
Elasticsearch 中有四种基本的数据操作。 每个操作都有自己的资源需求。每个用例都使用这些操作,但它们会优先于某些操作。
- Index:在这里被用做动词,而不是其名词索引。处理文档并将其存储在索引中以供将来检索。
- Delete:从索引中删除文档。
- Update:删除文档并索引替换文档。
- Search:从一个或多个索引中检索一个或多个文档或聚合。
在今天的文章中,我将详述上面的几个基本操作。
Elasticsearch 架构
如果你对 Elasticsearch 还不是很熟悉的话,我建议你可以先去读一下我之前的文章:
- Elasticsearch 简介
- Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica
简单地说,一个 Elasticsearch 的集群由如下的部分组成:
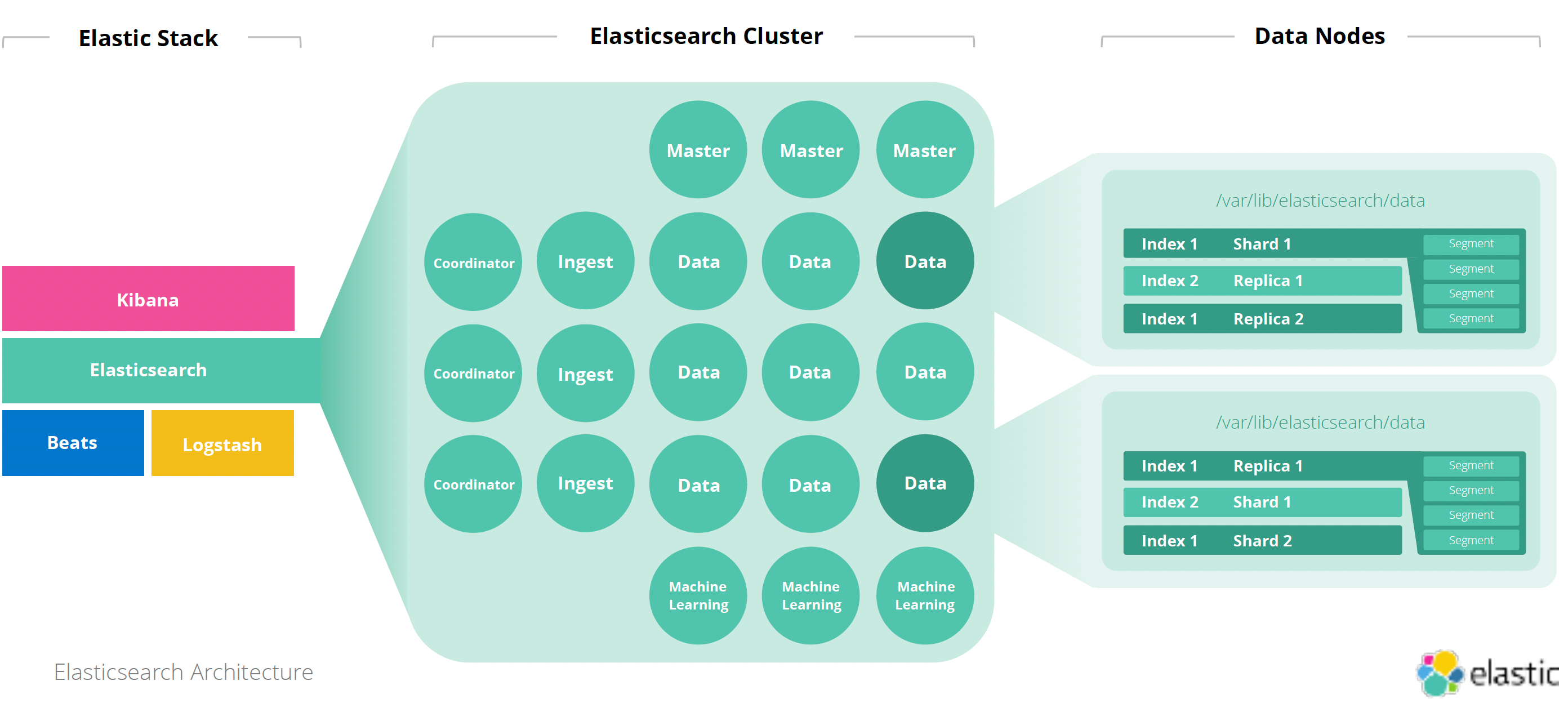
如上所示,Elastic Stack 由 Elasticsearch,Kibana,Beats 及 Logstash 来组成。用一句话来描述,Kibana 是用来可视化及搜索 Elasticsearch 的数据,管理及监控 Elasticsearch 集群,发送通知等。它是 Elastic Stack 的窗口。你可以进一步阅读文章 “Kibana:如何开始使用 Kibana” 以了解更多。 Elasticsearch 是一个大数据的搜索及分析引擎。Beats 及 Logstash 是被用来把数据写入到 Elasticsearch 中的工具。最新的 Elastic Stack 建议使用 Elastic Agent 来作为数据摄入的方式:
有关上面的节点的描述:
- Data:索引、存储和搜索数据
- Master:管理集群状态
- Ingest:转换摄入数据
- Machine learning:处理机器学习模型
- Coordinator:委托请求并合并搜索结果。通常由不担任任何角色的节点来担当,尽管也可以由 data, master,ingest 及 machine learning 节点来担当。
有关这些节点的具体描述,请参阅我之前的文章 “ Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”
了解 Elasticsearch index 数据流

上图显示了文档被索引到 Elasticsearch 集群时的数据流。 它包括以下基本步骤:
1)步骤1:客户端发出将文档放入集群的请求,集群中的协调器节点接受请求进行处理。
2)第 2 步:协调器节点使用索引请求中的管道(pipeline)参数来检查文档是否需要在路由到数据节点进行进一步处理之前进行丰富或转换。
如果答案为否,文档将被路由到集群中的数据节点。 如果答案为是,文档将被路由到集群中的摄取节点(ingest node)以丰富文档。 丰富过程完成后,摄取节点继续将丰富的文档路由到数据节点。
集群中哪个数据节点将进一步处理文档的决定是基于索引的分片信息和哈希模公式:
shard = hash(routing) % number_of_shards
从上面的公式中可以看出来,如果 number_of_shards 改变了,那么得出来的 shard 值也会改变。这也是为啥我们在创建一个索引之后,不能修改 number_of_shards 这个参数。一旦 number_of_shards 被修改了之后,我们必须通过 reindex 的方式写入另外一个索引来进行搜索和查询。
3)第三步:数据节点将文档解析为 JSON 对象,然后检查对象中是否有任何文本值。 如果找到文本值,就会涉及文本分析过程。 它分析文本并将其分解为更有用的结构组件。 它还应用一些处理来使文档与全文搜索更相关。 最后,文档被添加到内存缓冲区并附加到事务日志(translog)。
当缓冲区填满时,文档被写入一个段,然后缓冲区被清除。 同时,事务日志仍然保留文档,直到它变得足够大,执行完整提交。 文档永久刷新到磁盘,旧的事务日志被删除并创建新的。关于这个部分的描述,你可以阅读我之前的文章 “Elasticsearch:Elasticsearch 中的 refresh 和 flush 操作指南”。
如果启用复制,则触发复制数据过程。 该数据节点向包含索引副本分片的数据节点发送复制请求。 此处的整个索引过程将在该节点上完成以创建这些文档的副本。
更为详细的描述,请参阅我的另外一篇文章 “Elasticsearch:索引数据是如何完成的”。
了解 Elasticsearch 搜索数据流
搜索是信息检索的通用术语。 Elasticsearch 提供各种检索功能,包括全文搜索、地理搜索、范围搜索、脚本搜索和聚合。你可以阅读文章 “开始使用 Elasticsearch (2)”。
Elasticsearch 如何在幕后执行搜索查询? 下图显示了搜索操作的数据流。

Elasticsearch 在非正式称为 scatter、search、gather 和 merge 的阶段执行搜索。
