
目录
本文基于Pentaho的kettle模块实现ETL功能,在spoon中实现创建、定义作业,记录作业job的两种处理并行作业项的方法。
1. kettle简介
1.1 Pentaho、kettle、Spoon
Pentaho是一个以工作流为核心的、强调面向解决方案的开源商业智能(Business Intelligence, BI)套件,以构成全面的数据集成和业务分析平台。这些套件各自为独立产品,之间为松耦合可插拔式设计,用户可根据自身需求进行灵活选择。Kettle是Pentaho整个产品体系中的数据集成模块,使用突破性的元数据驱动方法提供强大的“提取,转换和加载(ETL)”功能。主要使用在数据仓库环境下,同时还可以:在应用程序或数据库之间进行数据迁移、将数据从数据库中导出到文本文件中、将大量数据加载到数据库中、数据清理、应用程序集成等。作为最受欢迎的开源ETL工具,其支持大量的输入和输出格式,包括文本文件、数据表,以及各类商业或开源的数据库引擎。除此之外,Kettle还易于使用,用户可通过图形化界面Spoon定义任务或转换,无需编写代码。当然,Kettle支持用户使用脚本语言定义更加丰富的个性化功能。
1.2 kettle的作业(Job)
转换(Transformation) 和 作业(Job)是Spoon设计器的核心两个内容,这两块内容构建了整个Kettle工作流程的基础。
参考链接:Kettle的控件分为2种:作业(Job)和转换(Transform)
本文围绕作业(Job)展开。一个作业包括一个或多个作业项,作业项之间用跳(Job Hop)来连接。作业的执行顺序由跳,以及每个作业项的执行结果来决定,用户可以自定义。
针对作业项的执行结果,作业跳有以下情形:
无条件执行,无论上一个作业项执行成功与否,下一个作业都会执行,如上图,为其中蓝色带锁的连接线;
