
前言
最近有一些需求,需要抢一些东西,自己用代码写了个脚本。然后现在写个文章记录一下。我争取用最简单的话来写出代码,代码已经脱敏处理,如果要转载,请联系我征求同意。
环境配置
代码运行环境
使用conda虚拟环境,用的python3.9.6,安装pip的包是:msedge-selenium-tools==3.141.4,使用的浏览器是Edge。
需要下载的东西
点击跳转下载
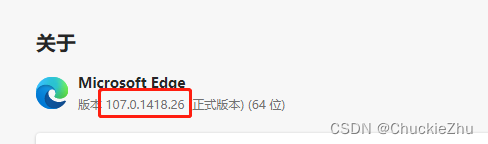
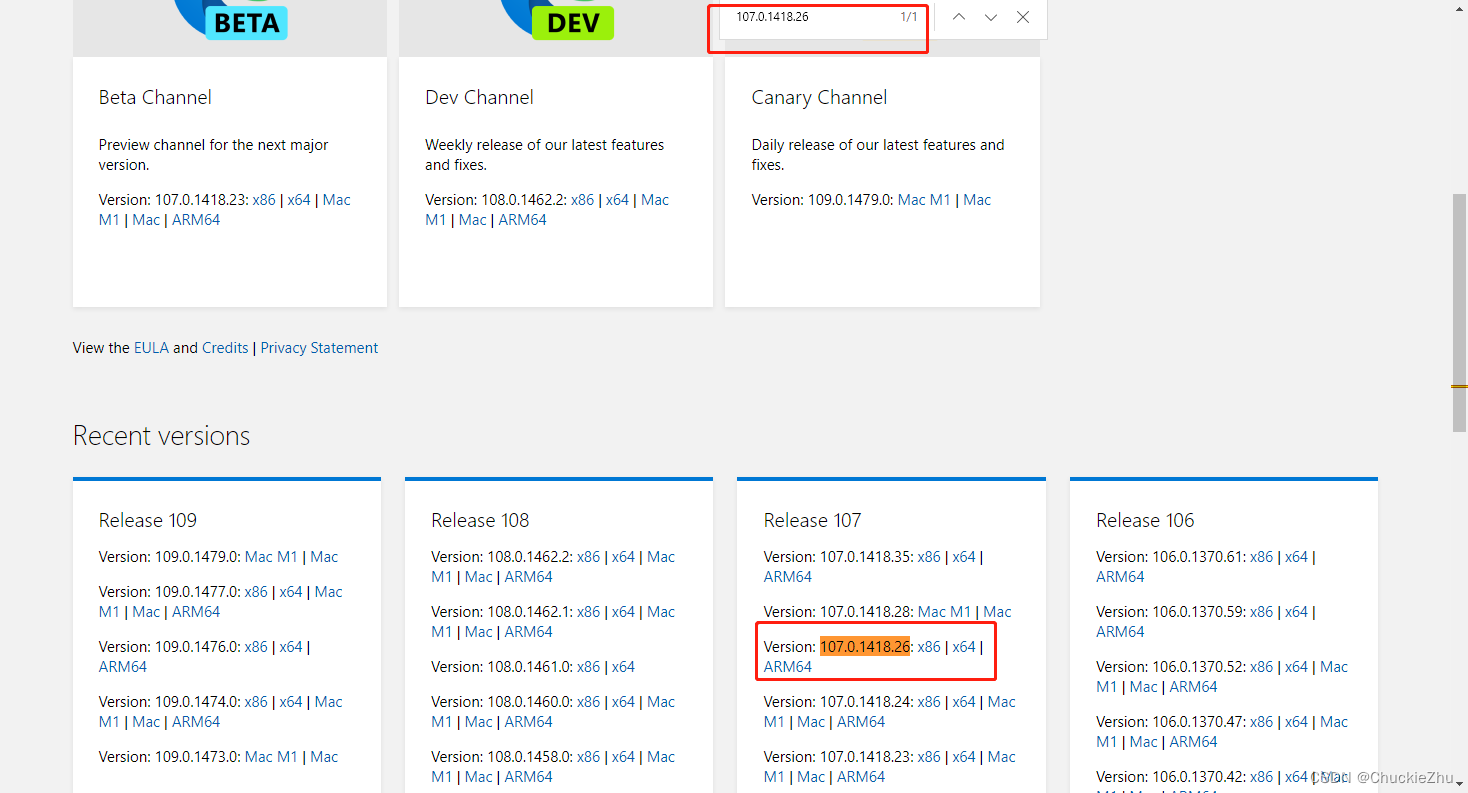
要选对版本,首先看一下自己Edge版本,然后在下载页面ctrl+f搜索这个版本号就行了
代码实现
这里肯定不能用我做的任务的代码,我就用我的路由器模拟登录和拨号给大家做个示例。
文件目录
那两个视频原本是做了准备发B站出视频教程的,但是B站说我打广告,把视频给我退回了,我也不知道哪里有广告,实在没办法,发不出去,大家将就看。
全部代码
这里先把所有代码贴上,然后后面逐行讲解。
# -*- coding: utf-8 -*-
# 文件已经做了脱敏处理
# 作者:ChuckieZhu
# 平台:CSDN
import time
from selenium import webdriver
from selenium.webdriver.support.select import Select
def main():
brower = webdriver.Edge(executable_path="./msedgedriver.exe")
brower.implicitly_wait(20)
brower.get("http://192.168.1.1/") # 自己的浏览器后台,根据路由器不同变化
input("回车开始") # 你们自己实现的时候可以不写
# 输入登陆密码
pwd_input = brower.find_element_by_xpath('//*[@id="lgPwd"]')
