
大数据入门(黑马的Hadoop)环境配置
准备虚拟机上的Linux操作系统环境
一.VMware准备Linux虚拟机
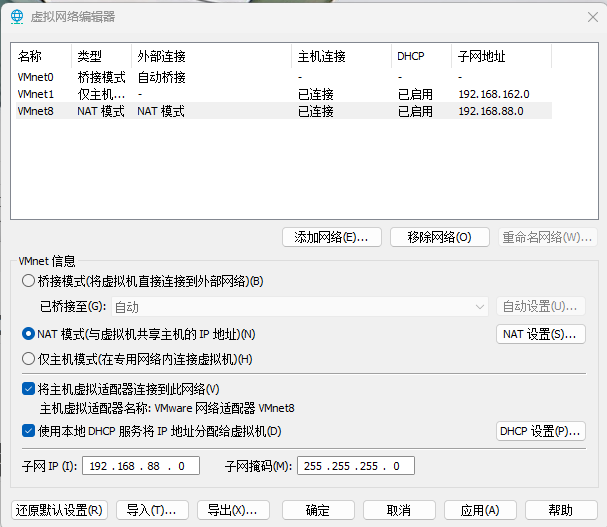
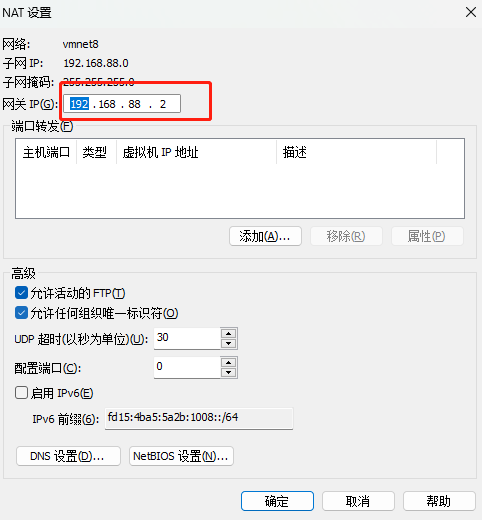
1.设置VMware网段
在VMware的虚拟网络编辑器中,将VMnet8虚拟网卡的:(没有强制要求,数字随便设置,满足地址要求即可)
- 网段设置为:192.168.88.0
- 网关设置为:192.168.88.2
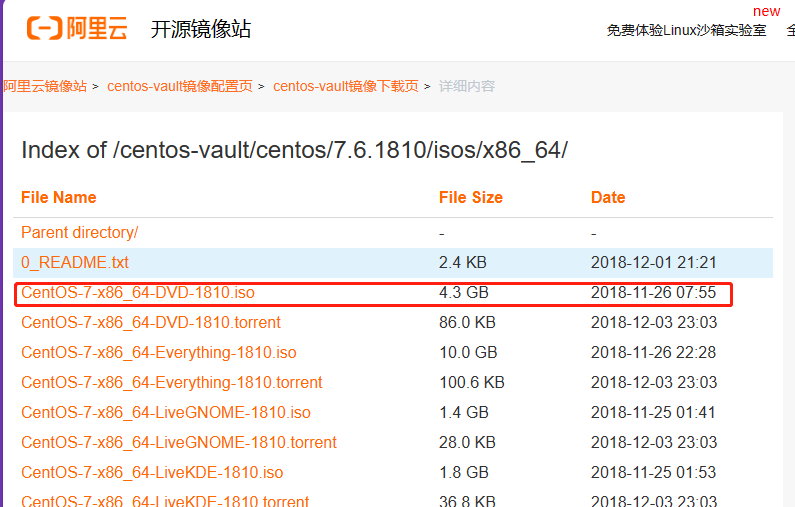
2.下载CentOS操作系统
centos-vault-centos-7.6.1810-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
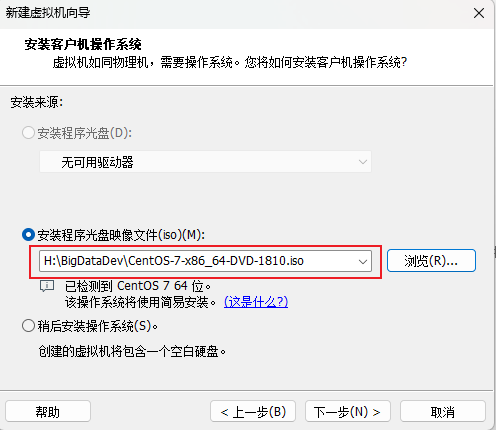
3.在VMware中安装CentOS操作系统
3.1打开VMware,新建虚拟机
3.2配置虚拟机
- 设置账户
- 无脑下一步,等待安装centos系统
- 创建成功
4.配置多台Linux虚拟机
- 在VMware中,创建一个文件夹,起名为大数据集群
- 克隆,取名node1
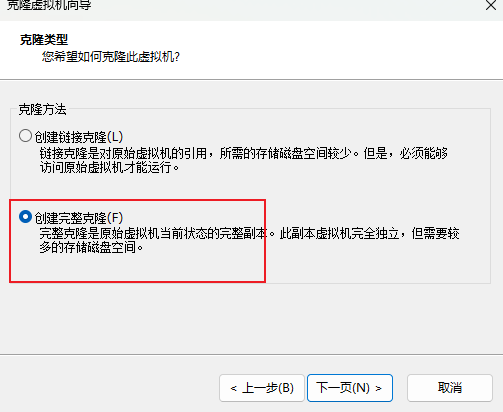
- 同样的操作克隆出:node2和node3
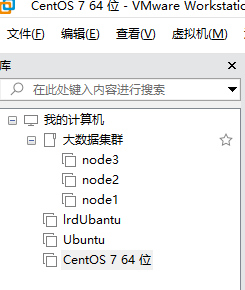
- 对虚拟机的内存进行配置:1. node1配置为4G内存2. node2、node3配置为2G内
二.VMware虚拟机系统设置
1.对三台虚拟机完成主机名、固定IP、SSH免密登陆等系统设置
1.1配置固定IP地址
//提升权限
su -
//修改主机名
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
//修改IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
//修改
BOOTPROTO="dhcp"为
BOOTPROTO="static"
//在文件中添加内容(node1为101,node2为102,node3为103)
IPADDR="192.168.88.101"
NETMASK="255.255.255.0"
GATEWAY="192.168.88.2"
DNS1="192.168.88.2"
//重启网卡
systemctl stop network
systemctl start network
//或者直接使用
systemctl restart network
1.2配置主机名映射
1.2.1在Windows系统中修改hosts文件,填入如下内容:
路径:C:\Windows\System32\drivers\etc
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
1.2.2在3台Linux的/etc/hosts文件中,填入如下内容(3台都要添加)
