
目录
1. Mysql整体架构
客户端: 由各种语言编写的程序,负责与Mysql服务端进行网络连接。
服务端: 包括以下几层
- 连接层:负责客户端的接入工作。
- 服务层:4大组件。SQL接口组件、解析器、优化器、缓存和缓冲区
- 存储引擎层:存储引擎负责与磁盘打交道。Mysql的存储引擎支持可拔插式,可以切换不同的存储引擎。
- 文件系统层:是一个基于磁盘的文件系统
一条sql语句的执行就是从上往下经过这4层。

1-1. 连接层
- 一个客户端的与服务端要建立连接,Mysql内部就需要一个线程来负责该客户端接下来的所有工作。
- MySQL是基于TCP/IP协议栈实现的连接建立工作,但并非使用HTTP协议建立连接的。具体协议要根据不同的客户端,例如:
jdbc``````odbc等 - 数据库连接池负责复用线程、管理线程以及限制最大连接数。因为线程属于宝贵资源。
show variables like '%max_connections%';查询目前Mysql的最大连接数。
1-2. 服务层
- SQL接口组件1. 负责接收SQL语句,将其发送给其他组件。然后等待接收执行结果的返回,最后会将其返回给客户端。
- 解析器1. 接收SQL接口组件发来的SQL语句2. 验证SQL语句是否正确,以及将SQL语句解析成MySQL能看懂的机器码指令
- 优化器1. 解析器完成之后,优化器就生成执行计划,最终会选择出一套最优的执行计划。这个执行的过程实际上是在调用存储引擎所提供的API。
- 缓存和缓冲区1. 缓存主要就是
select的数据缓存。MySQL会对于一些经常执行的查询SQL语句,将其结果保存在缓存中。2. 在MySQL 8.X中,移除了缓存区,毕竟命中率不高。同时一般程序都会使用Redis做一次缓存。3. 缓冲区的设计主要是:为了通过内存的速度来弥补磁盘速度较慢对数据库造成的性能影响。4. 对数据库进行写操作时,都会先从缓冲区中查询是否有,如果有,则直接对内存中的数据进行操作(例如修改、删除等),对缓冲区中的数据操作完成后,会直接给客户端返回成功的信息,然后MySQL会在后台利用一种名为Checkpoint的机制,将内存中更新的数据刷写到磁盘。5. 缓冲区是与存储引擎有关的,不同的存储引擎实现也不同,比如InnoDB的缓冲区叫做innodb_buffer_pool,而MyISAM则叫做key_buffer。
1-3. 存储引擎层
- 存储引擎是MySQL数据库中与磁盘文件打交道的子系统,不同的引擎底层访问文件的机制也存在些许细微差异。
- 引擎也不仅仅只负责数据的管理,也会负责库表管理、索引管理等,MySQL中所有与磁盘打交道的工作,最终都会交给存储引擎来完成。
1-4. 文件系统层