pwd_input.clear()
pwd_input.send_keys("这里是密码")
# 点击登录
# time.sleep(10)
brower.find_element_by_xpath('//*[@id="loginSub"]').click() # 点击登录
brower.find_element_by_xpath('//*[@id="routerSetMbtn"]').click() # 跳转到路由设置
brower.find_element_by_xpath('//*[@id="network_rsMenu"]').click() # i点击上网设置
brower.find_element_by_xpath('//*[@id="wanSel"]').click() # 展开上网方式
# 找到上网方式可选列表
uls = brower.find_element_by_xpath('//*[@id="selOptsUlwanSel"]') # 找到列表
lis = uls.find_elements_by_tag_name('li') # 找到了子元素
for li in lis:
print(li.text)
if "宽带" in li.text:
li.click()
break
time.sleep(2)
name = brower.find_element_by_xpath('//*[@id="name"]')
name.clear()
name.send_keys("这里是用户名")
pwd = brower.find_element_by_xpath('//*[@id="psw"]')
pwd.clear()
pwd.send_keys("这里是密码")
brower.find_element_by_xpath('//*[@id="save"]').click() # 点击连接
input("回车退出")
brower.quit()
if __name__ == "__main__":
main()
逐行讲解
我这里默认你们把代码原样复制到了自己的编译器里,用行号代指代码。
7-11行:导入需要的包
14行:打开浏览器的句柄,这个browser的单词写错了,大家不要在意。
15行:这里是使用隐式等待,等待元素加载出来之后才会执行下一步动作,可以防止出现“定位不到元素”的错误。这里不建议大家使用time.sleep(10)去等待,因为页面如果1秒加载完了,剩下9秒白等,如果11秒才能加载完,整个程序就崩溃了。
其实这里的隐式加载也不是太好的解决办法,因为有很多地方会加载很久,但是需要点击的内容已经加载出来可以点击了,可以使用下面的改法:
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC # 等待条件
# 多import两个东西
try:
username_input = WebDriverWait(driver=browser, timeout=20).until(
EC.presence_of_element_located(
(By.XPATH, '//*[@id="username"]')
)
) # 这个元素只要出现就取用
username_input.clear() # 清空内部
username_input.send_keys(username) # 输入名字
del username_input
except Exception as e:
print("[-]: ", str(e))
16行:打开一个网址
20-22行:使用xpath路径定位一个元素,操作如下:
使用F12打开开发者界面,点击这个按钮

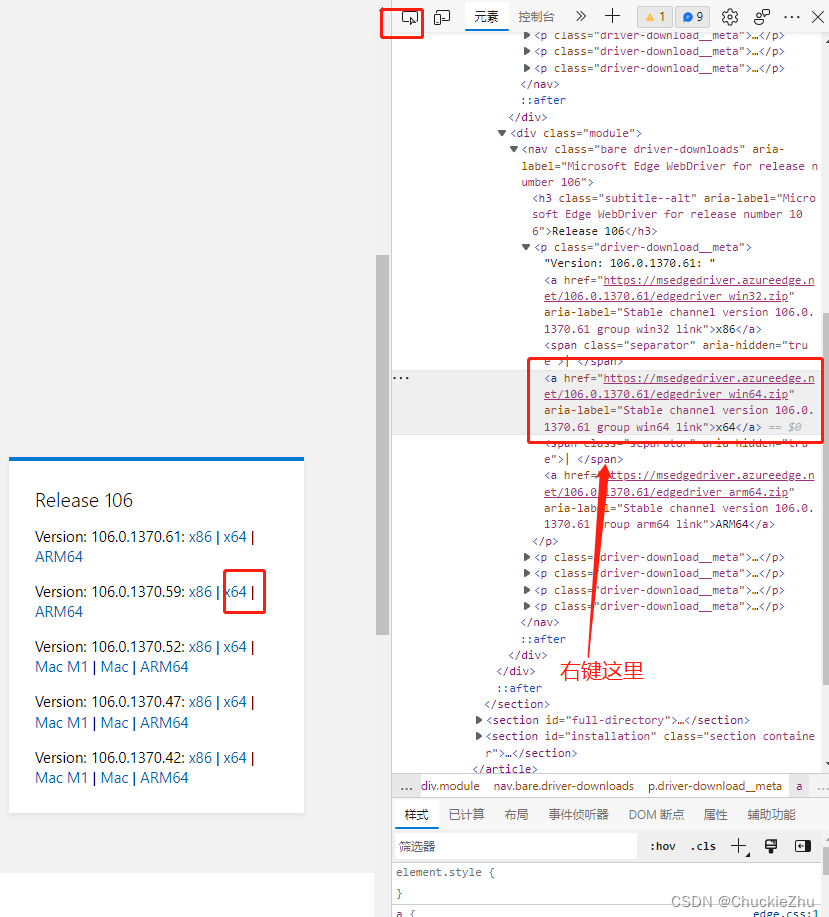
用那个箭头点击自己想用浏览器点击的元素,在右边会自动跳转到代码区,并高亮显示那一个代码区域,右键这个区域:
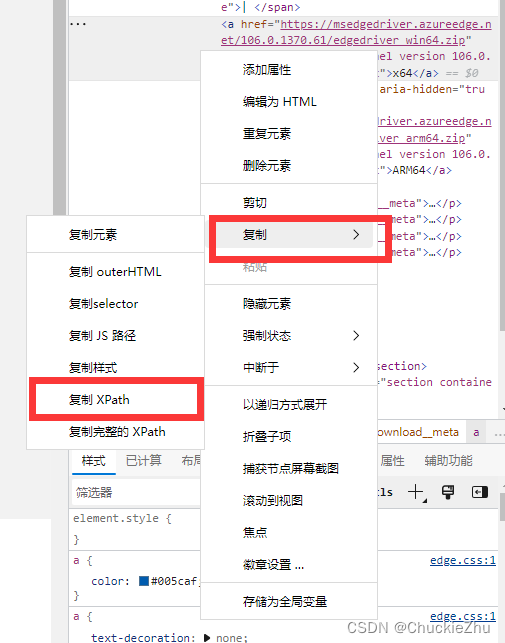
复制xpath路径。就是find_element_by_xpath里面的参数。
