
文章目录
Hadoop环境搭建
1.安装VMware
下载并安装VMware,这里不做赘述,具体步骤可自行百度。
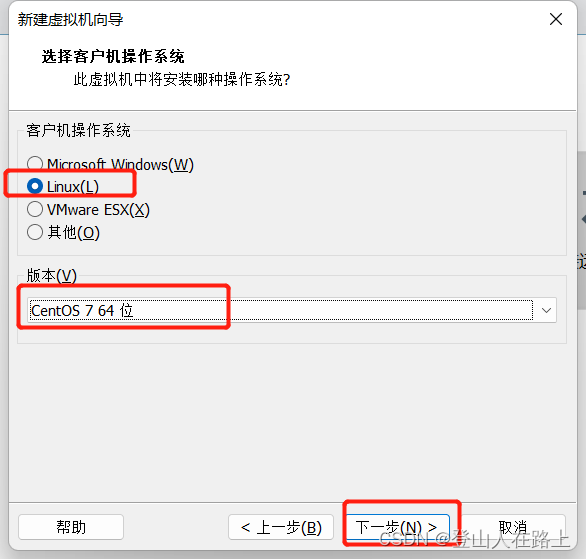
2.centos软硬件安装
本篇文章使用的VMware15版本演示,其他版本步骤同理。
2.1硬件部分
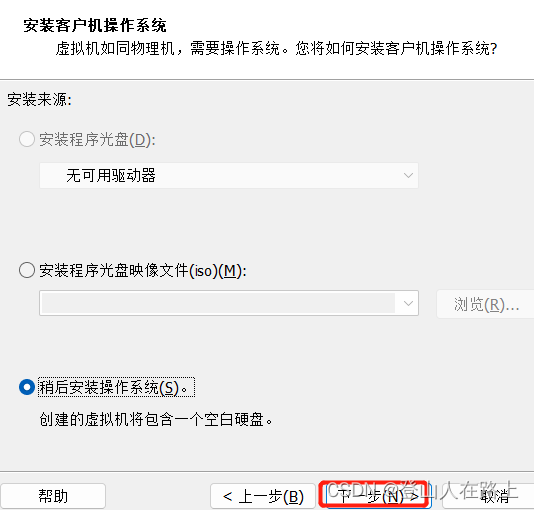
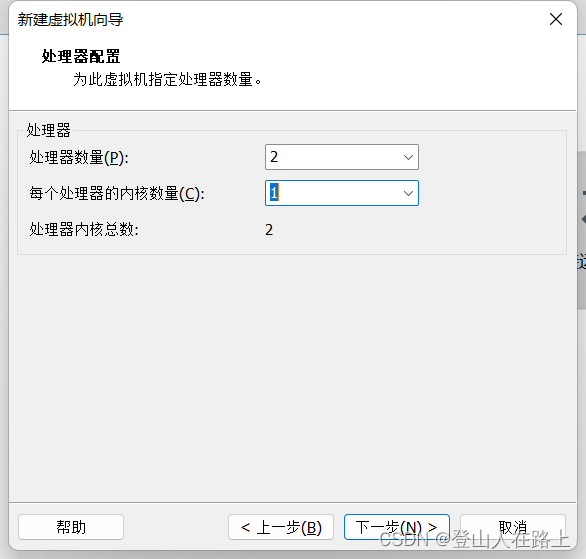
注意:这里不能超过自己电脑内核总数
打开任务管理器(快捷键 ctrl + alt +del),查看电脑内核总数: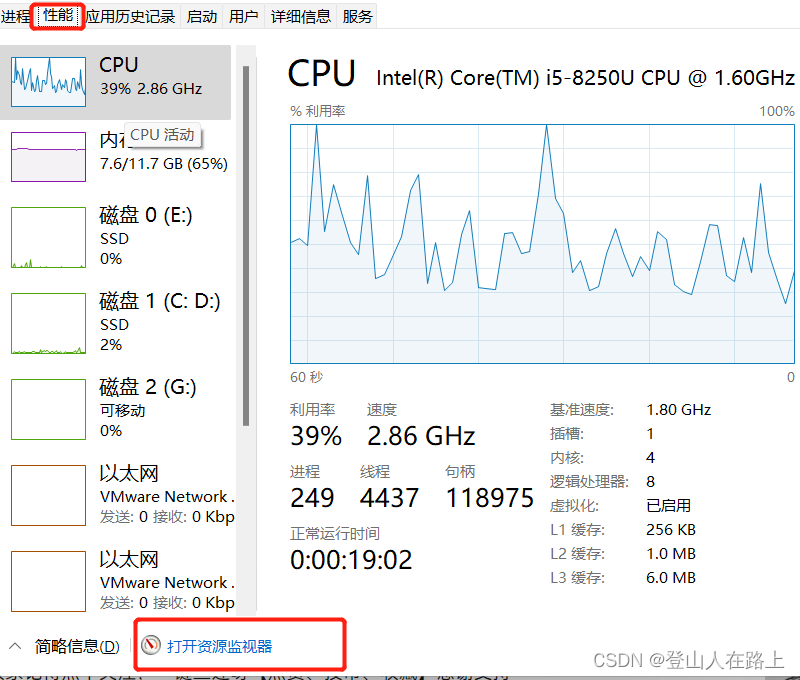
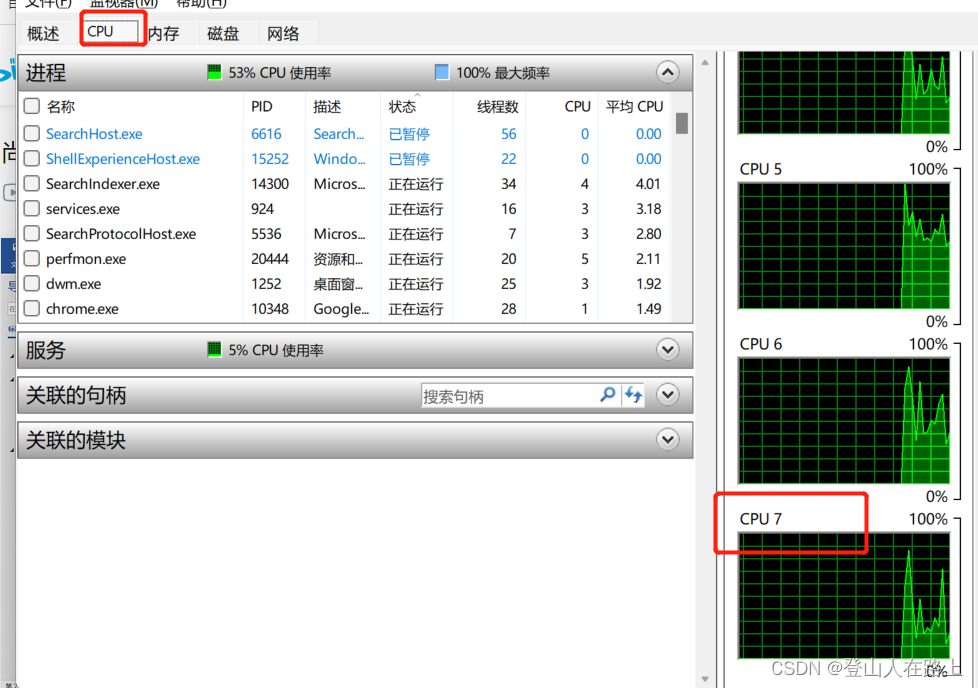
查看到我电脑是有8个CPU内核
假如我们未来要克隆三台虚拟机,再加上本机,一共四台计算机
所以我们平分一下,一台两个内核
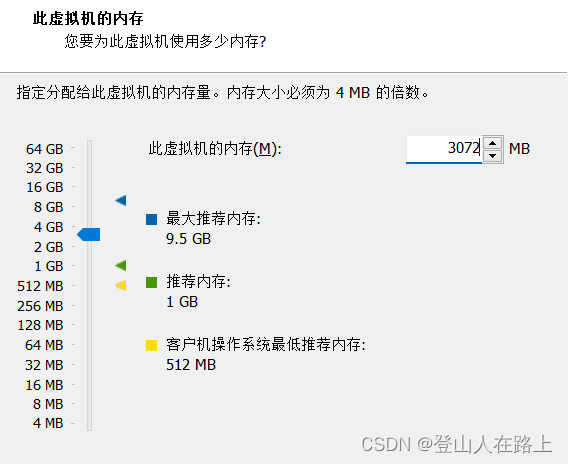
根据自己的需求和电脑配置情况设置内存大小,我这里每台配置3g内存.
