
实验报告
①.spark集群基础
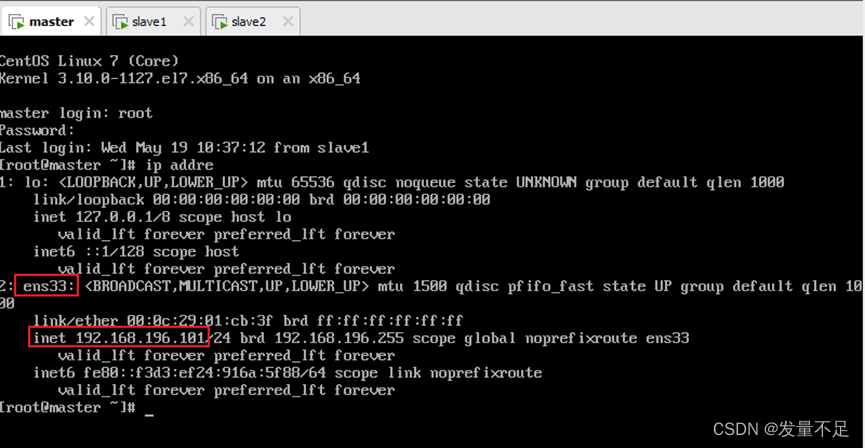
查看自己三个节点环境的ip地址:ip addre
Master:
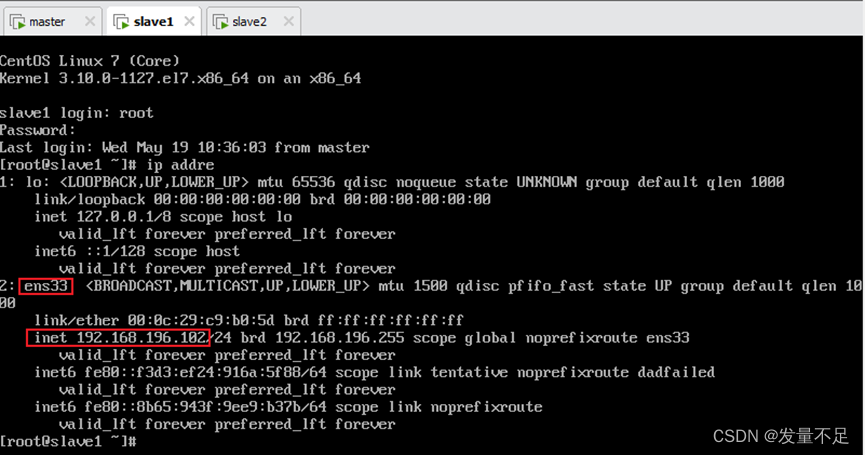
Slave1:
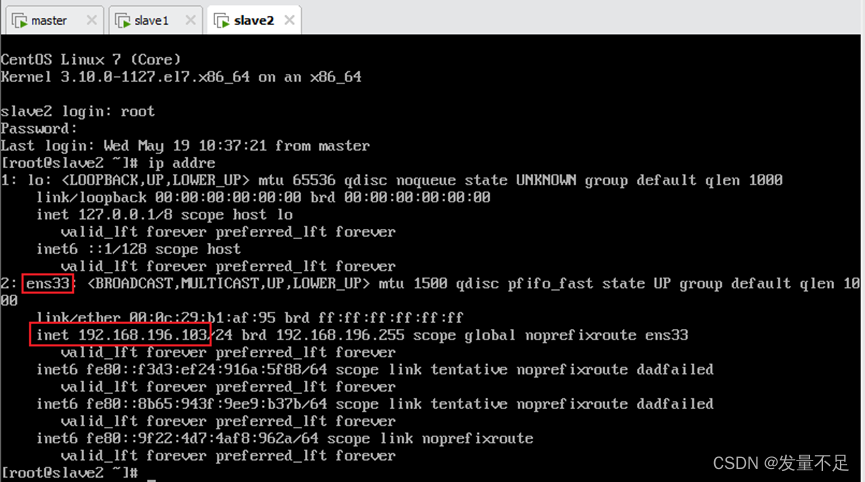
Slave2:
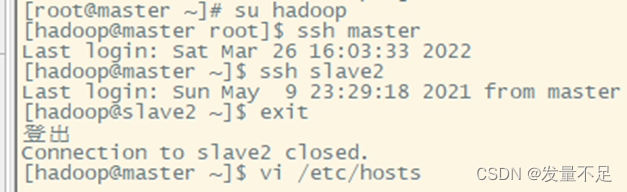
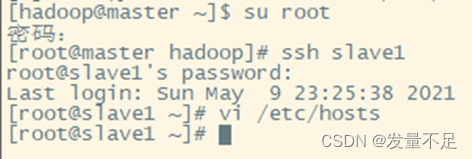
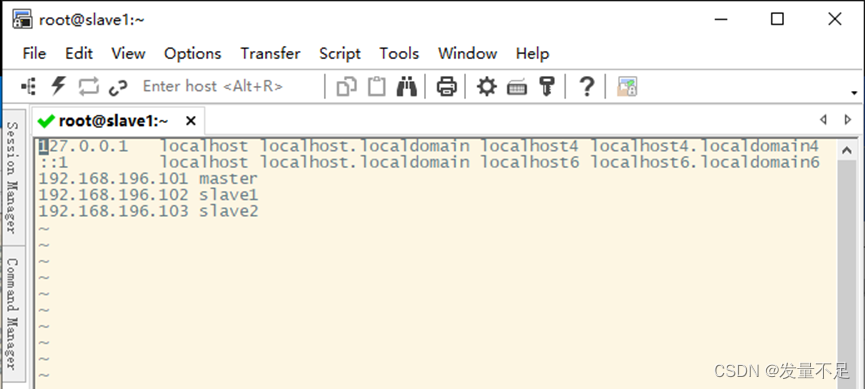
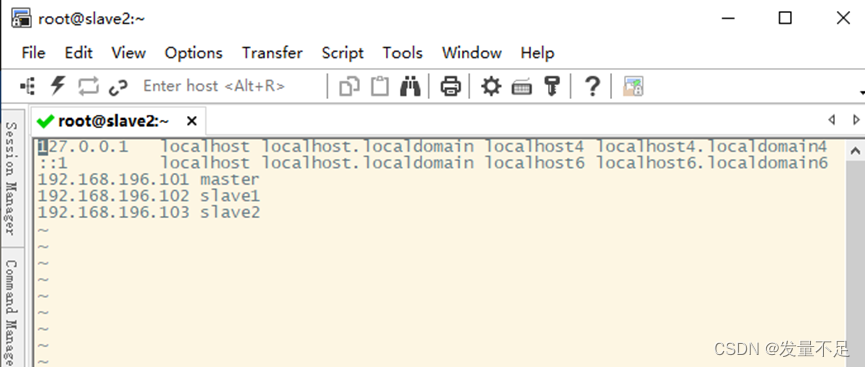
切换hadoop用户查看master能否切换另外两台slave然后配置另外两台可以自由切换