- 可以考虑使用finalshell工具远程连接
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3
1.3配置SSH免密登录
后续安装的集群化软件,多数需要远程登录以及远程执行命令,我们可以简单起见,配置三台Linux服务器之间的免密 码互相SSH登陆
1.3.1在每一台机器都执行:一路回车到底即可
ssh-keygen -t rsa -b 4096
//可以进入ssh文件查看
cd .ssh/
ll
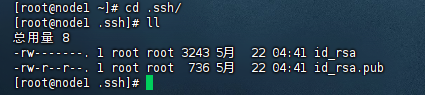
1.3.2在每一台机器都执行:(选择yes,输入密码即可)
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
ssh node3
node1登录node3成功
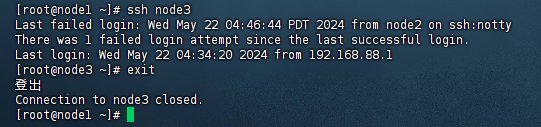
1.3.3 执行完毕后,node1、node2、node3之间将完成root用户之间的免密互通
1.4创建hadoop用户并配置免密登录
后续大数据的软件,将不会以root用户启动(确保安全,养成良好的习惯) 我们为大数据的软件创建一个单独的用户hadoop,并为三台服务器同样配置hadoop用户的免密互通
1.4.1. 在每一台机器执行:useradd hadoop,创建hadoop用户
1.4.2. 在每一台机器执行:passwd hadoop,设置hadoop用户密码为123456 (提示无效,再次设置即可,应为我们是root用户)
1.4.3. 在每一台机器均切换到hadoop用户:su - hadoop,并执行 ssh-keygen -t rsa -b 4096,创建ssh密钥
1.4.4. 在每一台机器均执行
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
2.对三台虚拟机完成JDK环境的部署
JDK:Java Development Kit,是用于Java语言开发的环境。
大数据的很多软件的运行都需要有Java运行环境的支持 所以我们在三台服务器上,预先都部署好JDK环境。
使用JDK1.8版本
2.1配置JDK环境
2.1.1下载jdk
java[Java Downloads | Oracle]
下载jdk-8u361-linux-x64.tar.gz
2.1.2创建文件夹,用来部署JDK,将JDK和Tomcat都安装部署到:/export/server 内
mkdir -p /export/server
//用命令rz上传文件
2.1.3 解压缩JDK安装文件
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/server/
2.1.4配置JDK的软链接
ln -s /export/server/jdk1.8.0_361/ jdk
2.1.5配置JAVA_HOME环境变量,以及将$JAVA_HOME/bin文件夹加入PATH环境变量中
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
