
我知道你想裂,但你先别裂
目录
脑裂
用集群部署的大多数的分布式系统无可避免会面临脑裂问题。简单来说,脑裂就是在同一时刻出现了两个“Leader(或叫Master)”。设想这样一个场景:某分布式系统的分别部署在A,B两机房,每个机房有若干个节点。在正常情况下,这个分布式系统通过一致性协议(如 Paxos 或 Raft)来选举出一个 Leader,所有的读写请求都会通过 Leader 进行处理,副本们同Leader保持一致,确保数据的一致性。
假设一天出现了某种故障,A 机房和 B 机房之间的通信中断,且Leader丢失。这时,A 机房和 B 机房的节点可能会各自进行Leader选举,导致出现两个 Leader。这就是脑裂现象。
此时,如果多个不同区域的客户端向系统发送请求,根据就近路由的原则,用户可能向A机房的 leader 发送写请求,也可能向 B 机房的 leader 发送写请求,那么这两个请求可能会导致系统状态不一致。
Kafka脑裂实验
通过制造网络分区实现脑裂场景,观察kafka做了些什么
- 准备一个kafka实例,包含三个broker(brokerA,brokerB,brokerC);
- 在kafka中创建一个Topic,设置副本数为3,min.insync.replicas=1,随意生产几条消息,确认集群正常运行;

- 查看Isr,找到Leader hostip
./kafka-topics.sh --describe--zookeeper<zk ip>:<port>--topic<topic>
./zookeeper-shell.sh <zk ip>:<port> get /brokers/ids/<leader id>

4. 制造网络分区:将Leader副本与其他Follower副本之间的网络连接断开。自建kafka集群可以通过修改iptables实现(此操作会造成节点之间网络不通,请谨慎操作):
# 在Leader上执行以下命令(假设是A),阻止与B和C之间的通信
iptables -A INPUT -s<broker_B_IP>-j DROP
iptables -A OUTPUT -d<broker_B_IP>-j DROP
iptables -A INPUT -s<broker_C_IP>-j DROP
iptables -A OUTPUT -d<broker_C_IP>-j DROP
- 生产几条消息,查看Isr
./kafka-topics.sh --describe--zookeeper<zk ip>:<port>--topic<topic>
这里有两种可能:
- A节点被排除在ISR之外:leader发生变化。在这种情况下,ISR只包含B、C节点。
- B、C节点被排除在ISR之外:由于B、C节点无法与A节点进行通信,它们可能会落后于A节点,导致B、C节点被排除在ISR之外。在这种情况下,ISR只包含A节点。
- 恢复网络连接
iptables -D INPUT -s<broker_B_IP>-j DROP
iptables -D OUTPUT -d<broker_B_IP>-j DROP
iptables -D INPUT -s<broker_C_IP>-j DROP
iptables -D OUTPUT -d<broker_C_IP>-j DROP
- 在网络连接恢复后,Kafka集群将自动恢复正常状态。ISR列表又重新包含了A,B,C三个节点。
Kafka如何防止脑裂–Leader Epoch
鉴于kafka的副本选举机制,kafka也会面临脑裂问题。为了解决脑裂,kafka从0.11.0.0开始引入Leader Epoch的概念。
epoch是一个递增的整数。每当一个当新的leader被选举出来时,epoch都会+1。kafka的所有副本都会维护一个leader-epoch-checkpoint的文件,当eppch发生更新时,kafka会将矢量<LeaderEpoch => StartOffset> 追加到这个文件中,其中StartOffset表示当前的epoch下写入第一条消息的偏移量。副本在同步数据时,会将自己最新的epoch值一同发送给leader。leader收到follower的请求后,会检查请求中的epoch值。如果请求中的epoch值与当前leader的epoch值一致,说明follower与leader之间的同步关系符合预期,leader会接受follower的请求,将自己的数据复制给follower。如果请求中的epoch值小于当前leader的epoch值,说明follower已经过时,leader会拒绝follower的请求,并更新follower的epoch值。
# 查看leader-epoch-checkpoint# broker iptail-f /kafka-logs/<your—topic-partition>/leader-epoch-checkpoint
01
此外,在查看leader-epoch-checkpoint的时候可能会注意到replication-offset-checkpoint 文件。这个文件记录了follower副本已经成功同步的各个主题分区的Offset信息。当follower副本重新启动或发生故障恢复时,会根据这个文件从正确的位置继续同步数据。
leader-epoch-checkpoint和replication-offset-checkpoint文件在Kafka中分别负责管理leader副本和follower副本的状态信息。它们之间的关系在于它们共同参与了Kafka副本同步和故障恢复的过程,确保了Kafka集群在面临故障时能够正确地恢复状态,保证数据的一致性和可靠性。
epoch的局限性
Kafka利用epoch机制确保了在leader发生变更时,follower副本能够及时更新自己的状态,避免了脑裂问题。在leader切换的过程中,可能会出现数据不一致的情况,这种方法在某种程度上牺牲了一致性。
如何将不一致性带来的损失降到最低?
