
为什么使用scala做分析指标呢?
数据来源:神舟笔记本_淘宝搜索 (taobao.com)
- 五、把各项指标封装成6个类,我这里统计了6给方向的指标分析数据,数据文件在comper/data.jsonl文件里。
一、点击setting 项目设置 ,点击plugins 进入到插件商店,搜索Scala这个插件点击下载,后期可以方便后面构建项目可以使用scala语言分析。
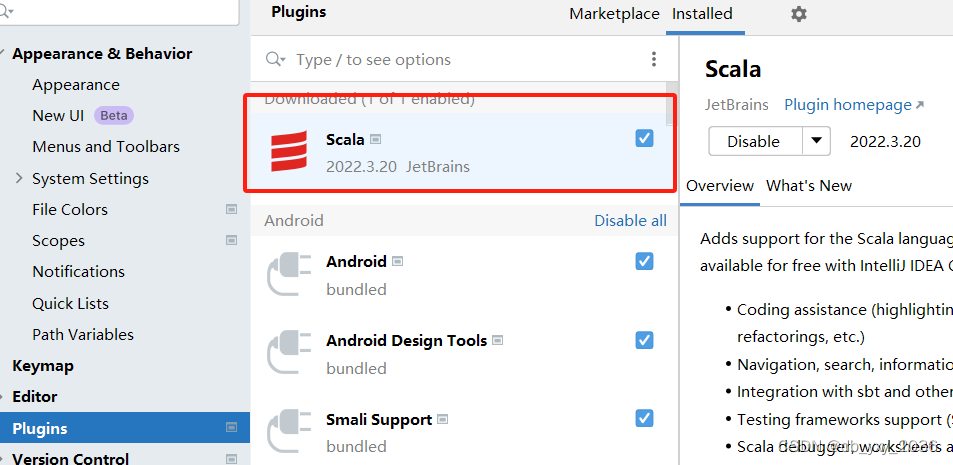
二、新建一个scala项目,building System 选择用idea运行的,jdk选择1.8的 ,sdk版本为2.11.12,点击构建
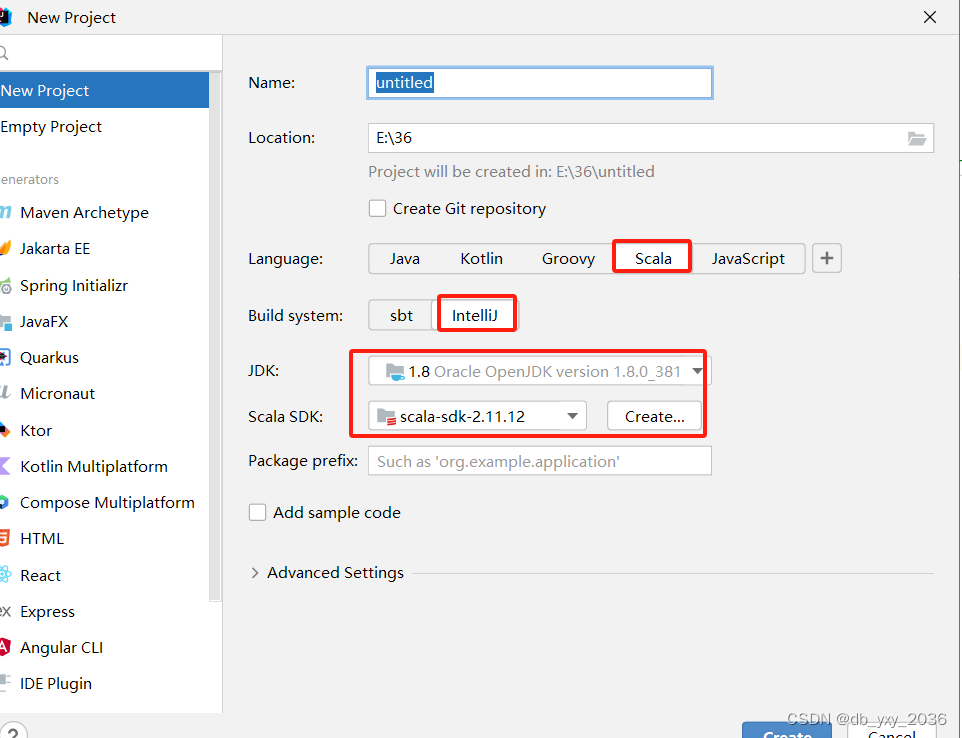
三、导入要使用到的依赖包,有两个依赖包,一个是saprk_lib的 依赖包,这个的作用可以让创建spark这个配置对象idea可以调用,第二个依赖包是scala-2.11.12,这个依赖包可以让你使用scala语言的时候可以识别出来,里面封装了很多的java的包
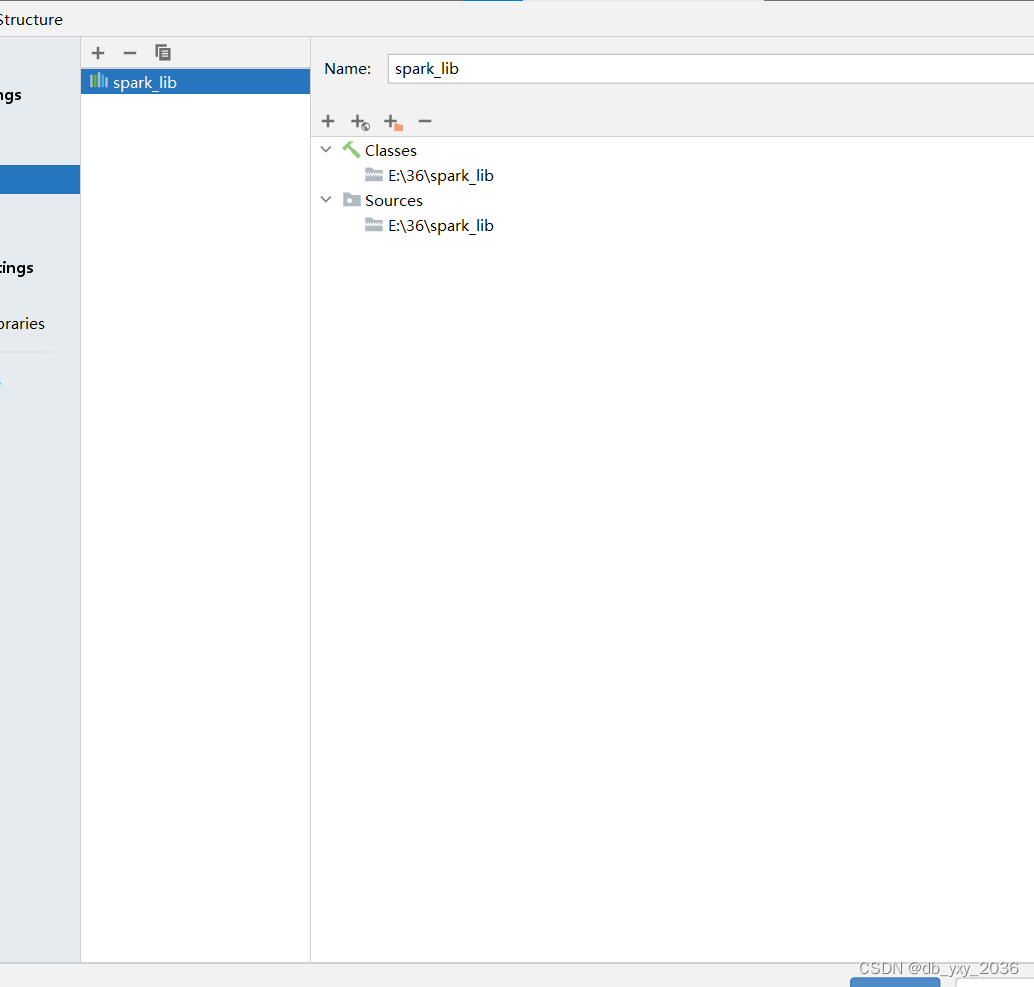
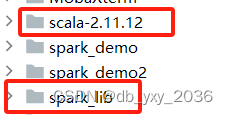
四、在scr文件目录下创建一个page包名为com.lzzy,里面是存放scala类
五、把各项指标封装成6个类,我这里统计了6给方向的指标分析数据,数据文件在comper/data.jsonl文件里。
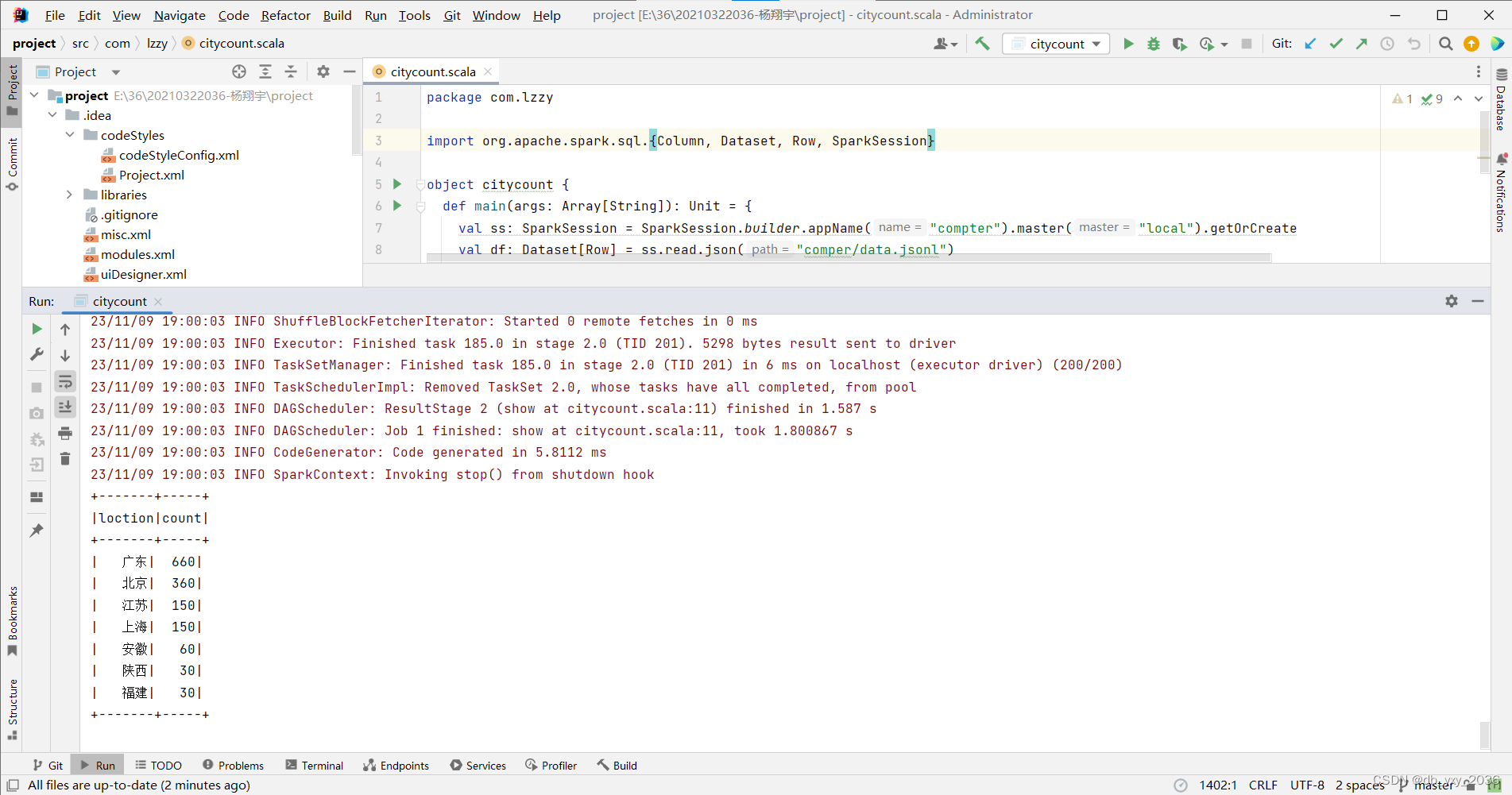
(1) citycount这个类是统计商品信息里面一共有多少个城市,可以更快知道属于某个地方有多少个在卖这个商品,这里用了分组,统计函数、降序、去重操作,统计出来排名各个城市情况。
代码实现:
package com.lzzy