配置成刚才三个节点的ip地址
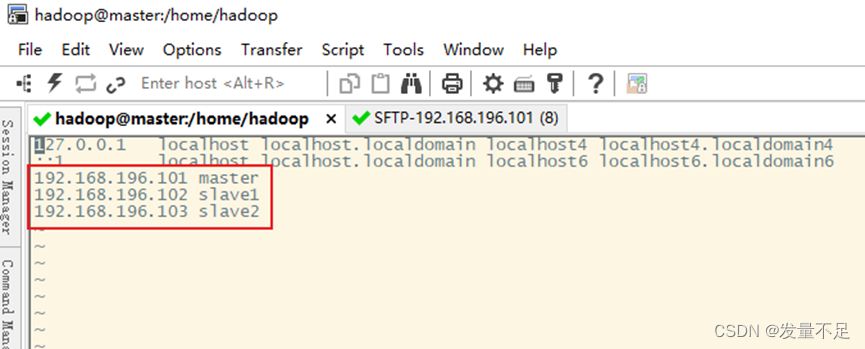
配置另外两个节点的免密快速访问(修改配置需要管理员root权限才能修改)
②.Spark集群安装部署
1.下载Spark安装包
Apache Spark官网httpd://spark.apache.org/downloads.html下载使用。
2.解压Spark安装包
在CRT页面Alt+P打开文件传输窗口
cd /opt/software/
ls
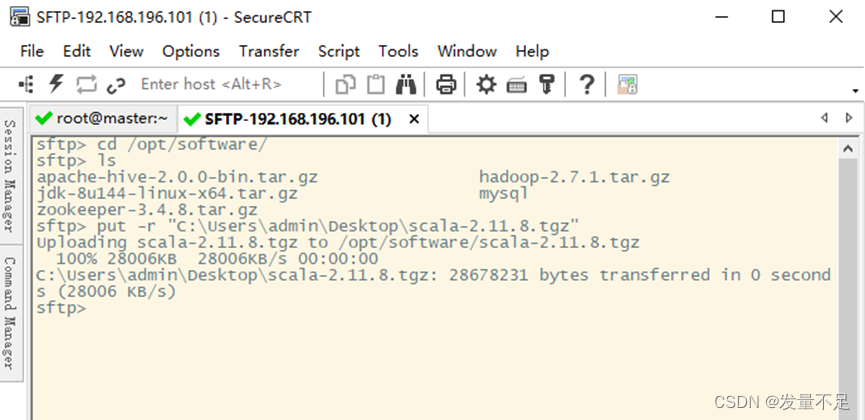
回到CRT页面切换hadoop用户
su Hadoop
cd /opt/software/
查看是否传输成功
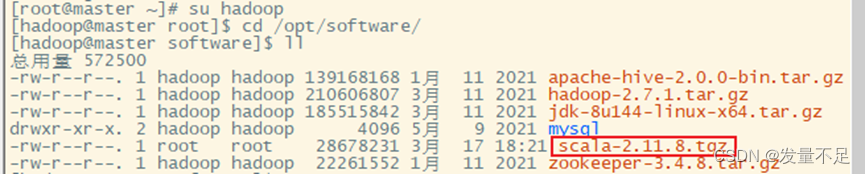
