
写在前面的话
目前为止,你应该已经了解爬虫的三个基本小节:
来源:xiaqo.com
- 正文 明确需求我们今天要爬的数据是
豆瓣电影Top250,是的,只有250条数据,你没猜错。 输入网址https://movie.douban.com/top250我们可以看到网页长这样: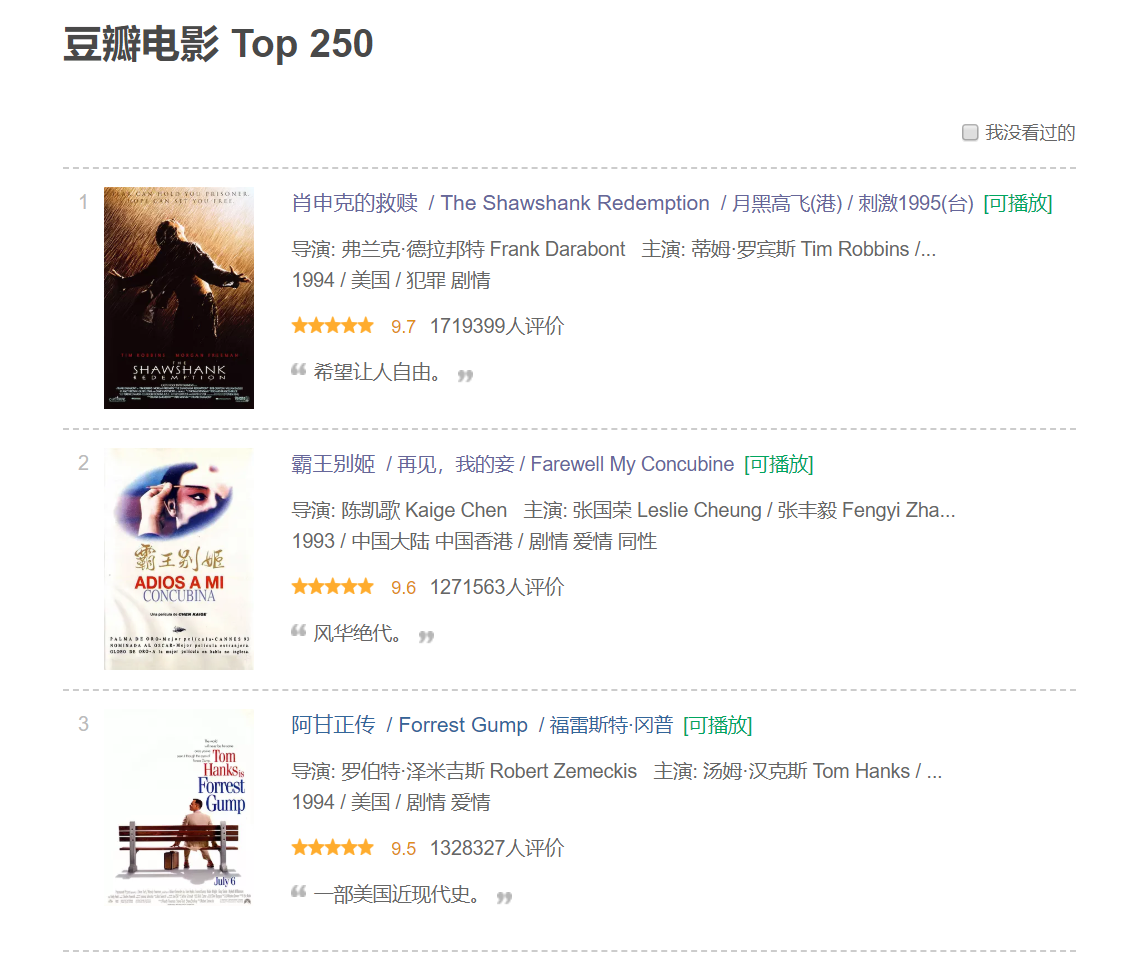
 编辑
编辑 编辑
编辑 250条数据清清楚楚,没有问题。 可以看到,这个页面其实已经包含了影片的主要内容:影片名、排序、编剧、主演、年份、类型、评论人数、评分,基本上都在这个页面中。但我点开详细影片之后,发现了这个: 编辑似乎这个页面数据更全一些,我们爬数据要的是什么,肯定是数据越多越好啊。相比这个详细内容,更是多了每个星级的影评占比,那我们肯定选择它了啊好,那理一下我们的思路 写一下伪代码
编辑似乎这个页面数据更全一些,我们爬数据要的是什么,肯定是数据越多越好啊。相比这个详细内容,更是多了每个星级的影评占比,那我们肯定选择它了啊好,那理一下我们的思路 写一下伪代码# 遍历10页data_movies # 保存所有影片数据集for per_page in pages: # 爬取10页的每一页数据 movies = craw_page_info(per_page) # 遍历每一页的25个影片 for movie in movies: # 爬取每个影片的详细内容 data_per_movie = craw_detail_info(movie) # 保存每个影片信息到数据集中 data_movies.append(data_per_movie) # 保存结果到数据库中data_movies_to_mysql稍微解释一下:两层循环,第一层是遍历10页网页,因为其中每个网页分别有25个影片,所以,第二层循环又依次遍历25个影片获取详细信息,最后保存结果到数据库中!是不是,很,简,单!> 但是,实操起来你可能会遇到各种各样的问题,做好心理准备! #### 开始实操 首先,确定我们要输出的影片字段主要数据包括:影片排序、影片名称、影片导演、影片编剧、影片主演、影片又名、影片链接关键数据包括:影片类型、制片国家、影片语言、上映日期、影片片长核心数据包括:影片评分、评论人数、5/4/3/2/1各星级对应的评论占比字段如下:movie_rank:影片排序movie_name:影片名称movie_director:影片导演movie_writer:影片编剧movie_starring:影片主演movie_type:影片类型movie_country:影片制片国家movie_language:影片语言movie_release_date:影片上映日期movie_run_time:影片片长movie_second_name:影片又名movie_imdb_href:影片IMDb 