当运行结果为真时执行,当上一个作业项执行成功时,才执行下一个作业项,如上图,为其中绿色带对号的连接线;
当运行结果为假时执行,当上一个作业项执行失败时,执行下一个作业项,如上图,为其中红色带叉号的连接线。
作业中的作业项也使用图标的方式进行图形化展示。用户可以复制出作业项的多个影子拷贝,影子拷贝的配置信息都是一样的,编辑一份拷贝其它拷贝也会随之修改。与转换不同,作业中作业项之间并不是数据流的传递。作业项之间可传递一个结果对象(Result Object),从而来实现相互之间的数据传递。结果对象类似于数据库中的一张表,其中包含字段与数据集。默认情况下,作业项之间是以串行的方式执行,需等一个作业项完全执行结束,才将结果对象传递给下一个作业项执行。
因为作业是可以相互嵌套的,一个作业可以作为另外一个作业的作业项,因此作业也要同作业项一样有运行结果。一个作业的运行结果来自于它最后一个执行的作业项。
参考链接:Pentaho 数据集成工具——Kettle
2. 问题描述
首先给出一个案例,可以看出该作业的执行逻辑是,在作业项Step1结束后Step2的3个作业项21、22、23并行执行,作业项Step31需要基于21和23的结果表,作业项32需要基于22和23的结果表,后面的Step5则是需要在Step4和Step32结束后执行。
由于kettle没有自带的处理并行等待作业,只要并行跑起来,就会全部执行下一步,不管其他的并行作业是否跑完,在这个作业中就可能造成下面的错误:
(1)执行作业项Step31时依赖的作业项21或23中一个执行完另一个未执行完毕,则Step31报错会提示找不到21或23的结果表
(2)同理,执行作业项Step32时,可能会报错找不到作业项22或23的结果表
