安装脚本来安装合理的版本。可是一开始执行sudo sh cuda_11.6.1_510.47.03_linux.run报错,因此这就涉及到了Method 2 ,参考如下:
由于ubuntu20.04默认的gcc版本是9,降级。
sudo apt-get install gcc-7 g++-7
目前还不清楚是否需要降级,开始的ERROR是否与gcc的版本有关尚未解决😪!
在降低gcc版本以后再次执行安装脚本依旧报错,提示:Installation failed. See log at /var/log/cuda-installer.log for details,错误日志内容如下:
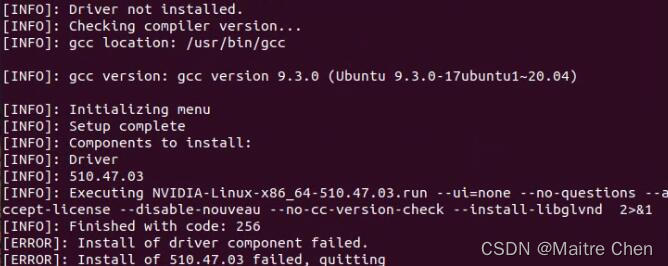
原因:系统已安装CUDA驱动
解决方案:继续执行sudo sh cuda_11.6.1_510.47.03_linux.run安装命令,在进入该界面时选择Continue,然后在安装界面取消Driver!!!

如果没有取消Driver,在[ ]里会显示X!这里一定要注意!否则一直重来一直错!!!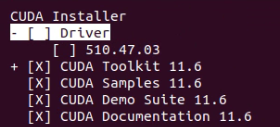
等待安装......🙄🙄🙄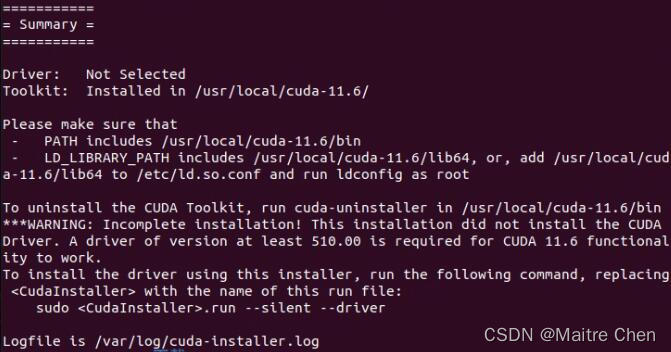 安装完成后,配置环境变量、更新、测试,上面已经讲得很清楚啦!
安装完成后,配置环境变量、更新、测试,上面已经讲得很清楚啦!
如果你是按照上述流程配置的话,细心的你一定会发现我下载的CUDA包与执行安装的包版本不同。这里需要说明一下,由于开始只是关注了CUDA与nvidia driver的关系,而忽略了cuDNN与CUDA以及Pytorch与CUDA的依赖关系,因此在安装完CUDA 11.6以后发现没有该平台支持的Pytorch。目前,在Pytorch官网最高只支持CUDA 11.3,另一个就是CUDA 10.2。而后者在Ubuntu 20.04上是无法安装cuDNN的,于是选择了CUDA 11.3,卸载驱动,重新安装😒~~
4.安装cuDNN
4.1 简介
cuDNN是一个用于深度神经网络DNN的GPU加速库,可以在GPU上实现并行计算,显著提高性能。
4.2 安装流程
访问cuDNN官网
需要注册,有些麻烦,稍安勿躁~~来杯卡布奇诺☕
4.3 下载安装包
选择和系统CUDA匹配的cuDNN版本。
由于本次配置CUDA 为10.3,因此安装11.x系列的cuDNN.
这里选择for Linux.
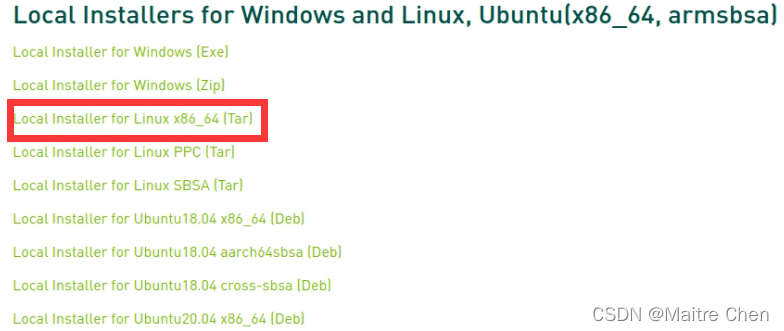
4.4 执行安装命令
4.4.1 进入对应安装文件夹
cd ....
