
文章目录
一、简介
1.1、基本介绍
Apache HBase 是以hdfs为数据存储的,
一种分布式、可扩展的noSql数据库。
是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。
数据行具有可排序的键和任意数量的列。
该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
最终理解HBase数据模型的关键在于
稀疏、分布式、多维、排序
的映射。其中映射map指非关系型数据库的
key-value结构
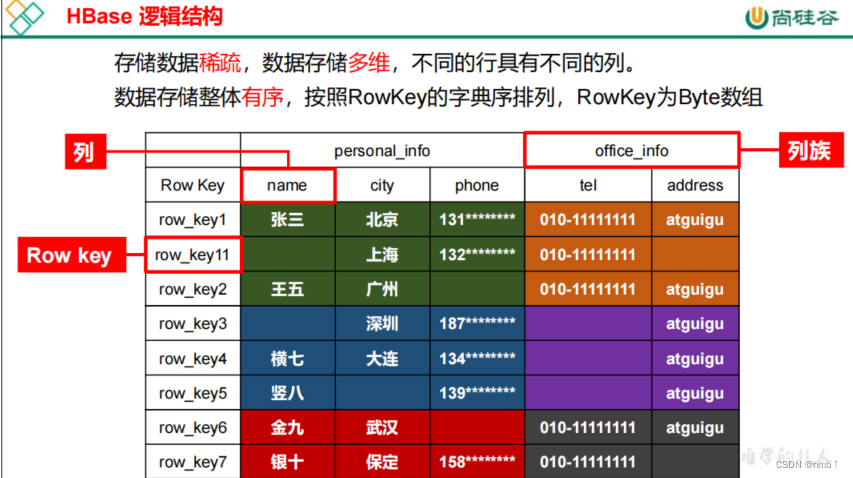
1.2、HBase逻辑结构
HBase可以用于存储多种结构的数据,以JSON为例,存储的数据原貌为:
{"row_key1":{"personal_info":{"name":"zhangsan","city":"北京","phone":"131********"},"office_info":{"tel":"010-1111111","address":"atguigu"}},"row_key11":{"personal_info":{"city":"上海","phone":"132********"},"office_info":{"tel":"010-1111111"}},"row_key2":{......}
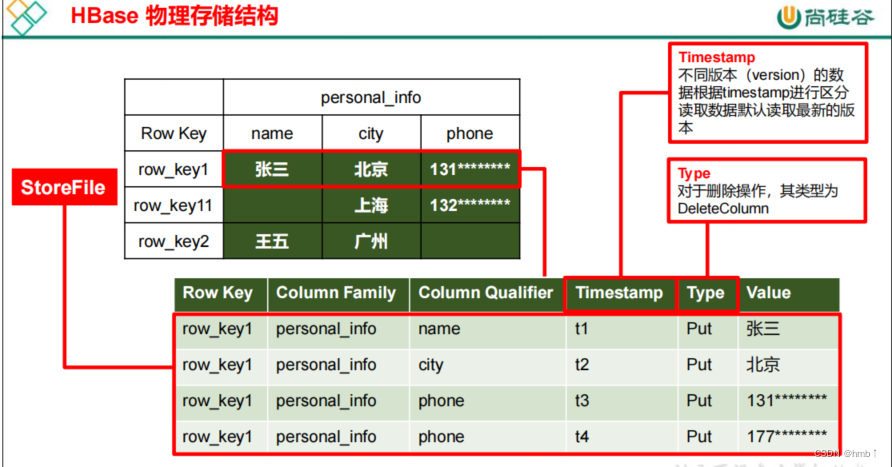
1.3、HBase物理存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不存储。就是上面的空单元格没有存储。
1.4、数据模型
1、Name Space
命名空间,类似于关系型数据库的 database 概念,每个命名空间下有多个表。HBase 两
个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default表是用户默认使用的命名空间。
2、Table
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需
要声明具体的列。因为数据存储时稀疏的,所有往 HBase 写入数据时,字段可以动态、按需
指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
3、Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey
的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重
要。
4、Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限
定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5、Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,
其值为写入 HBase 的时间
6、Cell
由{rowkey, column Family:column Qualifier, timestamp} 唯一确定的单元。cell 中的数
据全部是字节码形式存贮。
1.5、HBase 基础架构
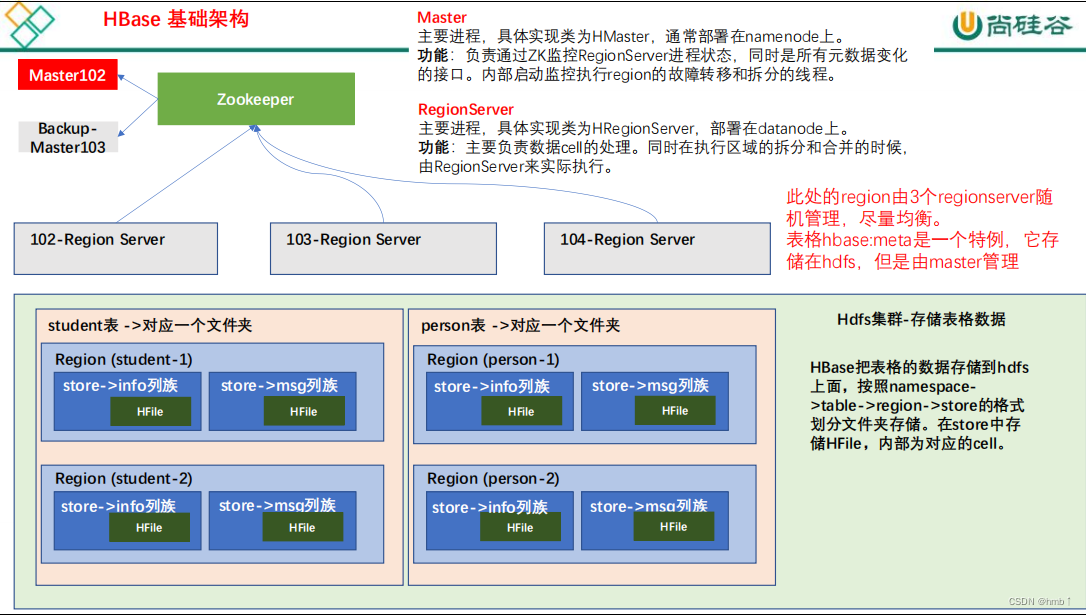
架构角色:
1、Master
实现类为 HMaster,负责监控集群中所有的 RegionServer 实例。主要作用如下:
- (1)管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行
- (2)监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
通过启动多个后台线程监控实现上述功能:
①LoadBalancer 负载均衡器
周期性监控 region 分布在 regionServer 上面是否均衡,由参数 hbase.balancer.period 控
制周期时间,默认 5 分钟。
②CatalogJanitor 元数据管理器
定期检查和清理 hbase:meta 中的数据。meta 表内容在进阶中介绍。
③MasterProcWAL master 预写日志处理器
把 master 需要执行的任务记录到预写日志 WAL 中,如果 master 宕机,让 backupMaster读取日志继续干
2、Region Server
Region Server 实现类为 HRegionServer,主要作用如下:
- (1)负责数据 cell 的处理,例如写入数据 put,查询数据 get 等
- (2)拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
3、Zookeeper
- HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储有 meta 表的位置信息。
- HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper的压力
4、HDFS
- HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
二、安装部署
docker 安装HBase
$ docker pull harisekhon/hbase:latest
docker run -d-h docker-hbase \-p2181:2181 \-p8080:8080 \-p8085:8085 \-p9090:9090 \-p9000:9000 \-p9095:9095 \-p16000:16000 \-p16010:16010 \-p16201:16201 \-p16301:16301 \-p16020:16020\-v /home/hbase-data/data:/hbase-data/data \--name hbase \
harisekhon/hbase
访问HBase WebUI界面 :
http://localhost:16010
三、HBase Shell 操作
3.1、进入 HBase 客户端命令行
先进入dockers容器内
进入shell命令模式
$ hbase shell
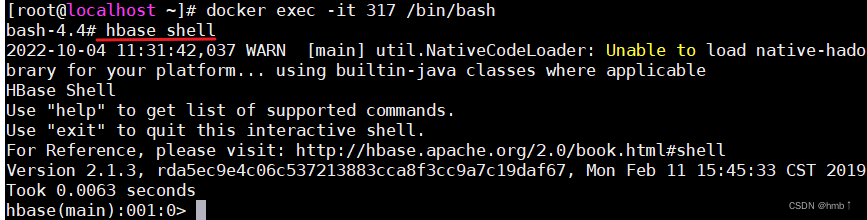
$ help
能够展示 HBase 中所有能使用的命令,主要使用的命令有 namespace 命令空间相关,DDL 创建修改表格,DML 写入读取数据。
3.2、Name Space 相关命令
1)、使用特定的 help 语法能够查看命令如何使用。
$ help'create_namespace'
2)、创建命名空间 bigdata
$ create_namespace 'bigdata'
3)、查看所有的命名空间
$ list_namespace
3.3、DDL 相关命令
1)、创建表
在 bigdata 命名空间中创建表格 student,两个列族。info 列族数据维护的版本数为 5 个,
msg不写默认版本数为 1
$ create 'bigdata:student', {NAME =>'info', VERSIONS =>5}, {NAME =>'msg'}
如果创建表格只有一个列族,没有列族属性,可以简写。
如果不写命名空间,使用默认的命名空间 default。
$ create 'student1','info'
2)、查看表
查看所有的表名
$ list
查看一个表的详情
$ describe 'student1'
3)、修改表
表名创建时写的所有和列族相关的信息,都可以后续通过 alter 修改,包括增加删除列
族。
(1)增加列族和修改信息都使用覆盖的方法
$ alter 'student1', {NAME =>'f1', VERSIONS =>3}
(2)删除信息使用特殊的语法
$ alter 'student1', NAME =>'f1', METHOD =>'delete'
$ alter 'student1', 'delete'=>'f1'
4)、删除表
shell 中删除表格,需要先将表格状态设置为不可用。
$ disable 'student1'
$ drop 'student1'
3.4、DML 相关命令
1)、写入数据
在 HBase 中如果想要写入数据,只能添加结构中最底层的 cell。可以手动写入时间戳指
定 cell 的版本,推荐不写默认使用当前的系统时间。
// 参数1:表面 参数2:rowKey 参数3:列名 参数4:值
$ put 'bigdata:student','1001','info:name','zhangsan'
$ put 'bigdata:student','1001','info:name','lisi'
$ put 'bigdata:student','1001','info:age','18'
如果重复写入相同 rowKey,相同列的数据,会写入多个版本进行覆盖。
2)、读取数据
get
最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行 cell。
$ get 'bigdata:student','1001' // 根据rowKey查询整条数据
$ get 'bigdata:student','1001' , {COLUMN =>'info:name'} // 只查这个列
也可以修改读取 cell 的版本数,默认读取一个。最多能够读取当前列族设置的维护版本
数。
$ get 'bigdata:student','1001' , {COLUMN =>'info:name', VERSIONS =>6}
scan
是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用 startRow 和
stopRow 来控制读取的数据,默认范围左闭右开。