1)第一阶段:scatter
客户端向集群发出搜索请求,集群中的协调器节点接受请求进行处理。 基于索引的信息,协调器节点将搜索请求路由到包含索引数据的所有数据节点。
2)第 2 阶段:search
在第一阶段接收到搜索请求的每个数据节点解析请求以检查搜索查询中的任何查询子句是否需要应用文本分析过程。 如果是,文本分析处理开始。 最后,数据节点在索引分片的每个段上执行搜索请求。有关文本分析,请详细阅读我的另外一篇文章 “Elasticsearch: analyzer”。
3)第 3 阶段:gather 和 merge
第一阶段 中的协调器节点从将搜索请求路由到的所有数据节点收集搜索结果。 收集处理完成后,合并处理开始。 它对搜索结果进行合并、排名和排序,然后将它们返回给客户端。
当用户针对 Elasticsearch 调用搜索查询时,会发生很多事情。 尽管我们之前谈到了机制,下图显示了引擎如何在后台执行搜索的机制。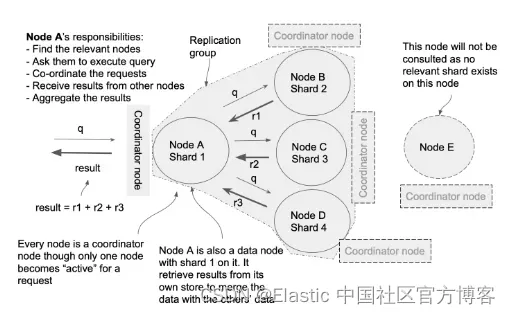
典型的搜索请求和搜索工作原理
特别指明:在上面,我们表明 Node A 是一个数据节点,但是针对大型的 Elasticsearch 集群来说,我们更希望有单独的不含有任何角色的节点来担当这些 coordinator 节点。
当从用户或客户端接收到搜索请求时,引擎将该请求转发到集群中的一个可用节点。 默认情况下,集群中的每个节点都分配有协调器(coordinator)角色; 因此,使每个节点都有资格在循环的(round-robin)基础上接收客户端请求。 一旦请求到达协调器(cooridnator)节点,它就会确定相关文档的分片所在的节点。
在上图中,节点A是协调节点,它接收来自客户端的请求。 它被选为协调器节点,除了演示目的外没有任何特定原因。 一旦它被选为(协调者)活动角色,它就会在由数据组成的集群中的各个节点上创建一个复制组,其中包含一组分片和副本。 请记住,索引由分片组成,每个分片都可以独立存在于其他节点上。 在我们的示例中,索引由四个分片组成:分片 1 到 4 分别存在于节点 A 到 D 上。
然后节点 A 制定查询请求发送给其他节点,请求它们执行搜索。 收到请求后,相应节点会在其分片上执行搜索请求。 然后它提取最上面的一组结果并用结果响应活动的协调器。 然后活动协调器(coordinator)合并数据并对其进行排序,然后将其作为最终结果发送给客户端。