链接movie_rating:影片总评分movie_comments_user:影片评论人数movie_five_star_ratio:影片5星占比movie_four_star_ratio:影片4星占比movie_three_star_ratio:影片3星占比movie_two_star_ratio:影片2星占比movie_one_star_ratio:影片1星占比movie_note:影片备注信息,一般为空然后,开始主流程确认一下主要参数,起始页码(默认为0),每页影片25个,共10页,参数如下:start_page:起始页码page_size:每一页大小pages:总页码定义类对象> 这里我们将每个影片封装成一个对象,传入我们的主要参数,设置爬虫头部,并建立和数据库的相关连接类定义对象如下:class DouBanMovie: def __init__(self, url, start_page, pages, page_size): """ 初始化 @param url: 爬取主网址 @param start_page: 起始页码 @param pages: 总页码(截止页码) @param page_size: 每页的大小 """ self.url = url self.start_page = start_page self.pages = pages self.page_size = page_size self.data_info = [] self.pymysql_engine, self.pymysql_session = connection_to_mysql() self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } “小一哥,你这里的数据库连接用的是什么啊,我怎么看不太懂?” “我封装了一下,数据库的连接这里选用了 SQLAlchemy。" 不要着急,以后会专门写一篇 SQLAlchemy 关于数据库的相关操作# 创建基类,Base = declarative_base()def connection_to_mysql(): """ 连接数据库 @return: """ engine = create_engine('mysql+pymysql://username:passwd@localhost:3306/db_name?charset=utf8') Session = sessionmaker(bind=engine) db_session = Session() # 创建数据表 Base.metadata.create_all(engine) return engine, db_session确定主框架:# 如果当前页码小于0,异常退出if self.start_page < 0: return ""# 如果起始页面大于总页码数,退出if self.start_page > self.pages: return ""# 若当前页其实页码小于总页数,继续爬取数据while self.start_page < pages: # 拼接当前页的网址 # 主爬虫代码 # 下一页 self.start_page = self.start_page + 1拼接当前页的网址这里解释一下,当我们去访问第一页的时候发现网址如下https://movie.douban.com/top250去访问下一页的时候发现网址变化如下https://movie.douban.com/top250?start=25&filter=而再下一页的网址变化如下:https://movie.douban.com/top250?start=50&filter=可以发现,新的网址只是变化了后面的 start 参数,于是我们拼接出每一页的网址:start_number = self.start_page * self.page_sizenew_url = self.url + '?start=' + str(start_number) + '&filter=' 爬取第一个页面确定好主框架之后,我们需要去爬取第一个网页,也就是包含25个影片的页面。 这时候,我们前三节提到的爬虫实现方式直接拿过来:self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',} # 爬取当前页码的数据response = requests.get(url=new_url, headers=self.headers) 成功获取到页面数据之后,我们需要对页面解析,拿到每一个影片跳转详细页面的超链接> 通过谷歌浏览器 F12 开发者工具可查看网页源码可以看到每个影片的详细信息在一个li 标签中,而每个 li 标签中都有一个class='pic' 的 div,在 div 里面存在这样一个a 标签中而这个 a 标签的 href 正是我们要需要的详细页面信息的超链接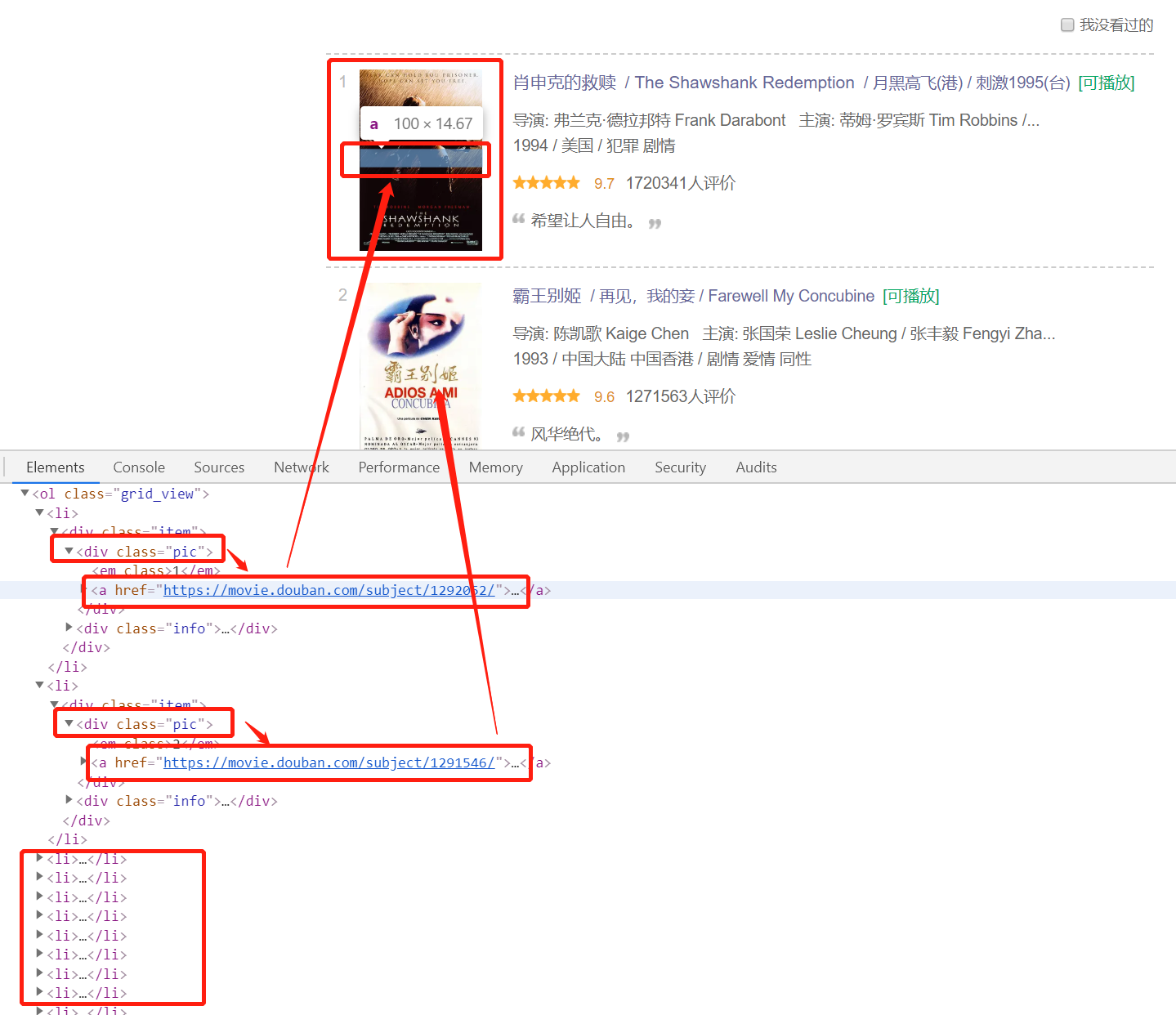 编辑 确定了超链接位置所在,打开我们上一节的 BeautifulSoup 详解,定位、解析