-用ISR
ISR列表
ISR(In-Sync Replicas)列表包含了分区的leader副本和已经成功同步了leader副本数据的follower副本。当选举发生时,新的leader会从ISR列表中选举出来,这样可以确保新的Leader拥有最新的数据,从而保证数据的一致性。
# 查看ISR列表
./kafka-topics.sh --describe--zookeeper<zookeeper_host>:<zookeeper_port>--topic<topic_name># ./kafka-topics.sh --describe --zookeeper localhost:15028 --topic topic0
Topic:topic0 PartitionCount:1 ReplicationFactor:3 Configs:retention.ms=43200000,cleanup.policy=delete,min.insync.replicas=1,max.message.bytes=1000012,retention.bytes=-1
Topic: topic0 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
# 其中,Isr字段表示ISR列表,包含了当前分区的Leader副本和已经成功同步了Leader副本数据的Follower副本。该分区的副本包括节点 2、1、0,目前处于同步复制(In-Sync Replica)状态的副本有节点 2、1、0。# 针对该主题的一些配置包括保留时间为 43200000 毫秒、清理策略为删除、最小副本数为 1,最大消息字节数为 1000012,保留字节数为 -1
当Leader接收到客户端的写入请求后,它会将数据写入本地日志,并将数据发送给所有的Follower副本。当follower副本成功写入数据后,它会向Leader发送ACK确认。当leader收到ISR列表中的所有follower副本的ack后,它会认为写入操作成功完成,并向客户端返回成功响应。
