
文章目录
1.4 Hadoop优势(4高)
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ULYQYE9Z-1659240575041)(../../../Pictures/hadoop/image-20220731120238827.png)]](https://img-blog.csdnimg.cn/f95662c1b5234b649a855cee6da554d4.png)
2)高扩展性:在集群间分配任务数据,可方便的扩展数以干计的节点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X1fnGUiE-1659240575041)(../../../Pictures/hadoop/image-20220731120246276.png)]](https://img-blog.csdnimg.cn/3518d3f40f8d4857b4eae46fbdbb544e.png)
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FPIQLIJ9-1659240575042)(../../../Pictures/hadoop/image-20220731120259457.png)]](https://img-blog.csdnimg.cn/28a52c0e9ec141a893eb4d7ea084ca90.png)
4)高容错性:能够自动将失败的任务重新分配。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Knueb8KG-1659240575042)(../../../Pictures/hadoop/image-20220731120308704.png)]](https://img-blog.csdnimg.cn/dc62bde12d5b44eda7768ec9d31f2268.png)
1.5 Hadoop组成(面试重点)
- 在Hadoopl.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
- 在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度MapReduce只负责运算。
- 在Hadoop3.x时代,在组成上没有变化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wPtzyIjk-1659240575043)(../../../Pictures/hadoop/image-20220731120416608.png)]](https://img-blog.csdnimg.cn/794a0b6087674344978cace93b486fca.png)
1.5.1 HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、
文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DatalNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
1.5.2 YARN架构概述
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P4CTRpSY-1659240575043)(../../../Pictures/hadoop/image-20220731120555357.png)]](https://img-blog.csdnimg.cn/047d11281ab242e99ede257296ad14e7.png)
1.5.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-esY3HLB7-1659240575043)(../../../Pictures/hadoop/image-20220731120625929.png)]](https://img-blog.csdnimg.cn/67d201300edc4e44ac020e3b7248affd.png)
1.5.4 HDFS、YARN、MapReduce三者关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fHLs0l5L-1659240575044)(../../../Pictures/hadoop/image-20220731120637947.png)]](https://img-blog.csdnimg.cn/fc40db00e3c545a7ae6bfb8723108ff6.png)
1.6 大数据技术生态体系
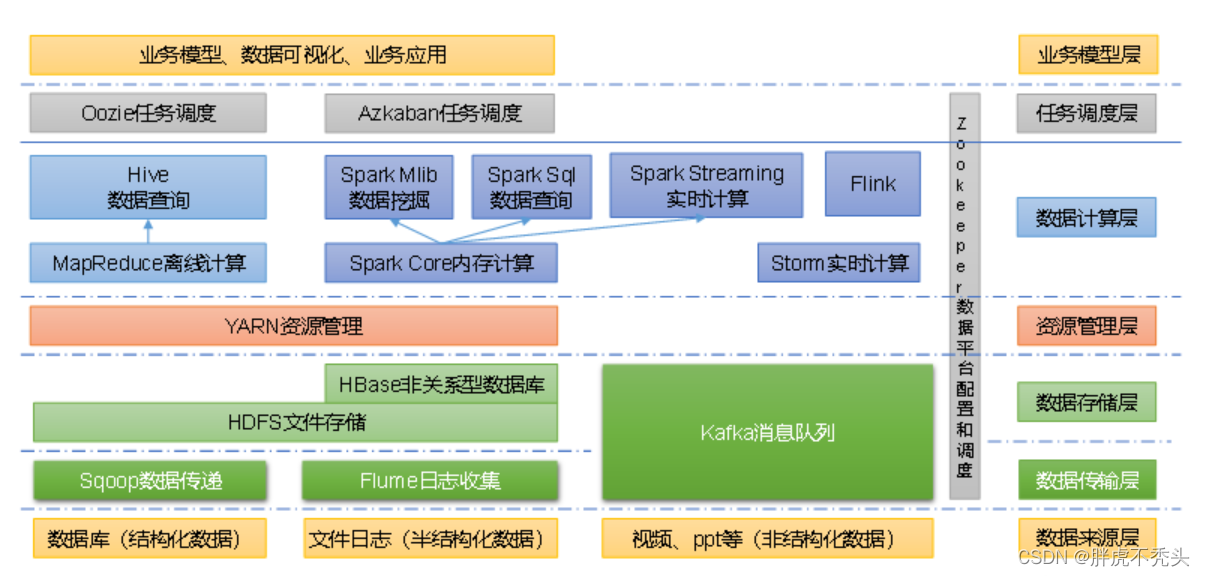
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie是一个管理Hadoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
1.7 推荐系统框架图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aHDwuxVx-1659240575045)(../../../Pictures/hadoop/image-20220731120742356.png)]](https://img-blog.csdnimg.cn/6f5fa473501a45fcad7c258ac4c40c4b.png)
版权归原作者 胖虎不秃头 所有, 如有侵权,请联系我们删除。