scan 'bigdata:student',{STARTROW =>'1001',STOPROW =>'1002'}
3)、删除数据
delete 表示删除一个版本的数据,即为 1 个 cell,不填写版本默认删除最新的一个版本。
$ delete 'bigdata:student','1001','info:name'
deleteall 表示删除所有版本的数据,即为当前行当前列的多个 cell。
(执行命令会标记 数据为要删除,不会直接将数据彻底删除,删除数据只在特定时期清理磁盘时进行)
$ deleteall 'bigdata:student','1001','info:name'
四、HBase API
依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.13</version><exclusions><exclusion><artifactId>slf4j-log4j12</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency>
yml添加hbase信息
hbase:zookeeper:quorum: localhost
property:clientPort:2181zookeeper:znode:parent: /hbase
添加HBase配置信息类
packageorg.jeecg.common.util.hbase;importorg.apache.hadoop.hbase.HBaseConfiguration;importorg.springframework.beans.factory.annotation.Value;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;/**
* HBase相关配置
*/@ConfigurationpublicclassHBaseConfig{@Value("${hbase.zookeeper.quorum}")privateString zookeeperQuorum;@Value("${hbase.zookeeper.property.clientPort}")privateString clientPort;@Value("${zookeeper.znode.parent}")privateString znodeParent;@BeanpublicHBaseServicegetHbaseService(){org.apache.hadoop.conf.Configuration conf =HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", zookeeperQuorum);
conf.set("hbase.zookeeper.property.clientPort", clientPort);
conf.set("zookeeper.znode.parent", znodeParent);returnnewHBaseService(conf);}}
封装HBase工具类
packageorg.jeecg.common.util.hbase;importlombok.extern.slf4j.Slf4j;importorg.apache.commons.lang.StringUtils;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.hbase.Cell;importorg.apache.hadoop.hbase.CompareOperator;importorg.apache.hadoop.hbase.TableName;importorg.apache.hadoop.hbase.client.*;importorg.apache.hadoop.hbase.filter.*;importorg.apache.hadoop.hbase.util.Bytes;importjava.io.IOException;importjava.math.BigInteger;importjava.text.MessageFormat;importjava.util.*;@Slf4jpublicclassHBaseService{/**
* 声明静态配置
*/privateConfiguration conf =null;privateConnection connection =null;publicHBaseService(Configuration conf){this.conf = conf;try{
connection =ConnectionFactory.createConnection(conf);}catch(IOException e){
log.error("获取HBase连接失败");}}/**
* 创建表
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param columnFamily 列族名
* @return void
*/publicbooleancreatTable(String tableName,List<String> columnFamily){Admin admin =null;try{
admin = connection.getAdmin();List<ColumnFamilyDescriptor> familyDescriptors =newArrayList<>(columnFamily.size());
columnFamily.forEach(cf ->{
familyDescriptors.add(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf)).build());});TableDescriptor tableDescriptor =TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)).setColumnFamilies(familyDescriptors).build();if(admin.tableExists(TableName.valueOf(tableName))){
log.debug("table Exists!");}else{
admin.createTable(tableDescriptor);
log.debug("create table Success!");}}catch(IOException e){
log.error(MessageFormat.format("创建表{0}失败",tableName),e);returnfalse;}finally{close(admin,null,null);}returntrue;}/**
* 预分区创建表
* @param tableName 表名
* @param columnFamily 列族名的集合
* @param splitKeys 预分期region
* @return 是否创建成功
*/publicbooleancreateTableBySplitKeys(String tableName,List<String> columnFamily,byte[][] splitKeys){Admin admin =null;try{if(StringUtils.isBlank(tableName)|| columnFamily ==null|| columnFamily.size()==0){
log.error("===Parameters tableName|columnFamily should not be null,Please check!===");returnfalse;}
admin = connection.getAdmin();if(admin.tableExists(TableName.valueOf(tableName))){returntrue;}else{List<ColumnFamilyDescriptor> familyDescriptors =newArrayList<>(columnFamily.size());
columnFamily.forEach(cf ->{
familyDescriptors.add(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf)).build());});TableDescriptor tableDescriptor =TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)).setColumnFamilies(familyDescriptors).build();//指定splitkeys
admin.createTable(tableDescriptor,splitKeys);
log.info("===Create Table "+ tableName
+" Success!columnFamily:"+ columnFamily.toString()+"===");}}catch(IOException e){
log.error("",e);returnfalse;}finally{close(admin,null,null);}returntrue;}/**
* 自定义获取分区splitKeys
*/publicbyte[][]getSplitKeys(String[] keys){if(keys==null){//默认为10个分区
keys =newString[]{"1|","2|","3|","4|","5|","6|","7|","8|","9|"};}byte[][] splitKeys =newbyte[keys.length][];//升序排序TreeSet<byte[]> rows =newTreeSet<byte[]>(Bytes.BYTES_COMPARATOR);for(String key : keys){
