
文章目录
窗口的概念
窗口:将无限数据切割成有限的“数据块”进行处理,串口是处理无界流的核心。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jJAjyIen-1650124027990)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220416182143892.png)]](https://img-blog.csdnimg.cn/4ea9720f568744debbfe15a44ad16e76.png)
窗口更像一个“桶”,将流切割成有限大小的多个存储桶,每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
- 动态创建:当有落在这个窗口区间范围的数据到达时,才创建对应的窗口
- 窗口关闭:到达窗口结束时间时,窗口就触发计算并关闭
窗口的分类
按照驱动类型分类
以什么标准来开始和结束数据的截取,我们把它叫做窗口的“驱动类型”,常见的有时间窗口、计数窗口。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1IVCUSLC-1650124027994)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220416182940280.png)]](https://img-blog.csdnimg.cn/dd65d2f0095b49ca8d62e5c770606911.png)
(1)时间窗口
时间窗口以时间点到来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。
窗口大小 = 结束时间 - 开始时间
Flink中有一个专门的TimeWindow类来表示时间窗口,这个类只有两个私有属性,表示窗口的开始和结束的时间戳,单位为毫秒
privatefinallong start;privatefinallong end;
我们可以调用公有的getStart()和getEnd()方法直接获取这两个时间戳。另外TimeWindow还提供了maxTimestamp()方法,用来获取窗口中能够包含数据的最大时间戳,窗口中运行的最大时间戳为end - 1,这代表了我们定义的窗口时间范围都是左闭右开的区间[start,end)
publiclongmaxTimestamp(){return end -1;}
(2)计数窗口(Count Window)
基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。
计数窗口理解简单,只需指定窗口大小,就可以把数据分配到对应的窗口中,Flink内部对应的类来表示计数窗口,底层通过全局窗口(Global Window)实现
按照窗口分配数据的规则分类
时间窗口、计数窗口只是对窗口的一个大致划分。在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以由不同的功能应用。
(1)滚动窗口(Tumbling Windows)