import org.apache.spark.sql.{Column, Dataset, Row, SparkSession}
object citycount {
def main(args: Array[String]): Unit = {
val ss: SparkSession = SparkSession.builder.appName("compter").master("local").getOrCreate
val df: Dataset[Row] = ss.read.json("hdfs://192.168.16.3:9000/input/*")
//统计有多少个城市//统计有多少个城市
val payperson: Dataset[Row] = df.select("loction")
payperson.groupBy("loction").count.dropDuplicates("loction").orderBy(new Column("count").desc, new Column("loction").desc).show()
}
}
实现效果:
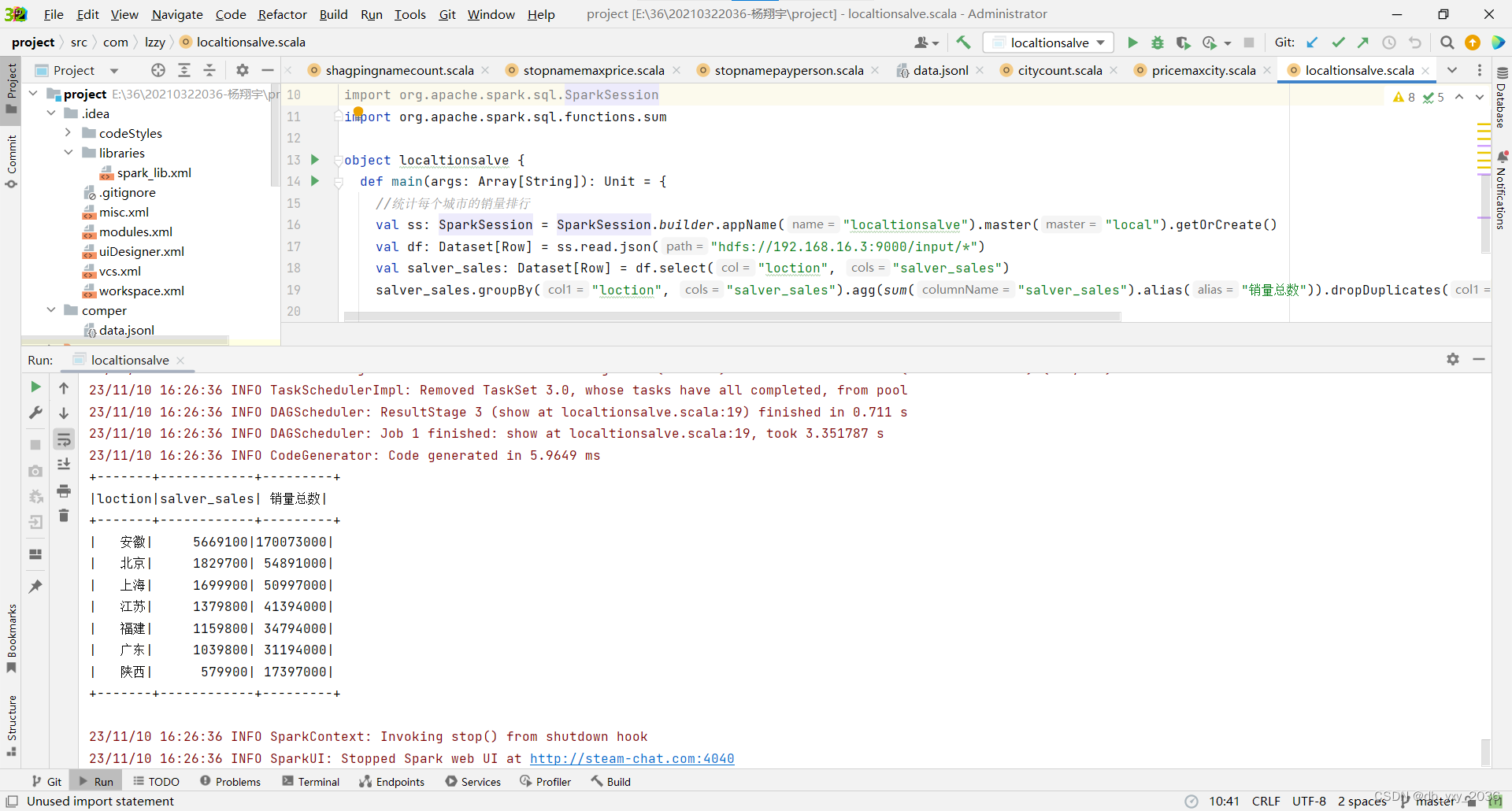
(2)localtionsalve这个类是统计每个城市的销量情况,可以知道哪个城市的经济及商品卖的情况比较好,这里用到了sum求和函数、分组、降序、去重操作。
代码实现:
package com.lzzy
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Column
import org.apache.spark.sql.Dataset
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.sum
object localtionsalve {
def main(args: Array[String]): Unit = {
//统计每个城市的销量排行
