
1. MySQL DISTINCT子句简介
从表中查询数据时,可能会收到重复的行记录。为了删除这些重复行,可以在
SELECT
语句中使用
DISTINCT
子句。
DISTINCT
子句的语法如下:
SELECT DISTINCT
columns
FROM
table_name
WHERE
where_conditions;
2. MySQL DISTINCT示例
下面来看看一个使用
DISTINCT
子句从
employees
表中选择员工的唯一姓氏(
lastName
)的简单示例。
首先,使用
SELECT
语句从
employees
表中查询员工的姓氏(
lastName
),如下所示:
SELECT
lastname
FROM
employees
ORDER BY lastname;
执行上面查询语句,得到以下结果 -
mysql> SELECT lastname FROM employees ORDER BY lastname;
+-----------+
| lastname |
+-----------+
| Bondur |
| Bondur |
| Bott |
| Bow |
| Castillo |
| Firrelli |
| Firrelli |
| Fixter |
| Gerard |
| Hernandez |
| Jennings |
| Jones |
| Kato |
| King |
| Marsh |
| Murphy |
| Nishi |
| Patterson |
| Patterson |
| Patterson |
| Thompson |
| Tseng |
| Vanauf |
+-----------+
23 rows in set
可看到上面结果中,有好些结果是重复的,比如:
Bondur
,
Firrelli
等,那如何做到相同的结果只显示一个呢?要删除重复的姓氏,请将
DISTINCT
子句添加到
SELECT
语句中,如下所示:
SELECT DISTINCT
lastname
FROM
employees
ORDER BY lastname;
执行上面查询,得到以下输出结果 -
mysql> SELECT DISTINCT lastname FROM employees ORDER BY lastname;
+-----------+
| lastname |
+-----------+
| Bondur |
| Bott |
| Bow |
| Castillo |
| Firrelli |
| Fixter |
| Gerard |
| Hernandez |
| Jennings |
| Jones |
| Kato |
| King |
| Marsh |
| Murphy |
| Nishi |
| Patterson |
| Thompson |
| Tseng |
| Vanauf |
+-----------+
19 rows in set
当使用
DISTINCT
子句时,重复的姓氏(
lastname
)在结果集中被消除。
3. MySQL DISTINCT和NULL值
如果列具有
NULL
值,并且对该列使用
DISTINCT
子句,MySQL将保留一个
NULL
值,并删除其它的
NULL
值,因为
DISTINCT
子句将所有
NULL
值视为相同的值。
例如,在
customers
表中,有很多行的州(
state
)列是
NULL
值。 当使用
DISTINCT
子句来查询客户所在的州时,我们将看到唯一的州和
NULL
值,如下查询所示:
SELECT DISTINCT
state
FROM
customers;
执行上面查询语句后,输出结果如下 -
mysql> SELECT DISTINCT state FROM customers;
+---------------+
| state |
+---------------+
| NULL |
| NV |
| Victoria |
| CA |
| NY |
| PA |
| CT |
| MA |
| Osaka |
| BC |
| Qubec |
| Isle of Wight |
| NSW |
| NJ |
| Queensland |
| Co. Cork |
| Pretoria |
| NH |
| Tokyo |
+---------------+
19 rows in set
4. MySQL DISTINCT在多列上的使用
可以使用具有多个列的
DISTINCT
子句。 在这种情况下,MySQL使用所有列的组合来确定结果集中行的唯一性。
例如,要从
customers
表中获取城市(
city
)和州(
state
)的唯一组合,可以使用以下查询:
SELECT DISTINCT
state, city
FROM
customers
WHERE
state IS NOT NULL
ORDER BY state , city;
SQL
执行上面查询,得到以下结果 -
mysql> SELECT DISTINCT state, city FROM customers WHERE state IS NOT NULL ORDER BY state ,city;
+---------------+----------------+
| state | city |
+---------------+----------------+
| BC | Tsawassen |
| BC | Vancouver |
| CA | Brisbane |
| CA | Burbank |
| CA | Burlingame |
| CA | Glendale |
| CA | Los Angeles |
| CA | Pasadena |
| CA | San Diego |
| CA | San Francisco |
| CA | San Jose |
| CA | San Rafael |
| Co. Cork | Cork |
| CT | Bridgewater |
| CT | Glendale |
| CT | New Haven |
| Isle of Wight | Cowes |
| MA | Boston |
| MA | Brickhaven |
| MA | Cambridge |
| MA | New Bedford |
| NH | Nashua |
| NJ | Newark |
