
🔎这里是【JAVA·面试题】,关注我学习JAVA不迷路
👍如果对你有帮助,给博主一个免费的点赞以示鼓励
欢迎各位🔎点赞👍评论收藏⭐️
👀专栏介绍
【JAVA·面试题】 该专栏主要更新JAVA面试题,题目来源于牛客网。牛客网里面除了最新出来的JAVA面试题还有其他热门语言的经典面试题,有兴趣的朋友可以去看看。
牛客刷题网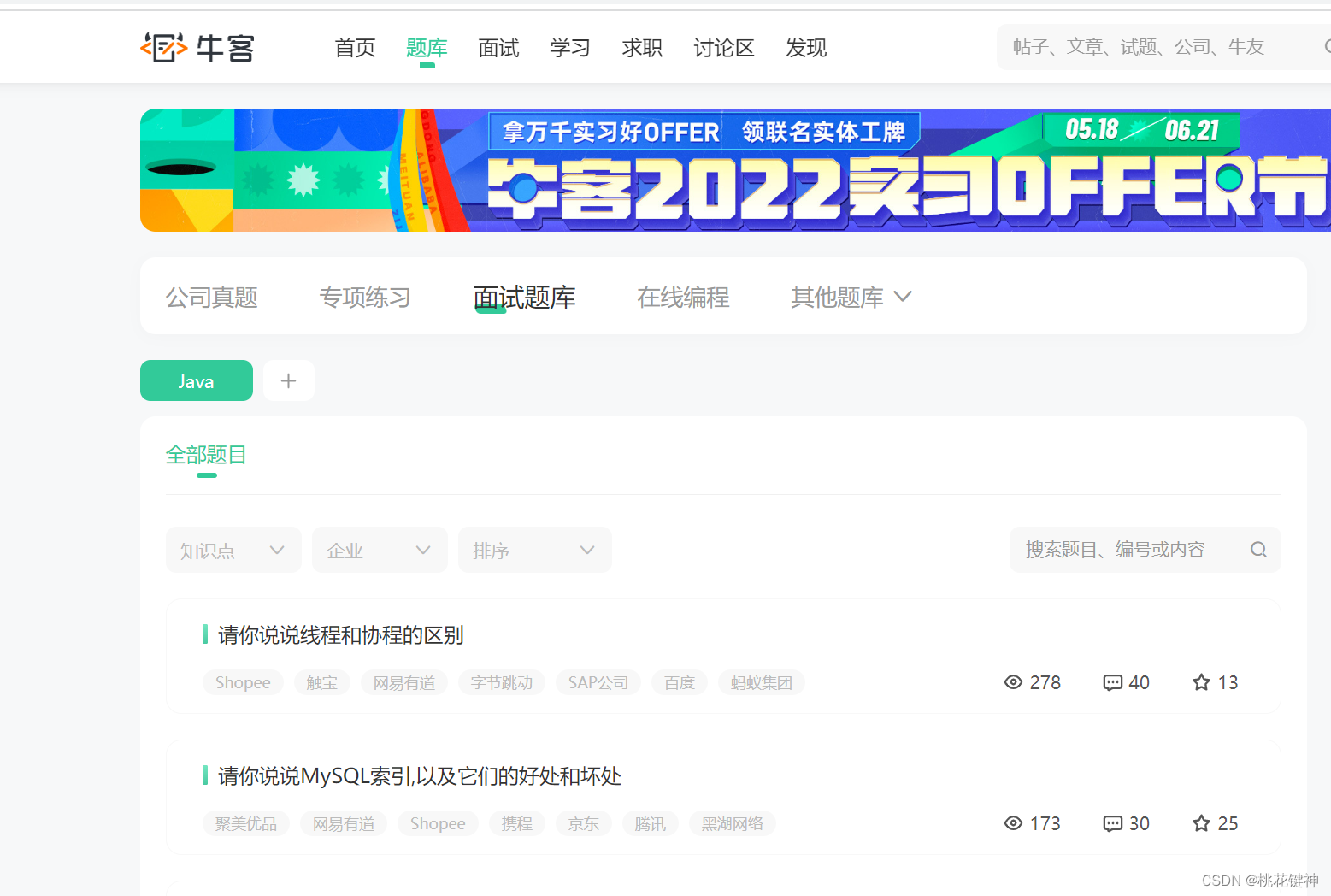
文章目录
请你说说多线程
思路:
得分点 线程和进程的关系、为什么使用多线程 标准回答 线程是操作系统调度的最小单元,它可以让一个进程并发地处理多个任务,也叫轻量级进程。所以,在一个进程里可以创建多个线程,这些线程都拥有各自的计数器、堆栈、局部变量,并且能够共享进程内的资源。由于共享资源,处理器便可以在这些线程之间快速切换,从而让使用者感觉这些线程在同时执行。 总的来说,操作系统可以同时执行多个任务,每个任务就是一个进程。进程可以同时执行多个任务,每个任务就是一个线程。一个程序运行之后至少有一个进程,而一个进程可以包含多个线程,但至少要包含一个线程。 使用多线会给开发人员带来显著的好处,而使用多线程的原因主要有以下几点:
- 更多的CPU核心 现代计算机处理器性能的提升方式,已经从追求更高的主频向追求更多的核心发展,所以处理器的核心数量会越来越多,充分地利用处理器的核心则会显著地提高程序的性能。而程序使用多线程技术,就可以将计算逻辑分配到多个处理器核心上,显著减少程序的处理时间,从而随着更多处理器核心的加入而变得更有效率。
- 更快的响应时间 我们经常要针对复杂的业务编写出复杂的代码,如果使用多线程技术,就可以将数据一致性不强的操作派发给其他线程处理(也可以是消息队列),如上传图片、发送邮件、生成订单等。这样响应用户请求的线程就能够尽快地完成处理,大大地缩短了响应时间,从而提升了用户体验。 3. 更好的编程模型 Java为多线程编程提供了良好且一致的编程模型,使开发人员能够更加专注于问题的解决,开发者只需为此问题建立合适的业务模型,而无需绞尽脑汁地考虑如何实现多线程。一旦开发人员建立好了业务模型,稍作修改就可以将其方便地映射到Java提供的多线程编程模型上。
说说怎么保证线程安全
思路:
得分点 原子类、volatile、锁 标准回答 Java保证线程安全的方式有很多,其中较为常用的有三种,按照资源占用情况由轻到重排列,这三种保证线程安全的方式分别是原子类、volatile、锁。 JDK从1.5开始提供了java.util.concurrent.atomic包,这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。在atomic包里一共提供了17个类,按功能可以归纳为4种类型的原子更新方式,分别是原子更新基本类型、原子更新引用类型、原子更新属性、原子更新数组。无论原子更新哪种类型,都要遵循“比较和替换”规则,即比较要更新的值是否等于期望值,如果是则更新,如果不是则失败。 volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的“可见性”,从而可以保证单个变量读写时的线程安全。可见性问题是由处理器核心的缓存导致的,每个核心均有各自的缓存,而这些缓存均要与内存进行同步。