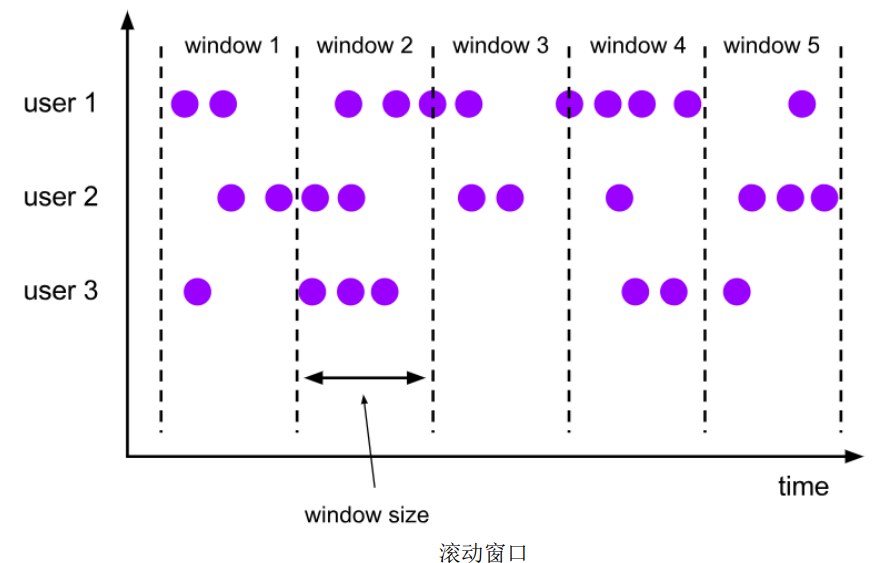
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式,首尾相接。我们之前所举的例子都是滚动窗口,也正是因为滚动窗口无缝衔接,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有窗口大小,我们可以定义一个长度为1小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为10的滚动计数窗口,就会每10个数进行一次统计
(2)滑动窗口(Sliding Windows)
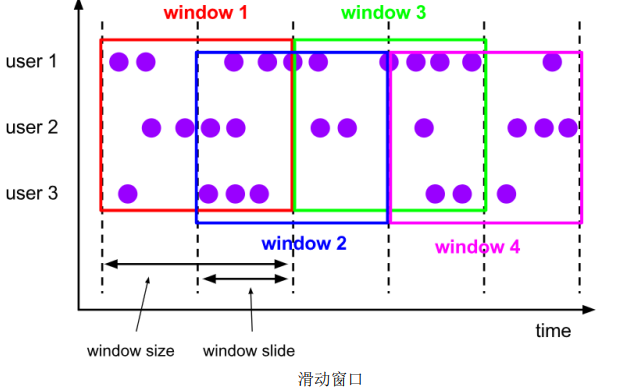
滑动窗口的大小固定,但窗口之间不是首尾相接,而有部分重合。滑动窗口可以基于时间定义、数据个数。
定义滑动窗口的参数与两个:窗口大小,滑动步长。滑动步长是固定的,且代表了两个个窗口开始/结束的时间间隔。数据分配到多个窗口的个数 = 窗口大小/滑动步长
(3)会话窗口(Session Windows)
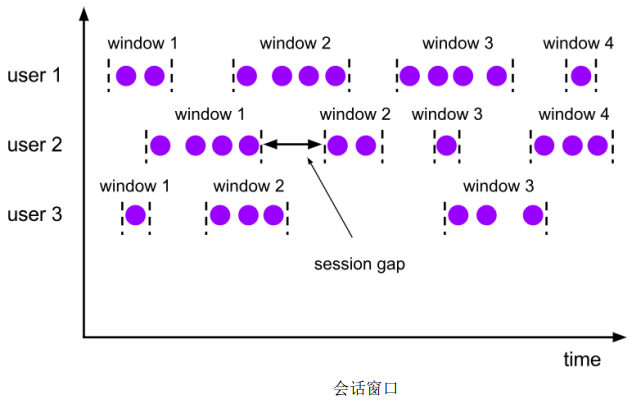
会话窗口只能基于时间来定义,“会话”终止的标志就是隔一段时间没有数据来。
size:两个会话窗口之间的最小距离。我们可以设置静态固定的size,也可以通过一个自定义的提取器(gap extractor)动态提取最小间隔gap的值。
在Flink底层,对会话窗口有比较特殊的处理:每来一个新的数据,都会创建一个新的会话窗口,然后判断已有窗口之间的距离,如果小于给定的size,就对它们进行合并操作。在Winodw算子中,对会话窗口有单独的处理逻辑。
会话窗口的长度不固定、起始和结束时间不确定,各个分区窗口之间没有任何关联。会话窗口之间一定是不会重叠的,且会留有至少为size的间隔
(4)全局窗口(Global Windows)
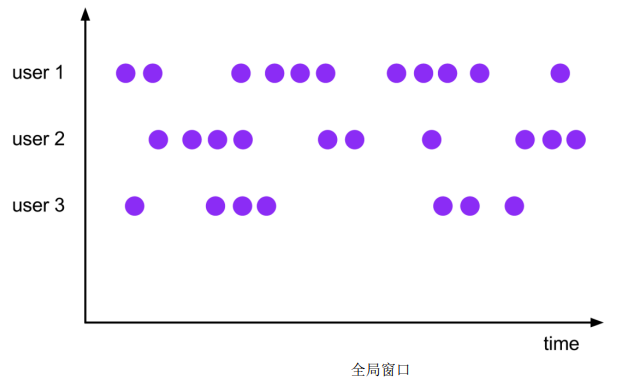
相同key的所有数据都分配到一个同一个窗口中;无界流的数据永无止境,窗口没有结束的时候,默认不做触发计算,如果希望对数据进行计算处理,还需要自定义“触发器”(Trigger)
窗口API概览
按键分区窗口(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先需要确定,到达是基于按键分区(Keyed)的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。也就是在调用窗口算子之前是否有keyBy操作
按键分区窗口(Keyed Windows)
经过按按键分区keyBy操作后,数据流会按照key被分为多条逻辑流(logical streams),也就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据被发送到同一个并行子任务,而窗口操作会基于每个key单独的处理。可以认为每个key上都定义了一组窗口,各自独立地进行统计计算。
stream.keyBy(...).window(...)
