
Celery PK APScheduler
Celery:我们通常将celery作为一个任务队列来使用,但是celery也有定时任务的功能。当然了,任务就是消息,消息中间件(也就是broker)可以使用redis或者rabbitmq 。
安装Celery模块:
pip install celery
Celery的默认broker(消息中间件)是RabbitMQ, 当然了,也可以使用Redis 。
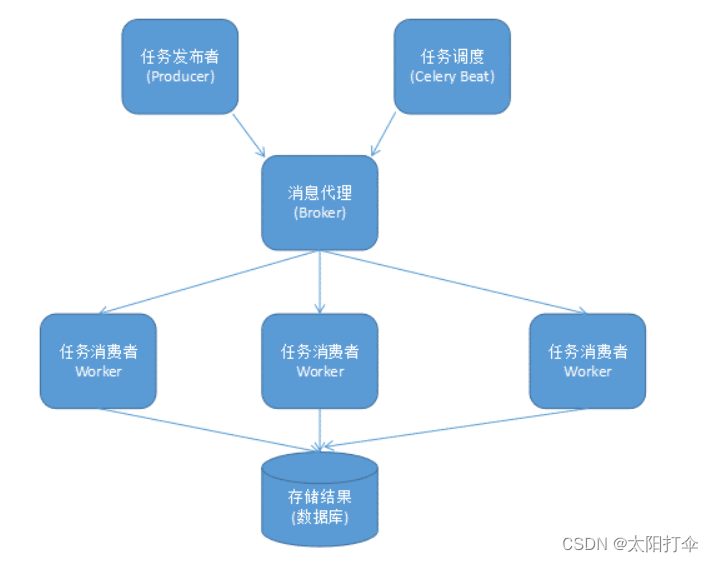
APScheduler:算是在实际项目中最好用的一个工具库,不仅可以在程序动态的添加和删除定时任务,还支持持久化 。APScheduler(Advanced Python Scheduler)是一个轻量级的Python定时任务调度框架(Python库)。
安装APScheduler库:
pip install apscheduler

APScheduler使用:
APScheduler有四个组件:
triggers: 触发器,用于设定触发任务的条件,触发器包含了调度的逻辑,每个任务都有自己的触发器决定该任务下次运行的时间。
job stores: 任务储存器,用于存放任务,把任务放在内存或者数据库中,一个
executors: 执行器,用于执行任务,可以设定执行模式为单线程或者线程池,任务完毕后,执行器会通知调度器
schedulers: 调度器,上面的三个组件都是参数,使用这三个参数创建调度器实例来运行
Celery简单使用代码展示:
先定义Celery应用:
test_celery.py:
from celery import Celery
from datetime import timedelta # 时间延后
app = Celery("tornado")
# 导入模块
app.conf["imports"] = ["celery_task"]
# 定义broker 代理人
app.conf.broker_url = "redis://:123@localhost:6379"
# 任务结果
app.conf.result_backend = "redis://:123@localhost:6379"
# 时区
app.conf.timezone = "Asia/Shanghai"
# 配置定时任务
app.conf.beat_schedule = {
"task1":{
"task":"celery_task.job", # 指定任务所在模块
"schedule":timedelta(seconds=3),
"args":()
}
}
定义celery任务task:
celery_task.py:
# 导入celery应用
from test_celery import app
from celery import shared_task # 装饰成定时任务
@shared_task
def job():
# 任务逻辑
return "test"
命令窗口开启服务(两个):
# 启动服务(命令窗)
celery -A test_celery worker --pool=solo -l info
celery -A test_celery beat -l info
会出现以下情况:
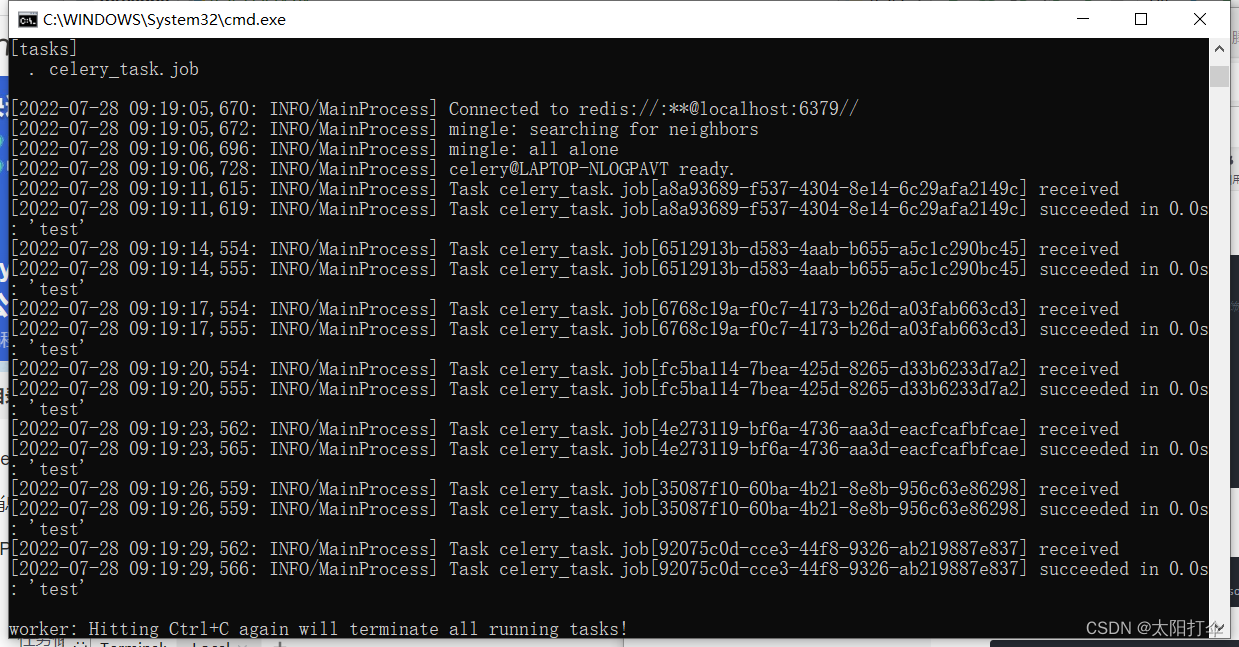