rows.add(Bytes.toBytes(key));}Iterator<byte[]> rowKeyIter = rows.iterator();int i=0;while(rowKeyIter.hasNext()){byte[] tempRow = rowKeyIter.next();
rowKeyIter.remove();
splitKeys[i]= tempRow;
i++;}return splitKeys;}/**
* 按startKey和endKey,分区数获取分区
*/publicstaticbyte[][]getHexSplits(String startKey,String endKey,int numRegions){byte[][] splits =newbyte[numRegions-1][];BigInteger lowestKey =newBigInteger(startKey,16);BigInteger highestKey =newBigInteger(endKey,16);BigInteger range = highestKey.subtract(lowestKey);BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);for(int i=0; i < numRegions-1;i++){BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));byte[] b =String.format("%016x", key).getBytes();
splits[i]= b;}return splits;}/**
* 获取table
* @param tableName 表名
* @return Table
* @throws IOException IOException
*/privateTablegetTable(String tableName)throwsIOException{return connection.getTable(TableName.valueOf(tableName));}/**
* 查询库中所有表的表名
*/publicList<String>getAllTableNames(){List<String> result =newArrayList<>();Admin admin =null;try{
admin = connection.getAdmin();TableName[] tableNames = admin.listTableNames();for(TableName tableName : tableNames){
result.add(tableName.getNameAsString());}}catch(IOException e){
log.error("获取所有表的表名失败",e);}finally{close(admin,null,null);}return result;}/**
* 遍历查询指定表中的所有数据
* @author
* @date 2018/7/3 18:21
* @since 1.0.0
* @param tableName 表名
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/publicMap<String,Map<String,String>>getResultScanner(String tableName){Scan scan =newScan();returnthis.queryData(tableName,scan);}/**
* 根据startRowKey和stopRowKey遍历查询指定表中的所有数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param startRowKey 起始rowKey
* @param stopRowKey 结束rowKey
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/publicMap<String,Map<String,String>>getResultScanner(String tableName,String startRowKey,String stopRowKey){Scan scan =newScan();if(StringUtils.isNotBlank(startRowKey)&&StringUtils.isNotBlank(stopRowKey)){
scan.withStartRow(Bytes.toBytes(startRowKey));
scan.withStopRow(Bytes.toBytes(stopRowKey));}returnthis.queryData(tableName,scan);}/**
* 通过行前缀过滤器查询数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param prefix 以prefix开始的行键
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/publicMap<String,Map<String,String>>getResultScannerPrefixFilter(String tableName,String prefix){Scan scan =newScan();if(StringUtils.isNotBlank(prefix)){Filter filter =newPrefixFilter(Bytes.toBytes(prefix));
scan.setFilter(filter);}returnthis.queryData(tableName,scan);}/**
* 通过列前缀过滤器查询数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param prefix 以prefix开始的列名
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/publicMap<String,Map<String,String>>getResultScannerColumnPrefixFilter(String tableName,String prefix){Scan scan =newScan();if(StringUtils.isNotBlank(prefix)){Filter filter =newColumnPrefixFilter(Bytes.toBytes(prefix));
scan.setFilter(filter);}returnthis.queryData(tableName,scan);}/**
* 查询行键中包含特定字符的数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param keyword 包含指定关键词的行键
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/publicMap<String,Map<String,String>>getResultScannerRowFilter(String tableName,String keyword){Scan scan =newScan();if(StringUtils.isNotBlank(keyword)){Filter filter =newRowFilter(CompareOperator.GREATER_OR_EQUAL,newSubstringComparator(keyword));
scan.setFilter(filter);}returnthis.queryData(tableName,scan);}/**
* 查询列名中包含特定字符的数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param keyword 包含指定关键词的列名
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/publicMap<String,Map<String,String>>getResultScannerQualifierFilter(String tableName,String keyword){Scan scan =newScan();if(StringUtils.isNotBlank(keyword)){Filter filter =newQualifierFilter(CompareOperator.GREATER_OR_EQUAL,newSubstringComparator(keyword));
scan.setFilter(filter);}returnthis.queryData(tableName,scan);}/**
* 通过表名以及过滤条件查询数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param scan 过滤条件
* @return java.util.Map<java.lang.String,java.util.Map<java.lang.String,java.lang.String>>
*/privateMap<String,Map<String,String>>queryData(String tableName,Scan scan){//<rowKey,对应的行数据>Map<String,Map<String,String>> result =newHashMap<>();ResultScanner rs =null;// 获取表Table table=null;try{
table =getTable(tableName);
