
一、简介
1、hive建表时存储格式
一般情况下hive在创建表时默认的存储格式是textfile,hive常用的存储格式有五种,textfile、sequencefile、rcfile、orc、parquet。
2、五种存储格式的区别
hive五种存储格式的区别
存储格式文件存储编码格式建表指定textfile
将表中的数据在hdfs上以正常文本的格式存储,下载后可以直接查看。
stored as textfile
sequencefile
将表中的数据在hdfs上以二进制格式编码,并将数据压缩,下载的数据是二进制格式,不可以直接查看,无法可视化。
stored as sequecefilercfile 将表中的数据在hdfs上以二进制格式编码,并且支持压缩。下载后的数据无法可视化。stored as rcfileorc文件存储方式为二进制文件。orc文件格式从hive0.11版本后提供,是RcFile格式的优化版,主要在压缩编码,查询性能方面做了优化。按行组分割整个表,行组内进行列式存储。stored as orcparquet文件存储方式为二进制文件。parquet基于dremel的数据模型和算法实现,列式存储。stored as parquet
textfile利弊:
- 基于行存,每一行就是一条记录。
- 可以使用任意的分隔符进行分割。
- 无压缩,造成存储空间大。
sequencefile利弊:
- 基于行存储。
- sequencefile存储格有压缩,存储空间小,有利于优化磁盘和I/O性能。
- 同时支持文件切割分片,提供了三种压缩方式:none,record,block(块级别压缩效率跟高).默认是record(记录)。
rcfile利弊:
- 行列混合的存储格式,基于列存储。
- 因为基于列存储,列值重复多,所以压缩效率高。
- 磁盘存储空间小,io小。
orc利弊:
- 具有很高的压缩比,且可切分;由于压缩比高,在查询时输入的数据量小,使用的task减少,所以提升了数据查询速度和处理性能。每个task只输出单个文件,减少了namenode的负载压力。
- 在ORC文件中会对每一个字段建立一个轻量级的索引,如:row group index、bloom filter index等,可以用于where条件过滤。