编辑 确定了超链接位置所在,打开我们上一节的 BeautifulSoup 详解,定位、解析soup = BeautifulSoup(response.text, 'html.parser')# 定位到每一个电影的 div (pic 标记的 div)soup_div_list = soup.find_all(class_="pic")# 遍历获取每一个 div 的电影详情链接for soup_div in soup_div_list: # 定位到每一个电影的 a 标签 soup_a = soup_div.find_all('a')[0] movie_href = soup_a.get('href') print(movie_href)拿到当前页面的25 个影片的详细内容的超链接我们离成功又进了一步!爬取详细页面同样,一行代码拿下页面数据'''爬取页面,获得详细数据'''response = requests.get(url=movie_detail_href, headers=self.headers)创建一个有序字典,保存当前影片数据# 生成一个有序字典,保存影片结果movie_info = OrderedDict()我们再来看一下这个页面的的源码是什么样的,首先是影片排序和影片名称,我们可以从上个页面传递过来。但是,既然它这里有,我直接解析行不行?必须行啊!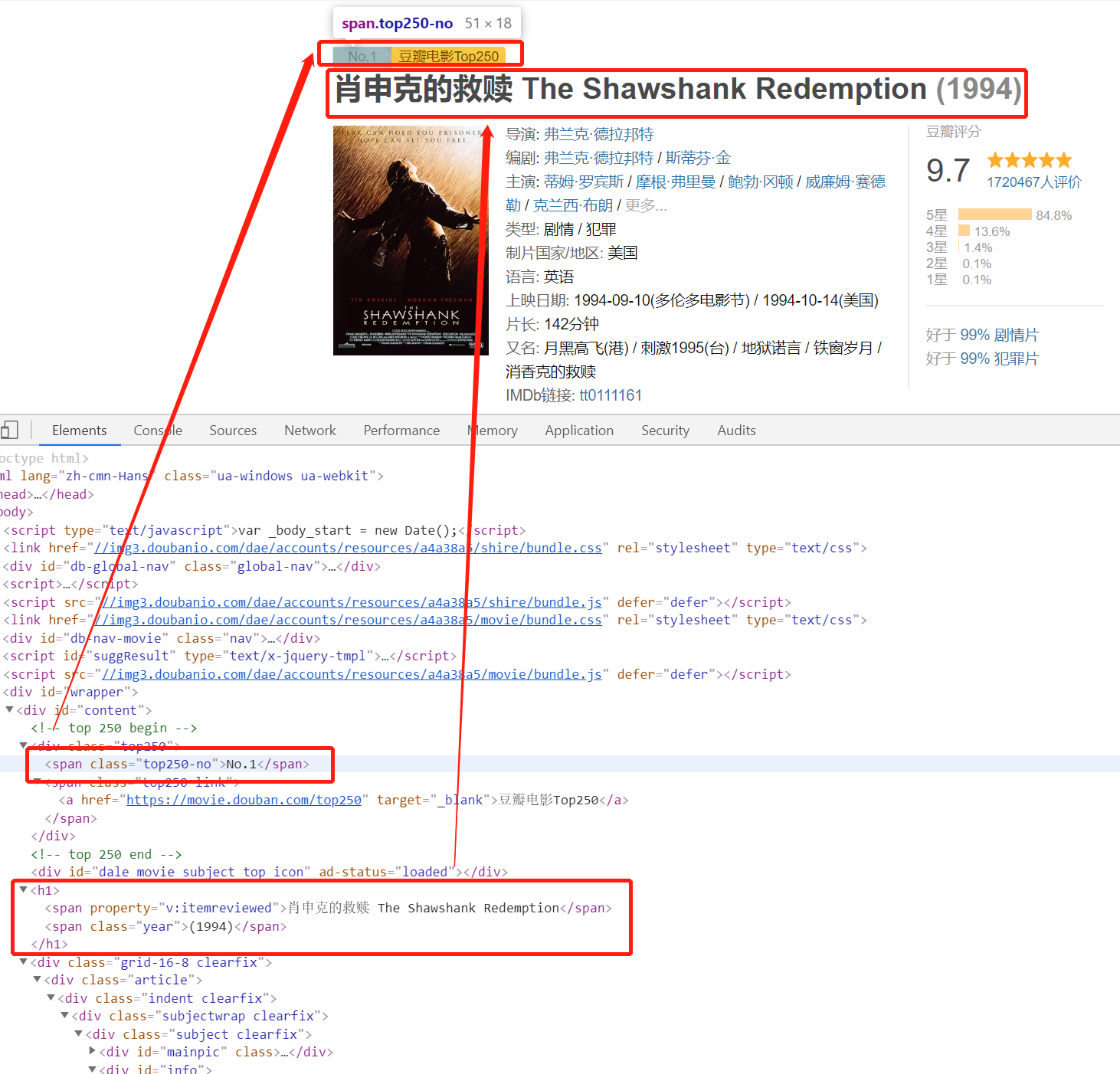 编辑 这个更简单,影片排名直接定位一个
编辑 这个更简单,影片排名直接定位一个 class='top250-no' 的 span 标签,影片名称定位一个property='v:itemreviewed' 的 span 标签,获取标签内容即可# 解析电影排名和名称movie_info['movie_rank'] = soup.find_all('span', class_='top250-no')[0].stringmovie_info['movie_name'] = soup.find_all('span', property='v:itemreviewed')[0].string 接下来是影片主要数据: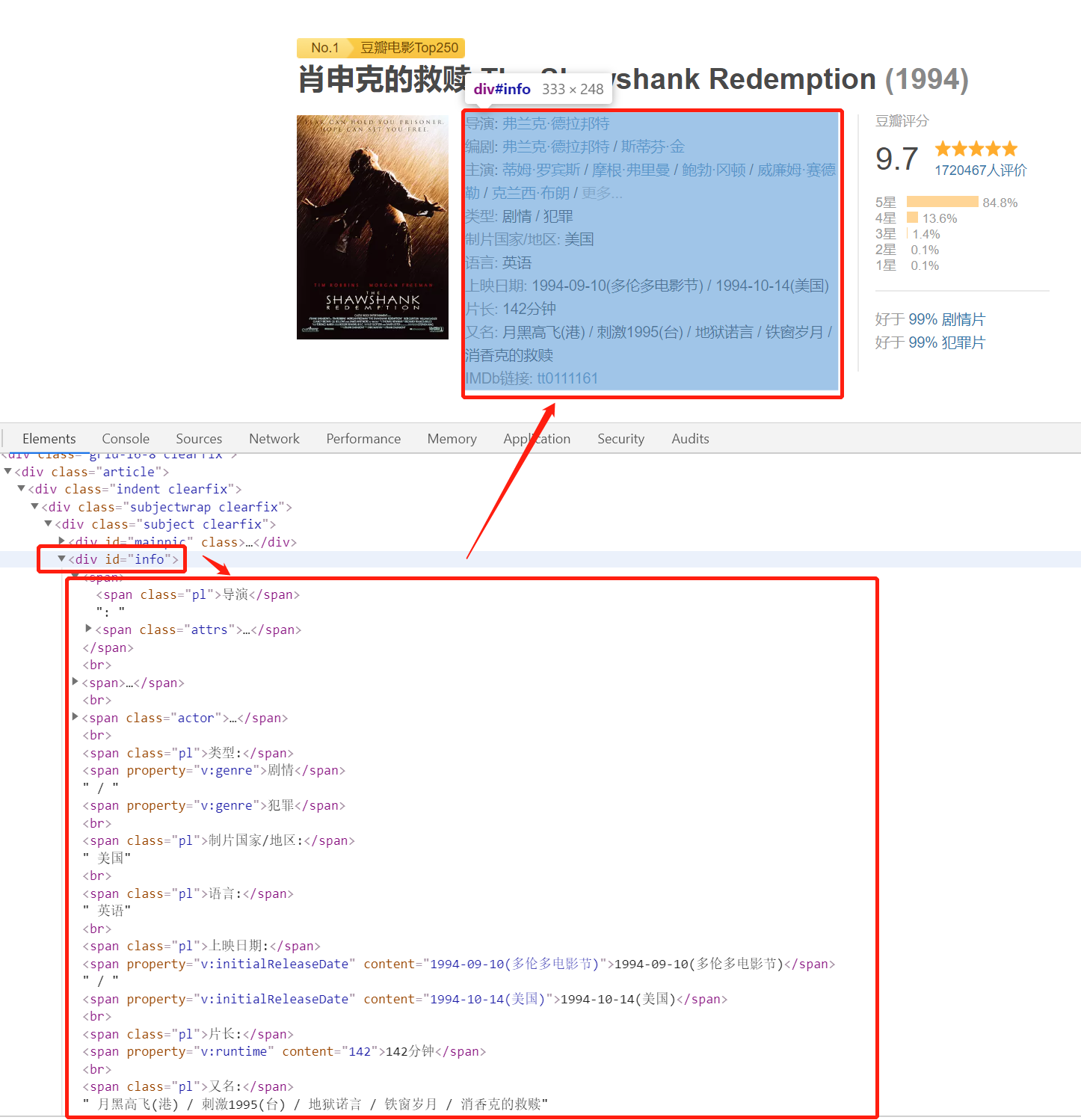 编辑 这个时候我们需要先定位到