如果电脑的内存大小不够的话可以设置为2G或者1G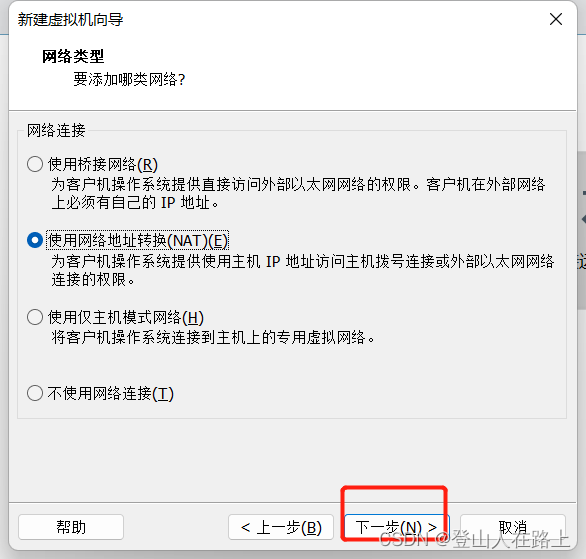
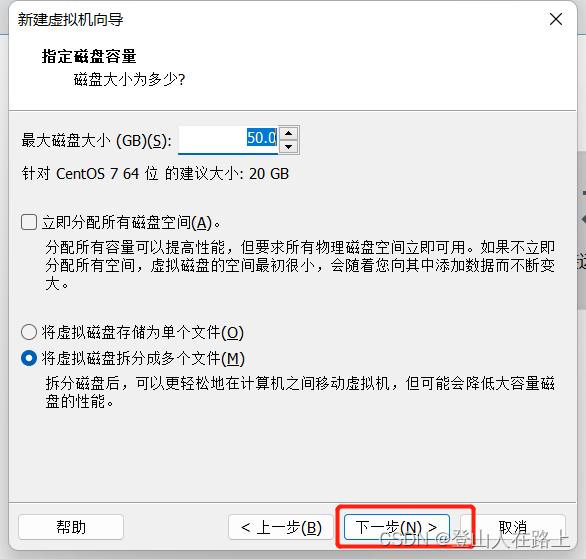
最大磁盘大小在条件允许的情况下建议是设置40G以上, 20G可能后续还需扩容,这里我们设置的50G.
注:50G 是指最大占用50G,如果你没有用到50G,别人也可以使用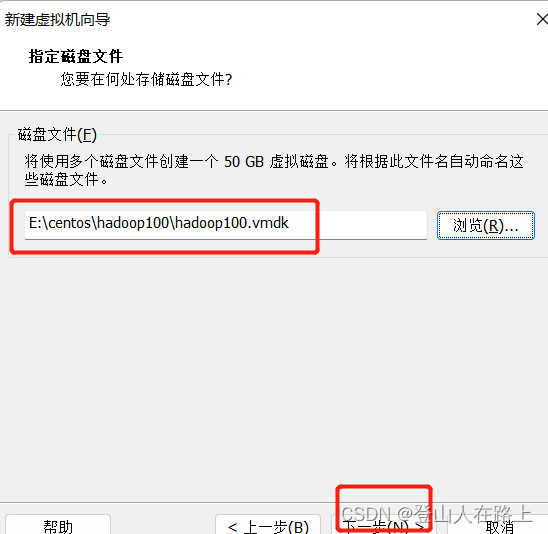
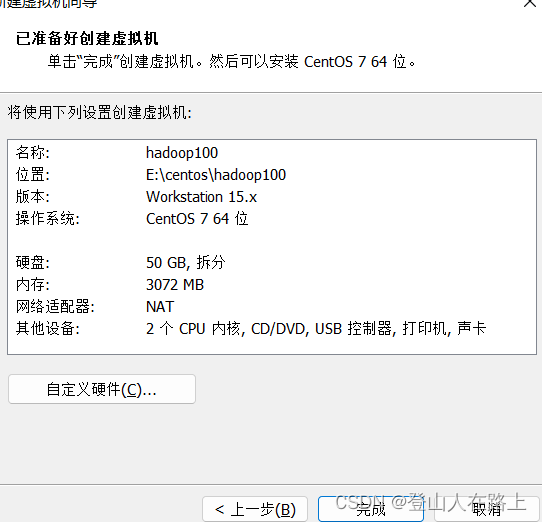
2.2软件部分
确保虚拟化技术已经打开,否则会安装失败.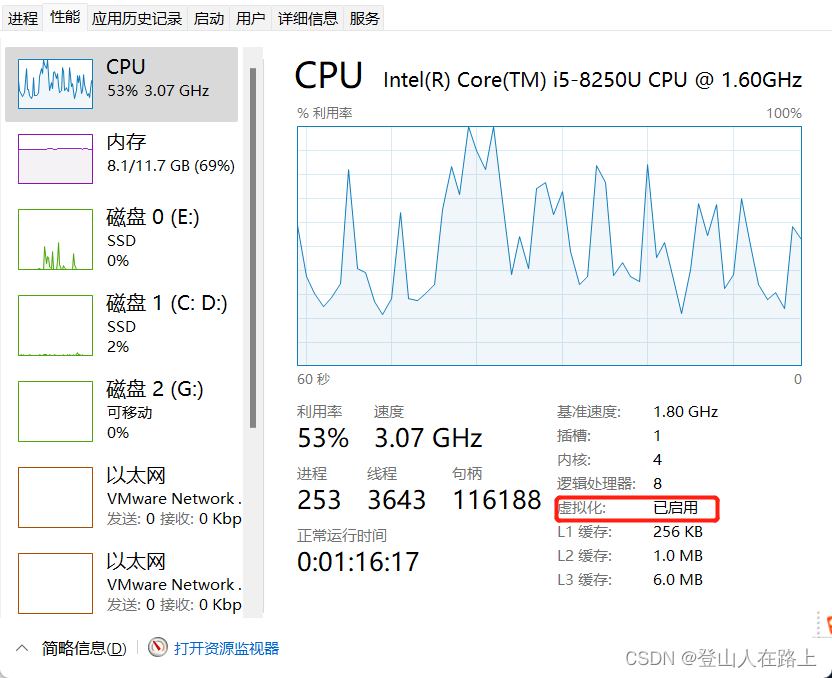
在虚拟机设置里面选择系统的镜像文件,本文使用的是提前下载好的centos7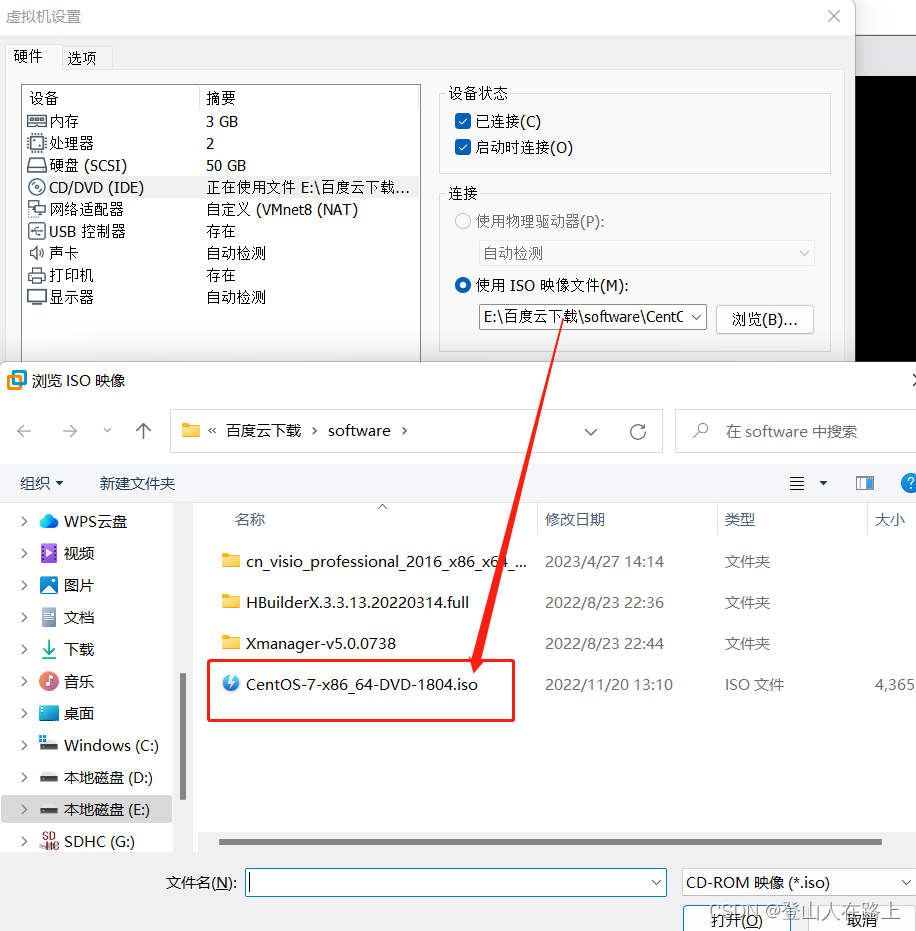
网络适配器可选择NAT模式或者自定义中选择VMnet8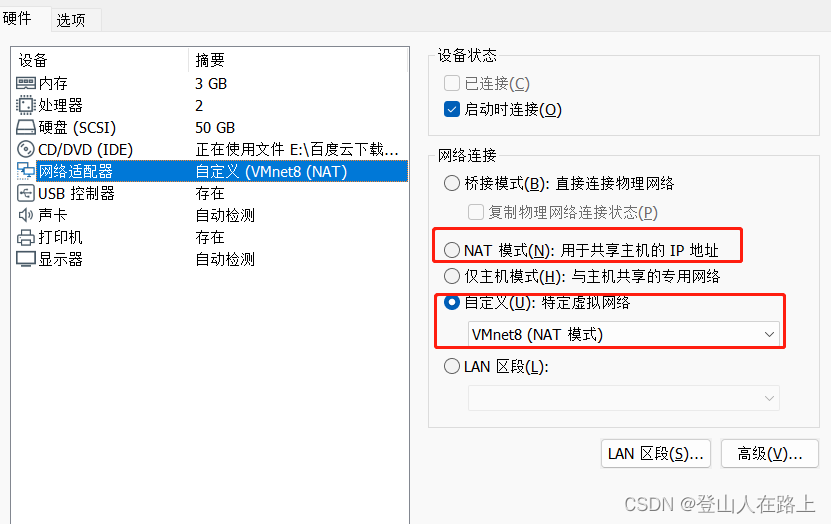
设置完成之后启动虚拟机
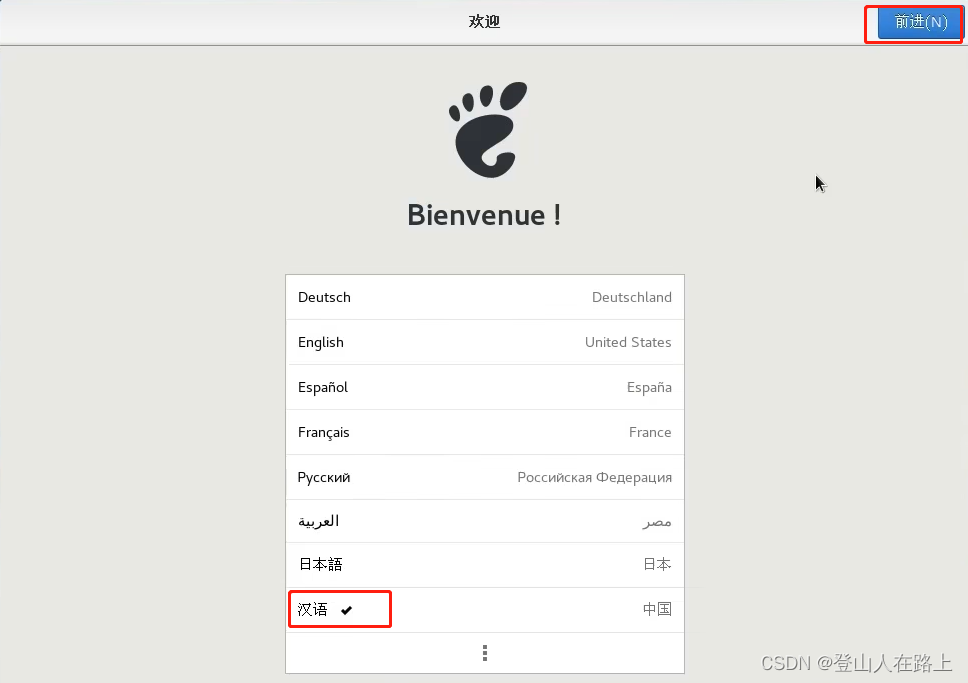
启动成功之后来到欢迎界面