非按键分区(Non-Keyed Windows)
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,相当于并行度变成了1
stream.windowAll(...)
代码中窗口API的调用
窗口的操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)
stream.keyBy(<key selector>).window(<window assigner>).aggregate(<window function>)
窗口分配器(Window Assigners)
定义窗口分配器是构建窗口算子的第一步,作用是定义数据应该被“分配”到哪个窗口。
窗口按照驱动类型可以分成时间窗口和计数窗口,按照具体的分配规定为滚动窗口、滑动窗口、会话窗口、全局窗口。除去自定义外的全局窗口外,其它常用的类型Flink都给出了内置的分配器实现
1、时间窗口
时间窗口又可以细分为:滚动、滑动、会话三种
(1)滚动处理时间窗口
stream.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(...)
这里创建了一个长度为5秒的滚动窗口。
.of()还有一个重载方法,可以传入两个Time类型的参数:size和offset。第二个参数代表窗口起始点的偏移量,比如,标志时间戳是1970年1月1日0时0分0秒0毫秒开始计算的一个毫秒数,这个时间时UTC时间,以0时区为标准,而我们所在的时区为东八区(UTC+8)。我们定义一天滚动窗口时,伦敦时间0但对应北京时间早上8点。那么设定如下就可以得到北京时间每天0点开开启滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.days(1),Time.hours(-8)))
(2)滑动处理时间窗口
stream.keyBy(...).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))).aggregate(...)
两个Time类型的参数:size和slide。后者表示滑动窗口的滑动步长。当然,可以追加第三个参数offset,用法同上
(3)处理时间会话窗口
stream.keyBy(...).window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))).aggregate(...)
.withGap()方法需要传入一个Time类型的参数size,表示会话的超时时间,也就是最小间隔session gap,静态的
.window(ProcessingTimeSessionWindows.withDynamicGap(newSessionWindowTimeGapExtractor<Tuple2<String,Long>>(){@Overridepubliclongextract(Tuple2<String,Long> element){// 提取 session gap 值返回, 单位毫秒return element.f0.length()*1000;}}))
动态提取时间间隔,这里我们提取了数据元素的第一个字段,用它的长度乘以1000作为会话超时的间隔
(4)滚动事件时间窗口
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.seconds(5))).aggregate(...)
(5)滑动事件时间窗口
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
(6)事件时间会话窗口
stream.keyBy(...).window(EventTimeSessionWindows.withGap(Time.seconds(10))).aggregate(...)
2、计数窗口
底层是全局窗口,Flink为我们提供了非常方便地接口:直接调用countWindow()方法,根据分配规则的不同,又可以分为滚动计数、滑动计数窗口。
(1)滚动计数窗口
stream.keyBy(...).countWindow(10)
(2)滑动计数窗口
stream.keyBy(...)
.countWindow(10,3)
长度为10,滑动步长为3
3、全局窗口
stream.keyBy(...).window(GlobalWindows.create());
使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
窗口函数(Window Functions)
定义窗口分配,我们知道了数据属于哪个窗口;定义窗口函数,如何进行计算的操作,这就是所谓的“窗口函数”。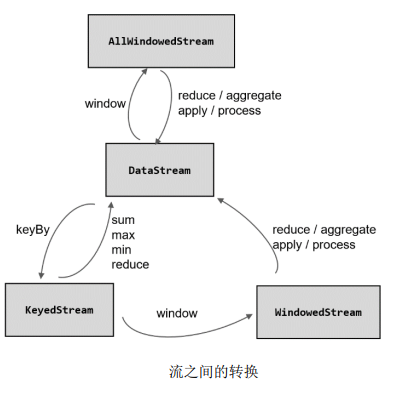
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数、全窗口函数
增量函数
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。窗口对无限流的切分,可以看作得到了一个有界数据集。如果我们等到所有数据都收集齐,在窗口到了结束时间要输出结果的一瞬间再去进行聚合,显然就不够高效了——批处理的思路做实时处理
为了提高实时性,我们可以每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间拿出之前聚合的状态直接输出。
典型的增量聚合函数有两个:ReduceFunction、AggregateFunction
(1)归约函数(ReduceFunction)
将窗口收集到的数据两两进行归约,实现增量式的聚合。
窗口函数提供了ReduceFunction
importcom.yingzi.chapter05.Source.ClickSource;importcom.yingzi.chapter05.Source.Event;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.api.common.functions.MapFunction;importorg.apache.flink.api.common.functions.ReduceFunction;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importjava.time.Duration;publicclassWindowReduceExample{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 从自定义数据源读取数据,并提取时间戳、生成水位线SingleOutputStreamOperator<Event> stream = env.addSource(newClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.timestamp;}}));