编辑 这个时候我们需要先定位到 id='info' 的 div中,然后可以看到整个 div 的数据就是我们需要的主要数据。# 定位到影片数据的 divsoup_div = soup.find(id='info')“不对啊,小一哥,我发现编剧有时候是一个,有时候是多个。多个的时候存在在多个 span 标签中,这个怎么办啊?” 编辑“这个简单,我写一个小函数,统一处理一下。“
编辑“这个简单,我写一个小函数,统一处理一下。“def get_mul_tag_info(self, soup_span): """ 获取多个标签的结果合并在一个结果中返回,并用 / 分割 """ info = '' for second_span in soup_span: # 区分 href 和标签内容 info = ('' if (info == '') else '/').join((info, second_span.string)) return info“对了,你记得把最外层的 span 标签给我就行。像这种:”# 解析电影发布信息movie_info['movie_director'] = self.get_mul_tag_info(soup_div.find_all('span')[0].find_all('a'))movie_info['movie_writer'] = self.get_mul_tag_info(soup_div.find_all('span')[3].find_all('a'))movie_info['movie_starring'] = self.get_mul_tag_info(soup_div.find_all('span')[6].find_all('a'))movie_info['movie_type'] = self.get_mul_tag_info(soup_div.find_all('span', property='v:genre'))movie_info['movie_country'] = soup_div.find(text='制片国家/地区:').next_element.lstrip().rstrip()movie_info['movie_language'] = soup_div.find(text='语言:').next_element.lstrip().rstrip()movie_info['movie_release_date'] = self.get_mul_tag_info(soup_div.find_all('span', property='v:initialReleaseDate'))movie_info['movie_run_time'] = self.get_mul_tag_info(soup_div.find_all('span', property='v:runtime'))movie_info['movie_imdb_href'] = soup_div.find('a', target='_blank')['href']“小一哥,又出问题了,有的影片没有又名标签,这个怎么处理呢?” “这个我们做个异常检测,没有的手动赋空值就行了。”movie_second_name = ''try: movie_second_name = soup_div.find(text='又名:').next_element.lstrip().rstrip()except AttributeError: print('{0} 没有又名'.format(movie_info['movie_name'])) movie_info['movie_second_name'] = movie_second_name 最后还剩下评分数据评分数据不但有总评分,还有每个星级的评分。“小一哥,你说我们取哪个数据啊?” “小孩才做选择,我当然是全部都要!”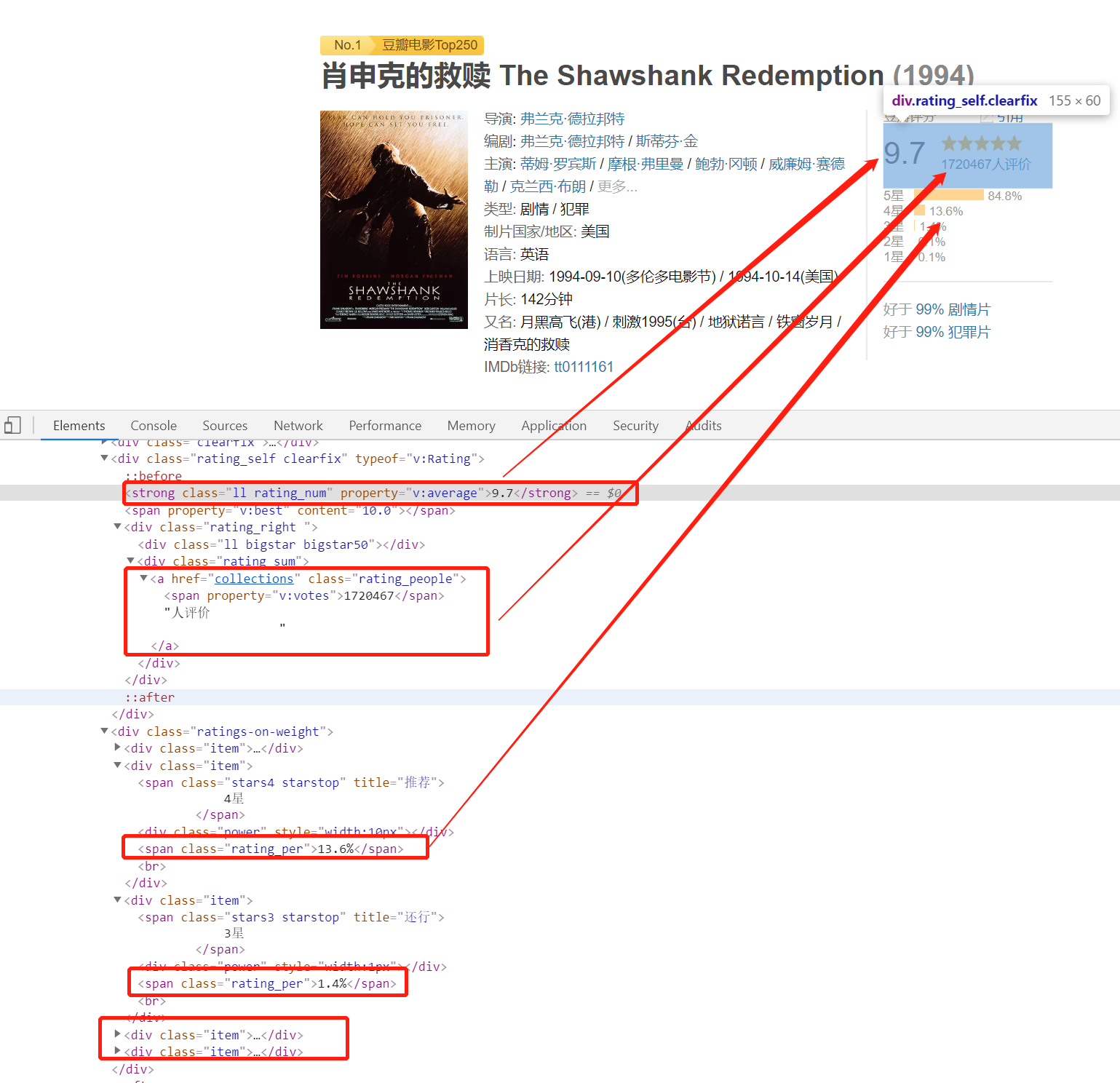 编辑 可以看到,总评分和总评论人数分别有一个
编辑 可以看到,总评分和总评论人数分别有一个唯一的 property,分别是property='v:average' 的 strong 标签和property='v:votes' 的 span 标签ok,接下来直接拿数据:# 获取总评分和总评价人数movie_info['movie_rating'] = soup.find_all('strong', property='v:average')[0].stringmovie_info['movie_comments_user'] = soup.find_all('span', property='v:votes')[0].string最后就剩下每个星级的评分占比,可以看到5星/4星/3星/2星/1星分别对应力荐/推荐/还行/较差/很差,可以看到他们都存在在一个class='ratings-on-weight' 的 div中所以,先定位 div :# 定位到影片星级评分占比的 divsoup_div = soup.find('div', class_="ratings-on-weight")然后获取每个星级评分占比数据:# 