选择语言,我这里选择简体中文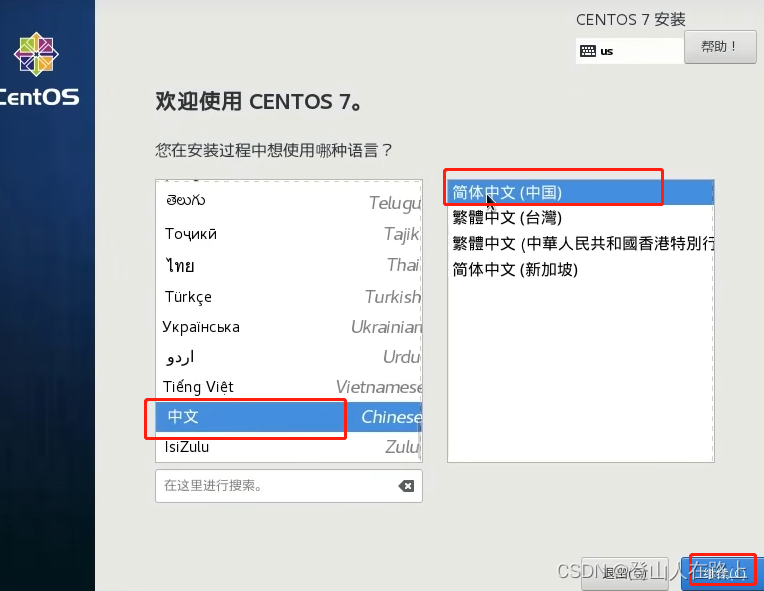
设置日期和时间,将日期和时间设置为当前时间,设置完成后点击完成即可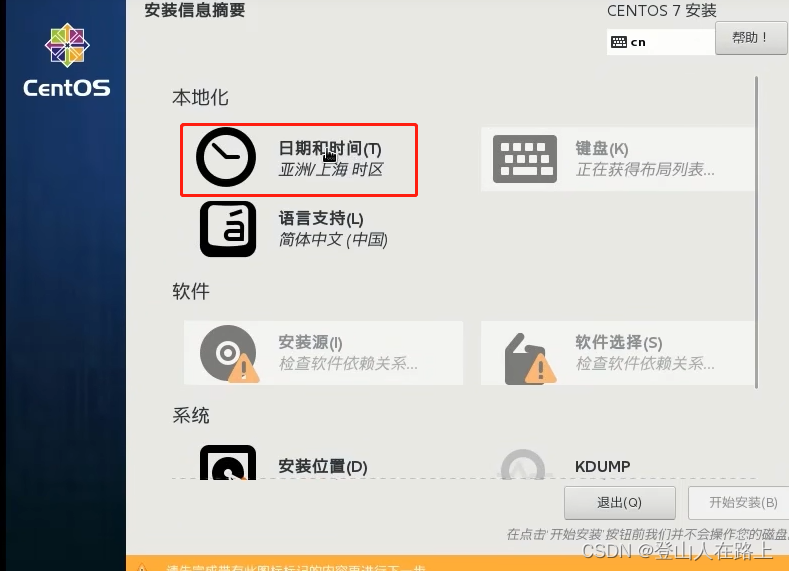
软件选择: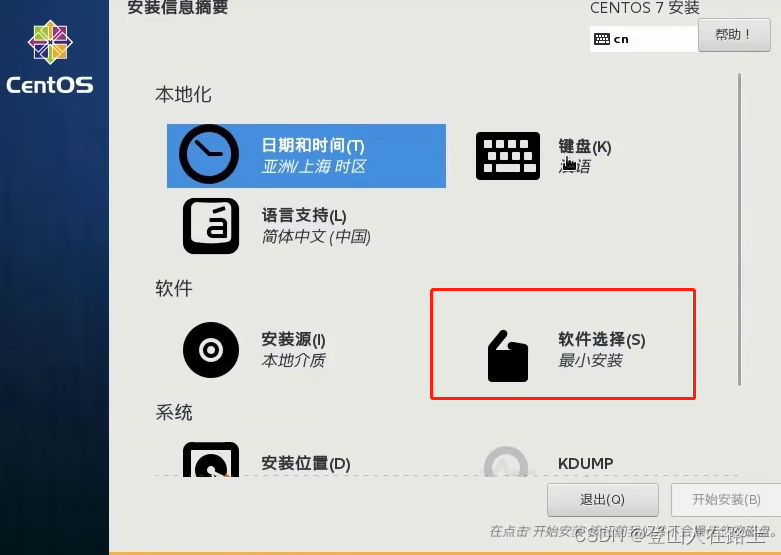
最小安装的意思是只提供命令行界面,不提供图形化界面
真正的生产环境中一般都是使用最小安装
学习阶段建议安装桌面版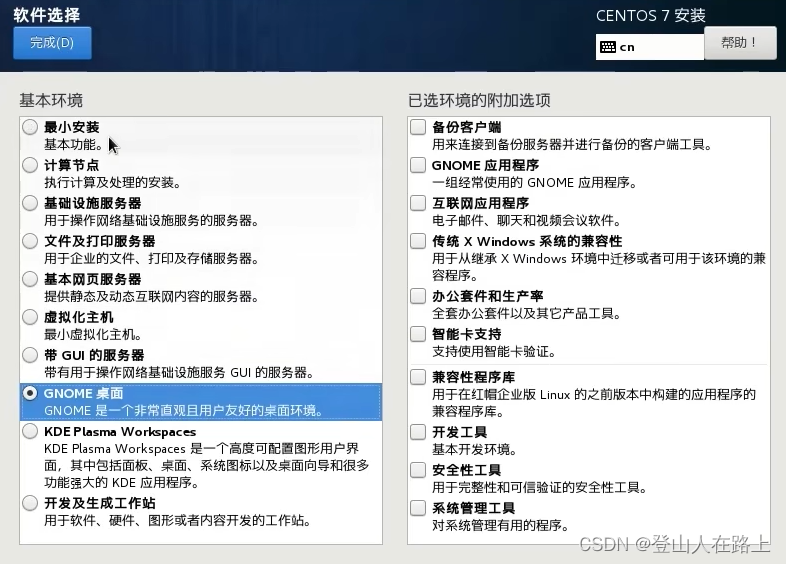
安装位置:
可以进去自定义分区,也可以选择自动分区。为了方便可以选择自动分区。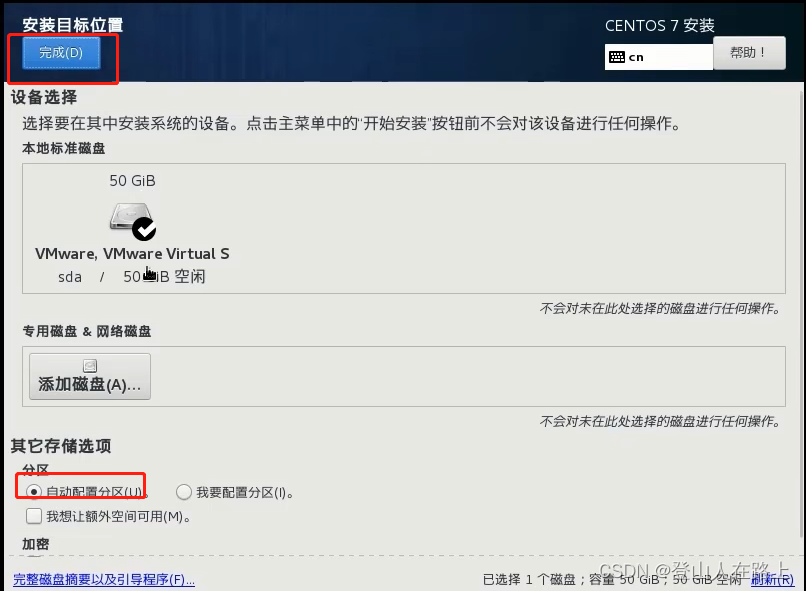
手动分区的话,选择“我要配置分区”,点击完成,然后弹出配置界面,进行配置即可,这里不作赘述。
网络和主机: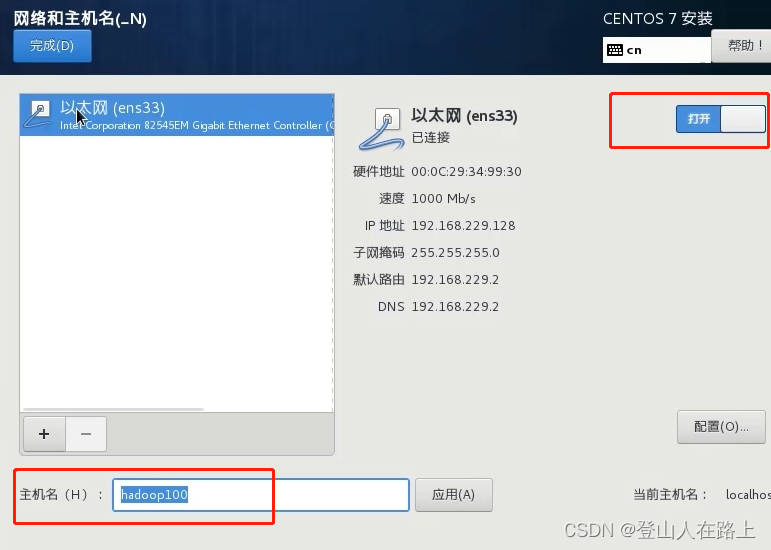
先打开网络连接,设置主机名
后面可以在系统中对主机名,IP地址等信息进行更改
安全策略:
配置完成之后点击开始安装即可
点击安装之后进行安装,安装需要一段时间,这时候可以设置root的密码
