
Redis数据类型之Zset详解
Zset简介
Redis 有序集合和Set集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
分数重复的情况下后插入的排在后面
因为Zset的插入方法是找到第一个比当前插入数据分值大的数据,然后插入到它的左边,成为其前驱节点。
Zset常用操作
- ZADD key score member [[score member]…] :往有序集合key中加入带分值元素
- ZREM key member [member …] :从有序集合key中删除元素
- ZSCORE key member :返回有序集合key中元素member的分值
- ZINCRBY key increment member :为有序集合key中元素member的分值加上increment
- ZCARD key :返回有序集合key中元素个数
- ZRANGE key start stop [WITHSCORES] :正序获取有序集合key从start下标到stop下标的元素
- ZREVRANGE key start stop [WITHSCORES] :倒序获取有序集合key从start下标到stop下标的元素
- ZUNIONSTORE destkey numkeys key [key …] :并集计算
- ZINTERSTORE destkey numkeys key [key …] :交集计算
应用场景
- 各种实时 or 历史排行榜
Zset实现
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 **字典(dict) + 跳表(zskiplist)** 。当数据比较少时,用 **ziplist** 编码结构存储。
- zset-max-ziplist-entries : 设置ziplist编码下最大支持的元素个数
默认128个,如超过则会使用字典(dict) + 跳表(zskiplist)模式; - zset-max-ziplist-value :设置ziplist编码下最大支持的单个元素所占字节数
默认64byte,如超过则会使用字典(dict) + 跳表(zskiplist)模式;
源码阅读
/* ZADD方法中判断Zset是否存在并选择使用哪种数据结构代码块*/
zobj =lookupKeyWrite(c->db,key);//查询对应的key在对应的db中是否存在,不存在则创建if(zobj ==NULL){if(xx)goto reply_to_client;/* No key + XX option: nothing to do. *//*
* 如果 zset_max_ziplist_entries ==0 或者 元素的长度 > zset_max_ziplist_value
* 则直接创建 skiplist 数据结构
* 否则创建ziplist 压缩列表数据结构
*/if(server.zset_max_ziplist_entries ==0||
server.zset_max_ziplist_value <sdslen(c->argv[scoreidx+1]->ptr)){
zobj =createZsetObject();}else{
zobj =createZsetZiplistObject();}// 关联对象到db dbAdd(c->db,key,zobj);}else{if(zobj->type != OBJ_ZSET){addReply(c,shared.wrongtypeerr);goto cleanup;}}// 处理所有元素 for(j =0; j < elements; j++){double newscore;// 分值
score = scores[j];int retflags = flags;// 元素
ele = c->argv[scoreidx+1+j*2]->ptr;/*
* 往zobj 添加元素
* 添加元素的zsetAdd方法会去判断当前的有序集合 encoding编码是 ziplist 还是 zset
* 如果是ziplist 则添加元素时还需要判断元素中个数与大小是否超过阈值,如超出则转为zset编码