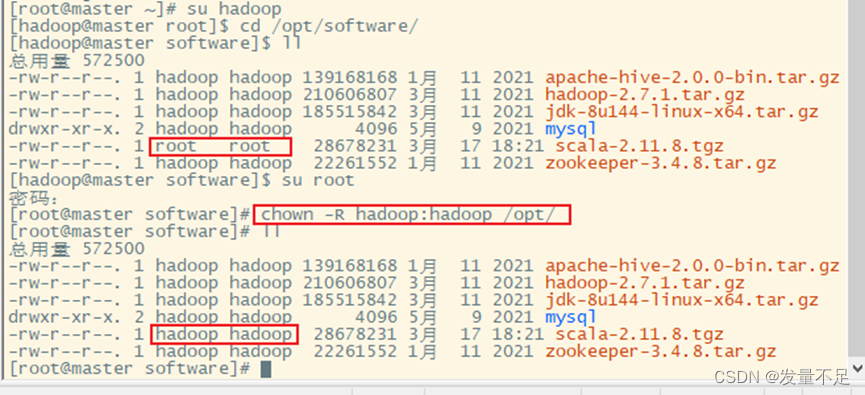
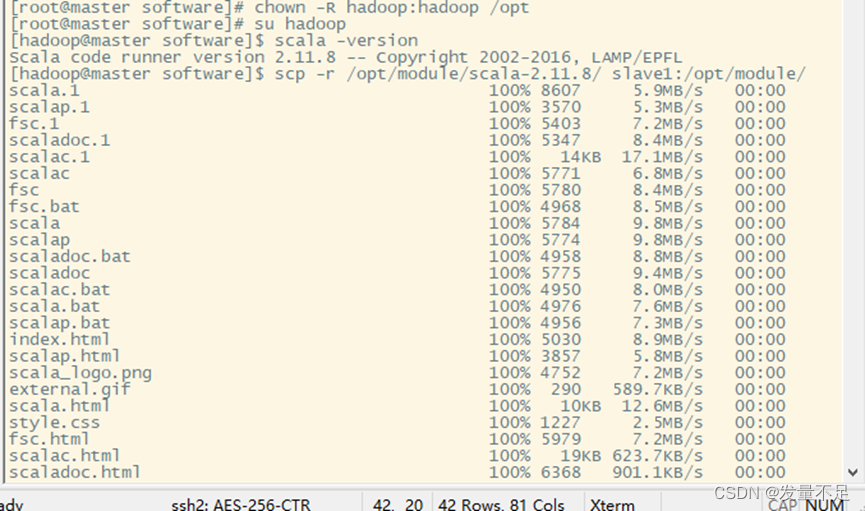
切换root修改scala的文件权限给hadoop
su Hadoop
cd /opt/software
su root
chown -R hadoop:hadoop /opt/
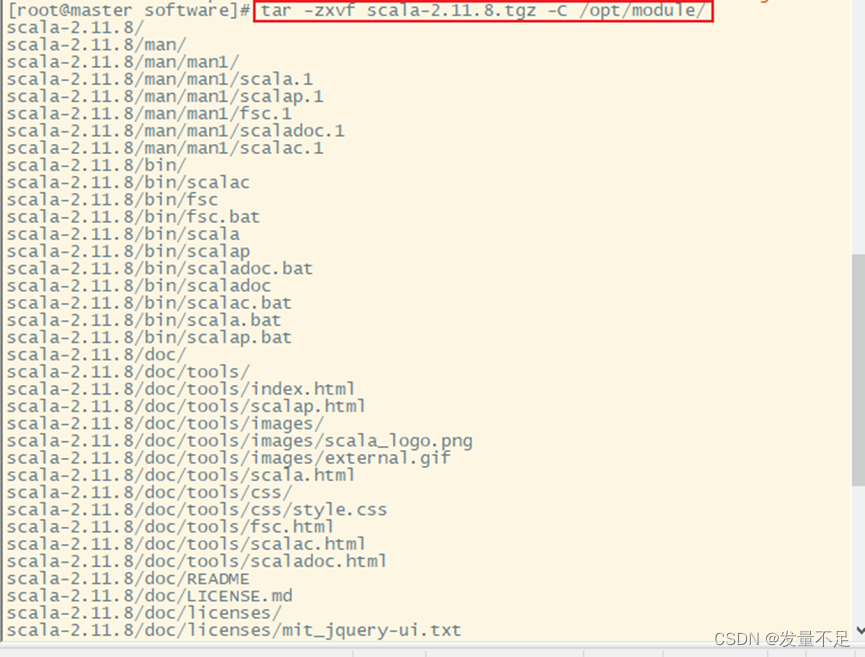
修改完成后解压scala
tar -zxvf scala-2.11.8.tgz -C /opt/module/
清屏
3.修改配置文件
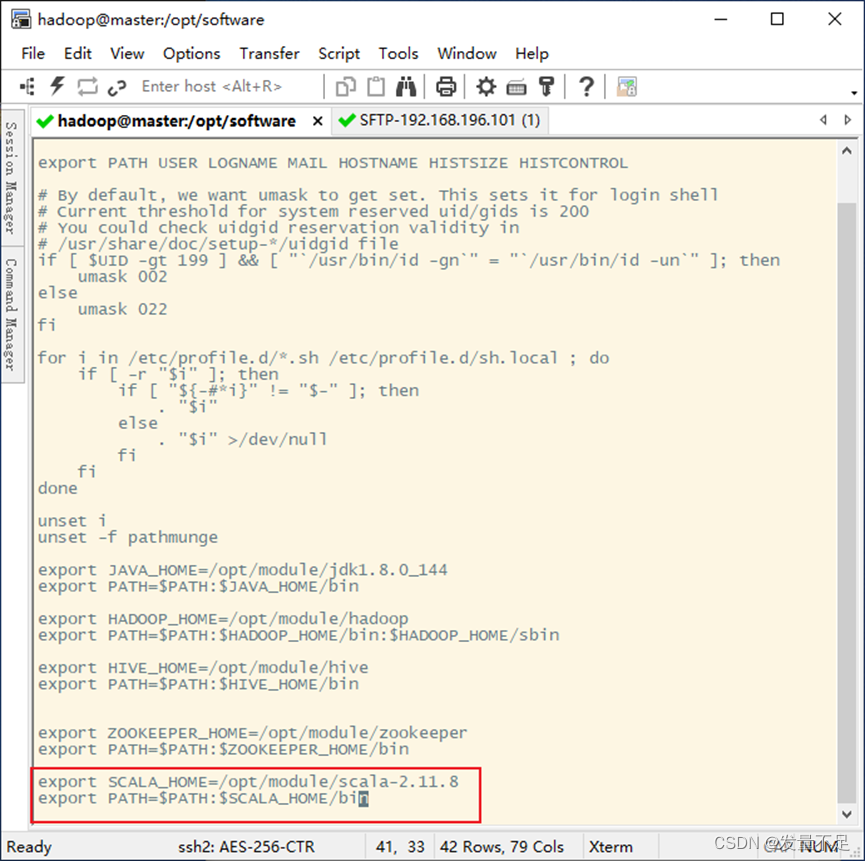
vi /etc/profile
添加如下配置:
export SCALA_HOME=/opt/module/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