stream.map(newMapFunction<Event,Tuple2<String,Long>>(){@OverridepublicTuple2<String,Long>map(Event value)throwsException{// 将数据转换成二元组,方便计算returnTuple2.of(value.user,1L);}}).keyBy(r -> r.f0)// 设置滚动事件时间窗口.window(TumblingEventTimeWindows.of(Time.seconds(5))).reduce(newReduceFunction<Tuple2<String,Long>>(){@OverridepublicTuple2<String,Long>reduce(Tuple2<String,Long> value1,Tuple2<String,Long> value2)throwsException{// 定义累加规则,窗口闭合时,向下游发送累加结果returnTuple2.of(value1.f0, value1.f1 + value2.f1);}}).print();
env.execute();}}
(2)聚合函数(AggregateFunction)
ReduceFunction接口有一个限制:输入数据类型、聚合状同类型、输出结果的类型一样。这就迫使我们在聚会前先将数据转换成预期结果类型。而在有些情况下,需要对状态进一步处理才能得到输出结果时,这时它们的类型可能不同。
Flink的Window API中的aggregate就提供了这样的操作。直接基于WindowedStream调用.aggregate()方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction的实现类
publicinterfaceAggregateFunction<IN, ACC, OUT>extendsFunction,Serializable{ACCcreateAccumulator();ACCadd(IN value,ACC accumulator);OUTgetResult(ACC accumulator);ACCmerge(ACC a,ACC b);}
AggregateFunction可看作是ReduceFunction的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)、输出类型(OUT)
- createAccumulator():创建一个累加器,为聚合创建一个初始状态
- add():将输入的元素添加到累加器中,这就是基于聚合状态,对新来的数据进一步聚合。方法传入两个参数,当前新到的数据value,和当前的累加器accumulator,返回一个新的累加器值。
- getResult():从累加器中提取聚合输出的结果。
- merge():合并两个累加器,并将合并的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口的场景就是会话窗口
下面举个例子:PV(页面浏览量)和UV(独立访客量)是非常重要的两个流量指标,我们计算 PV/UV
importcom.yingzi.chapter05.Source.ClickSource;importcom.yingzi.chapter05.Source.Event;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.api.common.functions.AggregateFunction;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importjava.time.Duration;importjava.util.HashSet;publicclassWindowAggregateTest_PVUV{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);SingleOutputStreamOperator<Event> stream = env.addSource(newClickSource())//乱序流的watermark生成.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.timestamp;}}));
stream.print("data");// 所有数据放在一起统计pv和uv
stream.keyBy(data ->true).window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(2))).aggregate(newAvgPv()).print();
env.execute();}//自定义一个AggregateFunction,用Long保存pv个数,用HashSet做uv去重publicstaticclassAvgPvimplementsAggregateFunction<Event,Tuple2<Long,HashSet<String>>,Double>{@OverridepublicTuple2<Long,HashSet<String>>createAccumulator(){returnTuple2.of(0L,newHashSet<>());}@OverridepublicTuple2<Long,HashSet<String>>add(Event value,Tuple2<Long,HashSet<String>> accumulator){//每来一条数据,pv个数+1,将user放入HashSet中
accumulator.f1.add(value.user);returnTuple2.of(accumulator.f0 +1,accumulator.f1);}@OverridepublicDoublegetResult(Tuple2<Long,HashSet<String>> accumulator){//窗口触发时,输出pv和uv的比值return(double) accumulator.f0 / accumulator.f1.size();}@OverridepublicTuple2<Long,HashSet<String>>merge(Tuple2<Long,HashSet<String>> a,Tuple2<Long,HashSet<String>> b){returnnull;}}}
全窗口函数(full window functions)
全窗口需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
典型的批处理思路——先攒数据,等一批都到齐了再正式启动处理流程。这种相较之下是低效的。
Flink中,全窗口函数也有两种:WindowFunction和ProcessWindowFunction
(1)窗口函数(WindowFunction)
WindowFunction是老版本的通用窗口函数接口,我们可以基于WindowedStream调用.apply()方法,传入一个WindowFunction实现类