(3)同理,执行作业项Step5时,可能会报错找不到作业项32或4的结果表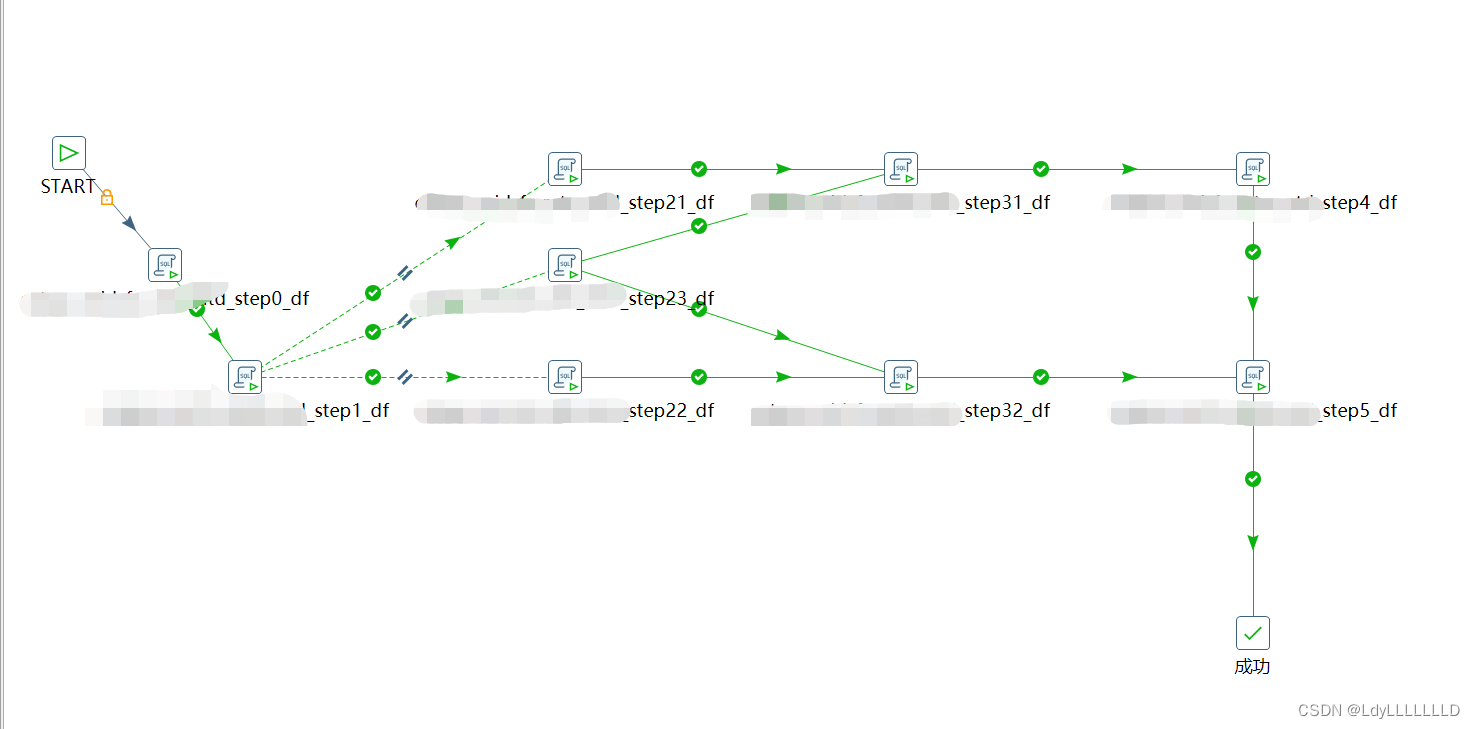
因此需要改正作业流程,使得在job作业中执行完全部并行作业项后,才开始下一步作业项的执行。
3. 解决方法
3.1 方法1:采用set_count等组件
给出下面案例,该工作流中包含2次并行作业项。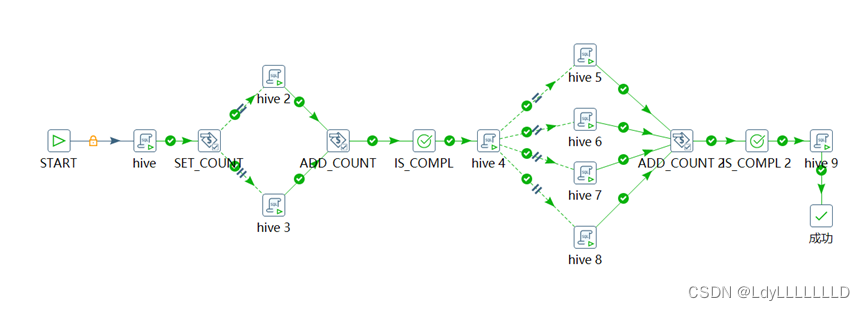
第一步,添加对象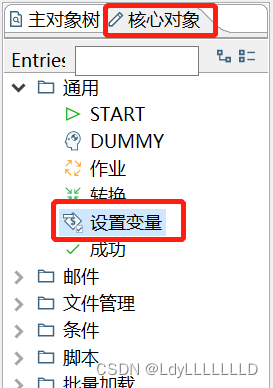
第二步,设置参数
SET_COUNT: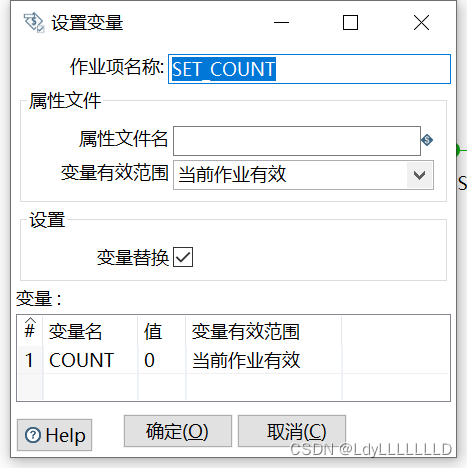
ADD_COUNT: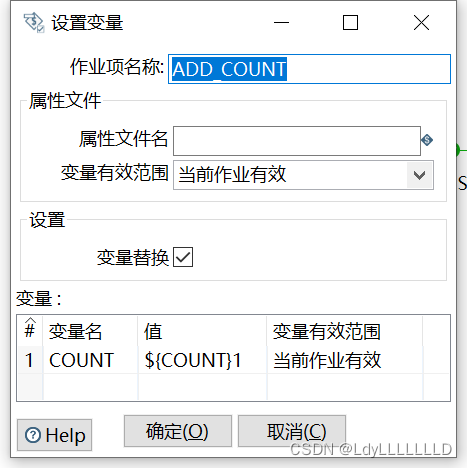