4.4.2 解压
tar -zxvf cudnn-11.1-linux-x64-v8.0.5.39.tgz
4.4.3 复制文件 + 权限修改
sudo cp cuda/include/cudnn*.h /usr/local/cuda/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
官方安装教程在这里。
4.5 测试安装
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
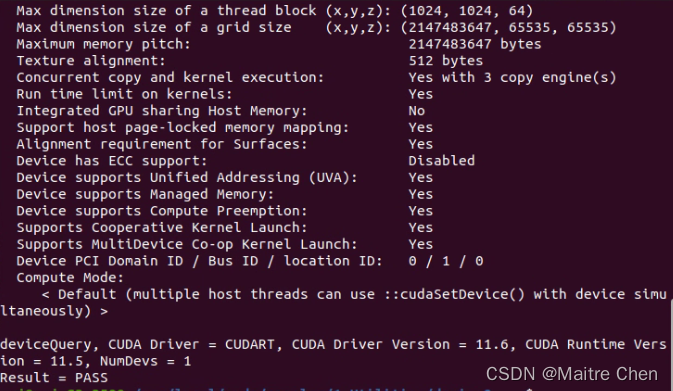
./deviceQuery
最后出现Result = PASS,即安装成功!如下:
5.安装深度学习框架Pytorch
官网选择相关属性,参考如下:
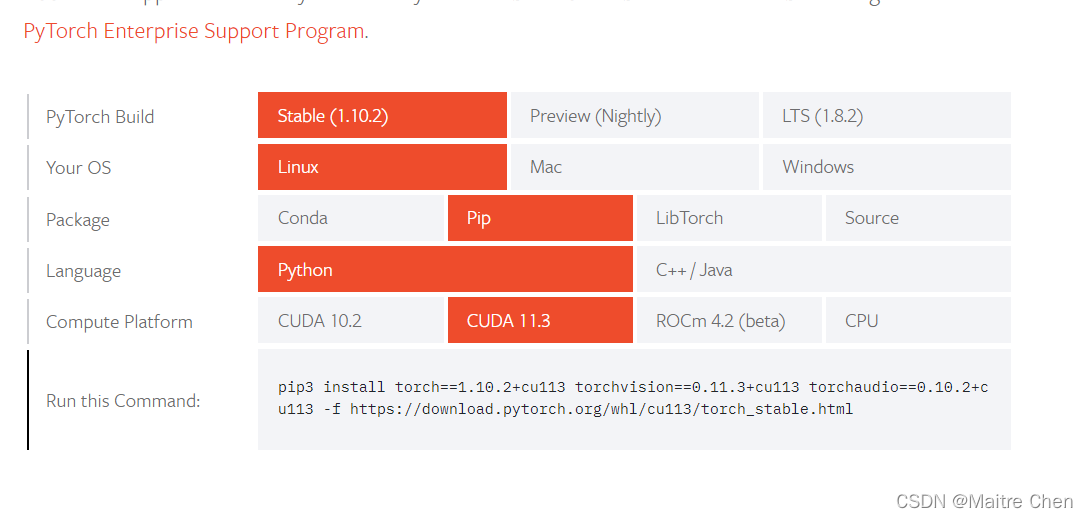 然后切换到虚拟环境,执行安装命令即可,参考如下:
然后切换到虚拟环境,执行安装命令即可,参考如下:
pip3 install torch==1.10.2+cu113 torchvision==0.11.3+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
测试安装,检查是否支持GPU驱动,参考如下:

That's True!!
Everything is OK!!
总结
本次深度学习环境的配置让我再次明白了一个道理:深入到细节是必然的,但更重要的是从整体上去思考问题。有了全局观念,就不会惑于某一个细节。这也是我的老师所强调的。
因此,大家在配置环境时一定要注意自己的系统版本、CUDA与Pytorch以及CUDA 与cuDNN的依赖关系等等 ,这样也不会像笔者一样将CUDA卸载多次才找到了适合的TA~~~~
版权归原作者 Maitre Chen 所有, 如有侵权,请联系我们删除。