
RDD
1、从已有的数据集合创建 RDD:
你可以使用
parallelize
方法从一个已有的 Scala 集合(如数组或列表)中创建 RDD。
val kmmrdd: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
2、从外部数据源读取数据创建 RDD:
你可以使用 Spark 提供的各种数据源来创建 RDD,比如文本文件、序列文件、JSON 文件、CSV 文件等。
val kmmrdd2 = sc.textFile("/data1/person.txt")

3、通过转换已有的 RDD 创建 RDD:
你可以通过对已有的 RDD 进行各种转换操作来创建新的 RDD。
val kmmrdd3 = kmmrdd.map(_ * 2)

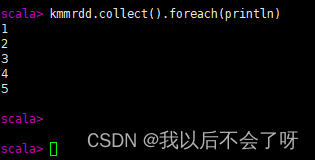
4. 显示RDD中的元素
kmmrdd.collect().foreach(println)
5. 对RDD中的每个元素应用函数:
val kmmRDD = kmmrdd.map(x => x * 2)

6. 对RDD中的元素进行过滤:
val kmmfilteredRDD = kmmrdd.filter(x => x % 2 == 0)

7. 对RDD中的元素进行聚合:
val kmmsum = kmmrdd.reduce((x, y) => x + y)

8. 对RDD中的元素进行排序:
val kmmsortedRDD = kmmrdd.sortBy(x => x, ascending = false)

9. 对两个RDD进行笛卡尔积操作:
val kmmcartesianRDD = kmmrdd.cartesian(kmmRDD)

10.对RDD中的每个分区应用函数:
val kmmPartitionsRDD = kmmrdd.mapPartitions(iter => iter.map(_ * 2))

DataFrame的常见操作方法

创建DataFrame
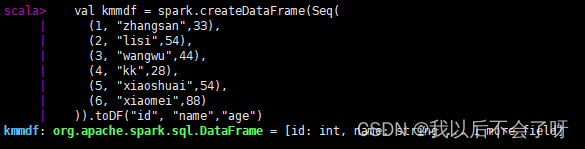
val kmmdf = spark.createDataFrame(Seq(
(1, "zhangsan",33),
(2, "lisi",54),
(3, "wangwu",44),
(4, "kk",28),
(5, "xiaoshuai",54),
(6, "xiaomei",88)
)).toDF("id", "name","age")
Dataframe提供了两种谮法风格,即DSL风格语法和SQL风格语法,二者在功能上并无区别,仅仅是根据用户习惯自定义选择操作方式。接下来,我们通过两种语法风格,分讲解Dstaframe操作的具体方法。
一.DSL风格操作
DataFrame提供了一个领域特定语言(DSL)以方便操作结构化数据,下面将针对DSL操作风格,讲解DataFrame
常用操作示例,
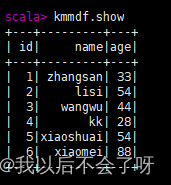
1.show():查看DataFrame中的具体内容信息
kmmdf.show
2.prittSchema0:查看0staFrame的Schema信息
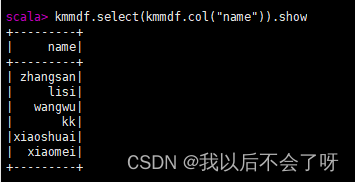
**3.select():**查看DataFmame中造取部分列的数据,
查看kmmdf对象的name字段数据
kmmdf.select(kmmdf.col("name")).show
1.select查看DataFrame中选取部分列的数据及进行重命名
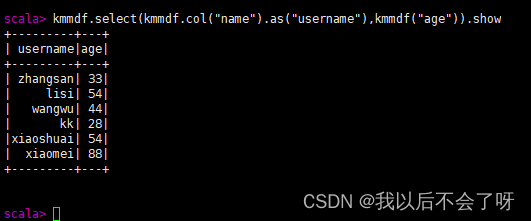
kmmdf.select(kmmdf.col("name").as("username"),kmmdf("age")).show
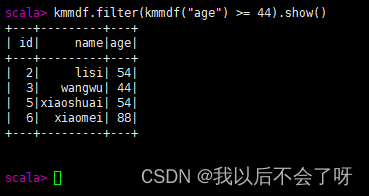
2.filter() 实现条件查询,过滤出想要的结果查询age为44的数据
kmmdf.filter(kmmdf("age") >= 44).show()
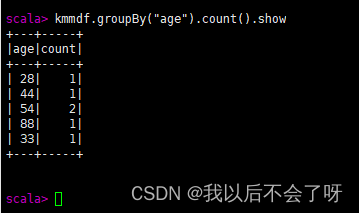
3.groupBy() 对记录进行分组
kmmdf.groupBy("age").count().show
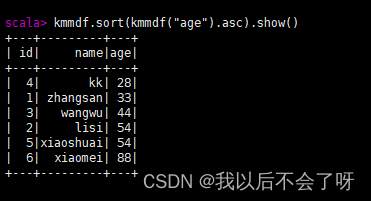
4.sort()对特定字段进行排序操作(默认升序)
(升序)kmmdf.sort(kmmdf("age").asc).show()
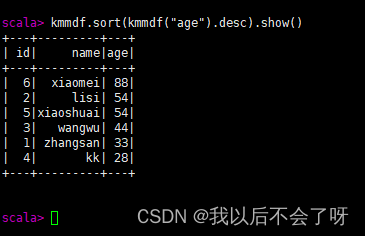
(降序)kmmdf.sort(kmmdf("age").desc).show()
SQL风格操作DataFrame
*1.将DataFrame*注册成一个临时表
kmmdf.registerTempTable("k_kmm")

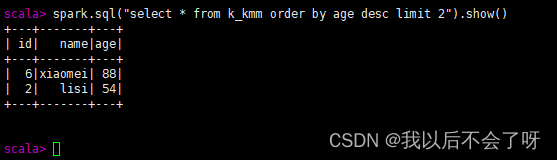
**2.**查询年龄最大的前两名人的信息
spark.sql("select * from k_kmm order by age desc limit 2").show()
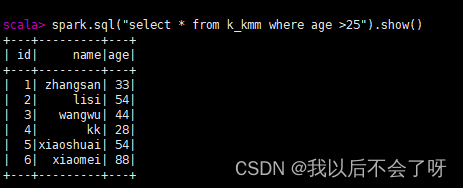
*3.查询年龄大于25*的人的信息
spark.sql("select * from k_kmm where age >25").show()
RDD、DataFrame及Dataset****的区别
•RDD数据的表现形式,即序号(1),此时RDD数据没有数据类型和元数据信息。
•DataFrame数据的表现形式,即序号(2),此时DataFrame数据中添加Schema元数据信息(列名和数据类型,如ID:String),DataFrame每行类型固定为Row类型,每列的值无法直接访问,只有通过解析才能获取各个字段的值。

Dataset数据的表现形式,序号(3)和(4),其中序号(3)是在RDD每行数据的基础之上,添加一个数据类型(value:String)作为Schema元数据信息。而序号(4)每行数据添加People强数据类型,在Dataset[Person]中里存放了3个字段和属性,Dataset每行数据类型可自定义,一旦定义后,就具有错误检查机制。

版权归原作者 我以后不会了呀 所有, 如有侵权,请联系我们删除。