获取每个星级的评分movie_info['movie_five_star_ratio'] = soup_div.find_all('div')[0].find(class_='rating_per').stringmovie_info['movie_four_star_ratio'] = soup_div.find_all('div')[2].find(class_='rating_per').stringmovie_info['movie_three_star_ratio'] = soup_div.find_all('div')[4].find(class_='rating_per').stringmovie_info['movie_two_star_ratio'] = soup_div.find_all('div')[6].find(class_='rating_per').stringmovie_info['movie_one_star_ratio'] = soup_div.find_all('div')[8].find(class_='rating_per').string打印一下看一下我们当前的影片数据:> 对 movie_starring 字段只输出部分显示OrderedDict( [ ('movie_rank', 'No.1'), ('movie_name', '肖申克的救赎 The Shawshank Redemption'), ('movie_director', '弗兰克·德拉邦特'), ('movie_writer', '弗兰克·德拉邦特/斯蒂芬·金'), ('movie_starring', '蒂姆·罗宾斯/摩根·弗里曼/鲍勃·冈顿/威廉姆·赛德勒/), ('movie_type', '剧情/犯罪'), ('movie_country', '美国'), ('movie_language', '英语'), ('movie_release_date', '1994-09-10(多伦多电影节)/1994-10-14(美国)'), ('movie_run_time', '142分钟'), ('movie_imdb_href', 'https://www.imdb.com/title/tt0111161'), ('movie_rating', '9.7'), ('movie_comments_user', '1720706'), ('movie_five_star_ratio', '84.8%'), ('movie_four_star_ratio', '13.6%'), ('movie_three_star_ratio', '1.4%'), ('movie_two_star_ratio', '0.1%'), ('movie_one_star_ratio', '0.1%'), ('movie_note', '') ])搞定,成功拿到了想要的数据,最后一步:保存数据库``````# 