
💕世界上最美好的东西之一,就是你每天都有机会开始全新的一天。💕
🐼作者:不能再留遗憾了🐼
🎆专栏:MySQL学习🎆
🚗本文章主要内容:详细介绍如何查看、创建和删除MySQL索引,以及MySQL索引的底层原理:B+树。🚗

前言
各位朋友们,大家好!前面我们已经介绍了MySQL的库和表操作,今天我将为大家分享使数据库查询更加高效的MySQL索引,如果大家觉得博主的文章对你有用的话,记得点个赞哦!😘
什么是MySQL索引
MySQL索引是一种用于加速对MySQL数据库表中数据的查找的数据结构。它可以帮助MySQL数据库在查询时快速定位到所需数据,从而提高查询效率。
MySQL索引基于数据表的某一列或多列创建,并按照一定的算法进行排序存储,以快速地返回符合条件的数据。通常情况下,索引可以被创建在表的主键列、唯一约束列、普通列上,其中主键和唯一约束列上的索引是最常用的。
使用索引可以有效地加快查询操作的速度,但也会增加写操作的开销。因此,在创建索引时需要根据实际情况进行权衡考虑。
MySQL索引的作用
1.提高查询速度:索引可以加速MySQL数据库执行SELECT查询语句的速度。MySQL在查询时可以利用索引直接定位到所需的数据行,而不必遍历整个数据表。
2.保证数据的唯一性:在MySQL数据库中,主键或唯一约束列上的索引能够保证数据的唯一性,避免重复数据的出现。
3.提高排序速度:当对某一个列进行ORDER BY操作时,MySQL可以利用索引进行快速排序,避免在内存中执行排序操作所造成的效率低下。
4.加速数据表的连接:当数据表之间进行JOIN操作时,MySQL可以利用索引快速定位所需数据,并将其连接成需要的结果。
MySQL索引适合在哪些场景下使用
因为MySQL索引虽然提高了查询的效率,但是也需要付出一定的代价。
1.需要付出额外的空间代价来保存索引数据
2.索引可能会拖慢新增、删除、修改的速度
MySQL索引通常在一下场景下使用:
1.经常查询的列:如果一个列经常被用于 SELECT 或 WHERE,那么它应该被索引。这种情况下,索引可以大大提高查询的性能。
2.唯一性列:主键、唯一性约束条件和外键都应该创建索引,这可以确保数据表的数据唯一性,并保证数据表间连接的性能。
3.经常连接的表:如果两个或多个表经常出现在 JOIN 语句中,那么创建这些表之间连接所需的列上的索引,可以大大提高查询的性能。
4.经常排序的列: 如果一个数据表中的某个列经常出现在 ORDER BY 子句中,那么索引可以大大提高排序操作的速度。