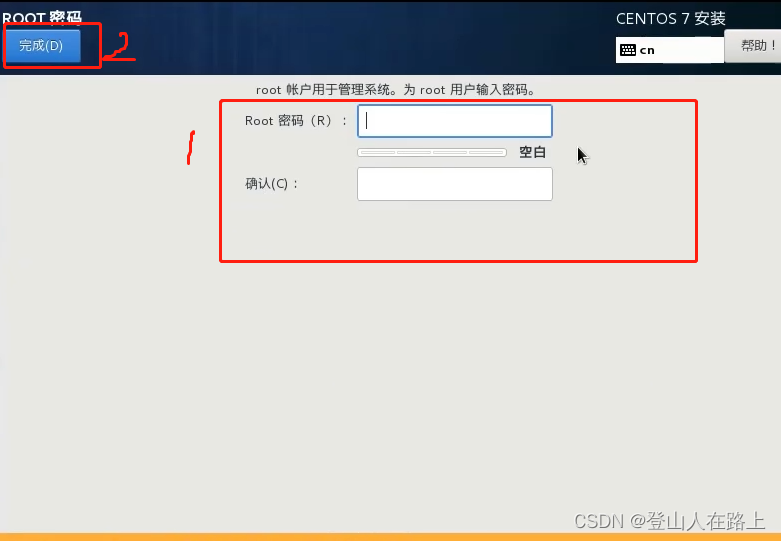

设置完成之后等待安装完成即可
安装完成之后点击重启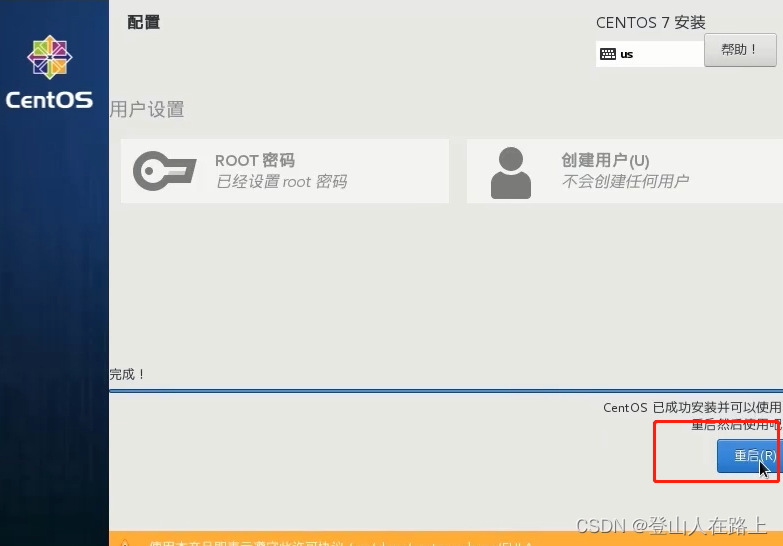
创建一个普通账号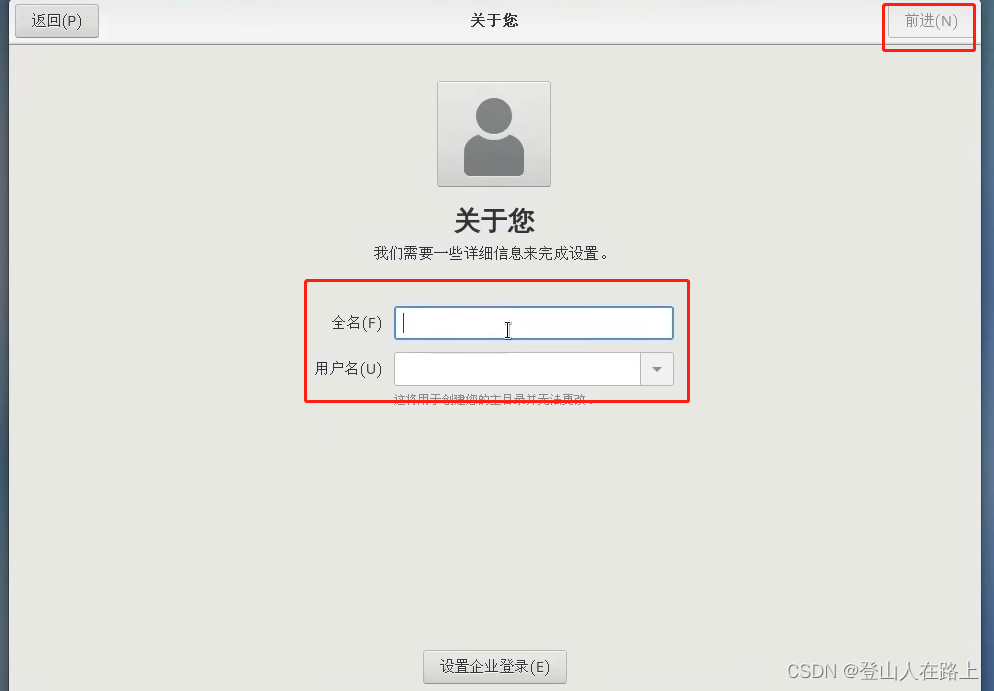
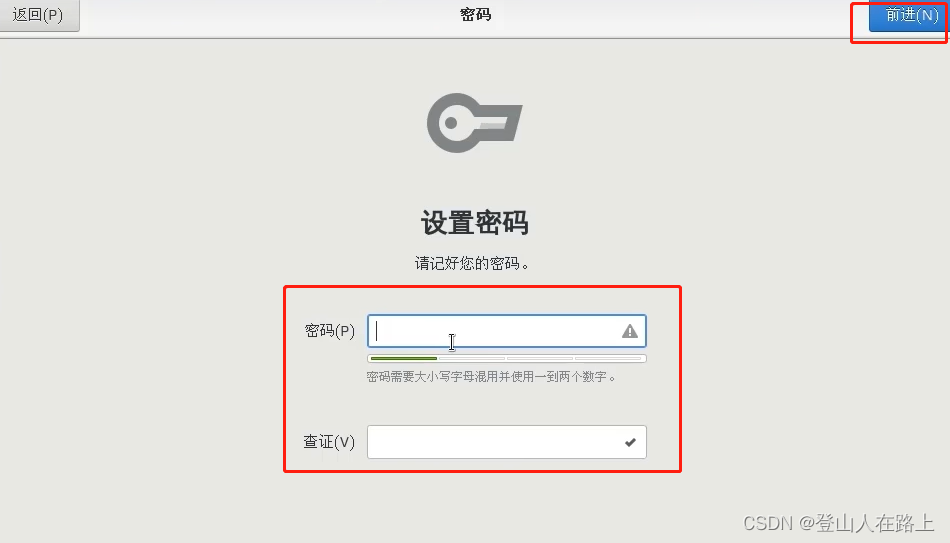
配置完成
3.主机IP和名称配置
3.1 IP配置
编辑–虚拟网络编辑器
IP设置:
这里的子网IP根据规则自己设置即可,我这里设置为192.168.101.0
另外需要选中nat模式和将主机虚拟适配器连接到此网络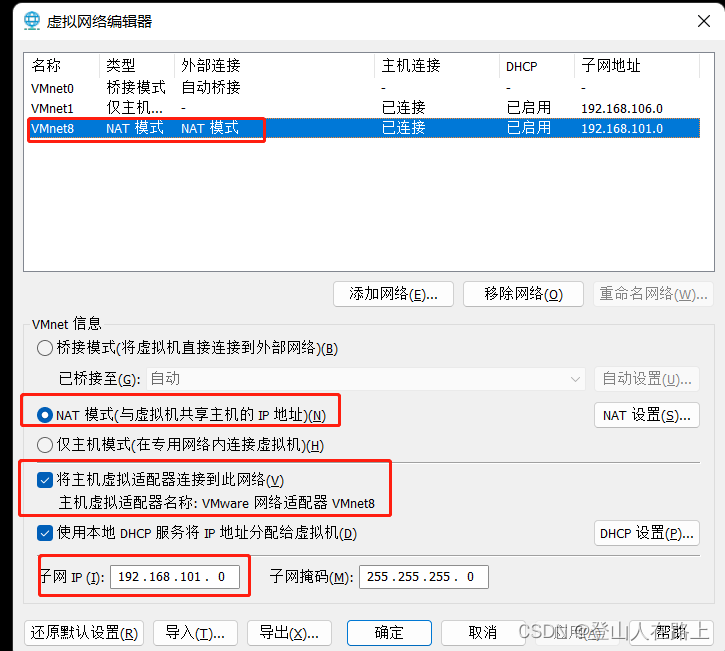
设置网关:
设置网关IP,网关IP要和子网IP在同一网段,我这里设置为192.168.101.2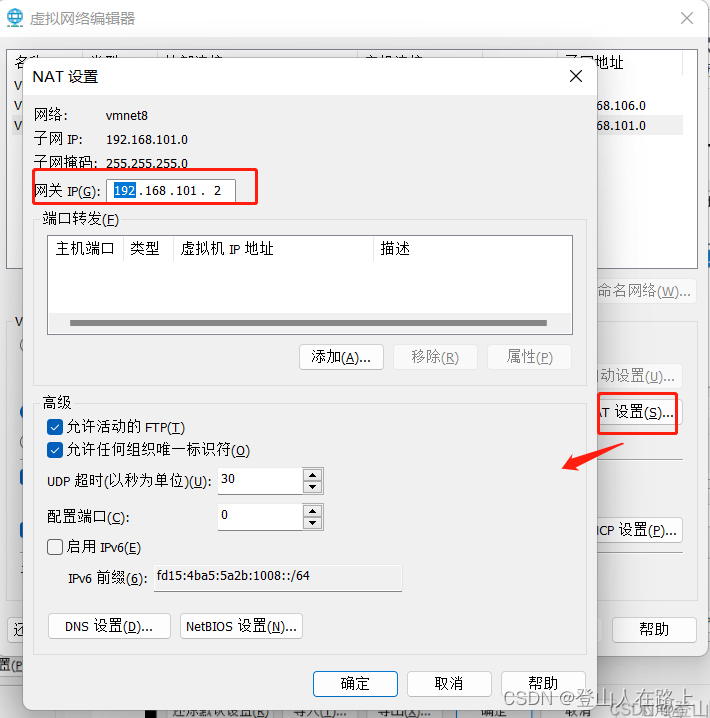
到这里相当于已经把vm的IP地址配置完了
然后我们配置自己电脑上面的IP地址
选择使用下面的IP地址
对照虚拟机中的配置进行填写即可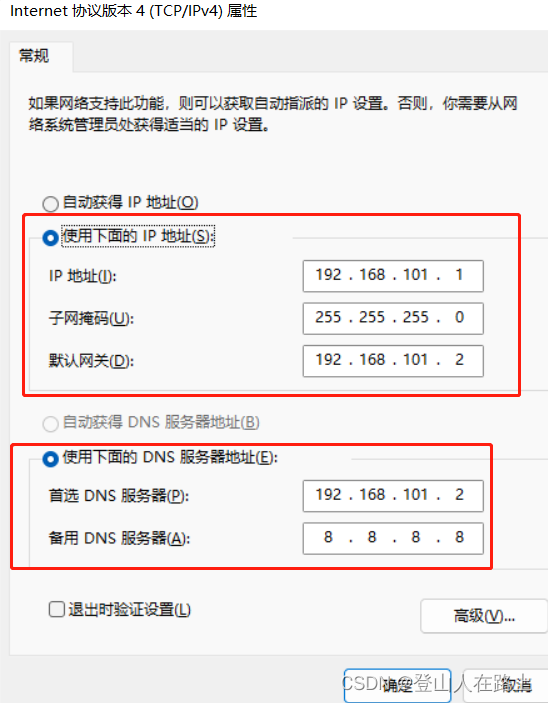
3.2主机名配置
vim /etc/hostname