保存当前影片信息self.data_info.append(movie_info)# 获取数据并保存成 DataFramedf_data = pd.DataFrame(self.data_info)# 导入数据到 mysql 中df_data.to_sql('t_douban_movie_top_250', self.pymysql_engine, index=False, if_exists='append')看一眼我们的数据库,该有的数据都存进去了 编辑到这里,爬虫就算是结束了。 ##### 总结一下:准备工作: 开始爬虫: 思考:以上就是我们今天爬虫实战的主要内容,相对来说比较简单。 第一个项目,旨在让大家了解
编辑到这里,爬虫就算是结束了。 ##### 总结一下:准备工作: 开始爬虫: 思考:以上就是我们今天爬虫实战的主要内容,相对来说比较简单。 第一个项目,旨在让大家了解爬虫流程,同时,也可以思考一下以下几点:以上数据的获取是否可以用今天的获取方法?如果不行,那应该通过什么方式获取这些数据? ##### 写在后面的话今天的实战项目就结束了,需要源代码的同学可以在公众号后台回复豆瓣电影获取,如果觉得小一哥讲的还不错的话,不妨点个赞?开篇已经提到,我们的目的不是爬数据。所以,我会利用这些数据做一个简单数据分析,目的很简单:了解数据分析的流程。下期见。- 首先,进入豆瓣电影Top250,一共10页,每页25个影片。- 然后,针对每一页的25个影片,进入其详细内容页面- 最后,解析每个影片的详细内容,保存内容到数据库中- 首先我们定义了一个影片对象,传入了网址的参数信息,设置了爬虫头部,并建立了数据库连接- 我们通过下一页分析出每个影片页的超链接,发现只是改变了参数- 建立了主流程,并写出了主流程的伪代码- 爬取第一页的网页内容- 解析第一页的内容,获取每页中25个影片的详细超链接- 爬取详细影片的网页内容- 解析第二页的内容,保存到每个影片对象中-保存数据到数据库中- 影片详细页面的短评论数据- 影片详细页面的获奖情况数据- 影片详细页面的讨论区数
标签:
爬虫
本文转载自: https://blog.csdn.net/2301_79354153/article/details/134678845
版权归原作者 JBIB 所有, 如有侵权,请联系我们删除。
版权归原作者 JBIB 所有, 如有侵权,请联系我们删除。