
这里相较于 wordcount,新的知识点在于学生实体类的编写以及使用
数据信息:
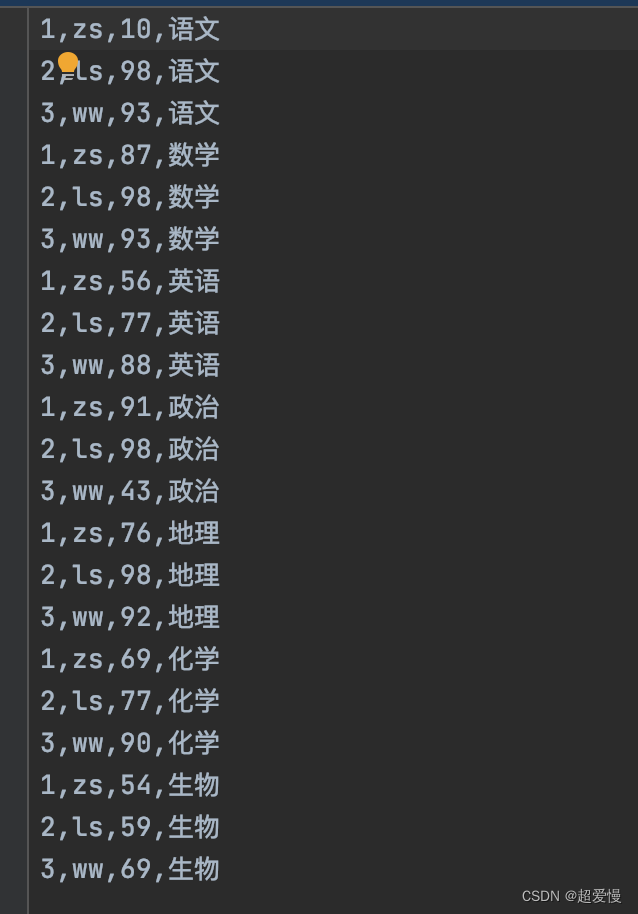
- Student 实体类
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Student implements WritableComparable<Student> {
// Object
private long stuid;
private String stuName;
private int score;
public Student(long stuid, String stuName, int score) {
this.stuid = stuid;
this.stuName = stuName;
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"stuid=" + stuid +
", stuName='" + stuName + '\'' +
", score=" + score +
'}';
}
public Student() {
}
public long getStuid() {
return stuid;
}
public void setStuid(long stuid) {
this.stuid = stuid;
}
public String getStuName() {
return stuName;
}
public void setStuName(String stuName) {
this.stuName = stuName;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
// 自动整理文件格式 ctrl + shift + f 英文输放状态
@Override
public int compareTo(Student o) {
return this.score > o.score ? 1 : 0;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(stuid);
dataOutput.writeUTF(stuName);
dataOutput.writeInt(score);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.stuid = dataInput.readLong();
this.stuName = dataInput.readUTF();
this.score = dataInput.readInt();
}
}
- mapper 阶段,StudentMapper 类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 输出 key:学生id value:Student对象
*/
public class StudentMapper extends Mapper<LongWritable, Text,LongWritable,Student> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
LongWritable stuidKey = new LongWritable(Long.parseLong(split[0]));
Student stuValue = new Student(Long.parseLong(split[0]),split[1],Integer.parseInt(split[2]));
context.write(stuidKey,stuValue);
}
}
- reduce 阶段,StudentReduce 类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class StudentReducer extends Reducer<LongWritable,Student,Student, NullWritable> {
@Override
protected void reduce(LongWritable key, Iterable<Student> values, Context context) throws IOException,
InterruptedException {
Student stuOut = new Student();
int sumScore = 0;
String stuName = "";
for (Student stu :
values) {
sumScore+=stu.getScore();
stuName = stu.getStuName();
}
stuOut.setScore(sumScore);
stuOut.setStuid(key.get());
stuOut.setStuName(stuName);
System.out.println(stuOut.toString());
context.write(stuOut, NullWritable.get());
}
}
- 驱动类,studentDriver 类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class StudentDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(StudentDriver.class);
//配置 job中map阶段处理类和map阶段的输出类型
job.setMapperClass(StudentMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Student.class);
//配置 job中deduce阶段处理类和reduce阶段的输出类型
job.setReducerClass(StudentReducer.class);
job.setOutputKeyClass(Student.class);
job.setOutputValueClass(NullWritable.class);
// 输入路径配置 "hdfs://kb131:9000/kb23/hadoopstu/stuscore.csv"
Path inpath = new Path(args[0]); // 外界获取文件输入路径
FileInputFormat.setInputPaths(job, inpath);
// 输出路径配置 "hdfs://kb131:9000/kb23/hadoopstu/out2"
Path path = new Path(args[1]); //
FileSystem fs = FileSystem.get(path.toUri(), conf);
if (fs.exists(path))
fs.delete(path,true);
FileOutputFormat.setOutputPath(job,path);
job.waitForCompletion(true);
}
}
本文转载自: https://blog.csdn.net/jojo_oulaoula/article/details/132568035
版权归原作者 超爱慢 所有, 如有侵权,请联系我们删除。
版权归原作者 超爱慢 所有, 如有侵权,请联系我们删除。