如果协调器具有数据节点(data node)的角色,它也会挖掘自己的存储来获取结果。 并非每个接收到请求的节点都一定是数据节点(事实上,针对大的集群,它会有专有的不含任何角色的 coordinator 节点来接受请求)。 同样,并非每个节点都应成为此搜索查询的复制组的一部分。
了解 Elasticsearch 删除数据流
如何从 Elasticsearch 中删除文档? 下图显示了删除单个文档的幕后数据流。
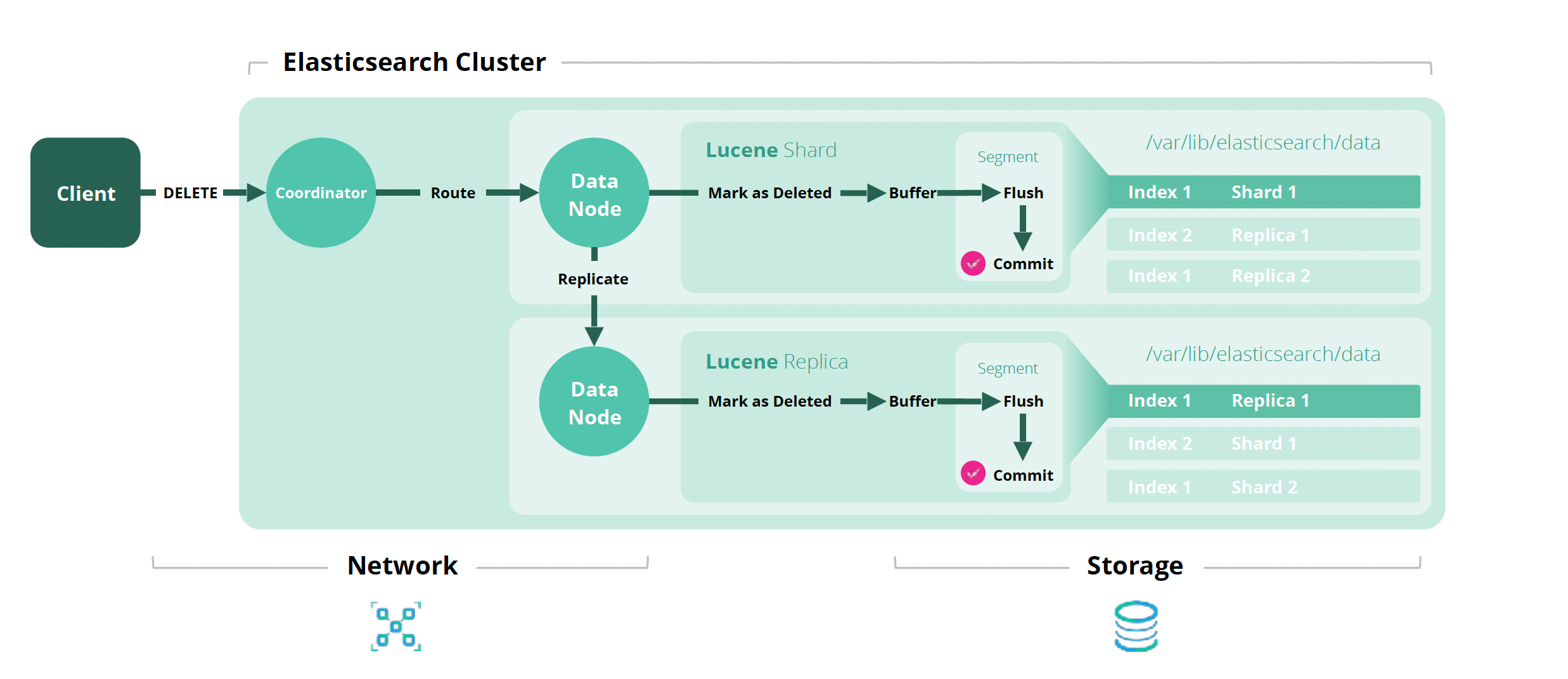
1)步骤1:客户端发出从集群中删除文档的请求,集群中的协调节点接受请求进行处理。
2)第 2 步:基于分片信息和文档 ID,协调节点将删除请求路由到包含存储文档的主分片的数据节点。
3)第 3 步:数据节点不会立即删除文档,它会将文档标记为已删除,然后将其添加到内存缓冲区并将其追加到事务日志(translog)中。 此时,文档是不可搜索的。
当缓冲区填满时,changes 将写入段并且缓冲区被清除。 同时,事务日志仍然保留已删除的文档,直到它变得太大,执行完整提交。 更改被刷新到磁盘,文档被永久删除。
如果为索引启用了复制,则复制数据进程开始。 该数据节点将删除请求发送到包含索引副本分片的数据节点。 此处的整个删除过程将在该节点上完成,以将文档从副本分片中完全删除。
了解 Elasticsearch 更新数据流
Elasticsearch 中的文档是不可变的。 当 Elasticsearch 更新文档时,它会删除原始文档并为新的、更新的文档编制索引。 这两个操作在每个 Lucene 分片中以原子方式执行。这会产生 delete 和 index 操作的成本,但它不会调用任何摄取管道。
我们可以描述 update 数据流为如下的操作:
Update = Delete + (Index - Ingest Pipeline)
好了,今天的文章就写到这里。希望你对 Elasticsearch 的数据操作有一个基本的了解。 这对以后如何提高索引速度,提高搜索速度提供一个良好的理解基础。更多关于如何优化这方面的文章,请详细阅读文章
- Elasticsearch:增加 Elasticsearch 写入吞吐量和速度的完整指南
- Elasticsearch:如何提高查询性能
- Elasticsearch:如何提高 Elasticsearch 数据摄入速度
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。