任务每隔三秒执行一次,这就是使用celery完成的简单定时任务,当然了,在实际工作当中会遇到较为复杂的任务,需要在任务中添加条件,这就要根据具体情况,具体分析!
APScheduler 使用起来还算是比较简单。运行一个调度任务只需要以下三部曲。
- 新建一个 schedulers (调度器) 。
- 添加一个调度任务(job stores)。
- 运行调度任务。
APScheduler的代码展示:
导包:
import os
from datetime import datetime
from tornado.ioloop import IOLoop, PeriodicCallback
from tornado.web import Application, RequestHandler, url
from apscheduler.schedulers.tornado import TornadoScheduler
写数据,初始化任务调度器:
scheduler = None
job_ids = []
# 初始化
def init_scheduler():
global scheduler
scheduler = TornadoScheduler()
scheduler.start()
print("定时任务启动")
声明要执行的任务:
def task(job_id,filename,size,count):
# 写入逻辑判断
count = int(count)
filelist = os.listdir("./static/uploads/")
temp = []
for i in range(count):
for x in filelist:
if x == "{}_{}".format(filename,i):
temp.append(x)
if len(temp) != count:
print("分片未传输成功")
return False
try:
filesize = os.path.getsize("./static/uploads/{}".format(filename))
except Exception as e:
filesize = 0
if int(size) != filesize:
print("分片合并未成功")
return False
# 删除分片
for x in range(count):
os.remove("./static/uploads/{}_{}".format(filename,x))
# 删除定时任务
scheduler.remove_job(job_id)
job_ids.remove(job_id)
print("分片执行完毕")
声明服务控制器:
class SchedulerHandler(RequestHandler):
async def get(self):
job_id = self.get_argument("job_id",None)
filename = self.get_argument("filename",None)
size = self.get_argument("size",None)
count = self.get_argument("count", None)
global job_ids
if job_id not in job_ids:
job_ids.append(job_id)
scheduler.add_job(task,"interval",seconds=3,id=job_id,args=(job_id,filename,size,count))
print("定时任务入队")
res = {"errcode":0,"msg":"ok任务完成"}
else:
print("该任务已经存在")
res = {"errcode":1,"msg":'fail失败'}
self.finish(res)
任务执行:
if __name__ == '__main__':
routes = [url(r"/scheduler/",SchedulerHandler)]
init_scheduler()
# 声明tornado对象
application = Application(routes,debug=True)
application.listen(8888) # 要注意端口号是否被占用问题
IOLoop.current().start()
在现在项目中,使用APScheduler也是比较简单的,掌握好技巧,玩转整个任务区!

本文转载自: https://blog.csdn.net/justzcy/article/details/126029088
版权归原作者 太阳打伞 所有, 如有侵权,请联系我们删除。
版权归原作者 太阳打伞 所有, 如有侵权,请联系我们删除。