rs = table.getScanner(scan);for(Result r : rs){//每一行数据Map<String,String> columnMap =newHashMap<>();String rowKey =null;for(Cell cell : r.listCells()){if(rowKey ==null){
rowKey =Bytes.toString(cell.getRowArray(),cell.getRowOffset(),cell.getRowLength());}
columnMap.put(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()),Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}if(rowKey !=null){
result.put(rowKey,columnMap);}}}catch(IOException e){
log.error(MessageFormat.format("遍历查询指定表中的所有数据失败,tableName:{0}",tableName),e);}finally{close(null,rs,table);}return result;}/**
* 根据tableName和rowKey精确查询一行的数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey 行键
* @return java.util.Map<java.lang.String,java.lang.String> 返回一行的数据
*/publicMap<String,String>getRowData(String tableName,String rowKey){//返回的键值对Map<String,String> result =newHashMap<>();Get get =newGet(Bytes.toBytes(rowKey));// 获取表Table table=null;try{
table =getTable(tableName);Result hTableResult = table.get(get);if(hTableResult !=null&&!hTableResult.isEmpty()){for(Cell cell : hTableResult.listCells()){// System.out.println("family:" + Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength()));// System.out.println("qualifier:" + Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));// System.out.println("value:" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));// System.out.println("Timestamp:" + cell.getTimestamp());// System.out.println("-------------------------------------------");
result.put(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()),Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}}}catch(IOException e){
log.error(MessageFormat.format("查询一行的数据失败,tableName:{0},rowKey:{1}",tableName,rowKey),e);}finally{close(null,null,table);}return result;}/**
* 根据tableName、rowKey、familyName、column查询指定单元格的数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey rowKey
* @param familyName 列族名
* @param columnName 列名
* @return java.lang.String
*/publicStringgetColumnValue(String tableName,String rowKey,String familyName,String columnName){String str =null;Get get =newGet(Bytes.toBytes(rowKey));// 获取表Table table=null;try{
table =getTable(tableName);Result result = table.get(get);if(result !=null&&!result.isEmpty()){Cell cell = result.getColumnLatestCell(Bytes.toBytes(familyName),Bytes.toBytes(columnName));if(cell !=null){
str =Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());}}}catch(IOException e){
log.error(MessageFormat.format("查询指定单元格的数据失败,tableName:{0},rowKey:{1},familyName:{2},columnName:{3}",tableName,rowKey,familyName,columnName),e);}finally{close(null,null,table);}return str;}/**
* 根据tableName、rowKey、familyName、column查询指定单元格多个版本的数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey rowKey
* @param familyName 列族名
* @param columnName 列名
* @param versions 需要查询的版本数
* @return java.util.List<java.lang.String>
*/publicList<String>getColumnValuesByVersion(String tableName,String rowKey,String familyName,String columnName,int versions){//返回数据List<String> result =newArrayList<>(versions);// 获取表Table table=null;try{
table =getTable(tableName);Get get =newGet(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(familyName),Bytes.toBytes(columnName));//读取多少个版本
get.readVersions(versions);Result hTableResult = table.get(get);if(hTableResult !=null&&!hTableResult.isEmpty()){for(Cell cell : hTableResult.listCells()){
result.add(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}}}catch(IOException e){
log.error(MessageFormat.format("查询指定单元格多个版本的数据失败,tableName:{0},rowKey:{1},familyName:{2},columnName:{3}",tableName,rowKey,familyName,columnName),e);}finally{close(null,null,table);}return result;}/**
* 为表添加 or 更新数据
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey rowKey
* @param familyName 列族名
* @param columns 列名数组
* @param values 列值得数组
*/publicvoidputData(String tableName,String rowKey,String familyName,String[] columns,String[] values){// 获取表Table table=null;try{
table=getTable(tableName);putData(table,rowKey,tableName,familyName,columns,values);}catch(Exception e){
log.error(MessageFormat.format("为表添加 or 更新数据失败,tableName:{0},rowKey:{1},familyName:{2}",tableName,rowKey,familyName),e);}finally{close(null,null,table);}}/**
* 为表添加 or 更新数据
* @author
* @date
* @since 1.0.0
* @param table Table
* @param rowKey rowKey
* @param tableName 表名
* @param familyName 列族名
* @param columns 列名数组
* @param values 列值得数组