IS_COMPL:(注意有几个需要并行的作业,就有几个‘1’)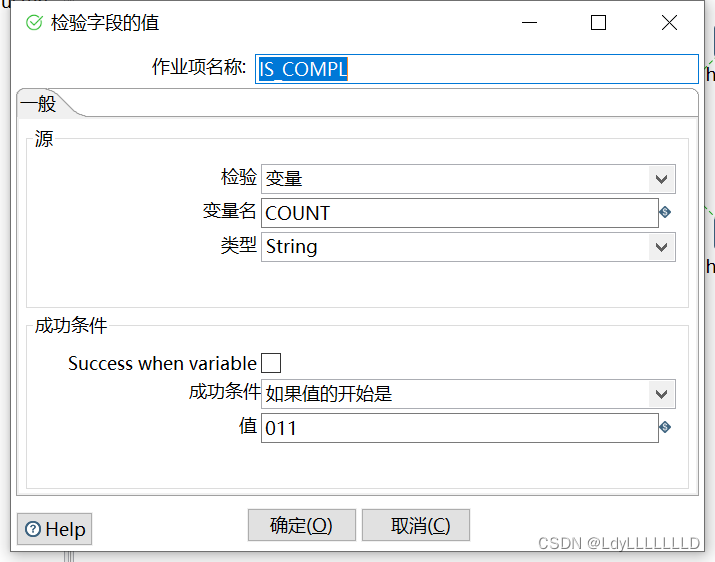
并行作业项第二部分
ADD_COUNT 2: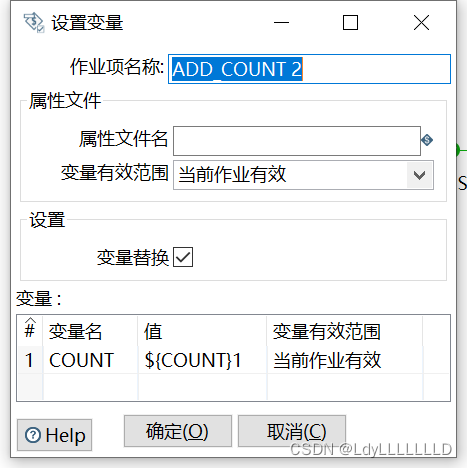
IS_COMPL 2:(6个1)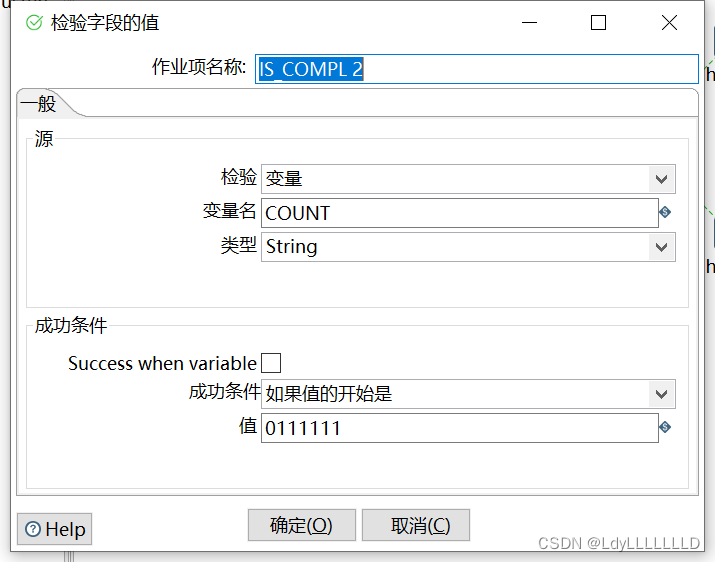
参考链接:kettle的job里面怎么并行跑作业(作业流中1次并行作业项)
3.2 方法2:采用wait for sql 实现对并行流程的等待
还是上面提到的案例。
第一步 delete record
需要先在该作业外建立一个表,比如hive中建表。
createtableifnotexiststemp.temp_kettle_job_paralle_exe_step22_23
asselect'temp_kettle_job_paralle_exe_step23'as job_name;
