

1、PRIMARY KEY
上期我们讲述了 not null 和 unique 约束,而本期的第一个约束就是这俩的结合体,也成为主键约束。
主键约束,说白了就是 not null + unique,主键也是在插入数据的时候先进行查询,而 MySQL 则会对 unique,primary key 这样的列自动的添加索引(后续介绍),来提高查询的效率。
● 在实际开发中,大部分的表,一般都会带有一个主键,主键往往是一个整数表示的 id。
create table student (
id int primary key,
name varchar(10)
);
只要你给改列设置了主键,意味着后续插入的数据,既不能重复,也不能为空!
● 在 MySQL 中,一个表中只能有一个主键,不能有多个。
create table student (
id int primary key,
name varchar(10) primary ke
);
-- ERROR 1068 (42000): Multiple primary key defined
● 虽然主键不能有多个,但支持将多个列放到一起,共同作为主键,称为联合主键。
create table student (
id int,
name varchar(10),
primary key (id, name)
);
desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(10) | NO | PRI | NULL | |
+-------+-------------+------+-----+---------+-------+
-- 2 rows in set (0.00 sec)
这样我们就能发现 Key 这一列有两个 PRI 了,PRI 是主键的简写,表示是主键字段,同时也能看到 Null 这一列为 NO,所以主键包含了 not null 和 unique 的特性。
● 主键还有一个非常常用的用法,使用 MySQL 自带的自增主键作为主键的值。
create table student (
id int primary key auto_increment,
name varchar(10)
);
这里我们就来插入数据试一试:
insert into student value
(88, '李四'),
(12, '张三');
这里仍然可以插入成功,由此能发现设置了自增主键仍然能自定义值,那么下面如果不自定义 id 的值呢?会自动生成多少呢?
insert into student(name) values('王五');
-- Query OK, 1 row affected (0.00 sec)
select * from student;
+----+--------+
| id | name |
+----+--------+
| 12 | 张三 |
| 88 | 李四 |
| 89 | 王五 |
+----+--------+
-- 3 rows in set (0.00 sec)
注意:这里可以看到,我们插入是 李四,张三,但是查询却是 张三在前李四在后,所以 MySQL 并未保证插入顺序和取出是顺序是一致的!
再者这里可以发现,自增主键插入数据对应字段不给值时,使用最大值+1。那如果我把王五删了,再次插入一条数据,自增主键会是多少呢?
delete from student where name = '王五';
-- Query OK, 1 row affected (0.00 sec)
insert into student(name) values('赵六');
-- Query OK, 1 row affected (0.00 sec)
select * from student;
+----+--------+
| id | name |
+----+--------+
| 12 | 张三 |
| 88 | 李四 |
| 90 | 赵六 |
+----+--------+
-- 3 rows in set (0.00 sec)
看到没!并不是按照当前列的最大值来自增主键的,你可以理解为 MySQL 有个记录主键最大值的玩意,是按照这个之前主键最大值自增的!删除了数据,不影响主键的最大值!
我们再来看一个操作:
insert into student values(null, '孙七');
这个操作并不是插入 null 数据,而是交给数据库使用自增主键!
这里又有一个疑问了,如果数据量太大,一个服务器存不下那么多数据怎么办?那就要采用分库分表的操作了,多台服务器来存储了,本质上就是把一张大表,分成多张小表,每个服务器分别只存一部分大大数据,这就可以理解成分布式处理了,
问题来了,上述这样的情况,还能使用自增主键吗?