val ss: SparkSession = SparkSession.builder.appName("localtionsalve").master("local").getOrCreate()
val df: Dataset[Row] = ss.read.json("hdfs://192.168.16.3:9000/input/*")
val salver_sales: Dataset[Row] = df.select("loction", "salver_sales")
salver_sales.groupBy("loction", "salver_sales").agg(sum("salver_sales").alias("销量总数")).dropDuplicates("loction").orderBy(new Column("销量总数").desc).show()
}
}
实现效果:
(3)pricemaxcity这个类是统计每个城市的最高价格Top10名,把每个城市卖的商品的价格统计起来,从而得知哪一个城市相对来说卖的商品价格信息符合自己需要的,这里用到了sum求和函数、分组、降序、去重操作。
代码实现:
package com.lzzy
import org.apache.spark.sql.functions.sum
import org.apache.spark.sql.{Column, Dataset, Row, SparkSession}
object pricemaxcity {
def main(args: Array[String]): Unit = {
val ss: SparkSession = SparkSession.builder.appName("pricemaxcity").master("local").getOrCreate()
val df: Dataset[Row] = ss.read.json("hdfs://192.168.16.3:9000/input/*")
//统计每个城市的最高价格Top10名
val price: Dataset[Row] = df.select("loction", "price")
price.groupBy("loction", "price").agg(sum("price").alias("总价格")).dropDuplicates("loction").orderBy(new Column("总价格").desc).show(10)
}
}
实现效果: 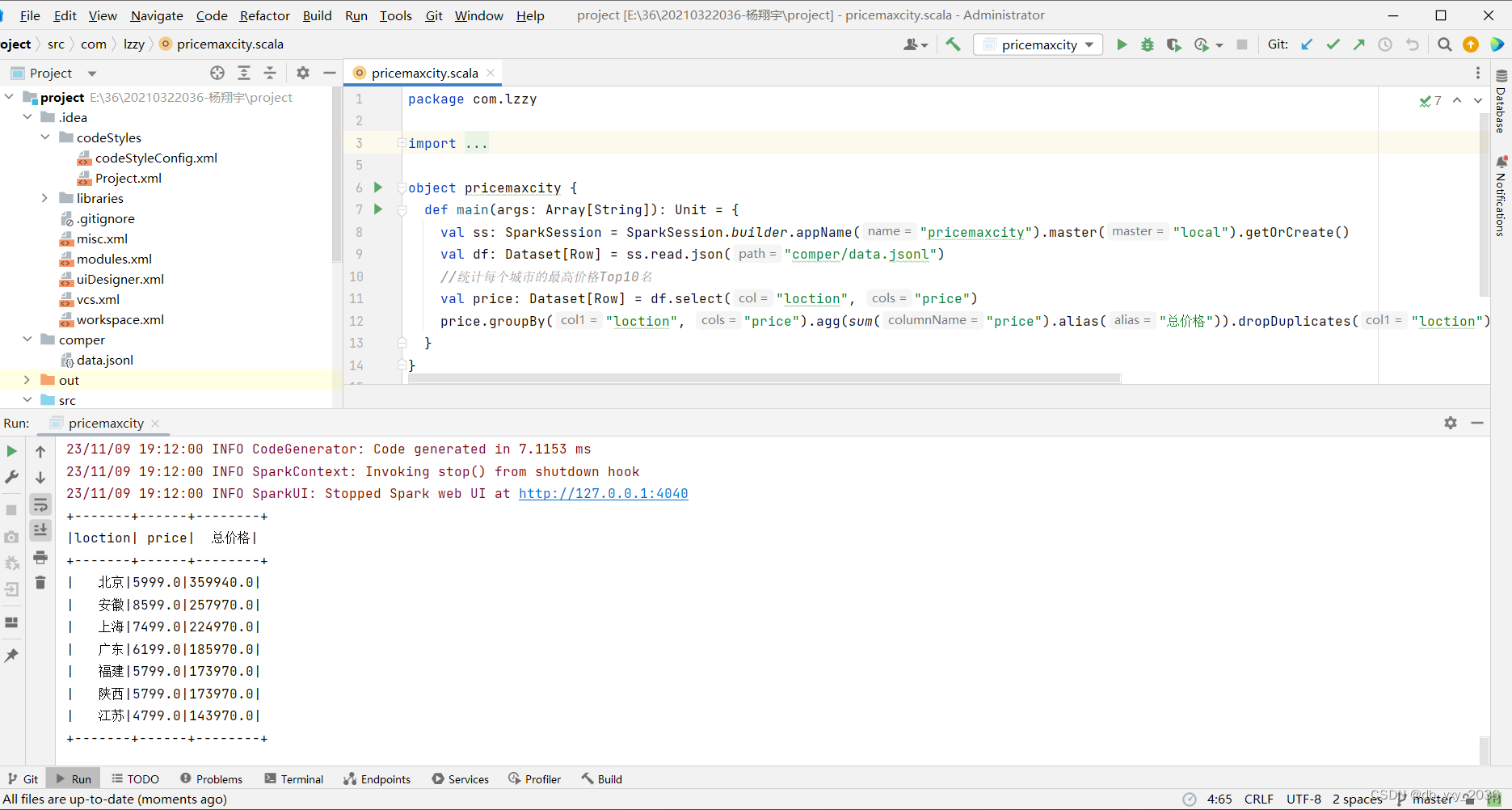
(4)salvestopmax这个类是统计每个店铺的最高销量排名前八名,可以知道哪一个店铺的知名度比较高,这里用到了sum求和函数、分组、降序、去重操作。
代码实现:
package com.lzzy
import org.apache.spark.sql.{Column, Dataset, Row, SparkSession}
import org.apache.spark.sql.functions.sum
object salvestopmax {
def main(args: Array[String]): Unit = {
//统计每个店铺的最高销量排名前八
val ss: SparkSession = SparkSession.builder.appName("stopnamepayperson").master("local").getOrCreate()
val df: Dataset[Row] = ss.read.json("hdfs://192.168.16.3:9000/input/*")
val stopname = df.select("salver_sales", "stopname")
