
今天我们来详细学习一些 selenium 的强大用法
一、selenium简介
由于requests模块是一个不完全模拟浏览器行为的模块,只能爬取到网页的HTML文档信息,无法解析和执行CSS、JavaScript代码,因此需要我们做人为判断;
1、什么是selenium
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法执行javaScript代码的问题。
selenium模块本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器;由于selenium解析执行了CSS、JavaScript所以相对requests它的性能是低下的;
2、selenium的用途
1)selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用浏览器自动访问目标站点并操作,那我们也可以拿它来做爬虫。
2)selenium本质上是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等…进而拿到网页渲染之后的结果,可支持多种浏览器
二、selenium的安装与测试
1、下载selenium模块:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
或者在pycharm中下载
2、安装浏览器驱动
- Google浏览器驱动(在下载驱动之前,查看一下chrome浏览器的版本号,如下:

国内镜像网站地址:http://npm.taobao.org/mirrors/chromedrive

当然也可以去官网找最新的版本,官网: https://sites.google.com/a/chromium.org/chromedriver/downloads
另外注意:把下载好的chromedriver.exe放到python安装路径的scripts目录中即可
- firefox浏览器驱动
selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver
下载链接:https://github.com/mozilla/geckodriver/releases
- 测试是否安装成功
import time
from selenium import webdriver
browser=webdriver.Chrome()
#实例化1个谷歌浏览器对象
browser.get('https://www.baidu.com/')
time.sleep(5)
browser.close()