这里涉及到一个 "分布式系统中唯一 id 生成算法" ,也就是全局唯一 id,常见的即:
实现公式:时间戳+主机编号+随机因子 => 全局唯一的 id。
当然感兴趣的可以下来进一步了解下,这里就不过多阐述了。
2、FOREIGN KEY
外键约束,说白了就是两个表之间相互约束。
注意:外键是用于关联其他表的主键或唯一键!
foreign key (字段名) references 主表(列)
这里我们举个例子,在学校里,有很多个班级,每个班级里有很多学生,也就是一个学生对应一个班级,一个班级对应多个学生,假设某某学校,只有三个 java 班级,分别是 java1班,java2班,java3班,每个班级又有若干个学生,现在开学了,学生去学校报道, 报道的时候呢会登记你的班级,志愿者一问,同学你哪个班的呀?我说:我 java2 班的,于是顺利登记成功,后面又来了一个同学,同样的问题,同学你哪个班的呀?我 java6班,志愿者一查询,咱学校没有 java6班呀,于是那个同学就被老师带走调查了...
上述只是一个故事,可以把我们自己想象成一条数据,当然登记信息肯定不仅仅是登记班级,还有有 学号 姓名 性别 身份证 班级号... 而这里我们的班级号不是随便哪个都可以的,是有固定的几个班级号,如果这几个班级号中没有你报的班级号,那么你的信息,就录不上去,也就是一个错误的信息。假设这几个班级号放在一起,对应一张班级表,咱们登记登记的信息,对应学生表, 那么就是两张表之间指定字段的约束。
有了上述铺垫,我们就来用代码来理解一下:
● 首先创建一张班级表 classes,id 为主键:
create table classes (
id int primary key,
name varchar(10)
);
这样 classes 班级表就建好了,这里有个问题,为什么 id 要作为主键呢?
答:首先这里的 id 对应班级号,name 是班级名称,而外键是用于关联其他表的主键或唯一键,所以说这里的 id 字段,要不是主键,要不是唯一键。
未来学生表会有一个字段拥有外键属性,来关联这个 classes 的 id 字段!!!
● 创建学生表 student 指定 classId 为外键,关联 classes 表中 id 字段
create table student (
id int,
name varchar(10),
sex varchar(1),
classId int,
foreign key (classId) references classes(id)
);
这段 sql 语句最后一条,foreign key (classId) references classes(id),这条语句表示,将创建的 student 表中 classId 字段作为外键,于 classes 表中 id 字段关联!
这两张表是创建好了,现在得创建数据了,为 classes 表中创建三个班级数据:
insert into classes value
(1, 'java1班'),
(2, 'java2班'),
(3, 'java3班');
这样就能表示有存在了三个班级,分别是 1班,2班,3班,如果接下来我去登记信息,录入的班级在这三个班之中,那就毫无问题:
insert into student values (230115, '篮球哥', '男', 2);
-- Query OK, 1 row affected (0.00 sec)
这里是不是就如同我们上面举例说明的这样,我是 java2 班的,而 classId 录入了一个 2,关联 classes 的 id 字段 2,对应的就是 java2 班。
那如果后来的同学,录入一个 java6 班呢?
insert into student values (230205, '小王', '男', 6);
-- ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`demo`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `classes` (`id`))
那么此处的外键约束的含义,要求了 student 里的 classId 务必要在 classes 表的 id 列中存在!
相信看到这,大家都能明白外键约束的作用了,student 表中的数据,要依赖 classes 表的数据,而 classes 表的数据要对 student 表产生约束力,就像 父亲 对 孩子 有约束力。此处起到约束作用的表我们称为 "父表",被约束的表我们称为 "子表"。
看到这里啊,说白了就是 父表 对 子表 起到了约束作用,限制了约束的字段的取值.
这里我不禁想到一句话,当你在凝视深渊的时候,深渊也在凝视你!
我们表面上看确实是 父表 对 子表 起到约束,但反过来其实 子表 也限制着 父表!
这里我们尝试删除父表中 id 为 2 的数据,也就是删除 java1班:
delete from classes where id = 2;
-- ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`demo`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `classes` (`id`))
发现报错了,其实我们想也能想到,如果真能删除,那子表中 classesId = 2 的那一条数据不就尴尬了吗?那这外键约束建了又像没有建一样,所以就僵住了,显然是不允许这样的情况发生的!
