
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀**对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于卷积神经网络的古诗词生成系统
设计思路
一、课题背景与意义
古诗作为中华文化的重要组成部分,传统的古诗创作需要高水平的文学素养和诗词鉴赏能力。然而,随着人工智能技术的发展,利用自然语言处理和生成模型如BERT等,可以开发出能够自动生成符合古诗规律和风格的诗句的古诗生成器。这样的生成器可以为创作者提供创作灵感和辅助工具,帮助普通读者欣赏和接触古诗,促进古诗的传承和传播,以及在教育领域辅助教师进行古诗教学。
二、算法理论原理
2.1 深度学习
BERT模型在古诗生成系统中通过丰富的上下文理解能力和长距离依赖建模,能够生成准确、流畅的古诗作品。同时,BERT模型的多样性和创新性使得生成的古诗更具个性和创意,满足不同用户的需求和口味。此外,它还推动了文学研究领域的发展,通过生成大量的古诗作品,为文学特征和演变的分析提供支持,加深了对古代文学的理解。综上所述,BERT模型的应用为古诗创作和文学研究带来了新的可能性和进展。
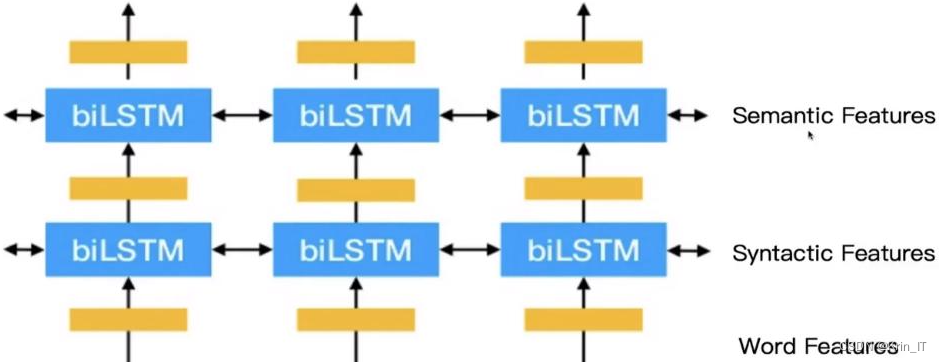
BERT模型可以使用两种策略来应对不同的任务和应用场景:
- Fine-tuning(微调)策略:首先使用大规模无监督的预训练数据对BERT模型进行预训练,学习通用的语言表示。然后,将预训练的BERT模型用于特定任务时,通过在少量标注数据上进行有监督的微调,将模型参数调整到与特定任务相关的特征上。这种策略适用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。通过微调,BERT模型可以适应不同任务的特定特征和语境。
- Feature-based(基于特征)策略:在某些场景下,微调整个BERT模型的代价较高,或者只希望利用BERT模型的表示能力而不改变模型架构。在这种情况下,可以使用基于特征的策略。该策略通过在预训练的BERT模型之上构建新的模型,将BERT的输出作为输入特征,并在其基础上进行后续的任务建模和训练。例如,可以将BERT的输出作为输入,连接到一个全连接层或其他特定任务的模块,然后进行目标任务的训练和推断。这种策略在需要灵活调整模型结构或在计算资源有限的情况下很有用。
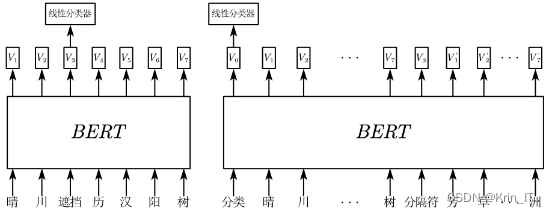
2.2 神经网络
卷积神经网络(CNN)在古诗生成系统能够通过层级特征提取捕捉古诗的字、词、句子结构和模式,生成准确而富有语言感的古诗作品。CNN的并行计算能力使得处理大规模数据更加高效,提高了生成速度和实时性。其局部感知能力帮助理解古诗中字、词之间的依赖关系和语义规律,生成连贯自然的古诗。数据共享和参数共享机制减少了过拟合风险,提高了模型的泛化能力。此外,CNN的可解释性使得开发者和研究人员能够理解和优化模型的行为。

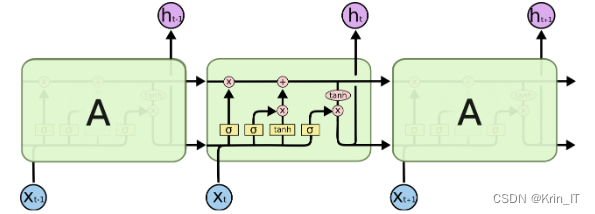
LSTM(长短期记忆网络)在古诗生成系统中具有显著的优势。其主要优点包括:
- 对长距离依赖关系的建模能力,使得LSTM能够捕捉古诗中的上下文信息,生成具有连贯性和一致性的古诗作品;
- 对输入文本的序列特征进行建模,有助于理解和学习古诗中的节奏、韵律和语言结构,生成更加韵味悠长的古诗;
- 具有记忆单元和遗忘门机制,可以有效地处理输入序列的长期依赖和信息传递,帮助LSTM模型更好地捕捉古诗中的语义和情感;
- 能够适应不同长度的输入序列,使得LSTM在处理古诗生成任务时更具灵活性和适应性。
相关代码示例:
# 构建LSTM模型
model = Sequential()
model.add(LSTM(128, input_shape=(X.shape[1], X.shape[2])))
model.add(Dense(len(chars), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# 训练模型
model.fit(X, y, epochs=50, batch_size=128)
# 使用模型生成古诗
start = np.random.randint(0, len(sequences)-1)
seed_seq = sequences[start]
generated_poem = ''.join([indices_char[value] for value in seed_seq])
for _ in range(100):
x = np.reshape(seed_seq, (1, sequence_length, 1))
x = x / float(len(chars))
prediction = model.predict(x, verbose=0)
index = np.argmax(prediction)
result = indices_char[index]
generated_poem += result
seed_seq.append(index)
seed_seq = seed_seq[1:]
print(generated_poem)