在作业项Step0中,代码执行前要把上面建立的表清空,即在正式代码前加上下面语句
truncatetabletemp.temp_kettle_job_paralle_exe_step22_23;
第二步 insert first record
本支线的任务执行完,插入一条记录“temp_kettle_job_paralle_exe_step21”到表中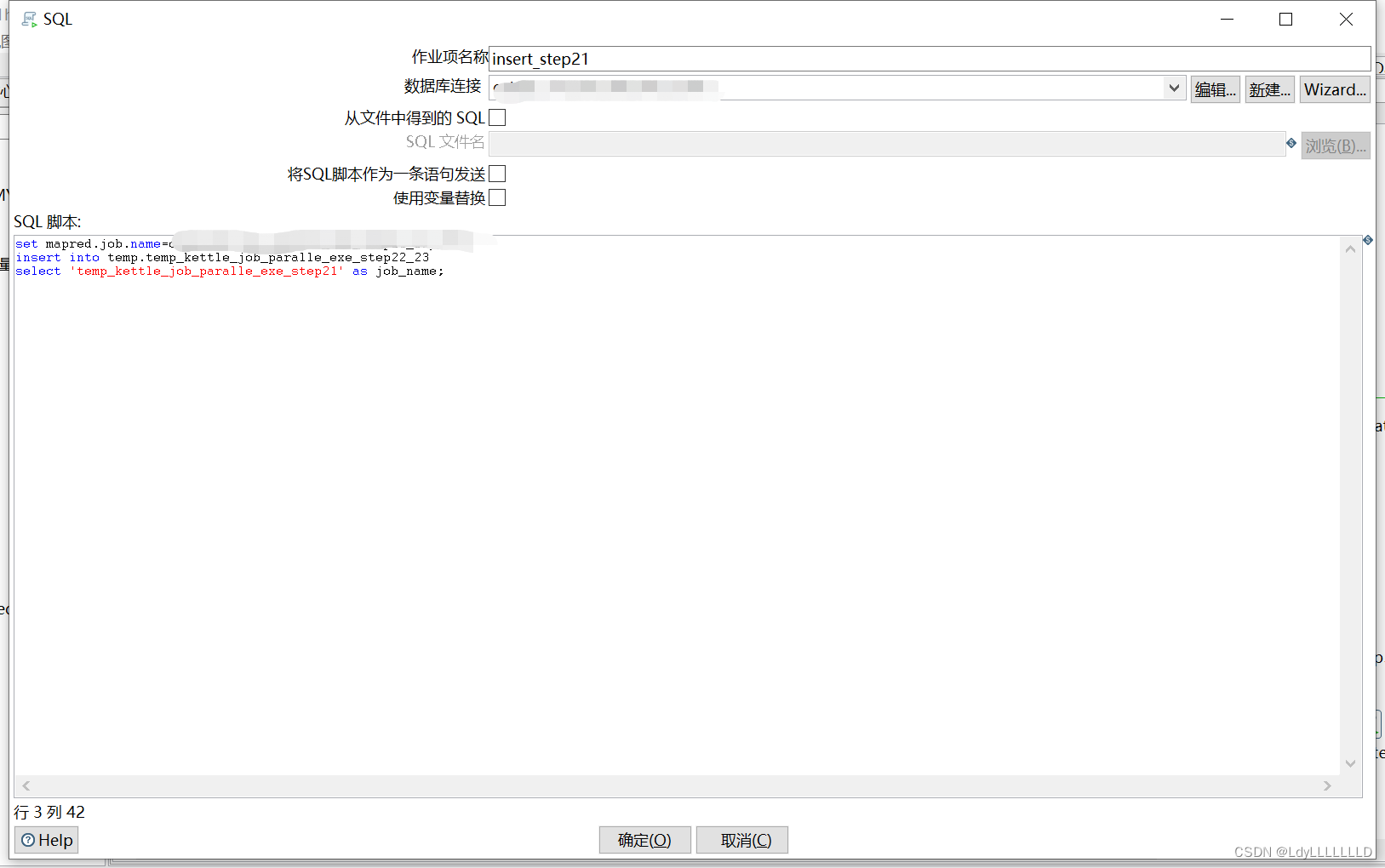
本支线的任务执行完,插入一条记录“temp_kettle_job_paralle_exe_step23”到表中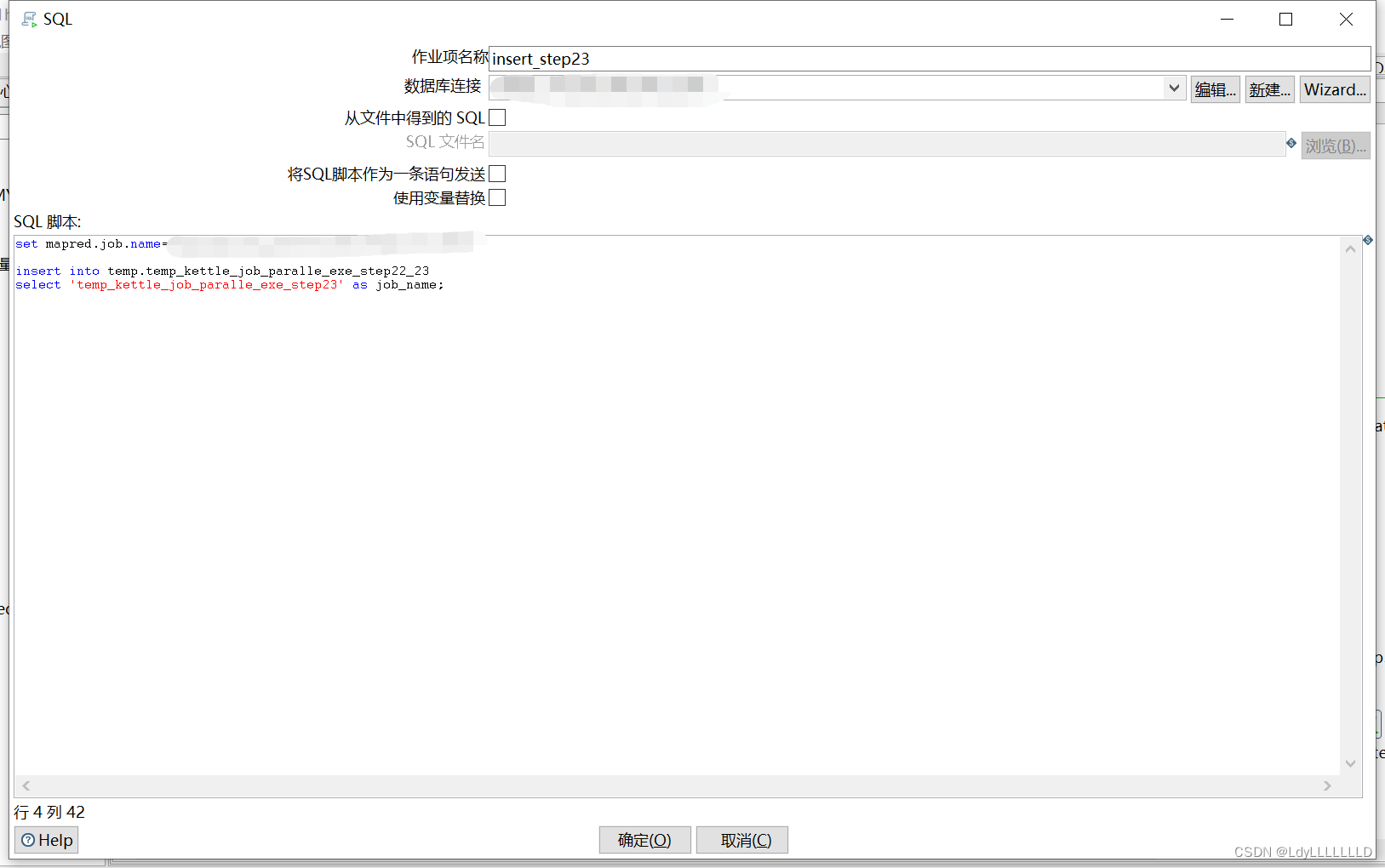