*/privatevoidputData(Table table,String rowKey,String tableName,String familyName,String[] columns,String[] values){try{//设置rowkeyPut put =newPut(Bytes.toBytes(rowKey));if(columns !=null&& values !=null&& columns.length == values.length){for(int i=0;i<columns.length;i++){if(columns[i]!=null&& values[i]!=null){
put.addColumn(Bytes.toBytes(familyName),Bytes.toBytes(columns[i]),Bytes.toBytes(values[i]));}else{thrownewNullPointerException(MessageFormat.format("列名和列数据都不能为空,column:{0},value:{1}",columns[i],values[i]));}}}
table.put(put);
log.debug("putData add or update data Success,rowKey:"+ rowKey);
table.close();}catch(Exception e){
log.error(MessageFormat.format("为表添加 or 更新数据失败,tableName:{0},rowKey:{1},familyName:{2}",tableName,rowKey,familyName),e);}}/**
* 为表的某个单元格赋值
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey rowKey
* @param familyName 列族名
* @param column1 列名
* @param value1 列值
*/publicvoidsetColumnValue(String tableName,String rowKey,String familyName,String column1,String value1){Table table=null;try{// 获取表
table=getTable(tableName);// 设置rowKeyPut put =newPut(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(familyName),Bytes.toBytes(column1),Bytes.toBytes(value1));
table.put(put);
log.debug("add data Success!");}catch(IOException e){
log.error(MessageFormat.format("为表的某个单元格赋值失败,tableName:{0},rowKey:{1},familyName:{2},column:{3}",tableName,rowKey,familyName,column1),e);}finally{close(null,null,table);}}/**
* 删除指定的单元格
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey rowKey
* @param familyName 列族名
* @param columnName 列名
* @return boolean
*/publicbooleandeleteColumn(String tableName,String rowKey,String familyName,String columnName){Table table=null;Admin admin =null;try{
admin = connection.getAdmin();if(admin.tableExists(TableName.valueOf(tableName))){// 获取表
table=getTable(tableName);Delete delete =newDelete(Bytes.toBytes(rowKey));// 设置待删除的列
delete.addColumns(Bytes.toBytes(familyName),Bytes.toBytes(columnName));
table.delete(delete);
log.debug(MessageFormat.format("familyName({0}):columnName({1})is deleted!",familyName,columnName));}}catch(IOException e){
log.error(MessageFormat.format("删除指定的列失败,tableName:{0},rowKey:{1},familyName:{2},column:{3}",tableName,rowKey,familyName,columnName),e);returnfalse;}finally{close(admin,null,table);}returntrue;}/**
* 根据rowKey删除指定的行
* @author
* @date
* @since 1.0.0
* @param tableName 表名
* @param rowKey rowKey
* @return boolean
*/publicbooleandeleteRow(String tableName,String rowKey){Table table=null;Admin admin =null;try{
admin = connection.getAdmin();if(admin.tableExists(TableName.valueOf(tableName))){// 获取表
table=getTable(tableName);Delete delete =newDelete(Bytes.toBytes(rowKey));
table.delete(delete);
log.debug(MessageFormat.format("row({0}) is deleted!",rowKey));}}catch(IOException e){
log.error(MessageFormat.format("删除指定的行失败,tableName:{0},rowKey:{1}",tableName,rowKey),e);returnfalse;}finally{close(admin,null,table);}returntrue;}/**
* 根据columnFamily删除指定的列族
* @author
* @date 2018/7/4 13:26
* @since 1.0.0
* @param tableName 表名
* @param columnFamily 列族
* @return boolean
*/publicbooleandeleteColumnFamily(String tableName,String columnFamily){Admin admin =null;try{
admin = connection.getAdmin();if(admin.tableExists(TableName.valueOf(tableName))){
admin.deleteColumnFamily(TableName.valueOf(tableName),Bytes.toBytes(columnFamily));
log.debug(MessageFormat.format("familyName({0}) is deleted!",columnFamily));}}catch(IOException e){
log.error(MessageFormat.format("删除指定的列族失败,tableName:{0},columnFamily:{1}",tableName,columnFamily),e);returnfalse;}finally{close(admin,null,null);}returntrue;}/**
* 删除表
* @author
* @date
* @since 1.0.0
* @param tableName 表名
*/publicbooleandeleteTable(String tableName){Admin admin =null;try{
admin = connection.getAdmin();if(admin.tableExists(TableName.valueOf(tableName))){
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
log.debug(tableName +"is deleted!");}}catch(IOException e){
log.error(MessageFormat.format("删除指定的表失败,tableName:{0}",tableName),e);returnfalse;}finally{close(admin,null,null);}returntrue;}/**
* 关闭流
*/privatevoidclose(Admin admin,ResultScanner rs,Table table){if(admin !=null){try{
admin.close();}catch(IOException e){
log.error("关闭Admin失败",e);}}if(rs !=null){
rs.close();}if(table !=null){try{
table.close();}catch(IOException e){
log.error("关闭Table失败",e);}}}}
测试
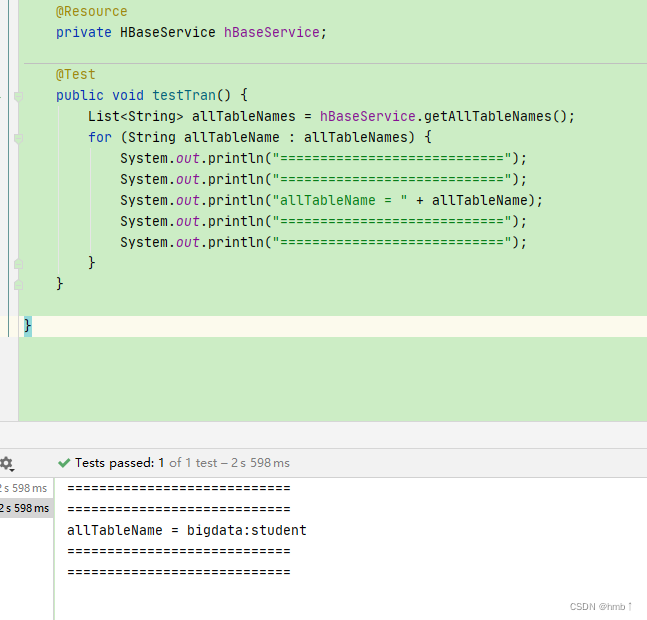
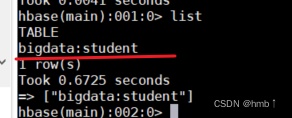
结果与shell终端查出来的一样,测试成功!!!