*/int retval =zsetAdd(zobj, score, ele,&retflags,&newscore);//......省略后续代码}
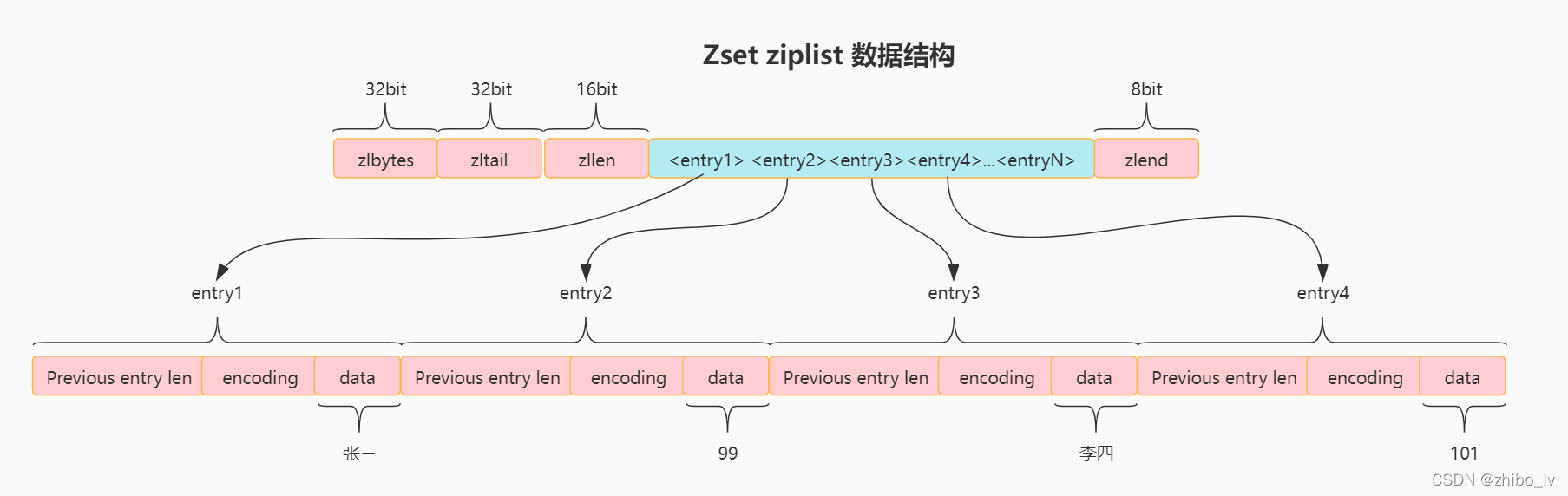
Zset—ziplist实现
当Zset的底层实现是 ziplist 时, ziplist 中的 entry 的个数永远是双数,是以 member score member score … member score 形式存储
且每一次插入都保证有序
。进行查询时,通过直接遍历ziplist,比对 score 的值来获取member 。
此处不再额外对ziplist源码进行阅读,如需了解请通过传送门查看ziplist具体实现:数据类型List实现源码详解
图解Zset—ziplist
假设我的zset中包含许多元素,而最小的两个分别为 :
zadd zset-ziplist 101 李四
zadd zset-ziplist 99 张三
Zset—字典(dict) + 跳表(zskiplist)实现
Zset其实可以看做一个根据 value排序的 hash集合,所以Zset中的 **字典(dict)** ,整体与 hash 的**字典(dict)** 实现基本一致
为了迅速根据member 获取score,同时也可以用于判断 member是否存在
。但是需要额外维护一个 跳表(zskiplist ) 用于排序。
说到有序集合的查找效率问题,当链表过深必然存在遍历缓慢问题,于是Redis选择用 空间换时间 采用 跳表(zskiplist) 方式,来做到一个接近 二分查找 的效率。
此处不再额外对dict源码进行阅读,如需了解请通过传送门查看dict具体实现:数据类型Hash实现源码详解
源码阅读
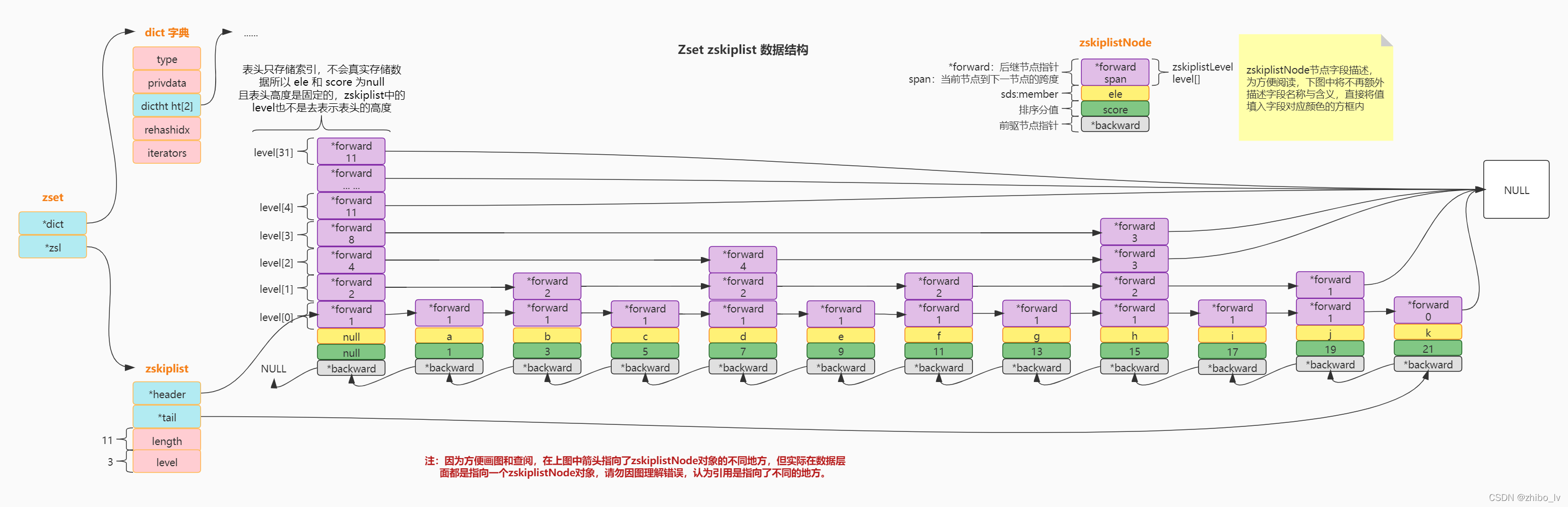
// zset的数据结构 dict + zskiplisttypedefstructzset{
dict *dict;
zskiplist *zsl;} zset;// zskiplist跳表数据结构typedefstructzskiplist{structzskiplistNode*header,*tail;//头、尾指针。方便正序或逆序遍历unsignedlong length;//元素总个数/*
* 跳跃表的节点中level最大的节点的level保存在该成员变量中。
* 但是不包括头结点,头结点的level永远都是最大的值:ZSKIPLIST_MAXLEVEL = 32。
* level的值随着跳跃表中节点的插入和删除随时动态调整
*/int level;} zskiplist;/*
* ZSET 使用专用版本的 Skiplist
* 以下为zskiplist的每个节点的数据结构
* 大家要注意这里的 level[] 这里是一个柔性数组
* 所以关于从高层索引层向下层移动查找时并不是像很多博客中画图的指针指向下一层级!!!
*/typedefstructzskiplistNode{
sds ele;//member元素double score;//分值,用于排序,可以相同structzskiplistNode*backward;//指向前驱节点的指针structzskiplistLevel{//后继节点指针,这个指针只会指向与当前level同层级的下一个节点。(也就是跳表的核心索引了)structzskiplistNode*forward;unsignedlong span;//从当前节点到下一个节点的跨度} level[];//索引数组,该成员是一种柔性数组} zskiplistNode;
图解zskiplist
因图片较大特附上原件地址:https://www.processon.com/view/link/61ff6ace1efad479c07b0323
你的点赞就是我创作的最大动力,如果写的不错,来个三连行不行
本文转载自: https://blog.csdn.net/zhibo_lv/article/details/122796064
版权归原作者 zhibo_lv 所有, 如有侵权,请联系我们删除。
版权归原作者 zhibo_lv 所有, 如有侵权,请联系我们删除。