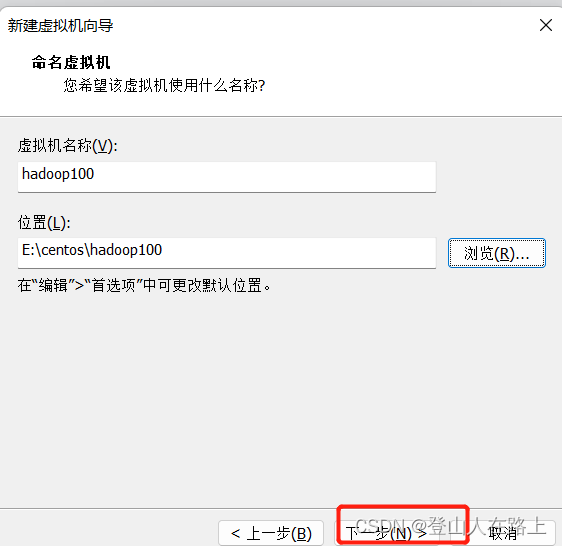
将主机名设置为hadoop100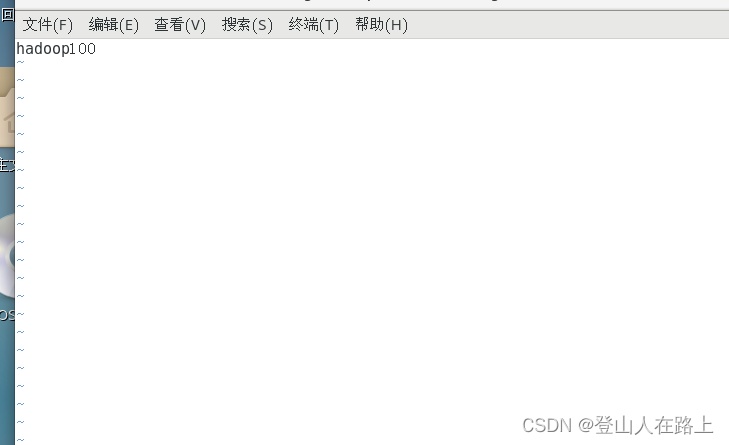
保存
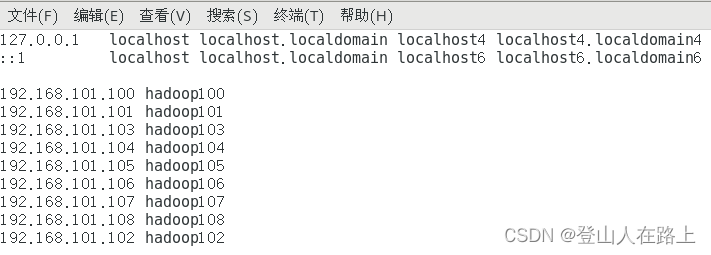
配置主机名和IP地址映射
vim /etc/hosts
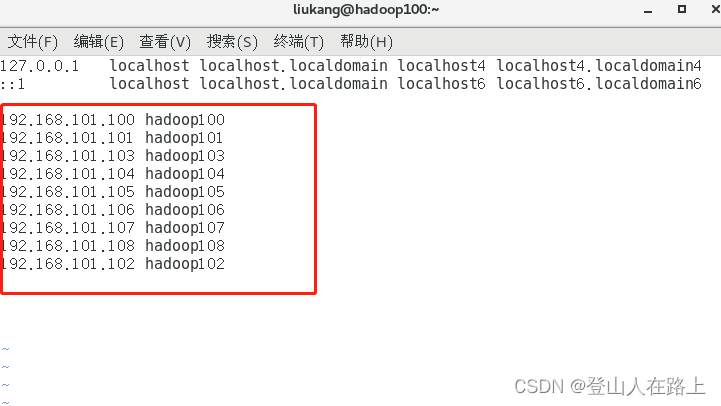
配置映射的作用:
比如在上面这台虚拟机上面配置了上述主机名称和IP的映射,那么我要在这台主机访问另外几个IP,只需要访问他们的主机名即可。
比如 ping 192.168.101.101和ping hadoop101其实是一样的
4.测试连接
输入主机IP,用户名和密码,点击确定。
这里的认证用户可以是root用户也可以是自己设置的普通用户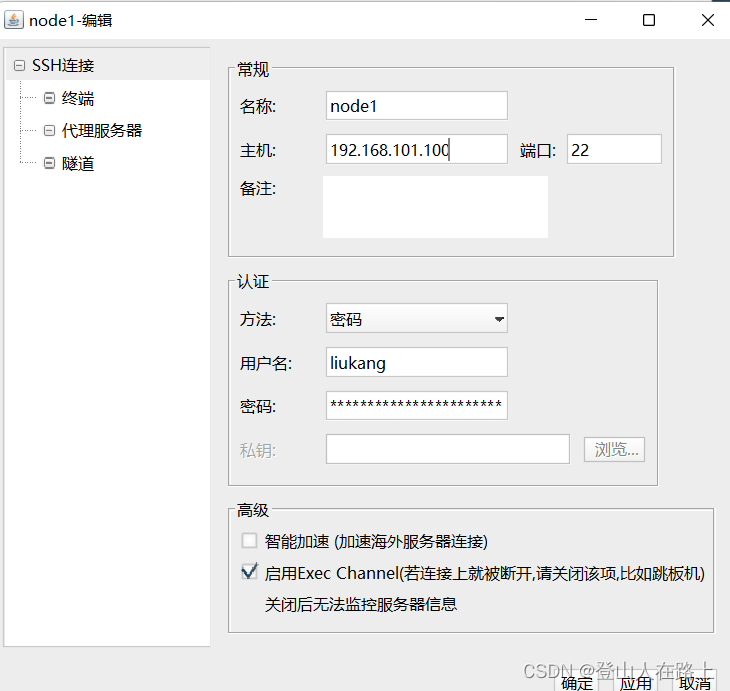
5.克隆虚拟机
5.1克隆虚拟机
将这台配置好的虚拟机克隆
关机,右键—>管理—>克隆
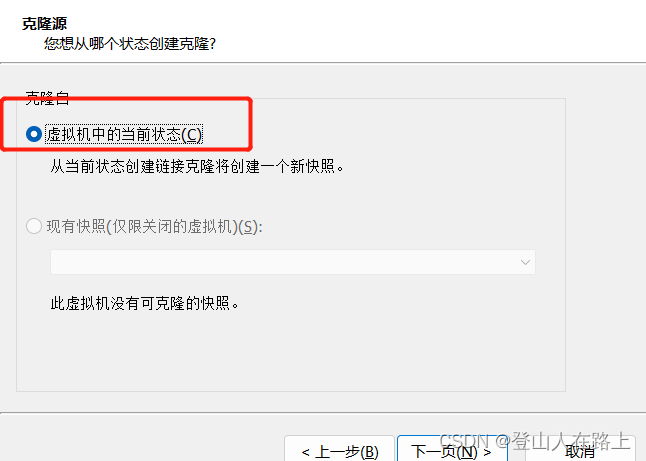
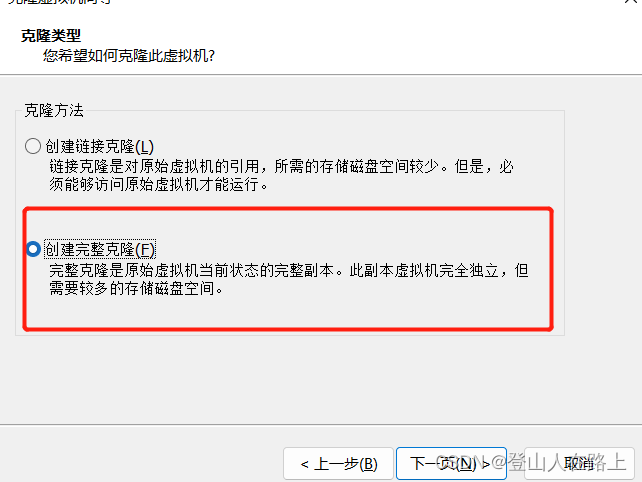
设置名称和地址,点击完成