当某个副本无法及时同步leader的数据时,它会被从ISR列表中移除转为OSR(Out-of-Sync Replicas)。当该副本恢复正常并成功同步了Leader的数据后,再将它重新加入到ISR列表中。
ISR列表的伸缩机制
- 此部分内容多数引用《深入理解Kafka:核心设计与实践原理 2019》第八章,朱忠华老师的这本书确确实实🐮好顶赞
失效副本:因同步失效被ISR剔除出去的就是失效follower副本,包含失效副本的分区称为 “同步失效分区”,即 under-replicated 分区。
怎么判定一个分区是否有副本处于同步失效的状态呢?
Kafka从0.9.x版本开始就通过唯一的broker端参数replica.lag.time.max.ms来抉择,当ISR集合中的一个follower副本滞后leader副本的时间超过此参数指定的值时则判定为同步失败,需要将此follower副本剔除出ISR集合。replica.lag.time.max.ms参数的默认值为10000。一般有三种情况会导致副本失效:
- follower副本进程卡住,在一段时间内根本没有向leader副本发起同步请求,比如频繁的GC。
- follower副本进程同步过慢,在一段时间内都无法追赶上leader副本,比如I/O开销过大。
- 新上线或刚刚恢复的follower,在追赶上leader之前也处于失效状态
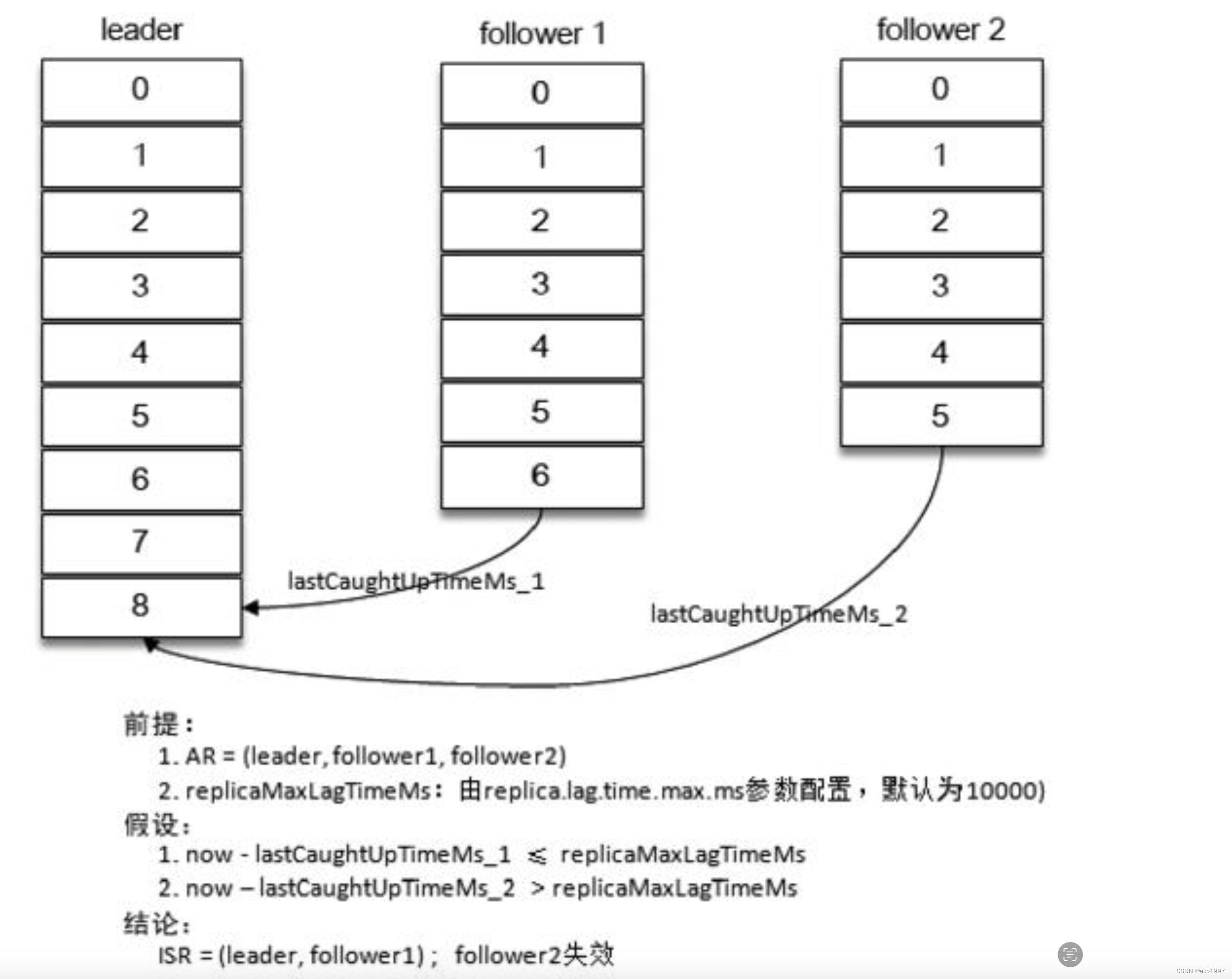
“当follower副本将leader副本LEO(LogEndOffset)之前的日志全部同步时,则认为该 follower 副本已经追赶上 leader 副本,此时更新该副本的lastCaughtUpTimeMs 标识。