2.1.6生效环境变量
source /etc/profile
2.1.7 配置java执行程序的软链接
//删除操作系统自带的java
rm -f /usr/bin/java
//软连接自己安装的java程序
ln -s /export/server/jdk/bin/java /usr/bin/java
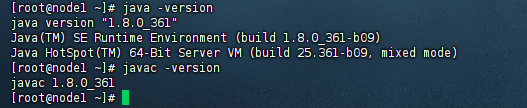
2.1.8 执行验证
java -version
javac -version
2.1.9快速配置node2和node3
//进入server文件夹中,使用scp命令将jdk复制到node2,node3中(注意包裹pwd的是键盘左上角的符号)
scp -r jdk1.8.0_361 node2:`pwd`/
scp -r jdk1.8.0_361 node3:`pwd`/
ln -s /export/server/jdk1.8.0_361/ jdk
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
rm -f /usr/bin/java
ln -s /export/server/jdk/bin/java /usr/bin/java
java -version
javac -version
3.对三台虚拟机完成防火墙、SElinux、时间同步等系统设置
3.1关闭防火墙和SELinux
集群化软件之间需要通过端口互相通讯,为了避免出现网络不通的问题,我们可以简单的在集群内部关闭防火墙。
//每一台机器都执行
systemctl stop firewalld
systemctl disable firewalld
Linux有一个安全模块:SELinux,用以限制用户和程序的相关权限,来确保系统的安全稳定。
在当前,我们只需要关闭SELinux功能,避免导致后面的软件运行出现问题即可
//每一台机器都执行
vim /etc/sysconfig/selinux
//将第七行,SELINUX=enforcing 改为
SELLINUX=disabled
//保存退出重启虚拟机
init 6
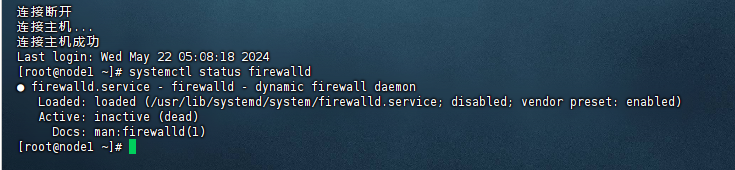
//重启后查看防火墙状态
systemctl status firewalld
3.2修改时区并配置自动时间同步
以下操作在三台Linux均执行
- 安装ntp软件
yum install -y ntp - 更新时区
rm -f /etc/localtime;sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime - 同步时间
ntpdate -u ntp.aliyun.com - 开启ntp服务并设置开机自启
systemctl start ntpd systemctl enable ntpd
三.设置快照
目前Linux虚拟机的状态基本准备就绪,可以对当前状态进行快照保存,以备后续恢复。 对三台虚拟机均执行拍摄快照。
版权归原作者 雨天的恶意 所有, 如有侵权,请联系我们删除。