5.2 修改主机IP和主机名
1.进入Hadoop102
vim /etc/sysconfig/network-scripts/ifcfg-ens33
2.修改IP地址
先切换到root用户再使用上述命令,否则无法修改文件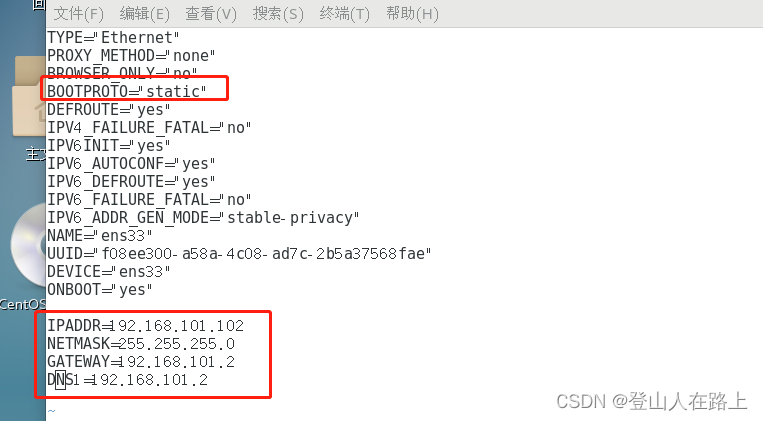
修改IP地址为192.168.101.102即可,上图是修改后的结果。
另外确保bootproto是static,而不是DHCP
这样能保证IP地址是固定的,而不是动态分配的
修改完成之后保存
3.修改主机名
vim /etc/hostname
改成hadoop102
4.查看映射
vim /etc/hosts
5.重启
reboot
测试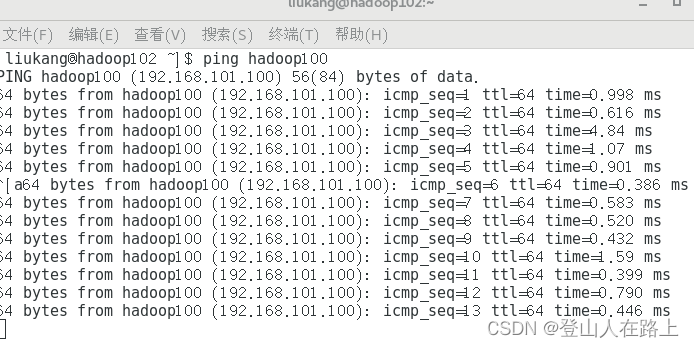
按照上述步骤还可继续克隆。
6.安装jdk
1.下载jdk并上传到虚拟机上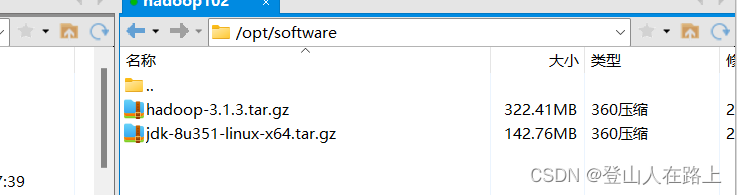
2.安装jdk
tar-zxvf jdk文件名称 -C 执行安装的目录
tar-zxvf jdk-8u351-linux-x64.tar.gz -C /opt/module/
3.安装完成来到/opt/module/查看是否存在