Kafka 的副本管理器会启动一个副本过期检测的定时任务,而这个定时任务会定时检查当前时间与副本的 lastCaughtUpTimeMs 差值是否大于参数replica.lag.time.max.ms 指定的值。千万不要错误地认为 follower 副本只要拉取 leader副本的数据就会更新 lastCaughtUpTimeMs。试想一下,当 leader 副本中消息的流入速度大于follower 副本中拉取的速度时,就算 follower 副本一直不断地拉取 leader 副本的消息也不能与leader副本同步。如果还将此follower副本置于ISR集合中,那么当leader副本下线而选取此follower副本为新的leader副本时就会造成消息的严重丢失。 ”–by《深入理解Kafka:核心设计与实践原理 2019》
Isr伸缩
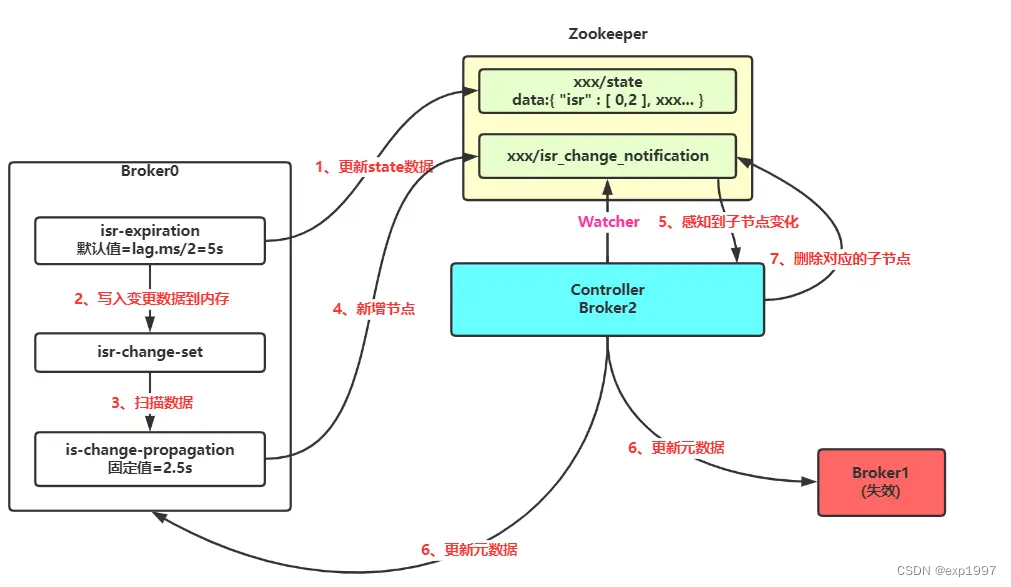
“Kafka 在启动的时候会开启两个与 ISR 相关的定时任务,名称分别为“isr-expiration”和“isr-change-propagation”。isr-expiration任务会周期性地检测每个分区是否需要缩减其ISR集合。当检测到ISR集合中有失效副本时,就会收缩ISR集合。如果某个分区的ISR集合发生变更,则会将变更后的数据记录到 ZooKeeper 对应的/brokers/topics/<topic>/partition/<parititon>/state节点中。” --by《深入理解Kafka:核心设计与实践原理 2019》
踢出 ISR 列表:
重回 ISR 列表: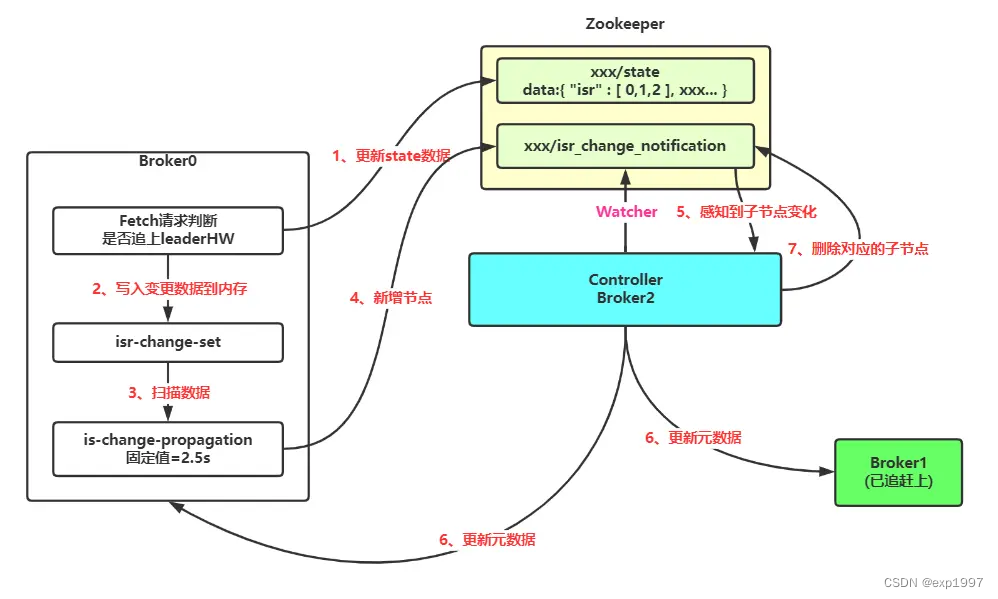
版权归原作者 exp1997 所有, 如有侵权,请联系我们删除。