- 本质上就是基于机器物理磁盘的一个文件系统,其中包含了配置文件、库表结构文件、数据文件、索引文件、日志文件等各类MySQL运行时所需的文件。
- 这一层的功能比较简单,也就是与上层的存储引擎做交互,负责数据的最终存储与持久化工作。
- 这一层主要可分为两个板块:①日志板块。②数据板块。
日志板块
①binlog二进制日志,主要记录MySQL数据库的所有写操作(增删改)。
②redo-log重做/重写日志,MySQL崩溃时,对于未落盘的操作会记录在这里面,用于重启时重新落盘(InnoDB专有的)。
③undo-logs撤销/回滚日志,记录事务开始前[修改数据]的备份,用于回滚事务。
④error-log:错误日志:记录MySQL启动、运行、停止时的错误信息。
⑤general-log常规日志,主要记录MySQL收到的每一个查询或SQL命令。
⑥slow-log:慢查询日志,主要记录执行时间较长的SQL。
⑦relay-log:中继日志,主要用于主从复制做数据拷贝。
数据板块
db.opt文件:主要记录当前数据库使用的字符集和验证规则等信息。
.frm文件:存储表结构的元数据信息文件,每张表都会有一个这样的文件。
.MYD文件:用于存储表中所有数据的文件(MyISAM引擎独有的)。
.MYI文件:用于存储表中索引信息的文件(MyISAM引擎独有的)。
.ibd文件:用于存储表数据和索引信息的文件(InnoDB引擎独有的)。
.ibdata文件:用于存储共享表空间的数据和索引的文件(InnoDB引擎独有)。
.ibdata1文件:这个主要是用于存储MySQL系统(自带)表数据及结构的文件。
.ib_logfile0/.ib_logfile1文件:用于故障数据恢复时的日志文件。
.cnf/.ini文件:MySQL的配置文件,Windows下是.ini,其他系统大多为.cnf。
2. 一条sql语句的执行过程
2-1. 数据库连接池的作用
客户端要将SQL语句发给服务端之前,要先根据配置文件中的
url
、
username
、
password
与服务端进行网络连接。
由于涉及到了网络请求,那此时必然会先经历TCP三次握手的过程,同时获取到连接对象完成SQL操作后,又要释放这个数据库连接,此时又需要经历TCP四次挥手过程。
因此每次操作数据库时,客户端都需要获取新的连接对象,这是非常耗时耗资源的操作。
「数据库连接池」和「线程池」的思想相同,会将数据库连接这种较为珍贵的资源,利用池化技术对这种资源进行维护。也就代表着之后需要进行数据库操作时,不需要自己去建立连接了,而是直接从「数据库连接池」中获取,用完之后再归还给连接池,以此达到复用的效果。
MySQL连接池维护的是工作线程,客户端连接池则维护的是网络连接。
2-2. 查询sql的执行过程
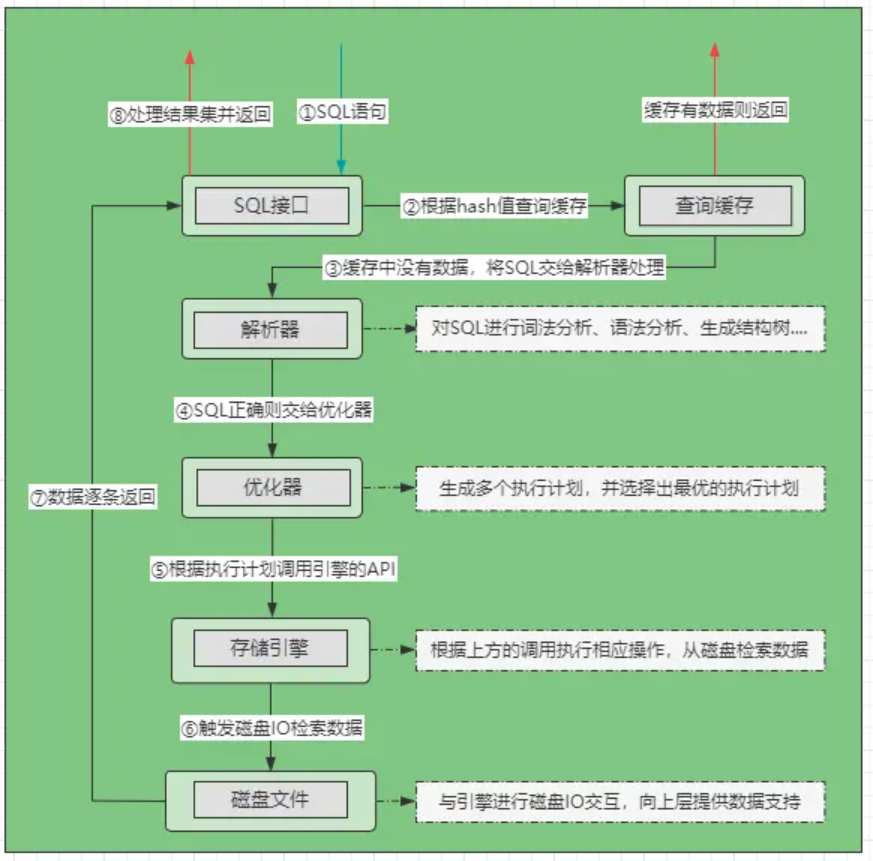
注意:
Mysql 8.X 版本
已经移除了查询缓存
- ①先将SQL发送给SQL接口,SQL接口会对SQL语句进行哈希处理。
- ②SQL接口在缓存中根据哈希值检索数据,如果缓存中有则直接返回数据。
- ③缓存中未命中时会将SQL交给解析器,解析器会判断SQL语句是否正确:- 错误:抛出1064错误码及相关的语法错误信息。- 正确:将SQL语句交给优化器处理,进入第④步。
- ④优化器根据SQL制定出不同的执行方案,并择选出最优的执行计划。
- ⑤工作线程根据执行计划,调用存储引擎所提供的API获取数据。
- ⑥存储引擎根据API调用方的操作,去磁盘中检索数据(索引、表数据…)。
- ⑦发生磁盘IO后,对于磁盘中符合要求的数据逐条返回给SQL接口。
- ⑧SQL接口会对所有的结果集进行处理(剔除列、合并数据…)并返回。
2-1. 写sql的执行过程
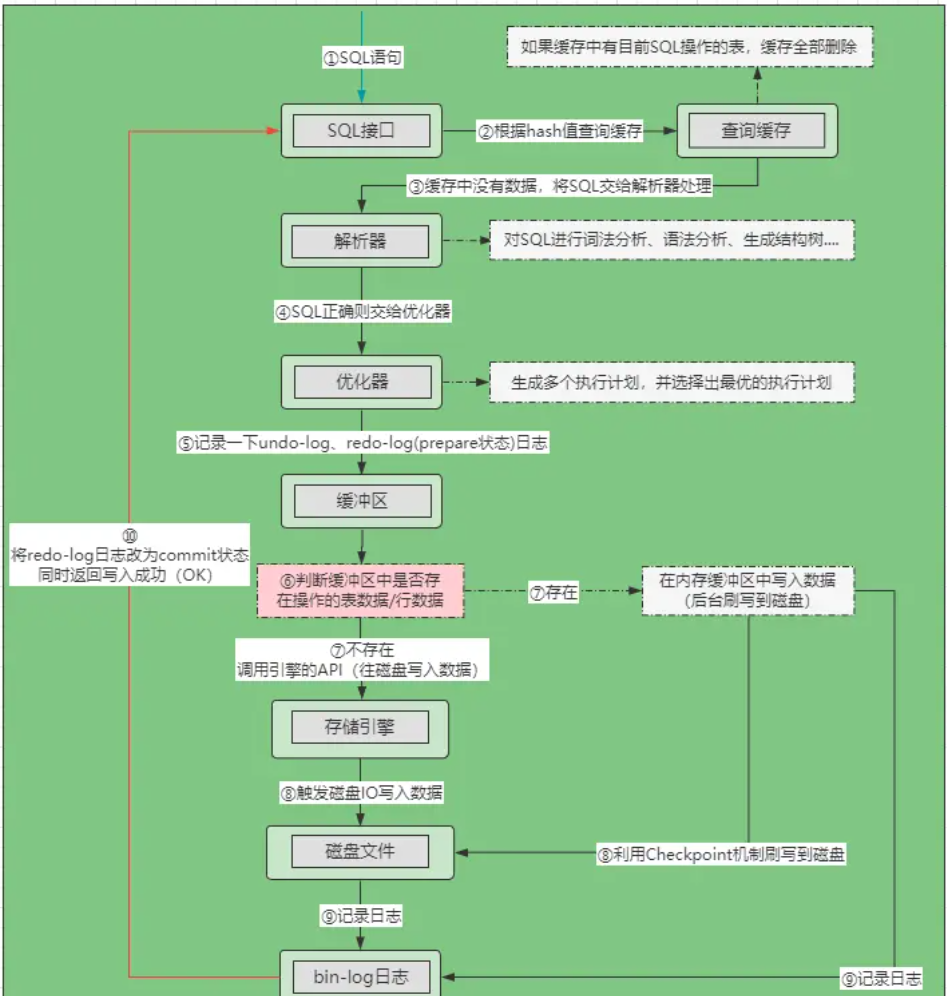
- ①先将SQL发送给SQL接口,SQL接口会对SQL语句进行哈希处理。
- ②在缓存中根据哈希值检索数据,如果缓存中有,则将对应表的所有缓存全部删除。
- ③经过缓存后会将SQL交给解析器,解析器会判断SQL语句是否正确: - 错误:抛出1064错误码及相关的语法错误信息。- 正确:将SQL语句交给优化器处理,进入第④步。
- ④优化器根据SQL制定出不同的执行方案,并择选出最优的执行计划。
- ⑤在执行开始之前,先记录一下
undo-log日志和redo-log(prepare状态)日志。 - ⑥在缓冲区中查找是否存在当前要操作的行记录或表数据(内存中): - 存在: - ⑦直接对缓冲区中的数据进行写操作。- ⑧然后利用
Checkpoint机制刷写到磁盘。- 不存在: - ⑦根据执行计划,调用存储引擎的API。- ⑧发生磁盘IO,对磁盘中的数据做写操作。 - ⑨写操作完成后,记录
bin-log日志,同时将redo-log日志中的记录改为commit状态。 - ⑩将SQL执行耗时及操作成功的结果返回给SQL接口,再由SQL接口返回给客户端。
undo-log日志
- 撤销/回滚日志,所有的写SQL在执行之前都会生成对应的撤销SQL,撤销SQL也就是相反的操作
- 比如现在执行的是insert语句,那这里就生成对应的delete语句
undo-log日志
- InnoDB引擎专属的,将写SQL的事务过程记录在案,如果服务器或者MySQL宕机,重启时就可以通过redo_log日志恢复更新的数据。
- 在「写SQL」正式执行之前,就会先记录一条prepare状态的日志,表示当前「写SQL」准备执行,然后当执行完成并且事务提交后,这条日志记录的状态才会更改为commit状态。
版权归原作者 程序员iteng 所有, 如有侵权,请联系我们删除。