当然 classes 表中 id 为 1 的数据可以删除,因为 子表 并不存在 classId 为 1 的数据嘛:
delete from classes where id = 1;
-- Query OK, 1 row affected (0.00 sec)
问题:可以先建子表再建父表吗?
显然是不行的呀,当你建子表指定外键约束的时候,你父表都没有,怎么建约束?
3、表的设计
表的设计算是一个比较抽象的概念,有了一定经验后,会更好理解,结合后期的项目设计,再来理解表设计,可能会更好,这里就简单介绍下常见设计。
3.1 一对一
比如说我们每个人都有的身份证,每个身份证id,就对应一个人,这就是一对一关系。
这种一对一关系可以如何创建表呢?
● 第一种方案
create table person (
id int primary key,
name varchar(10),
address varchar(50),
sex varchar(1)
);
把身份证id和姓名直接放在一张表里.
● 第二种方案
create table person (
id int primary key,
name varchar(10)
);
create table account (
accountId int primary key,
personName varchar(10),
address varchar(50),
sex varchar(1),
id int,
foreign key (id) references person(id)
);
第二种方案则是身份证号和姓名放在不同的表里,相互关联。
3.2 一对多
这个例子很像我们之前说过的,一个班级有多个学生,一个学生对应一个班级,这里就不在赘述。
3.3 多对多
比如说学校的一门课程,可以被多名学生选修,而一名学生可以选修多门课程,这就是多对多的关系:
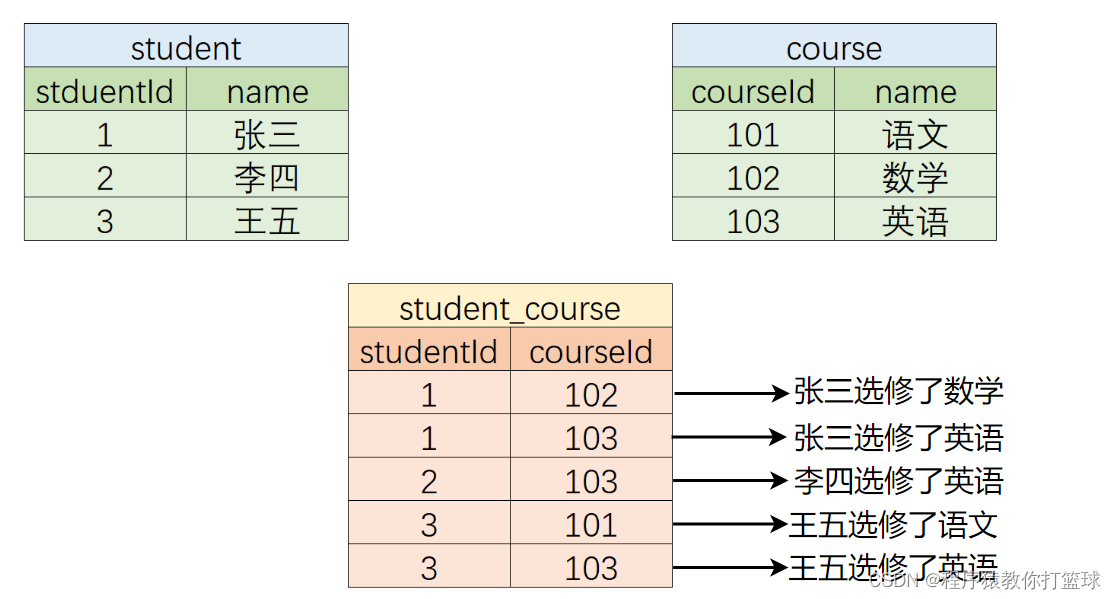
这里我们只需要让 student 表 studentId 字段 约束 student_course 表的 studentId 字段,以及 course 表 courseId 字段约束 student_course 表的 courseId 字段即可。
下期预告:【MySQL】聚合查询
版权归原作者 程序猿教你打篮球 所有, 如有侵权,请联系我们删除。