20-31: 一系列的寻找点击元素并点击。
34-40行:这里是一个下拉列表,
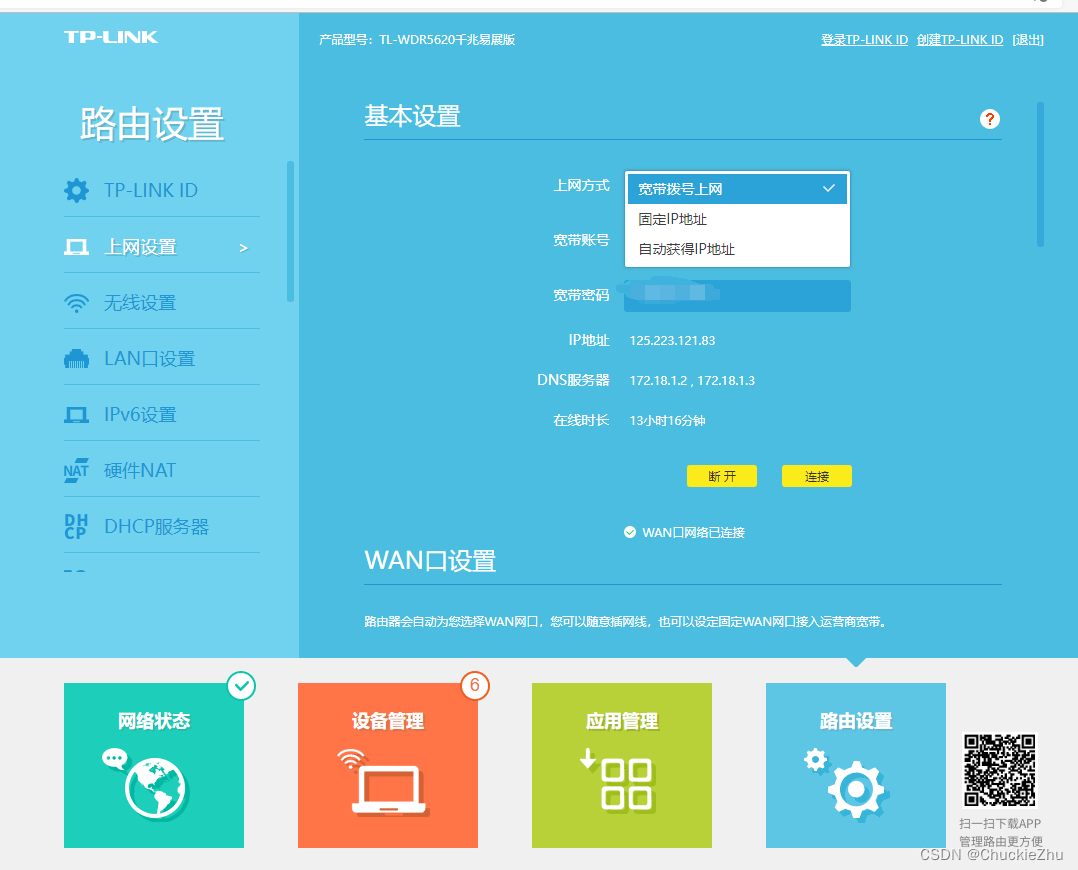
这个其实还是比较麻烦的,因为他不是直接用的selector,如果直接用的html的selector,那么使用下面代码:
from selenium.webdriver.support.select import Select
select = browser.find_element_by_xpath('//*[@id="wanSel"]')
Select(select).select_by_visible_text('宽带拨号上网')
print("选中宽带拨号上网") # 这个只对select适用
但是它使用的ul和li实现的,点击这个框之后,显示一个列表,然后点击列表选择内容,所以这个地方首先找到父元素,然后在父元素的基础上find_element_by_tag_name(),找到这个列表下的所有的li,然后判断里面的文字。
注意,这里的break是必须的,如果点击了宽带上网的方式,这个列表就没了,那么后面的元素相应的在html中也都消失了,这时候如果没有break,后面判断li.text的时候,就找不到这个东西了,会报stale element错误。
42行:页面刷新了,等待刷新,这个时候不能直接找,这个我怀疑使用try-except语句那种方式也可以,这里为了简单使用了sleep
44-50:输入宽带密码
52:点击连接按钮。
55:退出程序时quit掉浏览器。
后记
最近项目刚刚结束,不知道下一步咋办,升学之后课程也比较紧张,现在定的大方向是强化学习,后面小方向还正在阅读论文寻找感兴趣的内容。到时候找到了之后慢慢记录吧。
我也会不定时的做一些小工具,发上来。
注意事项
此代码不准用来做抢票等内容,这种行为肯定违反对应平台的规则,希望大家仅仅使用这个代码做路由器后台自动拨号、自动切换账号的脚本!
版权归原作者 ChuckieZhu 所有, 如有侵权,请联系我们删除。