配置完后让配置生效
然后检查版本

分发文件:修改完1配置文件后将master目录分发至slave1和slave2两个节点
scp -r /opt/module/scala-2.11.8/ slave1:/opt/module/
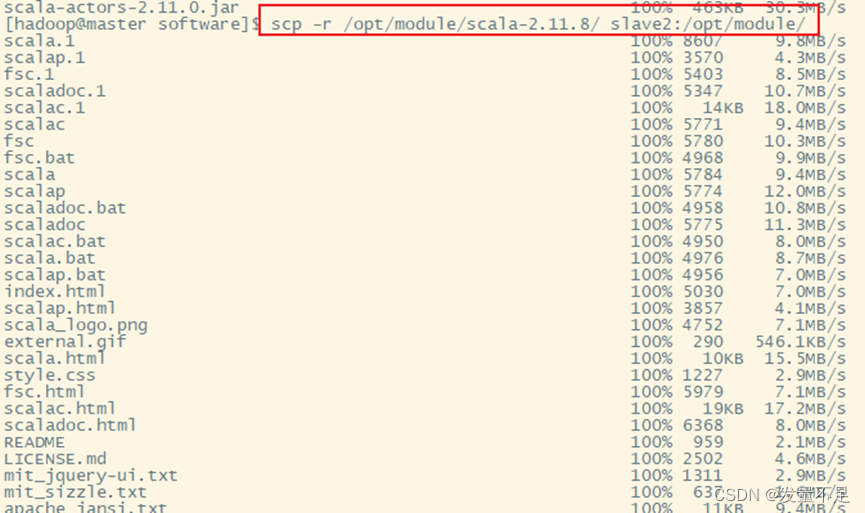
scp -r /opt/module/scala-2.11.8/ slave2:/opt/module/
切换slave1用户使用管理员身份
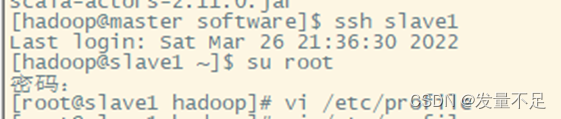
ssh slave1
su root
vi /etc/profile
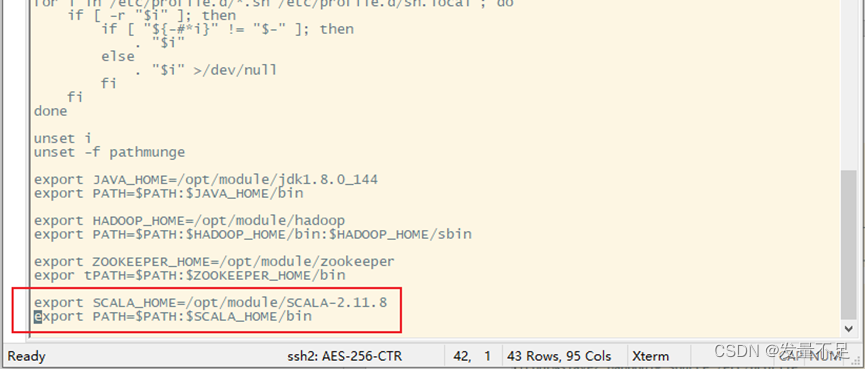
添加环境配置:
export SCALA_HOME=/opt/module/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
:wq保存
查看是否成功
scala -version
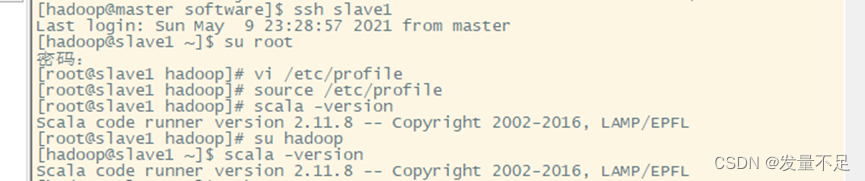
切换slave2用户使用管理员身份
ssh slave2
su root
vi /etc/profile
添加环境配置:
export SCALA_HOME=/opt/module/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
:wq保存
查看是否成功
scala -version


版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。