4.然后进入安装的jdk的目录
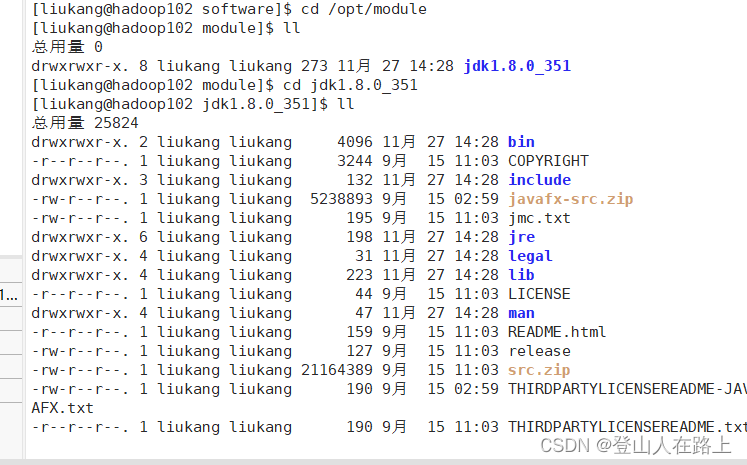
5.配置jdk的环境变量
cd /etc/ profile.d
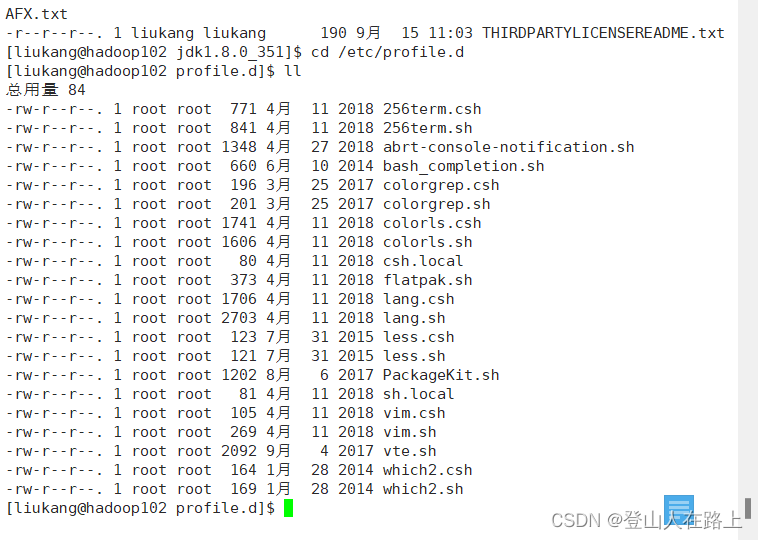
这里面就有后缀是sh的文件,系统启动的时候会加载这些文件
自己创建一个文件my_env.sh,在这个文件里面定义环境变量
sudovim my_env.sh
在里面写入配置环境变量并保存

生效环境变量
source /etc/profile

出现上面内容就可以了
7.安装Hadoop
1.来到software目录下(上传jdk到虚拟机上的时候,把Hadoop文件也一起上传了)
2.解压缩
tar-zxvf Hadoop文件名称 -C 执行安装的目录
tar-zxvf hadoop-3.1.3.tar.gz -C /opt/module/
3.查看module目录
4.配置环境变量
sudovim /etc/profile.d/my_env.sh
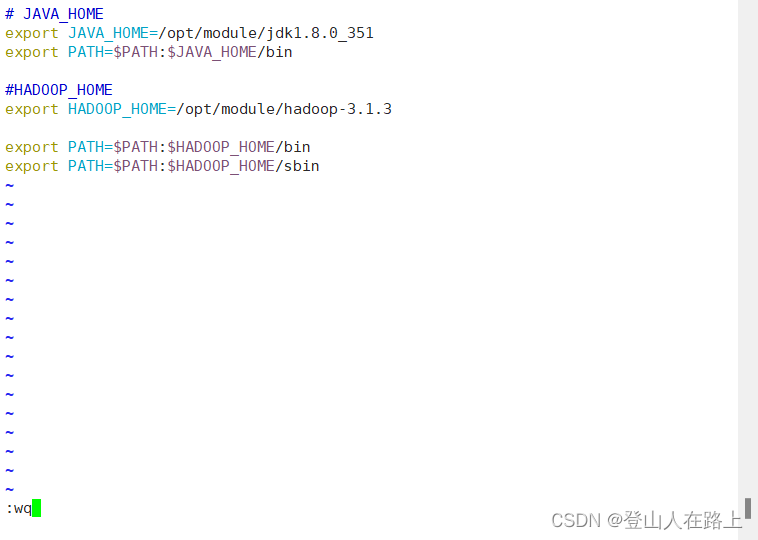
5.生效环境变量
source /etc/profile

6.测试是否成功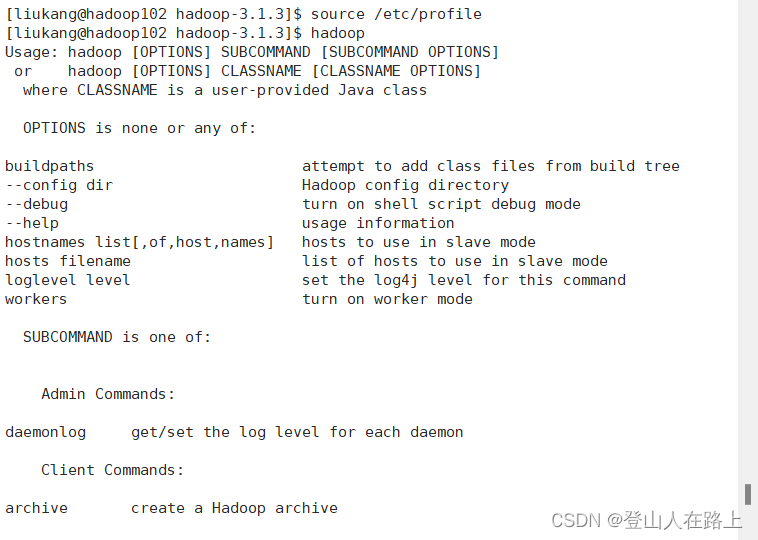