stopname.groupBy("stopname", "salver_sales").agg(sum("salver_sales").alias("销量总数")).dropDuplicates("stopname").orderBy(new Column("销量总数").desc, new Column("stopname").desc).show(8)
}
}
实现效果:
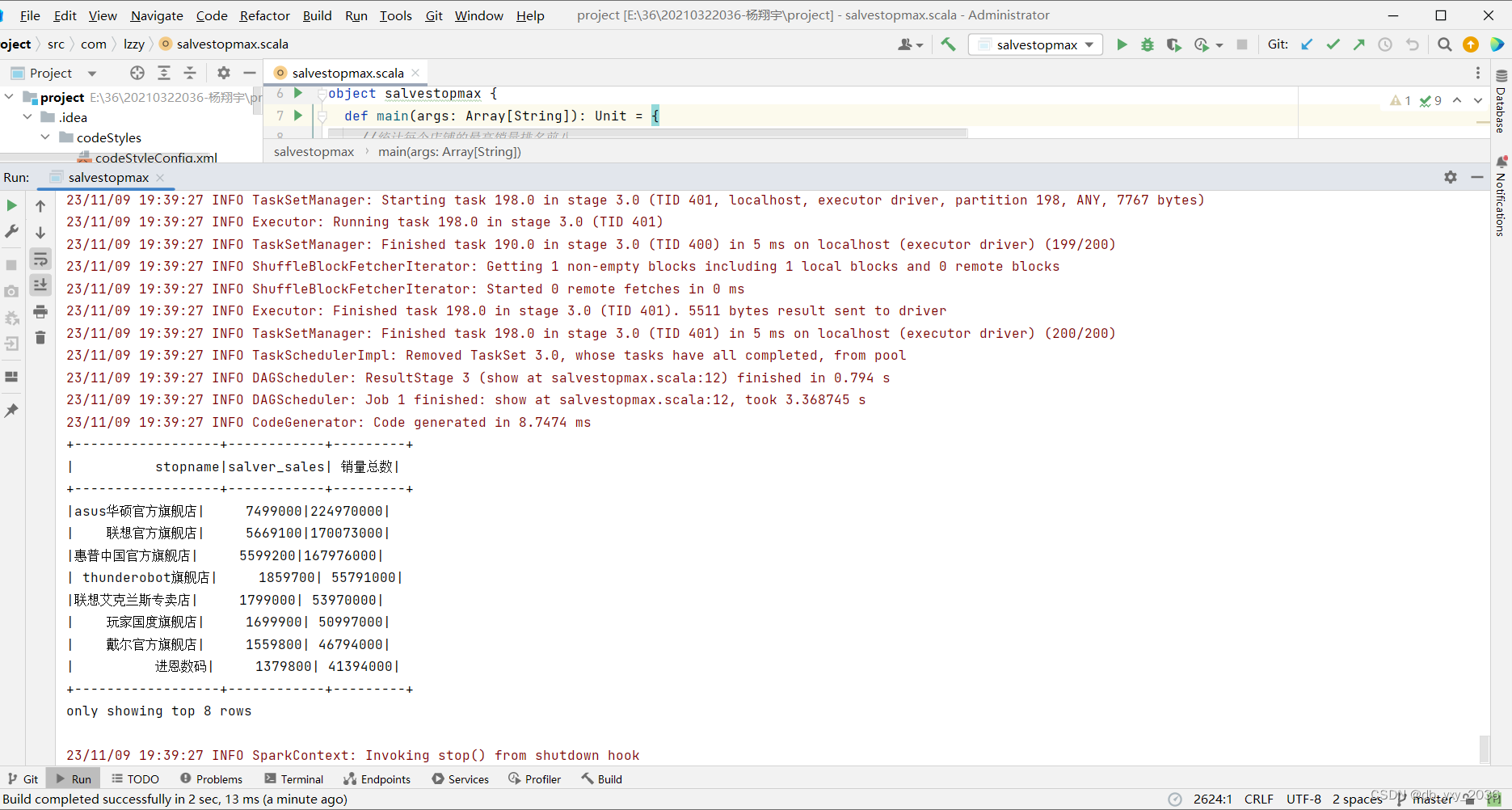
(5)stopnamemaxprice 这个类店铺的最高价格Top五名,店铺所在的地点展示,可以知道选择从哪一家的店铺的价格比较合适,这里用到了sum求和函数、分组、降序、去重操作。
代码实现:
package com.lzzy
import org.apache.spark.sql.{Column, Dataset, Row, SparkSession}
import org.apache.spark.sql.functions.sum
object stopnamemaxprice {
def main(args: Array[String]): Unit = {
val ss: SparkSession = SparkSession.builder.appName("compter").master("local").getOrCreate
val df: Dataset[Row] = ss.read.json("hdfs://192.168.16.3:9000/input/*")
//统计每个店铺的最高价格Top五名,店铺所在的地点展示
val pricestopname: Dataset[Row] = df.select("price", "stopname", "loction")