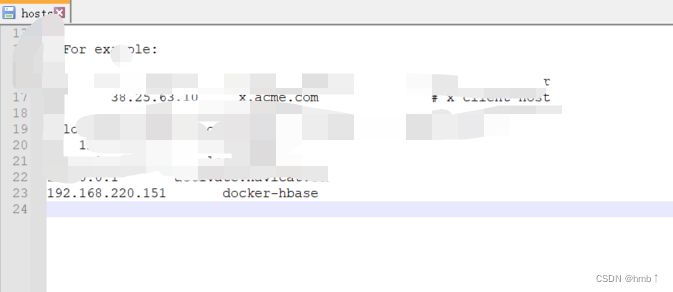
如果出现报错:Can not resolve docker-hbase, please check your network java.net.UnknownHostException: docker-hbase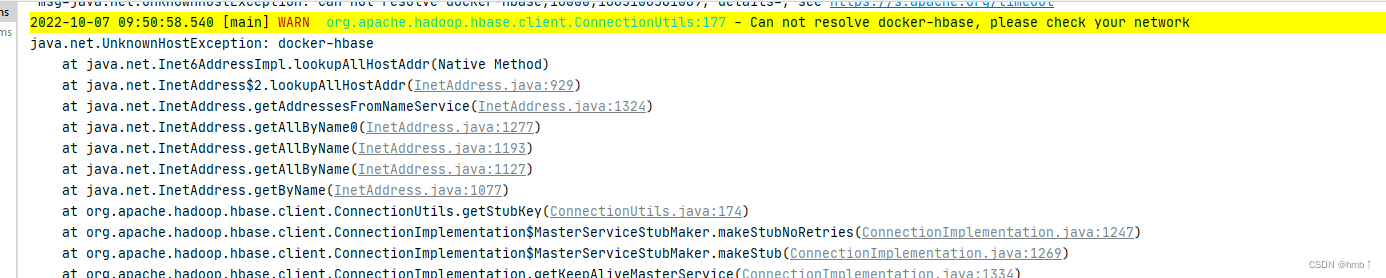
需添加hosts映射地址
五、整合Phoenix
5.1、Phoenix 简介
Phoenix 是 HBase 的开源 SQL 皮肤。可以使用标准 JDBC API 代替 HBase 客户端 API来创建表,插入数据和查询 HBase 数据。
就是像写sql一样,去插入查询HBase数据。
5.2、为什么使用 Phoenix
官方给的解释为:在 Client 和 HBase 之间放一个 Phoenix
中间层不会减慢速度
,因为用户编写的数据处理代码和 Phoenix 编写的没有区别(更不用说你写的垃圾的多),不仅如此Phoenix 对于用户输入的 SQL 同样
会有大量的优化手段
(就像 hive 自带 sql 优化器一样)。
5.3、下载安装
1、下载
下载链接: https://phoenix.apache.org/download.html
2、解压
$ tar-zxvf phoenix-hbase-2.1-5.1.2-bin.tar.gz
3、拷贝server包到hbase的lib文件下,注意是hbase文件夹下的lib。
$ dockercp phoenix-server-hbase-2.1-5.1.2.jar 容器Id:、/hbase/lib
4、进入hbase 的bin目录,重启hbase
$ stop-hbase.sh
$ start-hbase.sh
5、到phoenix的bin目录,启动
$ ./sqlline.py 192.168.220.152:2181 // 后面跟zookeeperIP端口
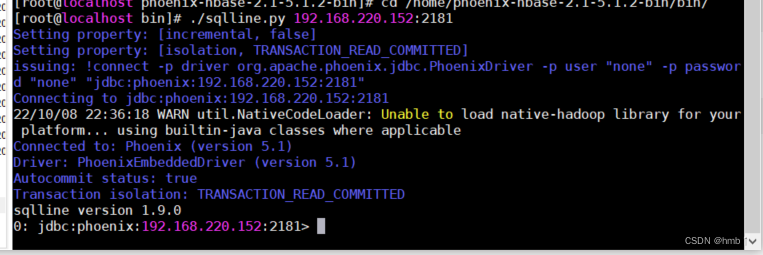
这时候就可以输入sql了,例如:
// 创建一张t_user 表CREATETABLEIFNOTEXISTS t_user (
name VARCHAR(20)NOTNULL,
age integer(3)NOTNULL,
address VARCHAR,
updatetime timestamp,
inserttime timestampCONSTRAINT pk_name_age PRIMARYKEY(name, age)// 联合主键);// 添加和更新数据都用 upsert, 没有 insert 和 update
UPSERT INTO t_user (name, age, address)values('test01',12,'上海市松江区');
UPSERT INTO t_user (name, age, address)values('test02',13,'上海市金山区');SELECT*FROM t_user;SELECTCOUNT(*)FROM t_user;