8.完成防火墙、SElinux、时间同步等系统设置
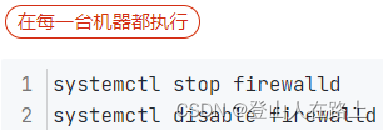
8.1关闭防火墙
集群化软件之间需要通过端口互相通讯,为了避免出现网络不通的问题,我们可以简单的在集群内部关闭防火墙。
8.2关闭SELinux
Linux有一个安全模块:SELinux,用以限制用户和程序的相关权限,来确保系统的安全稳定。
在当前,我们只需要关闭SELinux功能,避免导致后面的软件运行出现问题即可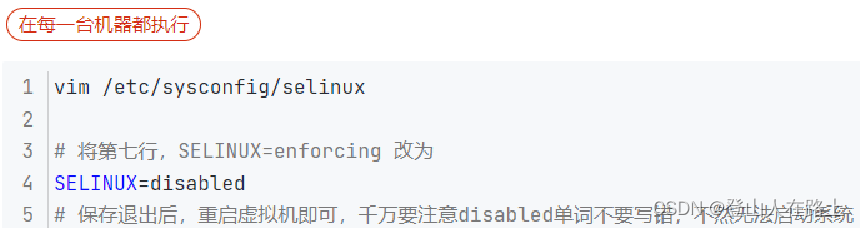
8.3修改时区并配置自动时间同步
以下操作在三台Linux均执行
yum install-y ntp
2. 更新时区
rm-f /etc/localtime;sudoln-s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3. 同步时间
ntpdate -u ntp.aliyun.com
4. 开启ntp服务并设置开机自启
systemctl start ntpd
systemctl enable ntpd
版权归原作者 登山人在路上 所有, 如有侵权,请联系我们删除。