
前言
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。这里先介绍本地运行模式
运行官方Grep案例
提供一些文本文件, grep可以从中找到想要匹配的文本
1. 在当前用户主(HOME)目录下面创建一个input目录
[ytsky@hadoop101 ~]$ mkdir input
2.将Hadoop的xml配置文件复制到input
[ytsky@hadoop101 ~]$ cp $HADOOP_HOME/etc/hadoop/*.xml input

3. 执行share目录下的MapReduce程序
[ytsky@hadoop101 ~]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
运行命令解释:
hadoop:hadoop启动命令
jar:以jar包运行方式运行
share/hadoop/mapreduce-examles-2.7.2.jar :这是hadoop官网提供的案例目录
grep:启动grep案例
input:输入目录
output:输出目录
需要注意:输出目录默认是由程序创建的,如果存在output输出目录,则程序会报错
你需要删除已存在的输出目录(rm -rf output)
'dfs[a-z.]+':正则表达式 表示已dfs开头所有匹配项,可无限累加

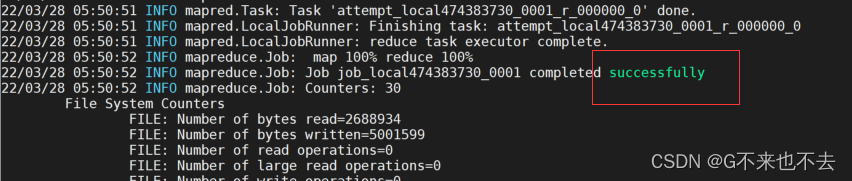
4. 查看输出结果
运行后,会在主目录中生成一个output目录,该目录存放运行结果
 part-r-0000: 表示运行结果 ,其中r表示reduce运行结果,0000表示结果编号
part-r-0000: 表示运行结果 ,其中r表示reduce运行结果,0000表示结果编号
[ytsky@hadoop101 output]$ cat part-r-00000

只有一个运行结果。
运行官方WordCount 案例
这例子是对文件中某些单词进行统计数。
1.创建在hadoop-2.7.2文件下面创建一个wcinput目录
[ytsky@hadoop101 ~]$ mkdir wcinput
2.在wcinput文件下创建一个wc.input文件
[ytsky@hadoop101 ~]$ cd wcinput
[ytsky@hadoop101 wcinput]$ touch wc.input
3编辑wc.input文件
[ytsky@hadoop101 wcinput]$ vi wc.input
在文件中输入如下内容
hadoop yarn ytsky
mapreduce yarn
ytsky hadoop
hadoop
保存退出(:wq)
4.执行程序
[ytsky@hadoop101 ~]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
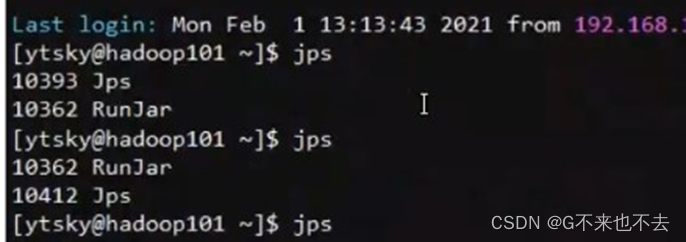
注意: 本地模式下运行程序分析,会显示一个运行进程(RunJar),当运行完成后该进程就会消失
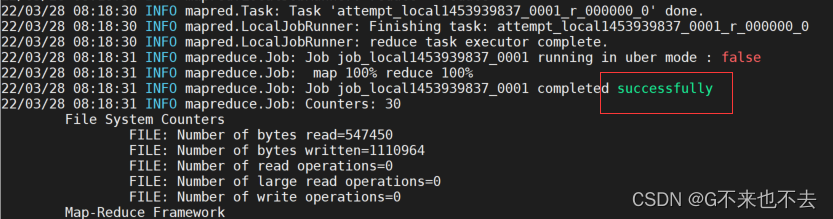
5**. 查看结果**
[ytsky@hadoop101 ~]$ cat wcoutput/part-r-00000

版权归原作者 G不来也不去 所有, 如有侵权,请联系我们删除。