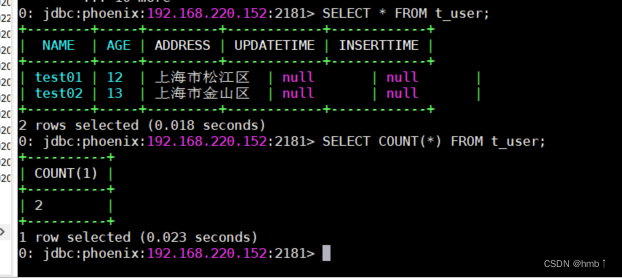
用hbase终端查看,表也在,测试成功!!!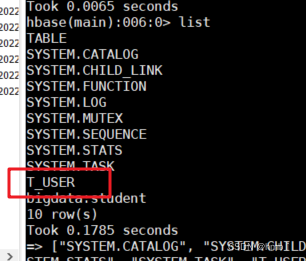
5.4、Phoenix Shell 相关命令
1)、显示所有表
$ !table 或 !tables
2)、创建表
直接指定单个列作为 RowKey
$ CREATETABLEIFNOTEXISTS student(
id VARCHARprimarykey,
name VARCHAR,
age BIGINT,
addr VARCHAR);
在 phoenix 中,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
指定多个列的联合作为 RowKey
$ CREATETABLEIFNOTEXISTS t_user (
name VARCHAR(20)NOTNULL,
age integer(3)NOTNULL,
address VARCHAR,
updatetime timestamp,
inserttime timestampCONSTRAINT pk_name_age PRIMARYKEY(name, age)// 联合主键);
注:Phoenix 中建表,会在 HBase 中创建一张对应的表。为了减少数据对磁盘空间的占用,Phoenix 默认会对 HBase 中的列名做编码处理。具体规则可参考官网链接:https://phoenix.apache.org/columnencoding.html,若不想对列名编码,可在建表语句末尾加上
COLUMN_ENCODED_BYTES = 0;
3)、插入数据
// 添加和更新数据都用 upsert, 没有 insert 和 update
UPSERT INTO t_user (name, age, address)values('test01',12,'上海市松江区');
4)、查询记录
SELECT*FROM t_user;SELECTCOUNT(*)FROM t_user;SELECT*FROM t_user where name='test01';
5)、删除记录
deletefrom t_user where name='test01';
6)、删除表
droptable t_user;
7)、退出命令行
!quit
关于 Phoenix 的语法建议使用时直接查看官网:
链接: https://phoenix.apache.org/language/index.html
5.5、表的映射
默认情况下,
HBase 中已存在的表,通过 Phoenix 是不可见的。
如果要在 Phoenix 中操
作 HBase 中已存在的表,可以在 Phoenix 中进行表的映射。映射方式有两种:视图映射和表
映射。
例如创建hbase表test
create 'test','info1','info2'

1)、视图映射
Phoenix 创建的视图是只读的,所以只能用来做查询,无法通过视图对数据进行修改等操作。
在 phoenix 中创建关联 test 表的视图