| NSW | Chatswood |
| NSW | North Sydney |
| NV | Las Vegas |
| NY | NYC |
| NY | White Plains |
| Osaka | Kita-ku |
| PA | Allentown |
| PA | Philadelphia |
| Pretoria | Hatfield |
| Qubec | Montral |
| Queensland | South Brisbane |
| Tokyo | Minato-ku |
| Victoria | Glen Waverly |
| Victoria | Melbourne |
+---------------+----------------+
37 rows in set
Shell
没有
DISTINCT
子句,将查询获得州(
state
)和城市(
city
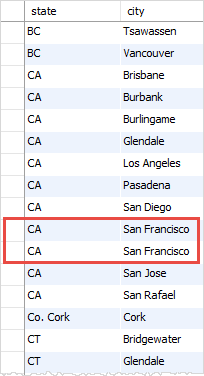
)的重复组合如下:
SELECT
state, city
FROM
customers
WHERE
state IS NOT NULL
ORDER BY state , city;
SQL
执行上面查询,得到以下结果 -
5. DISTINCT子句与GROUP BY子句比较
如果在
SELECT
语句中使用
GROUP BY
子句,而不使用聚合函数,则
GROUP BY
子句的行为与
DISTINCT
子句类似。
以下语句使用
GROUP BY
子句来选择
customers
表中客户的唯一
state
列的值。
SELECT
state
FROM
customers
GROUP BY state;
SQL
执行上面查询,得到以下结果 -
mysql> SELECT state FROM customers GROUP BY state;
+---------------+
| state |
+---------------+
| NULL |
| BC |
| CA |
| Co. Cork |
| CT |
| Isle of Wight |
| MA |
| NH |
| NJ |
| NSW |
| NV |
| NY |
| Osaka |
| PA |
| Pretoria |
| Qubec |
| Queensland |
| Tokyo |
| Victoria |
+---------------+
19 rows in set
Shell
可以通过使用
DISTINCT
子句来实现类似的结果:
mysql> SELECT DISTINCT state FROM customers;
+---------------+
| state |
+---------------+
| NULL |
| NV |
| Victoria |
| CA |
| NY |
| PA |
| CT |
| MA |
| Osaka |
| BC |
| Qubec |
| Isle of Wight |
| NSW |
| NJ |
| Queensland |
| Co. Cork |
| Pretoria |
| NH |
| Tokyo |
+---------------+
19 rows in set
SQL
一般而言,
DISTINCT
子句是
GROUP BY
子句的特殊情况。
DISTINCT
子句和
GROUP BY
子句之间的区别是
GROUP BY
子句可对结果集进行排序,而
DISTINCT
子句不进行排序。
如果将ORDER BY子句添加到使用
DISTINCT
子句的语句中,则结果集将被排序,并且与使用
GROUP BY
子句的语句返回的结果集相同。
SELECT DISTINCT
state
FROM
customers
ORDER BY state;
执行上面查询,得到以下结果 -
mysql> SELECT DISTINCT state FROM customers ORDER BY state;
+---------------+
| state |
+---------------+
| NULL |
| BC |
| CA |
| Co. Cork |
| CT |
| Isle of Wight |
| MA |
| NH |
| NJ |
| NSW |
| NV |
| NY |
| Osaka |
| PA |
| Pretoria |
| Qubec |
| Queensland |
| Tokyo |
| Victoria |
+---------------+
19 rows in set
6. MySQL DISTINCT和聚合函数
可以使用具有聚合函数(例如SUM,AVG和COUNT)的
DISTINCT
子句中,在MySQL将聚合函数应用于结果集之前删除重复的行。
例如,要计算美国客户的唯一
state
列的值,可以使用以下查询:
SELECT
COUNT(DISTINCT state)
FROM
customers
WHERE
country = 'USA';
执行上面查询,得到以下结果 -
mysql> SELECT COUNT(DISTINCT state) FROM customers WHERE country = 'USA';
+-----------------------+
| COUNT(DISTINCT state) |
+-----------------------+
| 8 |
+-----------------------+
1 row in set
7. MySQL DISTINCT与LIMIT子句
如果要将
DISTINCT
子句与LIMIT子句一起使用,MySQL会在查找
LIMIT
子句中指定的唯一行数时立即停止搜索。
以下查询
customers
表中的前
3
个非空(NOT NULL)唯一
state
列的值。
mysql> SELECT DISTINCT state FROM customers WHERE state IS NOT NULL LIMIT 3;
+----------+
| state |
+----------+
| NV |
| Victoria |
| CA |
+----------+
3 rows in set
在本教程中,我们学习了使用MySQL
DISTINCT
子句的各种方法,例如消除重复行和计数非
NULL
值。
版权归原作者 龙卷风夜闯牛棚 所有, 如有侵权,请联系我们删除。