5.经常分组的列: 如果一个数据表中的某个列经常用于聚合操作(如SUM、COUNT、AVG等),那么索引可以大大提高聚合操作的性能。
如何使用MySQL索引
查看索引
showindexfrom 表名

每一列所表示的含义:
Table:索引所属的数据表名。
Non_unique:这个索引是否是唯一索引。如果值为0,表示是唯一索引;如果值为1,表示非唯一索引。
Key_name:索引的名称。
Seq_in_index:索引中字段的位置。索引可以涉及到多个字段,这个字段标识了当前字段在索引中的位置。
Column_name:索引所在的列名。
Collation:索引的字符集。
Cardinality:索引中的唯一值的数量。
Sub_part:索引使用的列的前缀长度。
Packed:索引是否使用压缩。
Null:索引是否可以插入空值。
Index_type:索引的类型,可能是BTREE、HASH、FULLTEXT等。
Comment:关于索引的一些注释信息。
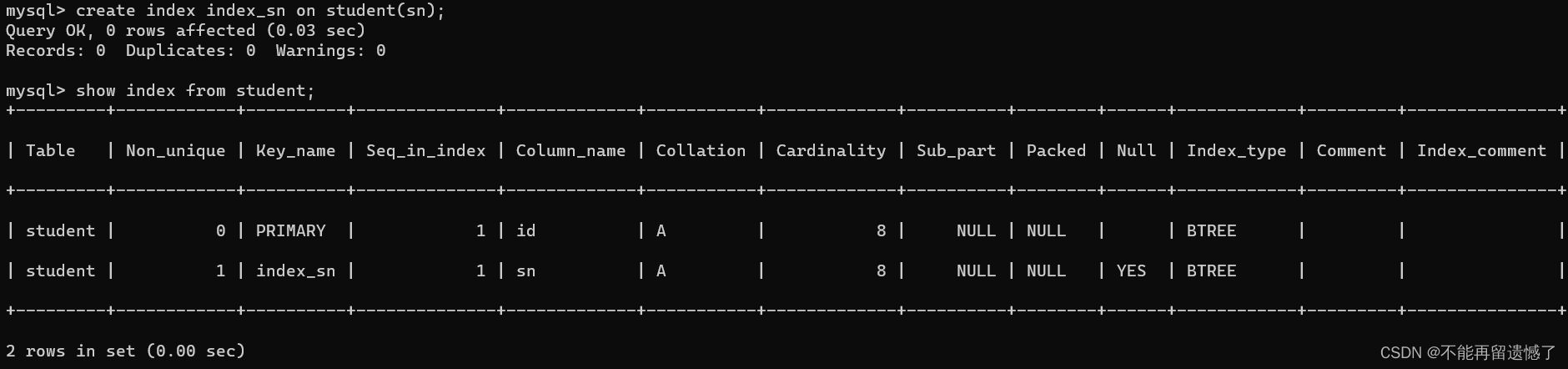
创建索引
createindex 索引名 on 表名(列名);
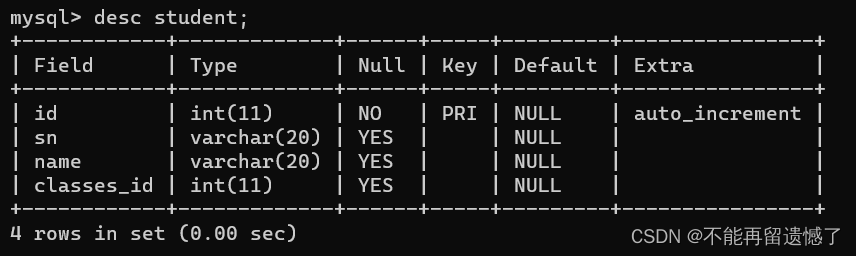
查看表结构
desc student;
创建索引并查看
createindex index_sn on student(sn);showindexfrom student;
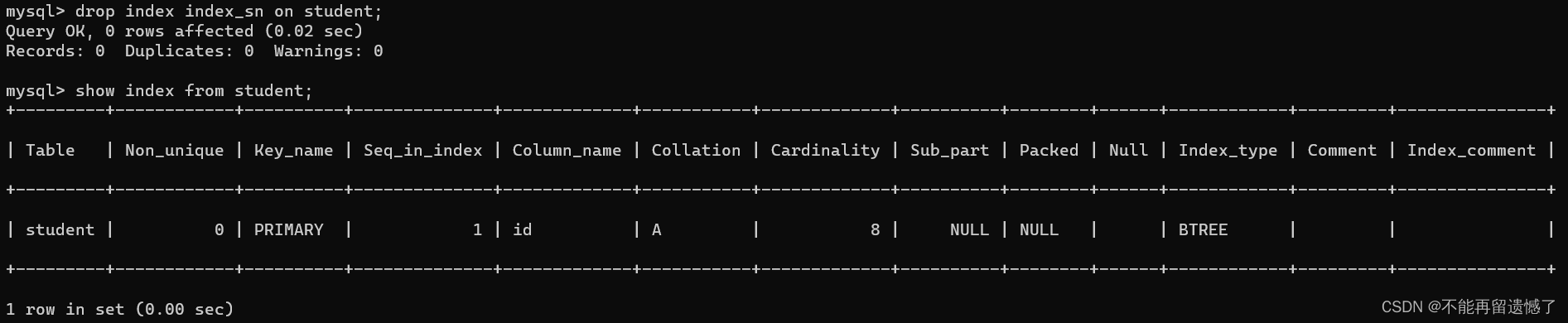
删除索引
dropindex 索引名 on 表名
dropindex index_sn on student;showindexfrom student;
MySQL索引的底层结构
MySQL索引的底层结构不是二叉搜索树和哈希表,而是B+树。说到B+树,大家可能都知道还有一个B树,B+树是在B树的基础上发展来的。
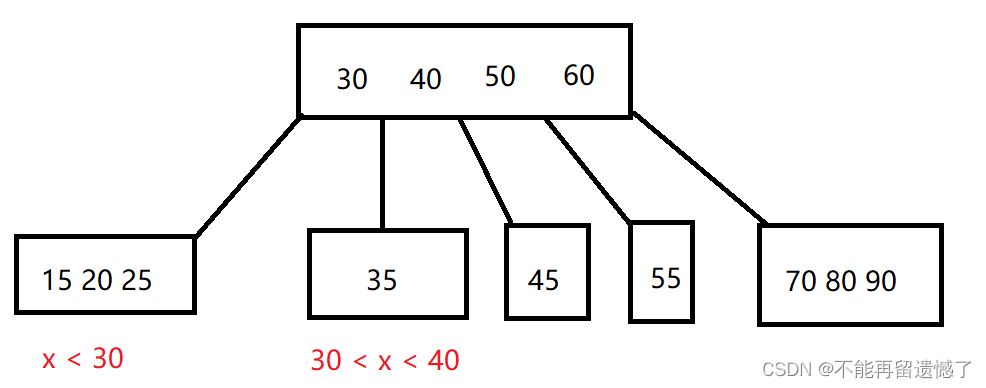
B树
🎁B树是一种多路查找树,用于在大小可变的文件中进行查找和排序。B树通常被用来实现数据库或文件系统中的数据结构,它具有平衡读写性能、支持数据的动态更新和查询复杂度低等优点。
🙌B树的基本思想是将关键字和数据元素按序存储在树的结点中,并按特定规则组织树形结构。B树的每个结点最多可以有m个子树,若结点中存储的关键字数为n,那么该结点中应有n+1个指向子树的指针。B树的关键字按大小顺序排列,且结点中所有关键字不重复。
下面就是一个简单的B树
B树的特点:
1.B树可以高效地支持多路查找。通过对结点进行平衡,B树的查找性能稳定,在最坏情况下仅需要O(log n)的时间复杂度即可在树结构中查找到一个关键字。
2.B树可以高效地支持数据的动态更新和平衡。通过在插入和删除操作中对树的平衡进行自我调整,B树能够高效地对数据的动态更新进行处理。
3.B树的每个结点可以存储更多的关键字和数据元素,进而减少磁盘I/O的次数,提高整体的查找和排序性能。
B+树
B+树是一种多路查找树,是B树的一种变种。B+树与B树的主要区别是:B+树的非叶子结点只包含导航信息,不包含实际数据;B+树的关键字只出现在叶子结点中,而且叶子结点本身按关键字大小顺序存储,且相邻叶子结点通过指针连接。
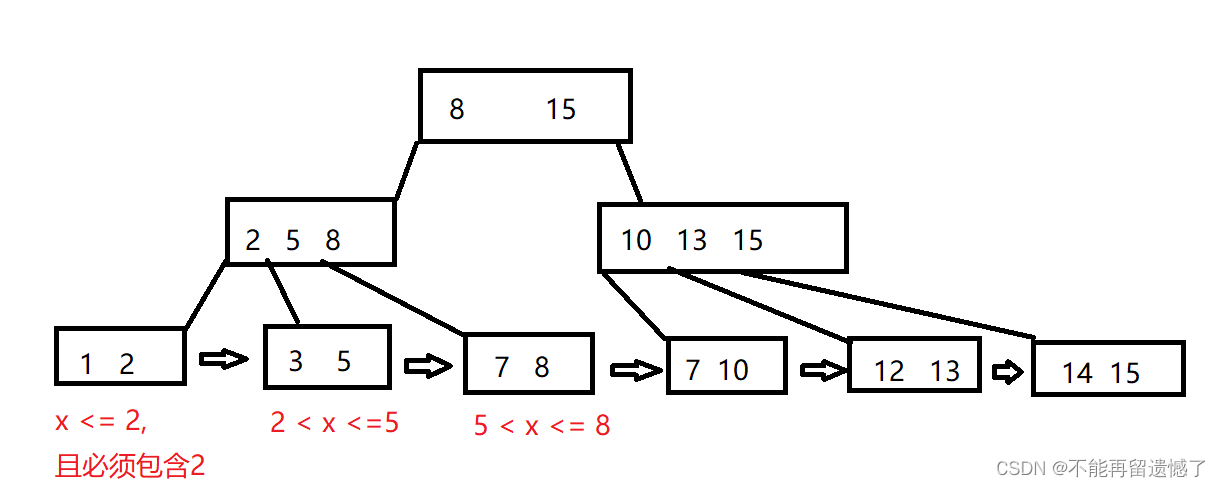
📱B+树的特点:
1.B+树的非叶子结点不存储数据,只存储导航信息。这种设计可以使得B+树的内部结构更加紧凑,从而减少树的高度,提高查询效率。
2.B+树的所有叶子结点都包含了相同的信息,因此可以很方便地实现区间查找或范围查找。这种设计也提高了B+树的查询性能。
3.类似B树,B+树也是平衡树,每个节点内部都包含多个关键字,能够有效支持多值查找和排序。
4.B+树的叶子结点之间可以用指针串接起来,形成一个有序链表,因此可以支持快速的区间遍历和排序数据。
🏀B+树的优势:
1.更快的查找性能:B+树在非叶子节点只存储索引信息,数据都存放在叶子节点中。当进行查找时,只需要从根节点开始往下遍历,每个非叶子节点只需要加载一次就能定位到数据所在的叶子节点,从而大大提高了查询效率。
2.更高的稳定性:B+树的非叶子节点只存储索引,而数据都存放在叶子节点中。当叶子节点变化时,只会对叶子节点进行操作,而非叶子节点不会改变,这种特性大大增加了数据结构的稳定性,减少了出错率。
3.适应范围更广:B+树能够适应更广范围的磁盘IO操作,因为B+树的叶子节点都是通过链表相互连接的,能够更加快速地支持区间查找和遍历操作,适用于海量数据存储和查询场景。
4.更高的顺序访问性能:由于B+树的叶子节点是按顺序进行存储的,因此能够更加快速地进行顺序遍历操作,特别是在需要频繁进行范围查询操作的场景,能够极大地提升性能。
注意
当表中存在一个主键索引时,如果还存在另一个索引,那么还是以主键索引为主构建B+树,叶子节点组织所有的数据行,而另一个非主键索引也会额外构架一个B+树,但是这个 B+ 树的叶子节点就不再存储这一行的完整数据,而是存主键的索引,还需要通过主键 索引 去主键的 B+ 树里再查一次(查两次 B+ 树),这个过程被称为回表
版权归原作者 不能再留遗憾了 所有, 如有侵权,请联系我们删除。