
一、Kafka Broker工作
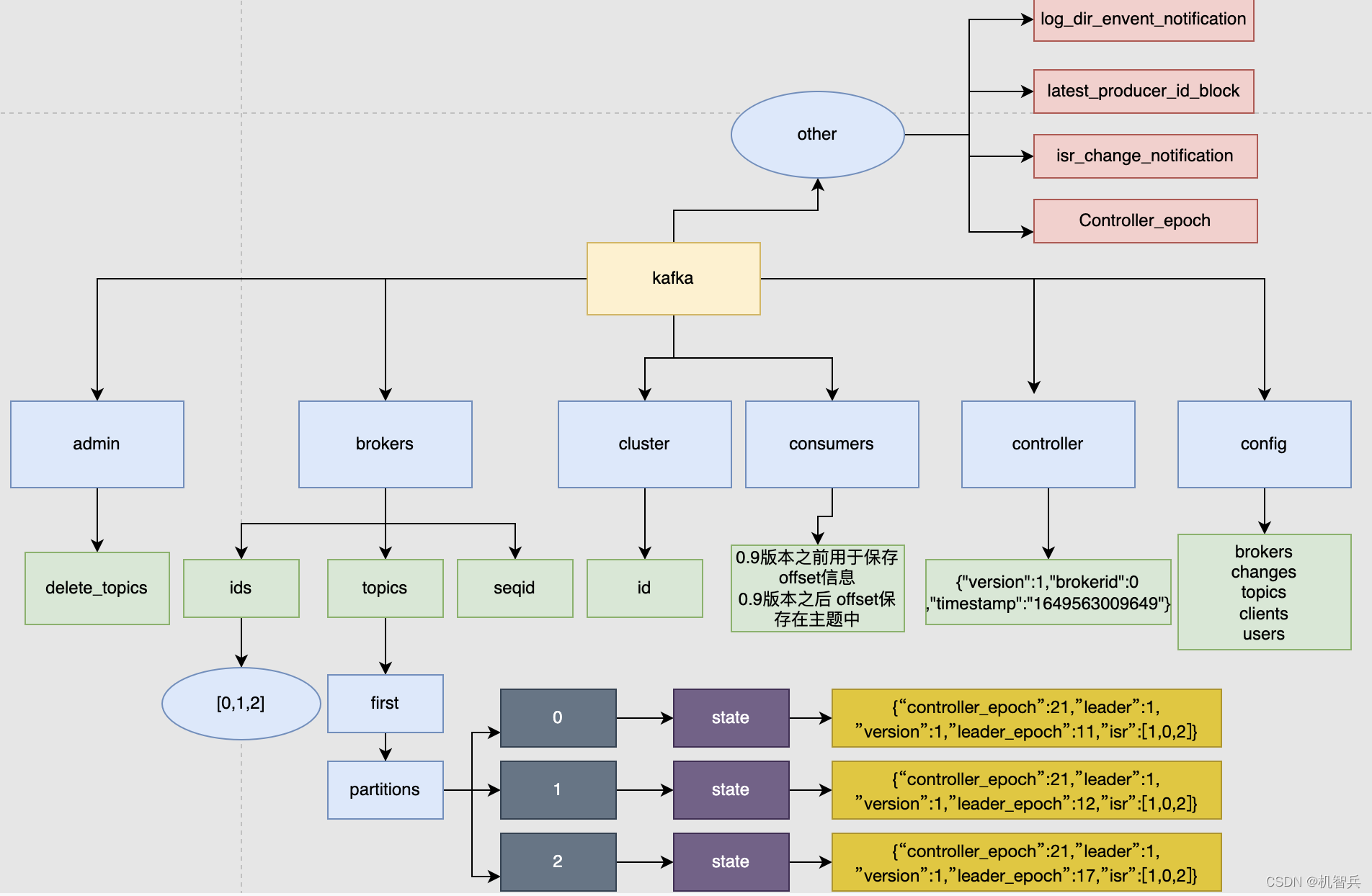
1.1 、zookeeper中存储的kafka信息
在zookeeper的服务器端存储的Kafka相关信息:
- /brokers/ids [0,1,2] 记录有哪些服务器
- /brokers/topics/first/partitions/0/state {"leader":1,"isr":[1,0,2]} 记录谁是Leader,有哪些服务器可用
- /controller {"brokerid":0} 辅助选举Leader
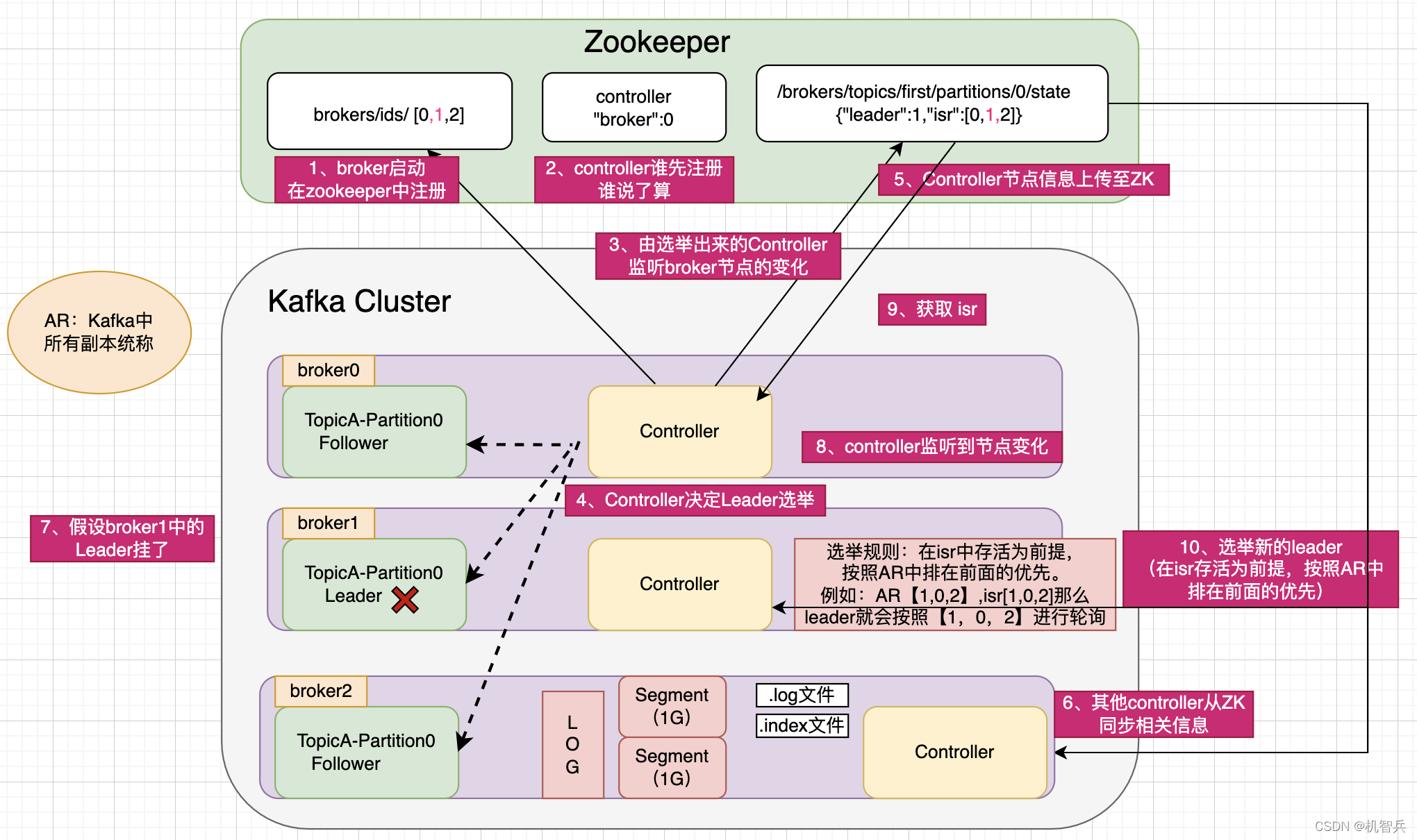
1.2、broker总体工作流程
二、kafka副本
2.1、副本的基本信息
Kafka副本作用:提高数据可靠性
Kafka默认副本1个,生产环境一般配置为2个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上的传输,降低效率。
Kafka中副本分为:Leader 和 Follower。Kafka生产者只会把数据发往Leader,然后Follower找Leader进行同步数据
Kafka分区中的所有副本统称为AR(Assigned Repllicas)