- 查询速度比rcfile快;支持复杂的数据类型;
- 无法可视化展示数据;读写时需要消耗额外的CPU资源用于压缩和解压缩,但消耗较少;
- 对schema演化支持较差;
parquet利弊:
- 具有高效压缩和编码,是使用时有更少的IO取出所需数据,速度比ORC快,其他方面类似于ORC。
- 不支持update和ACID。
- 不支持可视化展示数据。
二、实践操作
下图红框标出的部分是利用hadoop本身InputFormat API从不同的数据源读取数据,OutputFormat API将数据写成不同的格式。所以对于不同的数据源,不同的存储格式就需要不同对应的InputFormat和Outputformat类来实现。
1、textfile
CREATE TABLE teacher(
name string,
age int
)row format delimited fields terminated by ','
stored as textfile;

2、sequencefile
CREATE TABLE teacher01(
name string,
age int
)stored as sequencefile;
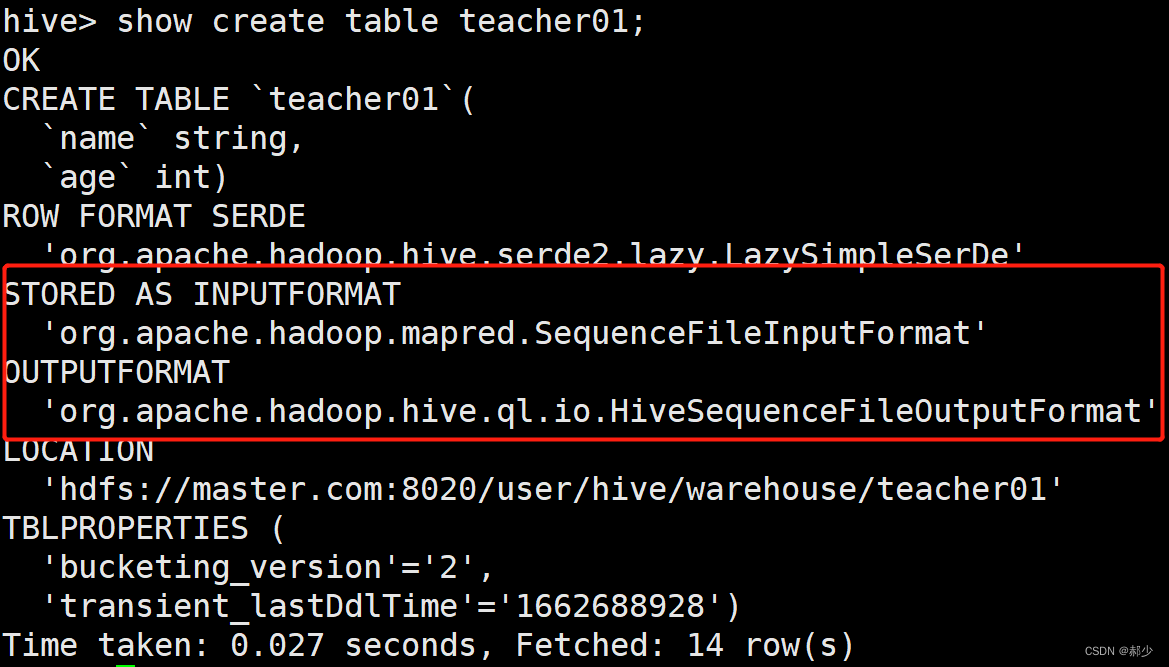
这里没有使用row format delimited fields terminated by ',',是因为没有必要,单纯的load以逗号分隔的文本进去会报错。
FAILED: SemanticException Unable to load data to destination table. Error: The file that you are trying to load does not match the file format of the destination table.
3、rcfile
CREATE TABLE teacher02(
name string,
age int
)stored as rcfile;
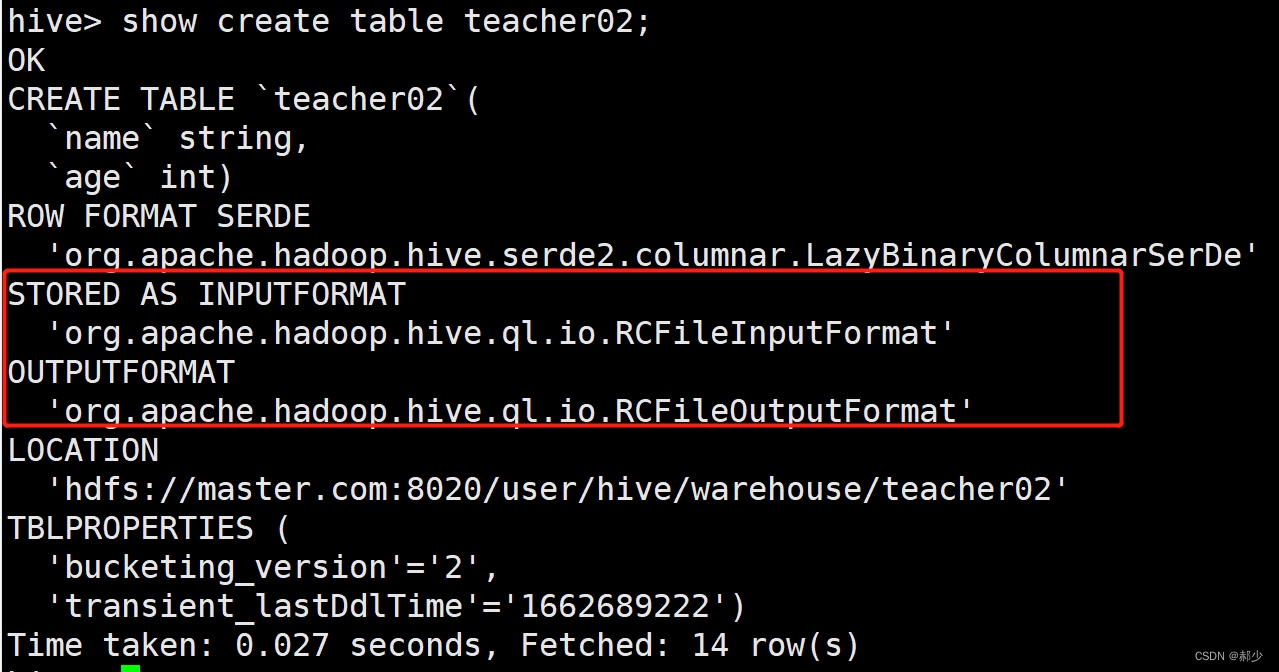
这里也没有使用row format delimited fields terminated by ',',是因为没有必要,单纯的load以逗号分隔的文本进去会报错。