三、selenium的使用
所谓模拟浏览器基本就是下面的流程:
1.请求
2.显示页面
3.查找元素
4.点击可点击元素
所以如何使用selenium找到页面中的标签,进而触发标签事件,就会变的尤为重要
1. selenium选择器
要想定位页面的元素,selenium也提供了一系列的方法。
- 通过标签id属性进行定位
browser.find_element_by_id('kw') # 其中kw便是页面中某个元素的id值
- 通过标签name属性进行定位
# 两种方式是一样的
browser.find_element_by_name("wd") # 其中wd是页面中某个元素的name值
- 通过标签名进行定位
browser.find_element_by_tag_name("img") # img参数表示的就是图片标签img
- 通过CSS查找方式进行定位
browser.find_elements_by_css_selector("#kw") # 根据选择器进行定位查找,其中#kw表示的是id选择器名称是kw的
- 通过xpath方式定位
browser.find_element_by_xpath('//*[@id="kw"]') # 参数即是xpath的语法
- 通过搜索页面中链接进行定位
有时候不是一个输入框也不是一个按钮,而是一个文字链接,我们可以通过link
browser.find_element_by_link_text("设置")
通过搜索页面中链接进行定位 ,可以支持模糊匹配**
browser.find_element_by_partial_link_text("百度") # 查找页面所有的含有百度的文字链接
2. selenium显示等待和隐式等待
显示等待:就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception
操作格式:WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
WebDriverWait()一般由until()或 until_not()方法配合使用 until(method, message=’ ‘):调用该方法提供的驱动程序作为一个参数,直到返回值为True until_not(method, message=’ '):调用该方法提供的驱动程序作为一个参数,直到返回值为False
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.chrome()
driver.get('http://www.baidu.com')
element = WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located((By.ID, "kw")))
element.send_keys('selenium')
隐式等待:就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素位置。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
driver.implicitly_wait() 默认设置为0
例如:driver.implicitly_wait(10) 。如果元素在10s内定位到了,继续执行。如果定位不到,将以循环方式判断元素是否被定位到。如果在10s内没有定位到,则抛出异常
from selenium import webdriver
driver = webdriver.chrome()
driver.get('http://www.baidu.com')
# 隐式等待10秒
driver.implicitly_wait(10)
另外还有一种就是我们常用的sleep,我们称为:强制等待。有时候我们希望脚本在执行到某一位置时暂停一段时间等待页面加载,这时可以使用sleep()方法。sleep()方法会固定休眠一定的时长,然后再继续执行。sleep()方法默认参数以秒为单位。
from time import sleep
from selenium import webdriver
driver = webdriver.chrome()
driver.get('http://www.baidu.com')
# 强制休眠2秒
sleep(2)
driver.find_element_by_id("kw").send_keys("selenium")
3. 元素交互操作
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽(滑动验证)等等。而selenium给我们提供了一个类来处理这类事件——ActionChains;
selenium.webdriver.common.action_chains.ActionChains(driver)
这个类基本能够满足我们所有对鼠标操作的需求。
- actionChains的基本使用
首先需要了解ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行。
这种情况下我们可以有两种调用方法:
链式写法
menu = driver.find_element_by_css_selector(".div1")
hidden_submenu = driver.find_element_by_css_selector(".div1 #menu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
分步写法
menu = driver.find_element_by_css_selector(".div1")
hidden_submenu = driver.find_element_by_css_selector(".div1 #menu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
两种写法本质是一样的,ActionChains都会按照顺序执行所有的操作。
- actionChains方法列表
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
示例代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
try:
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 1、往jd发送请求
driver.get('https://www.jd.com/')
# 找到输入框输入围城
input_tag = driver.find_element_by_id('key')
input_tag.send_keys('华为')
# 键盘回车
input_tag.send_keys(Keys.ENTER)
time.sleep(2)
# 找到输入框输入墨菲定
input_tag = driver.find_element_by_id('key')
input_tag.clear()
input_tag.send_keys('樊登读书')
# 找到搜索按钮点击搜索
button = driver.find_element_by_class_name('button')
button.click()
time.sleep(10)
finally:
driver.close()
或者前进后退相关
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.cnblogs.com/xuanyuan/')
browser.find_element_by_partial_link_text('我是如何把计算机网络考了100分的?').click()
time.sleep(3)
browser.back() # 后退
time.sleep(3)
browser.forward() # 前进
time.sleep(5)
browser.close()
四、综合案例
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC # available since 2.26.0
from selenium.webdriver.support.ui import WebDriverWait # available since 2.4.0
from selenium.webdriver.support import expected_conditions
import pandas as pd
class MyCrawler(object):
def __init__(self):
self.path = "./data"
if not os.path.exists(self.path):
os.mkdir(self.path)
self.driver = webdriver.Chrome()
self.base_url = "http://data.house.163.com/bj/housing/trend/district/todayprice/{date:s}/{interval:s}/allDistrict/1.html?districtname={disname:s}#stoppoint"
self.data = None
def craw_page(self, date="2020.01.01-2020.12.30", interval="month", disname="全市"):
driver = self.driver
url = self.base_url.format(date=date, interval=interval, disname=disname)
driver.get(url)
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "resultdiv_1")))
self.data = pd.DataFrame()
ct = True
while ct:
self.get_items_in_page(driver)
e_pages = driver.find_elements_by_xpath(
'//div[@class="pager_box"]/a[@class="pager_b current"]/following::a[@class="pager_b "]')
if len(e_pages) > 0:
next_page_num = e_pages[0].text
e_pages[0].click()
# 通过判断当前页是否为我们点击页面的方式来等待页面加载完成
WebDriverWait(driver, 10).until(
expected_conditions.text_to_be_present_in_element(
(By.XPATH, '//a[@class="pager_b current"]'),
next_page_num
)
)
else:
ct = False
brea
return self.data
finally:
driver.quit()
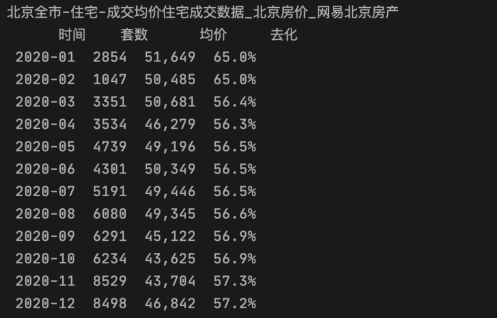
def get_items_in_page(self, driver):
e_tr = driver.find_elements_by_xpath("//tr[normalize-space(@class)='mBg1' or normalize-space(@class)='mBg2']")
temp = pd.DataFrame(e_tr, columns=['web'])
temp['时间'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd2').text.split(' ')[0])
temp['套数'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd5').text)
temp['均价'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd7').text)
temp['去化'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd14').text)
del temp['web']
self.data = pd.concat([temp, self.data], axis=0)
mcraw = MyCrawler()
data = mcraw.craw_page()
data= data.sort_values(by='时间')
print(data.to_string(index=False))
版权归原作者 zhouluobo 所有, 如有侵权,请联系我们删除。