** AR = ISR + OSR**
**ISR**:表示和Leader保持同步的Follower集合,如果Follower长时间未向Leader发送通信请求或者同步数据,则该Follower将被踢出ISR。该时间阈值由**replica.lag.time.max.ms**参数设定,,默认30s。Leader发生故障之后,就会从ISR中选举新的Leader。 **OSR**:表示Follower与Leader副本同步时,延迟过多的副本。
2.2、Leader选举流程
Kafka集群中有一个broker的Cntroller会被选举为Controller Leader,负责管理集群broker的上下线,所有topic的分区副本分配和Leader选举等工作。 **Controller**的信息同步工作是依赖于**Zookeeper**的。选举规则:在ISR中存活为前提,按照AR中排在前面的优先。
例如:AR【1,0,2】、ISR【1,0,2】,那么Leader就会按照【1,0,2】进行轮询产生
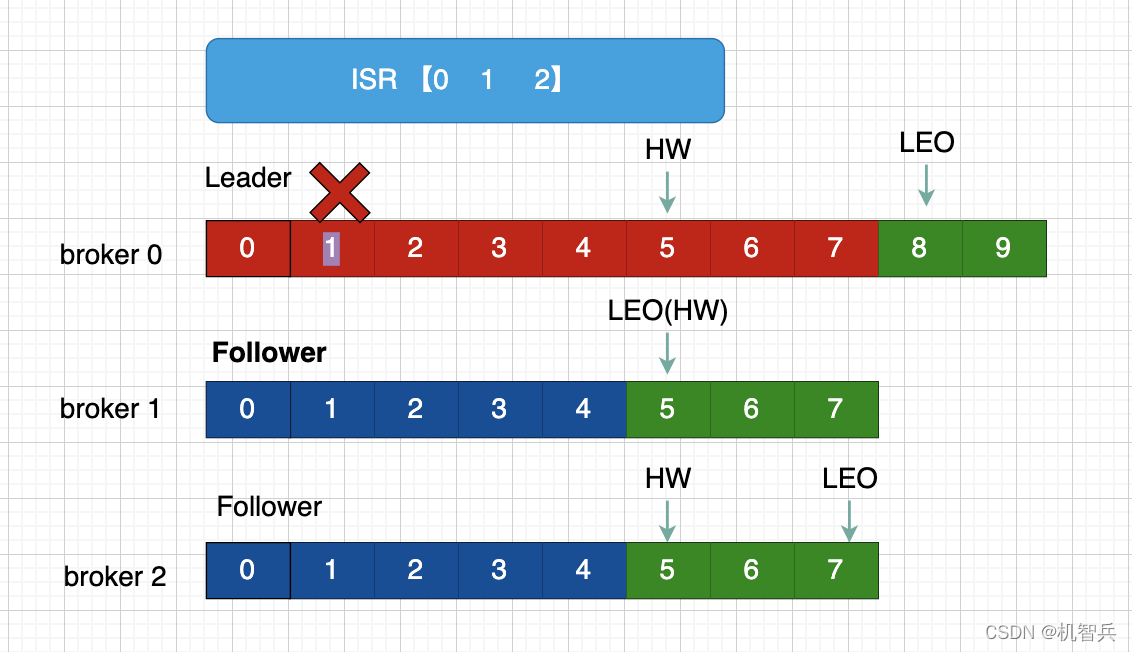
2.3、Leader 和 Follower 故障处理细节
LEO(Log End Offset): 每个副本等最后一个offset,LEO其实就是最新的offset+1