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
这个类接口的源码如下:
publicinterfaceWindowFunction<IN, OUT, KEY,WextendsWindow>extendsFunction,Serializable{voidapply(KEY key,W window,Iterable<IN> input,Collector<OUT> out)throwsException;}
当窗口到达结束时间需要触发计算时,就会调用这里的apply方法。我们可以从input集合中取出窗口收集的数据,结合key和window信息,通过收集器输出结果。WindowFunction的作用可以被ProcessWindowFunction全覆盖,一般在实际应用中,直接使用ProcessWindowFunction就可以
(2)处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口,他可以获取到一个“上下文对象”(Context)。这个上下文对象不仅能够获取窗口信息,还可以访问当前的时间和状态信息,这里的时间就包括了处理时间和事件时间水位线。
例子:求UV
importcom.yingzi.chapter05.Source.ClickSource;importcom.yingzi.chapter05.Source.Event;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;importorg.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importorg.apache.flink.streaming.api.windowing.windows.TimeWindow;importorg.apache.flink.util.Collector;importjava.sql.Timestamp;importjava.time.Duration;importjava.util.HashSet;publicclassWindowProcessTest{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);SingleOutputStreamOperator<Event> stream = env.addSource(newClickSource())//乱序流的watermark生成.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.timestamp;}}));//使用ProcessWindowFunction计算UV
stream.keyBy(data ->true).window(TumblingEventTimeWindows.of(Time.seconds(10))).process(newUvCountByWindow()).print();
env.execute();}//实现自定义的ProcessWindowFunction,输出一条统计信息publicstaticclassUvCountByWindowextendsProcessWindowFunction<Event,String,Boolean,TimeWindow>{@Overridepublicvoidprocess(Boolean aBoolean,Context context,Iterable<Event> elements,Collector<String> out)throwsException{//用一个HashSet保存userHashSet<String> userSet =newHashSet<>();//从elements中遍历数据,放到set中去重for(Event element : elements){
userSet.add(element.user);}Integer uv = userSet.size();//结合窗口信息Long start = context.window().getStart();Long end = context.window().getEnd();
out.collect("窗口"+newTimestamp(start)+"~"+newTimestamp(end)+"UV值为:"+ uv);}}}
增量聚合和全窗口结合
增量聚合的优点:高效,输出更加实时
全窗口的优点:提供更多的信息,更加“通用”的窗口操作。
在实际应用中,我们往往希望兼具这两者的优点,,结合使用,我们在传入窗口函数哪里,这里调用的机制:第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当做Iterable类型的输出。
例子:
为了方便处理,单独定义了一个POJO类,来表示输出结果的数据类型
publicclassUrlViewCount{publicString url;publicLong count;publicLong windowStart;publicLong windowEnd;publicUrlViewCount(){}publicUrlViewCount(String url,Long count,Long windowStart,Long windowEnd){this.url = url;this.count = count;this.windowStart = windowStart;this.windowEnd = windowEnd;}@OverridepublicStringtoString(){return"UrlViewCount{"+"url='"+ url +'\''+", count="+ count +", windowStart="+newTimestamp(windowStart)+", windowEnd="+newTimestamp(windowEnd)+'}';}}
importcom.yingzi.chapter05.Source.ClickSource;importcom.yingzi.chapter05.Source.Event;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.api.common.functions.AggregateFunction;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;importorg.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importorg.apache.flink.streaming.api.windowing.windows.TimeWindow;importorg.apache.flink.util.Collector;publicclassUrlCountViewExample{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);SingleOutputStreamOperator<Event> stream = env.addSource(newClickSource())//乱序流的watermark生成.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.timestamp;}}));