4、orc
CREATE TABLE teacher03(
name string,
age int
)stored as orc;

这里也没有使用row format delimited fields terminated by ',',是因为没有必要,单纯的load以逗号分隔的文本进去会报错。
5、parquet
CREATE TABLE teacher04(
name string,
age int
)stored as parquet;
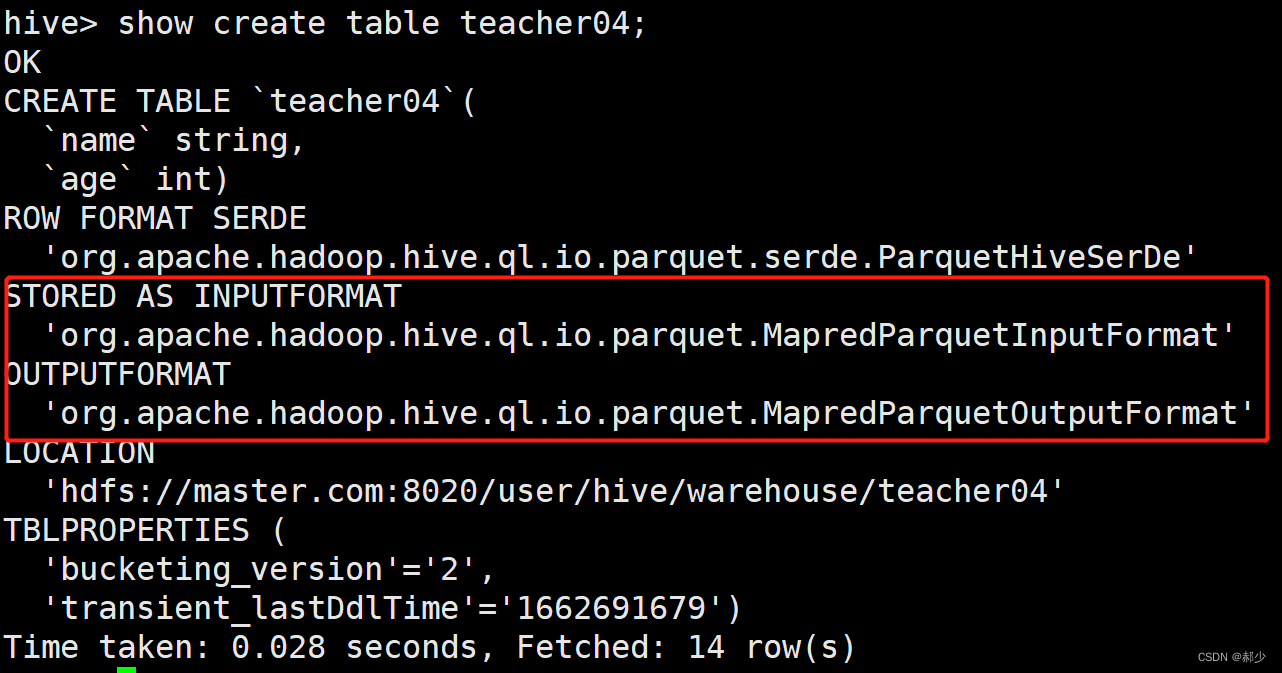
这里也没有使用row format delimited fields terminated by ',',是因为可以load以逗号分隔的文本进去。但是select 查询会报错。
hive> select * from teacher12;
OK
Failed with exception java.io.IOException:java.lang.RuntimeException: hdfs://master.com:8020/user/hive/warehouse/teacher12/teacher.txt is not a Parquet file. expected magic number at tail [80, 65, 82, 49] but found [44, 49, 52, 10]
Time taken: 0.095 seconds
三、适用场景
- 需要查看所存储的具体数据内容的小型查询,可以采用默认文件格式textfile。
- 不需要查看具体数据的小型查询时可使用sequencefile文件格式。
- 当用于大数据量查询时,可以使用rcfile、orc、parquet文件格式,一般情况下推荐使用orc,若字段数较多,不涉及到更新并且需要部分列查询场景多的情况下建议使用parquet。
- 需通过sqoop+hive与关系型数据库交互时,import和export的hive表需要使用textfile格式。如果需要操作的表不是textfile存储格式,需要先insert到textfile格式的表中再操作。
版权归原作者 郝少 所有, 如有侵权,请联系我们删除。