pricestopname.groupBy("price", "stopname", "loction").agg(sum("price").alias("价格总数")).dropDuplicates("stopname").orderBy(new Column("价格总数").desc, new Column("loction").desc).show(5)
}
}
实现效果:
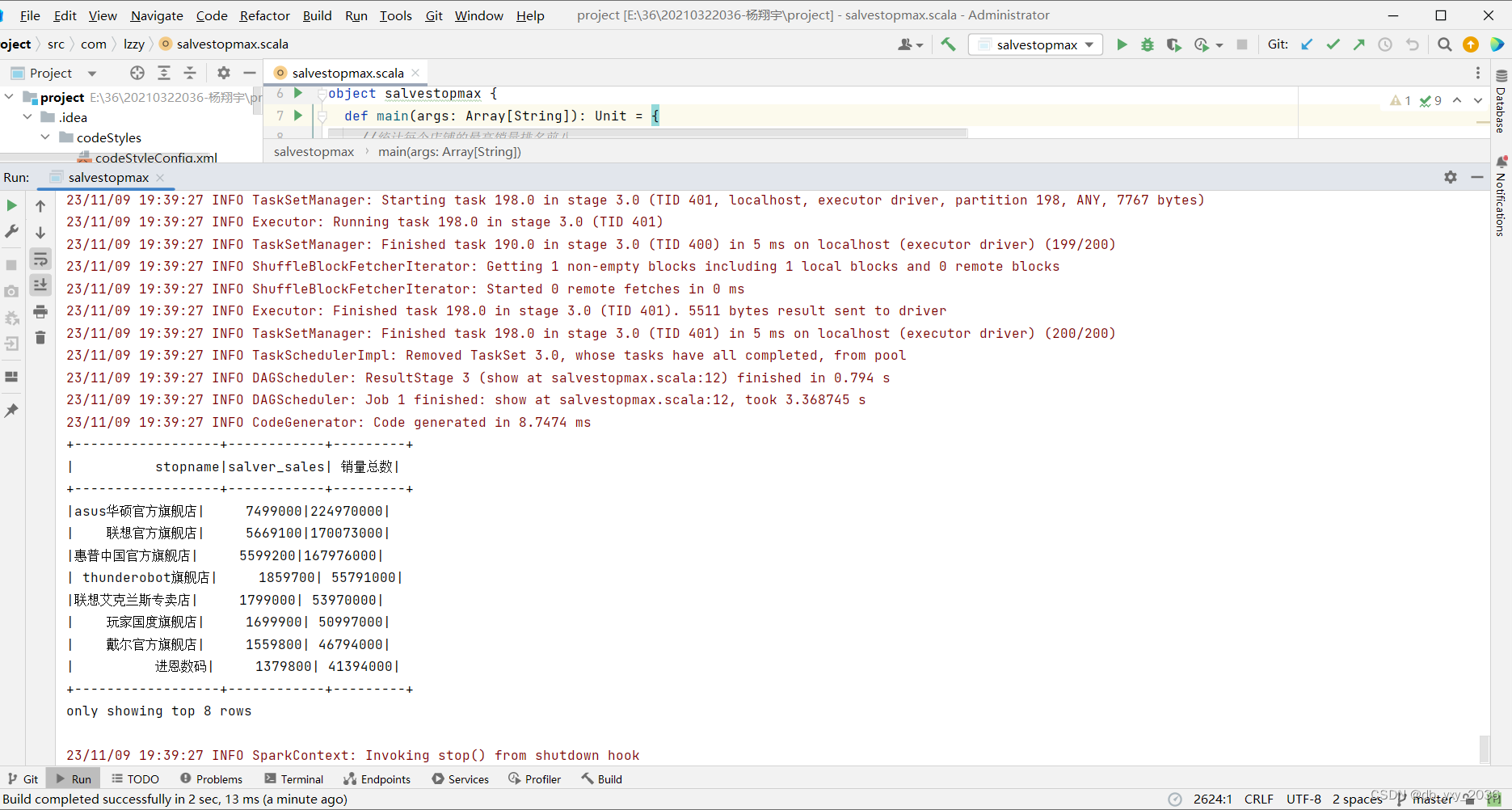
(6)stopnamepayperson这个类统计价格大于500的付款人数店铺,可以知道哪家的店铺最受欢迎,这里用了分组,统计函数、降序、去重操作,统计出来排名各个城市情况
代码实现:
package com.lzzy
import org.apache.spark.sql.{Column, Dataset, Row, SparkSession}
object stopnamepayperson {
def main(args: Array[String]): Unit = {
val ss: SparkSession = SparkSession.builder.appName("stopnamepayperson").master("local").getOrCreate()
val df: Dataset[Row] = ss.read.json("hdfs://192.168.16.3:9000/input/*")
//统计价格大于500的付款人数店铺
val city: Dataset[Row] = df.where("payperson>500")
val select: Dataset[Row] = city.select( "stopname")
select.groupBy("stopname").count.dropDuplicates("stopname").orderBy(new Column("count").desc).show()
}
}
实现效果: 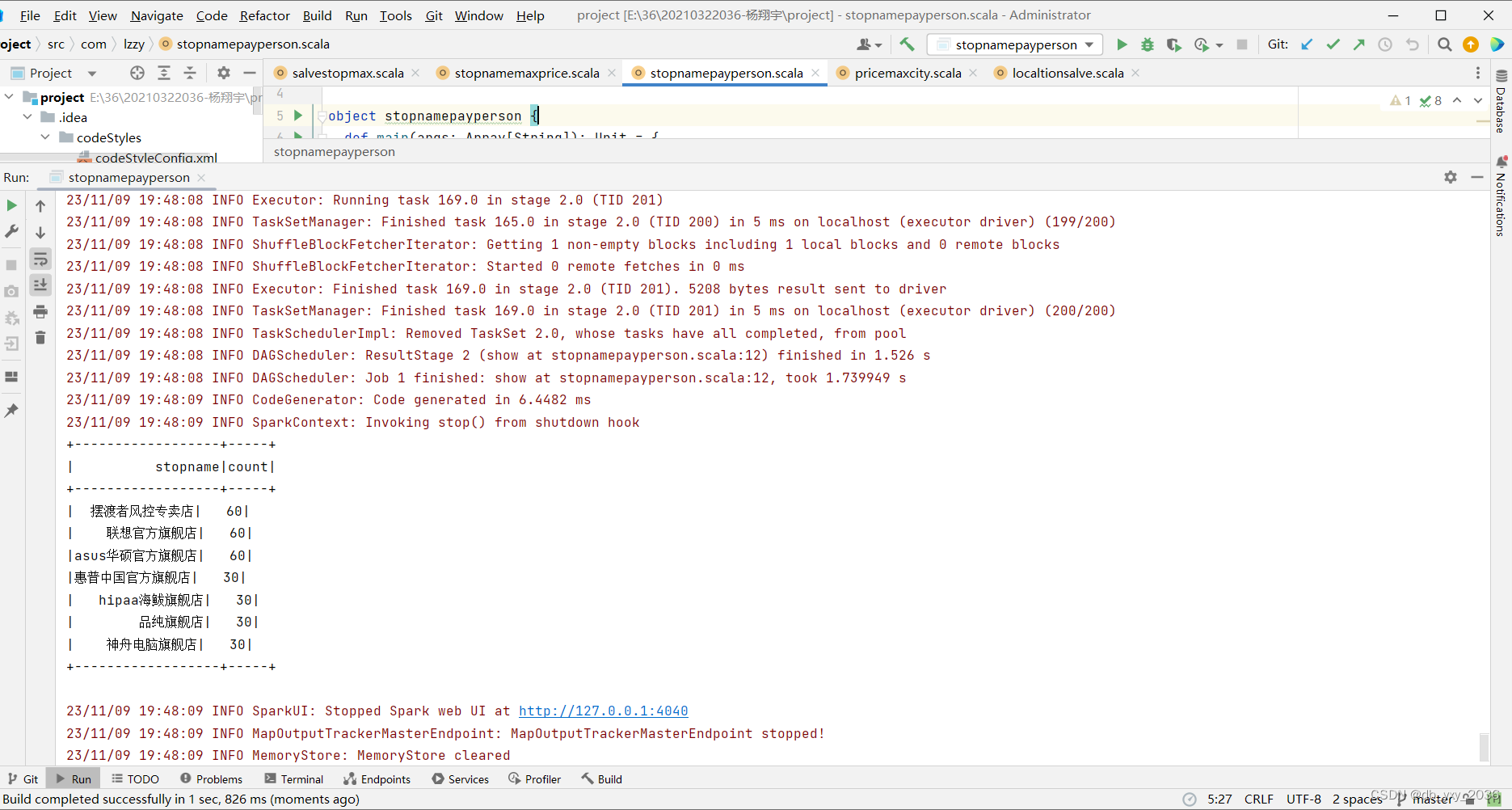