stream.print("input");//统计每个url的访问量
stream.keyBy(data -> data.url).window(TumblingEventTimeWindows.of(Time.seconds(10))).aggregate(newUrlViewCountAgg(),newUrlViewCountResult()).print();
env.execute();}//增量聚合,来一条数据 + 1publicstaticclassUrlViewCountAggimplementsAggregateFunction<Event,Long,Long>{@OverridepublicLongcreateAccumulator(){return0L;}@OverridepublicLongadd(Event value,Long accumulator){return accumulator +1;}@OverridepublicLonggetResult(Long accumulator){return accumulator;}@OverridepublicLongmerge(Long a,Long b){returnnull;}}//包装窗口信息,输出UrlViewCountpublicstaticclassUrlViewCountResultextendsProcessWindowFunction<Long,UrlViewCount,String,TimeWindow>{@Overridepublicvoidprocess(String s,Context context,Iterable<Long> elements,Collector<UrlViewCount> out)throwsException{Long start = context.window().getStart();Long end = context.window().getEnd();Long count = elements.iterator().next();
out.collect(newUrlViewCount(s,count,start,end));}}}
测试水位线和窗口的使用
importcom.yingzi.chapter05.Source.Event;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.api.common.functions.MapFunction;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;importorg.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importorg.apache.flink.streaming.api.windowing.windows.TimeWindow;importorg.apache.flink.util.Collector;importjava.time.Duration;publicclassWatermarkTest2{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 将数据源改为 socket 文本流,并转换成 Event 类型
env.socketTextStream("hadoop102",7777).map(newMapFunction<String,Event>(){@OverridepublicEventmap(String value)throwsException{String[] fields = value.split(",");returnnewEvent(fields[0].trim(), fields[1].trim(),Long.valueOf(fields[2].trim()));}})// 插入水位线的逻辑.assignTimestampsAndWatermarks(// 针对乱序流插入水位线,延迟时间设置为 5sWatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){// 抽取时间戳的逻辑@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.timestamp;}}))// 根据 user 分组,开窗统计.keyBy(data -> data.user).window(TumblingEventTimeWindows.of(Time.seconds(10))).process(newWatermarkTestResult()).print();
env.execute();}// 自定义处理窗口函数,输出当前的水位线和窗口信息publicstaticclassWatermarkTestResultextendsProcessWindowFunction<Event,String,String,TimeWindow>{@Overridepublicvoidprocess(String s,Context context,Iterable<Event> elements,Collector<String> out)throwsException{Long start = context.window().getStart();Long end = context.window().getEnd();Long currentWatermark = context.currentWatermark();Long count = elements.spliterator().getExactSizeIfKnown();
out.collect("窗口"+ start +" ~ "+ end +"中共有"+ count +"个元素, 窗口闭合计算时,水位线处于:"+ currentWatermark);}}}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6YSvWMHg-1650124027998)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220416223947979.png)]](https://img-blog.csdnimg.cn/384ee01d2f574927ba3d486b2d411b1b.png)
当最后输入Alice, ./prod?id=300, 15000时,流中会周期性地插入一个时间戳为15000L – 5 * 1000L – 1L = 9999 毫秒的水位线,已经到达了[0,10000)的结束时间。
其他API