本支线的任务执行完,插入一条记录“temp_kettle_job_paralle_exe_step22”到表中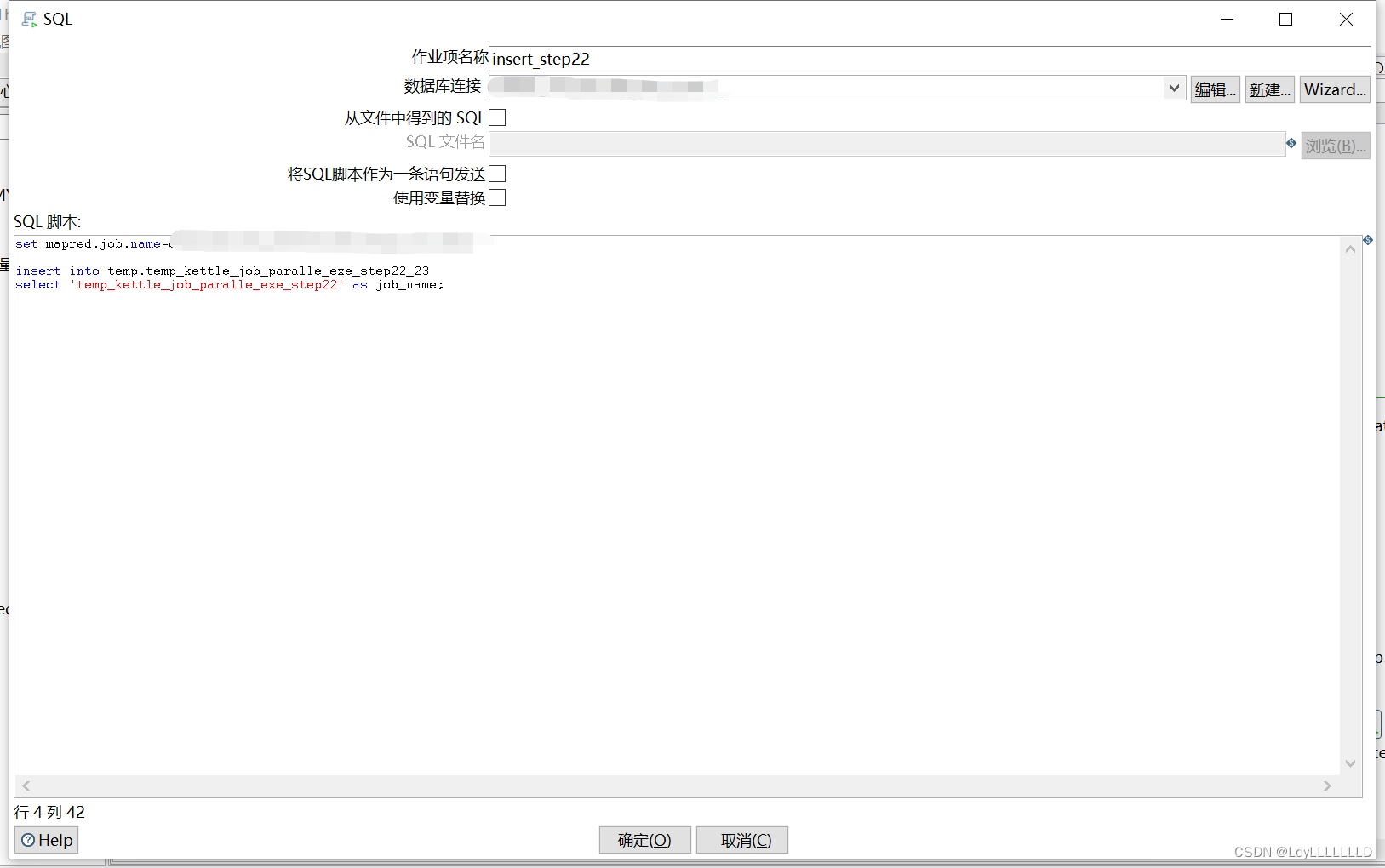
第三步 wait for sql
等待三个并行支线都完成任务,对表进行判断,只有满足3条记录才会执行下一步。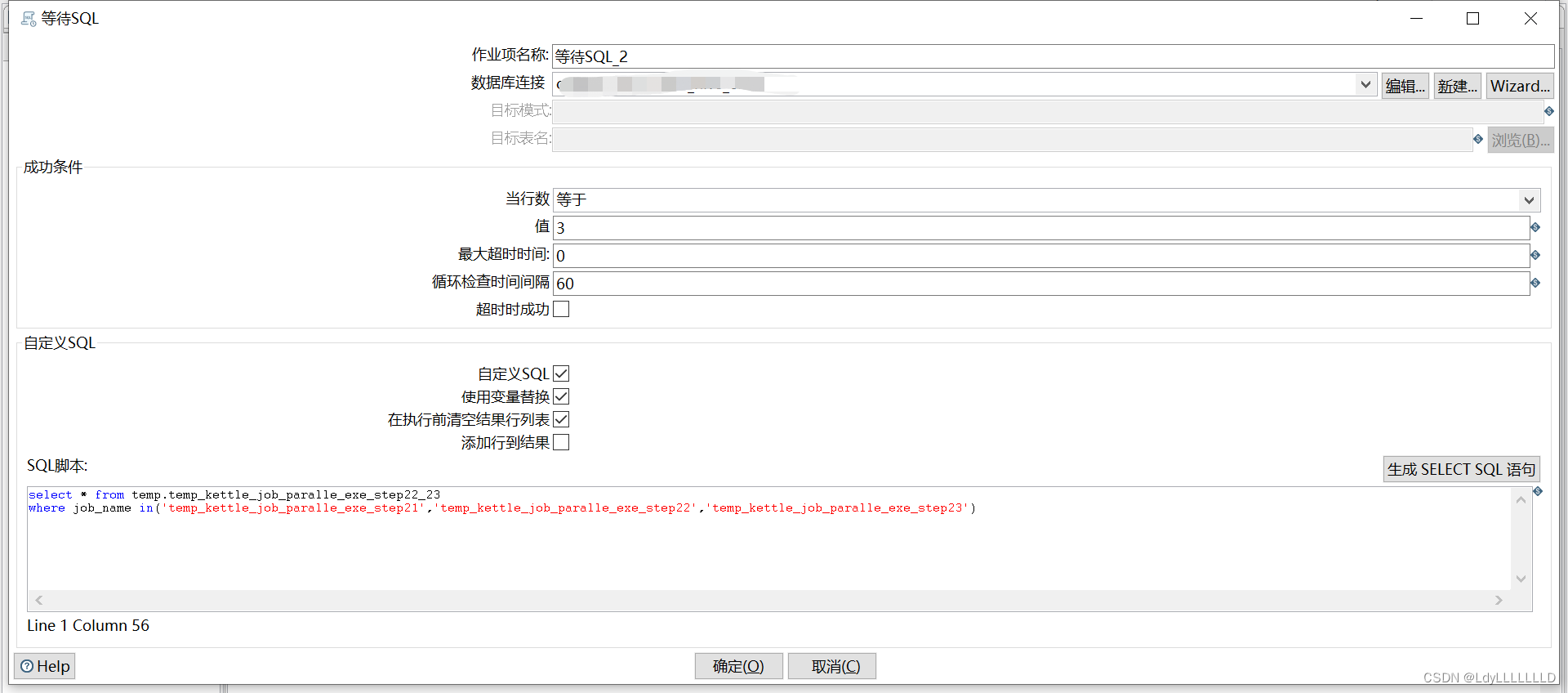
最大超时时间:设置的等待时间,如果在此时间内不满足条件就会认为failed。
超时时成功:选中此项后,当超过“最大超时时间”时间后,也不会判failed,会判success。0表示不限时间。
注意事项:
为了避免并行的作业/转换任何一个失败,任务就卡住的情况,在两个并行的作业中加入了“中止作业”,任何一个支线失败,整个任务就失败了。
参考链接:kettle(Pentaho)job作业并行都执行完后再执行下一步的操作
版权归原作者 LdyLLLLLLLD 所有, 如有侵权,请联系我们删除。