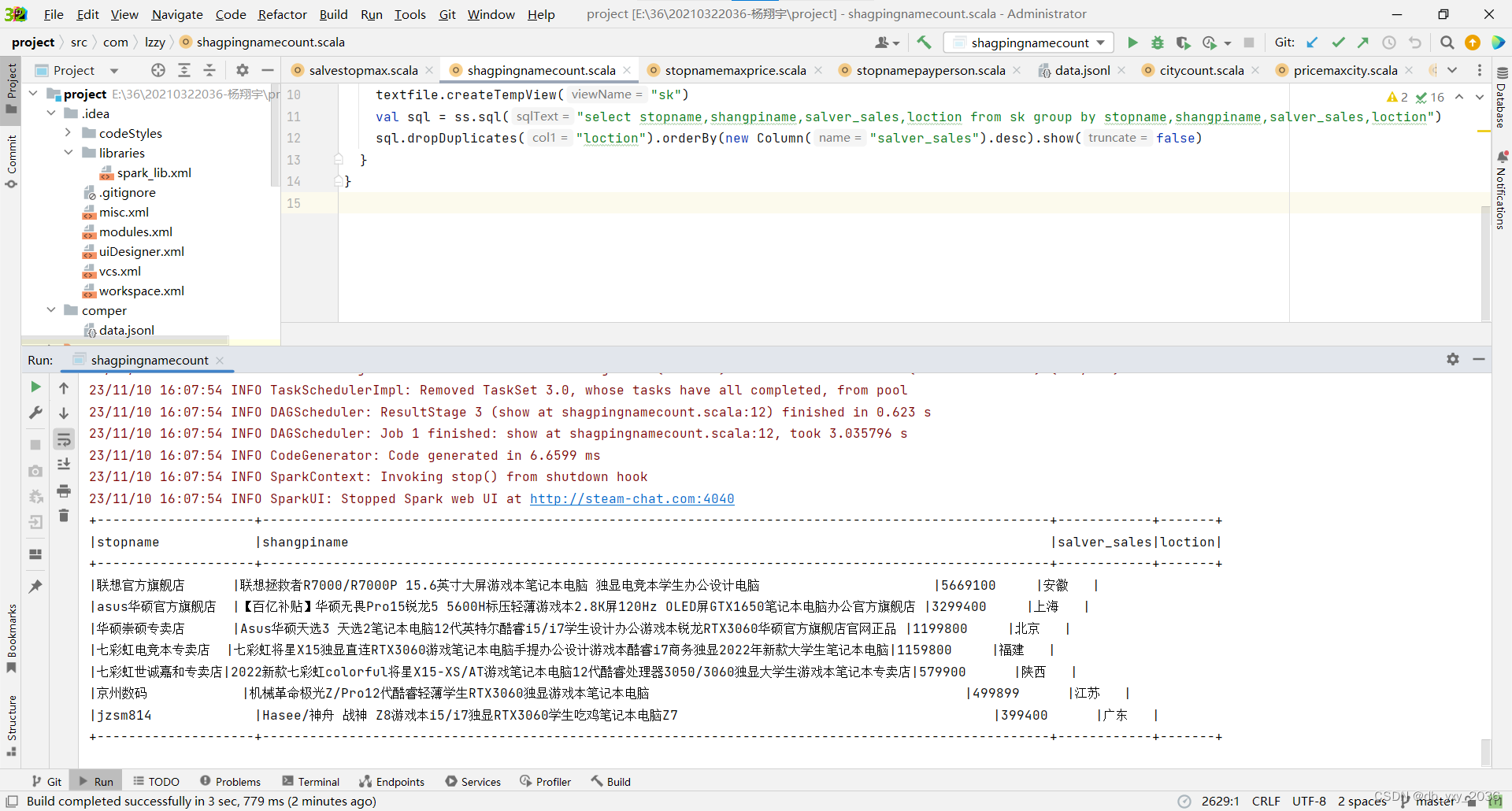
(7)shagpingnamecount这个类是统计每一个城市哪一家店铺的哪一个商品买的最好,这里使用了开窗函数,sql语句查询出来然后分组统计聚合
代码实现:
package com.lzzy
import org.apache.spark.sql.{Column, Dataset, Row, SparkSession}
object shagpingnamecount {
def main(args: Array[String]): Unit = {
val ss = SparkSession.builder.appName("compter").master("local").getOrCreate
val textfile = ss.read.json("comper/data.jsonl")
//Dataset<Row> where = textfile.select("loction='北京'");//Dataset<Row> where = textfile.select("loction='北京'");
textfile.createTempView("sk")
val sql = ss.sql("select stopname,shangpiname,salver_sales,loction from sk group by stopname,shangpiname,salver_sales,loction")
sql.dropDuplicates("loction").orderBy(new Column("salver_sales").desc).show(false)
}
}
实现效果 :
六、总结