对于一些窗口算子而言,窗口分配器和窗口函数是必不可少的,除此之外,Flink还提供了其他一些可选的API,可让我们更加灵活地控制窗口行为
1、触发器(Trigger)
调用trigger()方法,就可以传入一个自定义的窗口触发器
stream.keyBy(...).window(...).trigger(newMyTrigger())
Trigger 是窗口算子的内部属性,每个窗口分配器(WindowAssigner)都会对应一个默认 的触发器;对于 Flink 内置的窗口类型,它们的触发器都已经做了实现。例如,所有事件时间 窗口,默认的触发器都是 EventTimeTrigger;类似还有 ProcessingTimeTrigger 和 CountTrigger。 所以一般情况下是不需要自定义触发器的,不过我们依然有必要了解它的原理。 Trigger 是一个抽象类,自定义时必须实现下面四个抽象方法:
- onElement():窗口中每到来一个元素,都会调用这个方法
- onEventTime():当注册的事件时间定时触发时,将调用这个方法
- onProcessingTime():当注册的处理时间定时器触发时,将调用这个方法
- clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。
这些参数都有都有一个触发器上下文(TriggerContext)对象,可以用来注册定时器回调(callback)。都有一个“触发器上下文”(TriggerContext)对象,可以用来注册定时器回调(callback)。这 里提到的“定时器”(Timer),其实就是我们设定的一个“闹钟”,代表未来某个时间点会执行 的事件。
上面的前三个方法返回类型都是TriggerResult,这是一个枚举类型(enum),其中定义了对窗口进行操作的四种类型
- CONTINUE(继续):什么都不做
- FIRE(触发):触发计算,输出结果
- PURGE(清除):清空窗口中的所有数据,销毁窗口
- FIRE_AND_PURGE(触发并清除):触发计算输出结果,并清除窗口
importcom.yingzi.chapter05.Source.ClickSource;importcom.yingzi.chapter05.Source.Event;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.api.common.state.ValueState;importorg.apache.flink.api.common.state.ValueStateDescriptor;importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;importorg.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importorg.apache.flink.streaming.api.windowing.triggers.Trigger;importorg.apache.flink.streaming.api.windowing.triggers.TriggerResult;importorg.apache.flink.streaming.api.windowing.windows.TimeWindow;importorg.apache.flink.util.Collector;publicclassTriggerExample{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(newClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps().withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event event,long l){return event.timestamp;}})).keyBy(r -> r.url).window(TumblingEventTimeWindows.of(Time.seconds(10))).trigger(newMyTrigger()).process(newWindowResult()).print();
env.execute();}publicstaticclassWindowResultextendsProcessWindowFunction<Event,UrlViewCount,String,TimeWindow>{@Overridepublicvoidprocess(String s,Context context,Iterable<Event> iterable,Collector<UrlViewCount> collector)throwsException{
collector.collect(newUrlViewCount(
s,// 获取迭代器中的元素个数
iterable.spliterator().getExactSizeIfKnown(),
context.window().getStart(),
context.window().getEnd()));}}publicstaticclassMyTriggerextendsTrigger<Event,TimeWindow>{@OverridepublicTriggerResultonElement(Event event,long l,TimeWindow timeWindow,TriggerContext triggerContext)throwsException{ValueState<Boolean> isFirstEvent = triggerContext.getPartitionedState(newValueStateDescriptor<Boolean>("first-event",Types.BOOLEAN));if(isFirstEvent.value()==null){for(long i = timeWindow.getStart(); i < timeWindow.getEnd(); i = i +1000L){
triggerContext.registerEventTimeTimer(i);}
isFirstEvent.update(true);}returnTriggerResult.CONTINUE;}@OverridepublicTriggerResultonEventTime(long l,TimeWindow timeWindow,TriggerContext triggerContext)throwsException{returnTriggerResult.FIRE;}@OverridepublicTriggerResultonProcessingTime(long l,TimeWindow timeWindow,TriggerContext triggerContext)throwsException{returnTriggerResult.CONTINUE;}@Overridepublicvoidclear(TimeWindow timeWindow,TriggerContext triggerContext)throwsException{ValueState<Boolean> isFirstEvent = triggerContext.getPartitionedState(newValueStateDescriptor<Boolean>("first-event",Types.BOOLEAN));