SSD模型是一种多尺度的特征提取模型,用于定位图像中特定物体的位置和类别。它接受三通道彩色图像作为输入,也可以使用灰度图像进行训练。模型首先使用传统的VGG模型对整个图像进行特征提取,然后添加五层尺度不同的卷积层来辅助特征提取。每个卷积层都将图像划分为固定大小的格子,并在每个格子内设置多个不同大小的检测框。这样的设置确保在后续的特征提取过程中,只需在预定义的检测框内提取特征,而无需使用穷举法来检测特征,从而显著提高计算速度。每个检测框中提取的信息经过非极大值抑制(NMS)算法,得到正负样本比例为1:3的数据作为模型的输出。然后,将这些输出与其他层的输出一起进行分类和回归计算,得到最终框的位置信息和框内物体的信息。
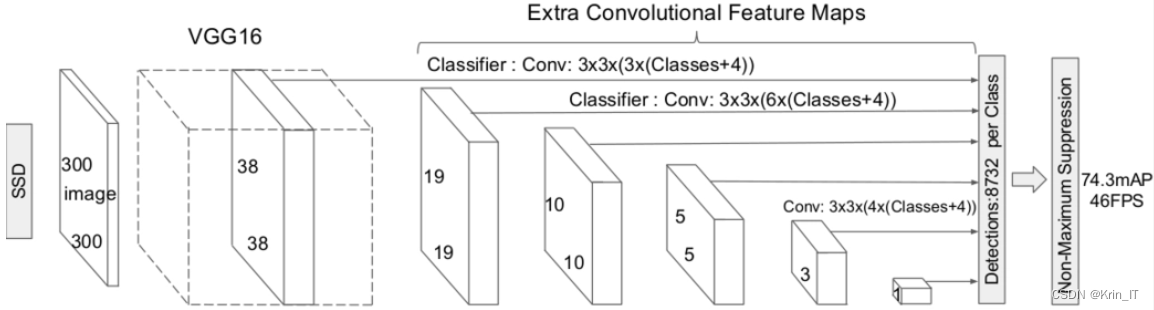
通过使用SSD模型进行目标检测,我们可以从图片中获取机器作诗所需的关键词。作诗模型可以从花鸟和景物中判断出船和鸟等目标,从而作为待生成作品的主题,并根据目标检测结果进行艺术创作。这种方法通过阅读图像增加了机器对图片的理解和认知能力,并且计算机可以识别多种目标对象。然而,在古典诗词中没有出现的现代物品和生活方式(如汽车、飞机、街舞等新词),由于缺乏足够的训练样本,作诗模型在生成效果上可能会受到一定影响。因此,推荐使用风景类和花鸟动物类的图片进行SSD目标识别。

在机器作诗中,需要探索其他方法来生成高质量的关键词。这可能涉及到更深入的文本分析和理解,结合诗歌的结构和意境,以及对诗歌风格和情感的把握。这样的尝试和改进将有助于提高机器作诗的质量和艺术性。
相关代码示例:
import torch
from torchvision import transforms
from torchvision.models import vgg16
from torchvision.models.detection import ssdlite320_mobilenet_v3_large
# 加载预训练的SSD模型和VGG模型
ssd_model = ssdlite320_mobilenet_v3_large(pretrained=True)
vgg_model = vgg16(pretrained=True)
# 设置模型为评估模式
ssd_model.eval()
vgg_model.eval()
# 定义图片预处理的转换
transform = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载图像
image = Image.open('image.jpg')
# 进行图像预处理
image_tensor = transform(image).unsqueeze(0)
# 使用VGG模型提取特征
features = vgg_model.features(image_tensor)
# 使用SSD模型进行目标检测
with torch.no_grad():
detections = ssd_model(features)
# 获取预测结果
boxes = detections[0]['boxes']
labels = detections[0]['labels']
scores = detections[0]['scores']
三、检测的实现
3.1 数据集
为了解决低频词在训练集中的不足,采用了基于词向量相似度的方法来扩展训练集。对于高频词,直接选取含有该词的古诗四联句作为标签;对于低频词,通过计算词向量相似度,选取与该词最相似的一组词作为标签。此外,为了确定每个关键词应匹配的标签数量,提出了一种选取阈值的方法。该方法旨在尽可能扩展低频词的相关诗句,并提高低频词与簇生词之间的相似度。
通过构建句关键词数据集,利用词向量相似度来扩展训练集,对高频词直接选取含有该词的古诗四联句作为标签,对低频词通过计算词向量相似度选取与该词最相似的一组词作为标签。同时,提出了一种选取阈值的方法来确定每个关键词应匹配的标签数量,以尽可能扩展低频词的相关诗句并提高低频词与簇生词之间的相似度。这样的模型能够生成更准确、连贯的古诗四联句,并考虑了词语的上下文信息和语义相似度。

import imgaug.augmenters as iaa
import cv2
import os
# 图像增强器
augmenter = iaa.Sequential([
iaa.Fliplr(0.5), # 左右翻转概率为0.5
iaa.Affine(rotate=(-45, 45)), # 旋转角度范围为-45到45度
iaa.Resize({"height": 300, "width": 300}) # 缩放图像到300x300像素
])
# 图像增强函数
def augment_image(image):
augmented_image = augmenter.augment_image(image)
return augmented_image
# 数据集路径import gensim
from sklearn.metrics.pairwise import cosine_similarity
# 加载预训练的词向量模型
word2vec_model = gensim.models.KeyedVectors.load_word2vec_format('word2vec_model.bin', binary=True)