createview"test"(id varcharprimarykey,"info1"."name"varchar,"info2"."address"varchar);// 删除视图dropview"test";
数字类型说明:
HBase 中的数字,底层存储为补码,而 Phoenix 中的数字,底层存储为在补码的基础上,将符号位反转。故当在 Phoenix 中建表去映射 HBase 中已存在的表,当 HBase 中有数字类型的字段时,会出现解析错误的现象。
例如:
// Hbase 演示:create'test_number','info'
put 'test_number','1001','info:number',Bytes.toBytes(1000)
scan 'test_number',{COLUMNS=>'info:number:toLong'}
// phoenix 演示:createview"test_number"(id varcharprimarykey,"info"."number"bigint);select*from"test_number";
解决上述问题的方案有以下两种:
(1)Phoenix 种提供了 unsigned_int,unsigned_long 等无符号类型,其对数字的编码解码方式和 HBase 是相同的,如果无需考虑负数,那在 Phoenix 中建表时采用无符号类型是最合适的选择.
// phoenix 演示:dropview"test_number";createview"test_number"(id varcharprimarykey,"info"."number"
unsigned_long);select*from"test_number";
(2)如需考虑负数的情况,则可通过 Phoenix 自定义函数,将数字类型的最高位,即
符号位反转即可,自定义函数可参考如下链接:https://phoenix.apache.org/udf.html
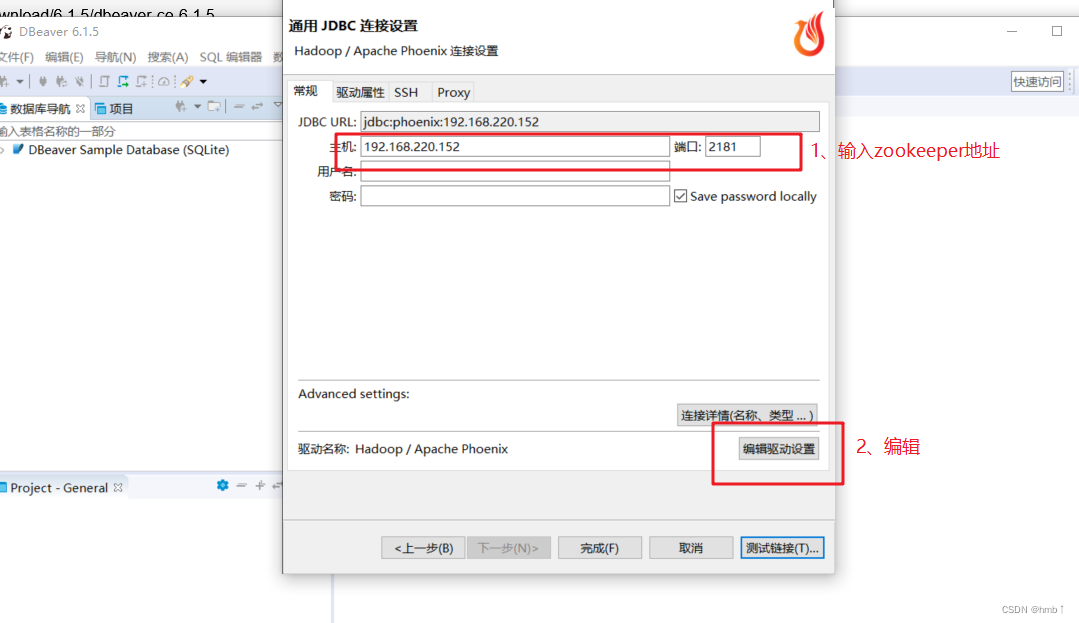
5.6、 Hbase Phoenix 数据库连接工具
下载工具链接: https://github.com/dbeaver/dbeaver/releases/download/6.1.5/dbeaver-ce-6.1.5-x86_64-setup.exe
安装完成后, 在安装目录找到 dbeaver.ini 文件, 在首行添加本机jdk安装目录:
-vm
C:\Program Files\Java\jdk1.8.0_281\bin // 以本机为准
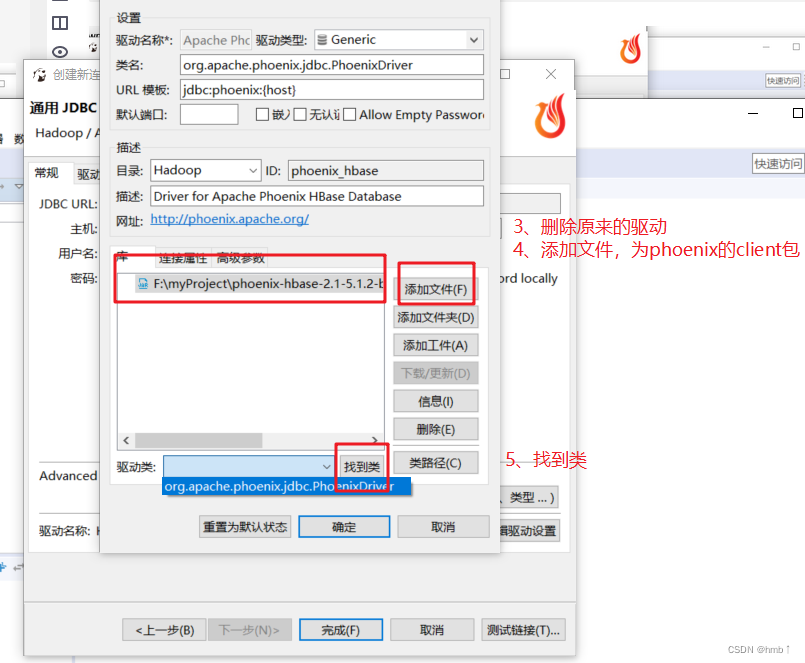 上方添加的文件为下载phoenix时的client包
上方添加的文件为下载phoenix时的client包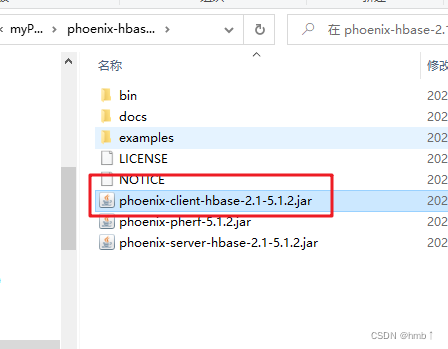
输入sql测试,成功!!!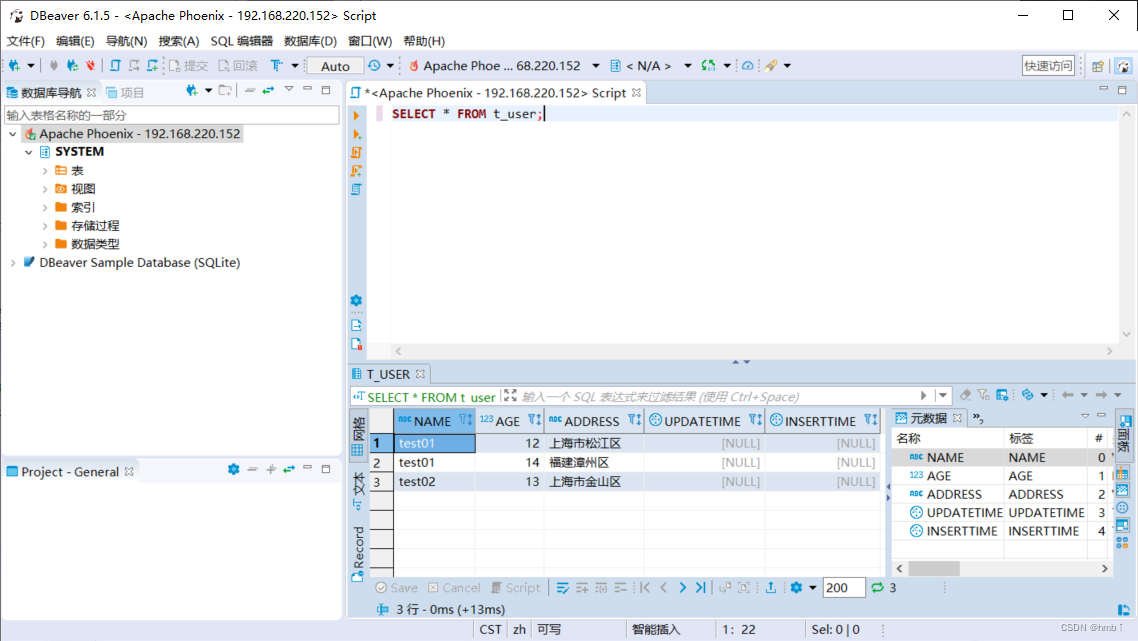
5.7、Springboot集成Phoenix
一直没成功,后续补上。。。
版权归原作者 Archie_java 所有, 如有侵权,请联系我们删除。