HW(High Watermark) :所有副本中最小的LEO
1、Leader故障处理
Leader发生故障之后,会从ISR中选出一个新的Leader
为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
** 注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不充分**
2、Follower故障处理
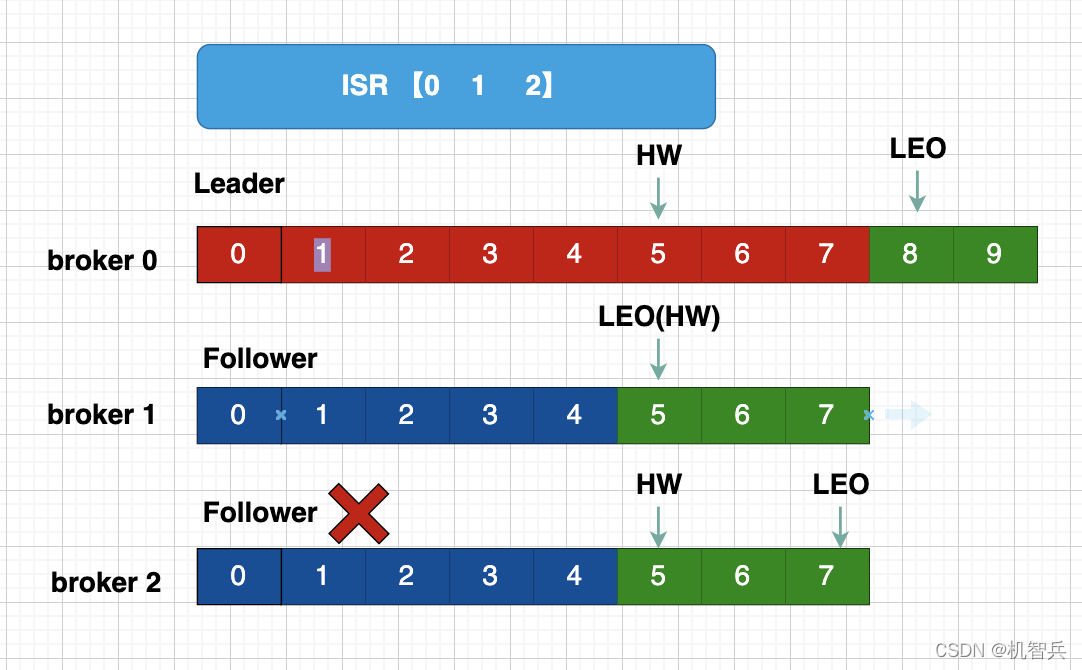
- Follower发生故障后被临时踢出ISR
- 这个期间Leader 和Follower继续接收数据
- 待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步
- 等该Follower的LEO大于该Partition的HW,即Follower追上Leader之后,就可以重新加入ISR了。
标签:
java
本文转载自: https://blog.csdn.net/a6470831/article/details/124076172
版权归原作者 机智兵 所有, 如有侵权,请联系我们删除。
版权归原作者 机智兵 所有, 如有侵权,请联系我们删除。