# 定义训练集中的低频词
low_frequency_words = ['低频词1', '低频词2', '低频词3']
# 定义阈值,用于确定每个关键词应匹配的标签数量
threshold = 0.8
# 扩展训练集中的低频词
expanded_train_data = []
for word in low_frequency_words:
# 计算低频词与训练集中所有词的相似度
similarities = word2vec_model.similarity(word, train_data)
# 根据相似度选择与低频词最相似的一组词作为标签
similar_words = [train_data[i] for i in range(len(train_data)) if similarities[i] > threshold]
# 将低频词和其对应的标签添加到扩展后的训练集中
expanded_train_data.append((word, similar_words))
# 打印扩展后的训练集
for word, labels in expanded_train_data:
print('Word:', word)
print('Labels:', labels)
print('----------------------')
dataset_path = "/path/to/dataset"
# 遍历数据集图像文件
for filename in os.listdir(dataset_path):
if filename.endswith(".jpg"):
image_path = os.path.join(dataset_path, filename)
# 读取图像
image = cv2.imread(image_path)
# 进行图像增强
augmented_image = augment_image(image)
# 保存增强后的图像
augmented_image_path = os.path.join(dataset_path, "augmented_" + filename)
cv2.imwrite(augmented_image_path, augmented_image)
3.2 实验环境搭建

3.3 模型训练
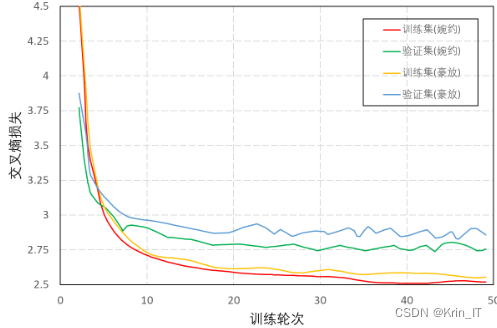
提出了一种改进的Seq2Seq模型,用于生成中文古典诗词。传统的Seq2Seq模型在处理古诗任务时存在连贯性问题,但改进后的模型通过引入注意力机制和一维卷积神经网络,解决了这个问题。模型采用了Transformer的自注意力机制来提取序列特征,并且能够并行训练以提高效率。最终,该模型能够生成具有较好连贯性的古诗词序列。
使用了标注的豪放派七言绝句古诗数据集(2509首)和婉约派七言绝句数据集(3091首)作为训练数据。训练集和验证集按照7:3的比例进行划分。词向量选用了BERT模型训练的200维词向量,自注意力机制使用了4个头,隐层维度为256维,前馈网络维度为128维。编码器模块堆叠了3层,解码器的参数与编码器一致。损失函数采用了交叉熵损失(categorical_crossentropy),输入尺寸的batch_size为64,训练轮数为50。
相关代码示例:
import torch
from transformers import BertTokenizer, BertForMaskedLM
def generate_poem(prompt, num_lines):
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForMaskedLM.from_pretrained('bert-base-chinese')
# 将输入文本编码为BERT模型所需的输入张量
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors='pt')
# 使用BERT模型生成古诗
with torch.no_grad():
outputs = model.generate(input_ids, max_length=num_lines*2, num_return_sequences=1, do_sample=True)
generated_poem = tokenizer.decode(outputs[0], skip_special_tokens=True)
poem_lines = generated_poem.split('\n')[:num_lines]
return poem_lines
# 示例使用
prompt = "白日依山尽,黄河入海流。"
num_lines = 4
generated_poem = generate_poem(prompt, num_lines)
for line in generated_poem:
print(line)
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/qq_37340229/article/details/135630247
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。