isFirstEvent.clear();}}}
2、移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑,实现evictor()方法,就可以传入一个自定义的移除器(Evictor),Evictor 是一个接口,不同的窗口类型都有各自预实现的移除器
stream.keyBy(...).window(...).evictor(newMyEvictor())
Evictor 接口定义了两个方法:
- evictBefore():定义执行窗口函数之前的移除数据操作
- evictAfter():定义执行窗口函数之后的数据操作
默认情况下,预实现的移除器都是在执行窗口函数(window fucntions)之前移除数据的
3、允许延迟(Allowed Lateness)
在事件时间语义下,窗口中可能会出现数据迟到的情况。这是因为在乱序流中,水位线 (watermark)并不一定能保证时间戳更早的所有数据不会再来。
Flink一个了一个特殊的接口,可以为窗口算子设置一个“运行的最大延迟”,也就是说我们可以设定允许延迟一段时间。
水位线 = 窗口结束时间 + 延迟时间
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1))).allowedLateness(Time.minutes(1))
4、将迟到的数据放入侧输出流
Flink 还提供了另外一种方式处理迟到数据。我们可以将未收入窗口的迟到数据,放入“侧 输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”, 这个流中单独放置那些错过了该上的车、本该被丢弃的数据
sideOutputLateData() 方法,传入一个输出标签,用来标记分治的迟到数据流
DataStream<Event> stream = env.addSource(...);OutputTag<Event> outputTag =newOutputTag<Event>("late"){};
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1))).sideOutputLateData(outputTag)
将迟到数据放入侧输出流之后,还应该可以将它提取出来。基于窗口处理完成之后的 DataStream,调用.getSideOutput()方法,传入对应的输出标签,就可以获取到迟到数据所在的流了
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1))).sideOutputLateData(outputTag).aggregate(newMyAggregateFunction())DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
窗口的生命周期
1、窗口的创建
窗口的类型和基本信息由窗口分配器(window assigners)指定,但窗口不会预先创建好,而是由数据驱动创建。当第一个应该属于这个窗口的数据元素到达时,就会创建对应的窗口
2、窗口计算的触发
除了窗口分配器,每个窗口还会有自己的窗口函数(window functions)和触发器(trigger)。 窗口函数可以分为增量聚合函数和全窗口函数,主要定义了窗口中计算的逻辑;而触发器则是指定调用窗口函数的条件
对于不同的窗口类型,触发计算的条件也会不同。例如,一个滚动事件时间窗口,应该在 水位线到达窗口结束时间的时候触发计算,属于“定点发车”;而一个计数窗口,会在窗口中 元素数量达到定义大小时触发计算,属于“人满就发车”。所以 Flink 预定义的窗口类型都有 对应内置的触发器
对于事件时间窗口而言,除去到达结束时间的“定点发车”,还有另一种情形。当我们设置了允许延迟,那么如果水位线超过了窗口结束时间、但还没有到达设定的最大延迟时间,这 期间内到达的迟到数据也会触发窗口计算
3、窗口的消耗
一般情况下,当时间达到了结束点,就会直接触发计算输出结果、进而清除状态销毁窗口。 这时窗口的销毁可以认为和触发计算是同一时刻。这里需要注意,Flink 中只对时间窗口 (TimeWindow)有销毁机制;由于计数窗口(CountWindow)是基于全局窗口(GlobalWindw) 实现的,而全局窗口不会清除状态,所以就不会被销毁。
在特殊的场景下,窗口的销毁和触发计算会有所不同。事件时间语义下,如果设置了允许延迟,那么在水位线到达窗口结束时间时,仍然不会销毁窗口;窗口真正被完全删除的时间点, 是窗口的结束时间加上用户指定的允许延迟时间
4、窗口API调用总结
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HO3LnjgW-1650124028000)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220416231558050.png)]](https://img-blog.csdnimg.cn/db0a2f362a2e4634873b599e5df82f21.png)
Window API 首先按照时候按键分区分成两类。keyBy 之后的 KeyedStream,可以调 用.window()方法声明按键分区窗口(Keyed Windows);而如果不做 keyBy,DataStream 也可 以直接调用.windowAll()声明非按键分区窗口
接下来首先是通过.window()/.windowAll()方法定义窗口分配器,得到 WindowedStream; 然 后 通 过 各 种 转 换 方 法 ( reduce/aggregate/apply/process ) 给 出 窗 口 函 数 (ReduceFunction/AggregateFunction/ProcessWindowFunction),定义窗口的具体计算处理逻辑, 转换之后重新得到 DataStream。这两者必不可少,是窗口算子(WindowOperator)最重要的组成部分
此外,在这两者之间,还可以基于 WindowedStream 调用.trigger()自定义触发器、调 用.evictor()定义移除器、调用.allowedLateness()指定允许延迟时间、调用.sideOutputLateData() 将迟到数据写入侧输出流,这些都是可选的 API,一般不需要实现。而如果定义了侧输出流, 可以基于窗口聚合之后的 DataStream 调用.getSideOutput()获取侧输出流
版权归原作者 未来影子 所有, 如有侵权,请联系我们删除。