学习了spark之后我才知道Hadoop和spark还有着这种缘分:Hadoop 是由Java语言编写的,部署在分布式服务器集群上,用于存储海量数据并运行分布式分析应用的开源框架;其重要组件有,HDFS 分布式文件系统、MapReduce 编程模型、Hbase 基于HDFS的分布式数据库:擅长实时随机读/写超大规模数据集。
由于上半学期的松懈,对于Hadoop的知识掌握的不是很好,所以在下半学期一边学习Spark一边学习Hadoop,对于他们的掌握有了显著的提升。我知道了Spark重要的内置模块:Spark Core:包括了内存计算、任务调度、部署模式、故障恢复、存储管理等;Spark SQL:统一处理关系和RDD,使用SQL命令进行数据分析;Spark Streaming:将流式计算分解为一系列的短小的批处理作业,支持多种数据源。
要学习好spark,scala语言的学习至关重要,scala语言是一门非常简洁的语言,但是这种简洁也给我带来很多苦恼,我时常不能分辨这些参数对应着谁,每每看到已经是脑袋空白啦!! 学习Spark需要将基础和实践结合起来,很多的基础知识在Hadoop中基础知识之上进行学习,只有去体验实际操作才能体会到区别。整个Spark讲的知识点不是很多,但是关键在于去理解,每个模块如何去工作、怎么去使用。
从Spark的上手到最后的项目,整个过程我一路磕磕绊绊的时常遇到一些奇怪的问题,但是好在本人寻找bug的能力还不错,都一一得到了解决,后半期学习结束了,但我还需要继续花时间去学习,尤其是Hadoop的知识点,结合两者的实际应用去体会不同。目前做的项目中还是用的Hadoop为主,Spark还是初期新项目中使用,因此两个都需要学好。
从大数据课程学习下来,体会到在平时的学习中需要经常记下错误和进度,时间长了容易忘记。需要能养成一个好的习惯,每天学的东西无论多少都学下来,最后项目结束再回头看,就会很容易解决当时的困难。接下来的时间,要继续学习好Hadoop和Spark,已经以后进行扩展其他的相关技术,愿你我走得更远!!!
版权归原作者 db_yxy_2036 所有, 如有侵权,请联系我们删除。