
Hadoop开发是一个针对大规模数据集处理的开源分布式计算框架。以下是关于Hadoop开发的一些关键信息和概念:
一、Hadoop概述
Hadoop是一个开源的分布式计算框架,主要用于处理大规模数据集。它包含两个核心组件:Hadoop Distributed File System (HDFS) 用于存储数据,而 Hadoop MapReduce 用于处理数据。
Hadoop是一个由Apache基金会所开发的开源分布式系统基础架构,用于处理大数据集。Hadoop的灵感来源于Google的MapReduce和Google文件系统(GFS)的论文。Hadoop以其高可靠性、高扩展性、高效性、高容错性和低成本等特性,在大数据领域得到了广泛的应用。
二、Hadoop核心组件
环境准备
- 安装Java:Hadoop是用Java编写的,因此你需要安装Java Development Kit (JDK)。
- 安装Hadoop:从Hadoop官方网站下载并安装Hadoop。
- 配置Hadoop:编辑Hadoop的配置文件(如
core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml),根据你的环境设置相关参数。
Hadoop分布式文件系统(HDFS):HDFS是一个高度容错性的分布式文件系统,它可以将大数据集存储在多个常规服务器上,并通过容错机制来保证数据的可靠性和可用性。HDFS采用主从结构模型,包括一个名称节点(NameNode)和多个数据节点(DataNode)。
Hadoop YARN(Yet Another Resource Negotiator):YARN是一个资源管理系统,它可以将集群中的计算资源分配给各个任务,并监控它们的执行状态。YARN包括ResourceManager和NodeManager两个主要组件,其中ResourceManager负责集群中所有资源的统一管理和分配,而NodeManager则负责节点上资源的监控和管理。
三、Hadoop编程模型
MapReduce是Hadoop的核心编程模型,它将大规模数据集划分成小块,并在集群上并行执行Map和Reduce操作。Map操作将输入数据转换成键值对,而Reduce操作对键值对进行聚合和计算。用户可以使用Java、Python等编程语言来编写MapReduce程序。
编写Hadoop程序
Hadoop程序主要由两个部分组成:Mapper和Reducer。Mapper将输入数据拆分成键值对,然后输出到Reducer。Reducer接收Mapper的输出,对具有相同键的值进行聚合。
示例:
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
以上代码少了配置和提交作业的部分。
编译Hadoop程序
使用Java编译器(如
javac
)编译你的Hadoop程序。确保你的类路径(CLASSPATH)包含了Hadoop的库文件。
打包Hadoop程序
将编译后的类文件打包成一个JAR文件。你可以使用
jar
命令或构建工具(如Maven或Gradle)来完成这个步骤。
提交Hadoop作业
使用
hadoop jar
命令提交你的Hadoop作业到Hadoop集群。你需要指定JAR文件的路径、主类的名称以及输入和输出的HDFS路径。
hadoop jar wordcount.jar WordCount /input /output
在上面的命令中,
wordcount.jar
是你的JAR文件的名称,
WordCount
是你的主类的名称,
/input
是输入数据的HDFS路径,
/output
是输出数据的HDFS路径。
监控和调试
- 监控:使用Hadoop的资源管理器(如YARN ResourceManager)来监控作业的执行情况,包括作业的状态、进度、资源使用情况等。
- 调试:如果作业执行出现问题,可以通过查看日志文件来定位问题。Hadoop会在执行作业的过程中生成大量的日志文件,你可以使用Hadoop提供的命令行工具或第三方工具来查看和分析这些日志文件。优化和扩展。
优化和扩展
优化:根据作业的执行情况和性能瓶颈,对Hadoop程序进行优化。这可能包括调整作业的配置参数、优化Mapper和Reducer的实现、使用更高效的数据结构等。
扩展:Hadoop生态系统提供了许多其他的工具和组件,如Hive、HBase、Pig、Spark等。你可以根据你的需求选择使用这些工具来扩展你的Hadoop应用程序。
官方文档:Hadoop和Hadoop生态系统中的每个组件都有详细的官方文档,包括安装指南、配置说明、API文档等。这些文档是你开发Hadoop程序的重要参考。
教程和示例:有许多在线教程和示例代码可以帮助你快速入门Hadoop开发。你可以通过搜索引擎或GitHub等代码托管平台找到这些资源。
社区支持:Hadoop有一个活跃的社区,你可以通过邮件列表、论坛、Stack Overflow等方式向社区寻求帮助和支持。
四、Hadoop生态系统
Hadoop不仅是一个单一的软件,而是一个由多个相关项目组成的生态系统。除了HDFS和YARN之外,Hadoop生态系统还包括Hive、HBase、Pig、Spark、Flink、Kafka等组件。这些组件相互配合,为Hadoop提供了丰富的数据处理和分析能力。
五、Hadoop开发优势
可扩展性:Hadoop可以在廉价的商用硬件集群上线性扩展,无需昂贵的专用硬件。
容错性:Hadoop通过数据复制和故障转移机制,提供了高可用性和容错能力。
成本效益:Hadoop可以在低成本的商用硬件上运行,降低了大数据处理的成本。
开源:Hadoop是开源软件,可以免费使用和修改,并得到大型社区的支持。
六、Hadoop应用场景
Hadoop的应用非常广泛,包括数据挖掘、日志分析、图像识别、机器学习等领域。例如,在数据挖掘中,Hadoop可以处理海量的用户行为数据,帮助企业进行用户画像和精准营销;在日志分析中,Hadoop可以收集和分析大量的系统日志,帮助企业监控系统的运行状况和发现潜在的安全风险。
七、思维导图
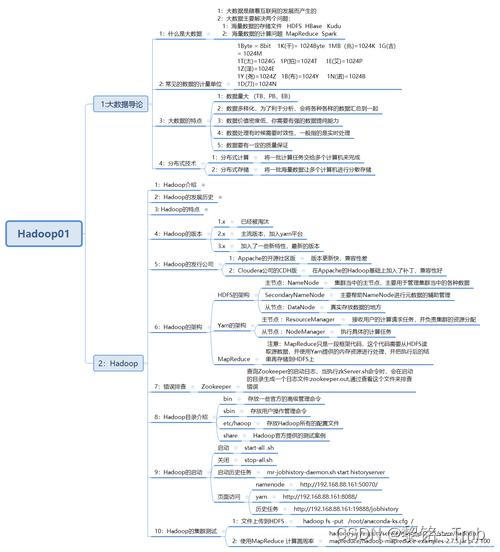
总之,Hadoop开发是一个涉及多个组件和技术的复杂过程,但凭借其强大的数据处理能力和广泛的应用场景,Hadoop已成为大数据领域的核心技术之一。
版权归原作者 黎铭---Tmb 所有, 如有侵权,请联系我们删除。