volatile具有如下的内存语义:当写一个volatile变量时,该线程本地内存中的共享变量的值会被立刻刷新到主内存;当读一个volatile变量时,该线程本地内存会被置为无效,迫使线程直接从主内存中读取共享变量。 原子类和volatile只能保证单个共享变量的线程安全,锁则可以保证临界区内的多个共享变量的线程安全,Java中加锁的方式有两种,分别是synchronized关键字和Lock接口。synchronized是比较早期的API,在设计之初没有考虑到超时机制、非阻塞形式,以及多个条件变量。若想通过升级的方式让它支持这些相对复杂的功能,则需要大改它的语法结构,不利于兼容旧代码。因此,JDK的开发团队在1.5新增了Lock接口,并通过Lock支持了上述的功能,即:支持响应中断、支持超时机制、支持以非阻塞的方式获取锁、支持多个条件变量(阻塞队列)。 加分回答 实现线程安全的方式有很多,除了上述三种方式之外,还有如下几种方式: 1. 无状态设计 线程安全问题是由多线程并发修改共享变量引起的,如果在并发环境中没有设计共享变量,则自然就不会出现线程安全问题了。这种代码实现可以称作“无状态实现”,所谓状态就是指共享变量。 2. 不可变设计 如果在并发环境中不得不设计共享变量,则应该优先考虑共享变量是否为只读的,如果是只读场景就可以将共享变量设计为不可变的,这样自然也不会出现线程安全问题了。具体来说,就是在变量前加final修饰符,使其不可被修改,如果变量是引用类型,则将其设计为不可变类型(参考String类)。 3. 并发工具 java.util.concurrent包提供了几个有用的并发工具类,一样可以保证线程安全: - Semaphore:就是信号量,可以控制同时访问特定资源的线程数量。 - CountDownLatch:允许一个或多个线程等待其他线程完成操作。 - CyclicBarrier:让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会打开,所有被屏障拦截的线程才会继续运行。 4. 本地存储 我们也可以考虑使用ThreadLocal存储变量,ThreadLocal可以很方便地为每一个线程单独存一份数据,也就是将需要并发访问的资源复制成多份。这样一来,就可以避免多线程访问共享变量了,它们访问的是自己独占的资源,它从根本上隔离了多个线程之间的数据共享。
请说说你对反射的了解
思路:
得分点 反射概念,通过反射机制可以实现什么 标准回答 Java程序中,许多对象在运行时都会有编译时异常和运行时异常两种,例如多态情况下Car c = new Audi(); 这行代码运行时会生成一个c变量,在编译时该变量的类型是Car,运行时该变量类型为Audi;另外还有更极端的情况,例如程序在运行时接收到了外部传入的一个对象,这个对象的编译时类型是Object,但程序又需要调用这个对象运行时类型的方法,这种情况下,有两种解决方法:第一种做法是假设在编译时和运行时都完全知道类型的具体信息,在这种情况下,可以先使用instanceof运算符进行判断,再利用强制类型转换将其转换成其运行时类型的变量。第二种做法是编译时根本无法预知该对象和类可能属于哪些类,程序只依靠运行时信息来发现该对象和类的真实信息,这就必须使用反射。 具体来说,通过反射机制,我们可以实现如下的操作: - 程序运行时,可以通过反射获得任意一个类的Class对象,并通过这个对象查看这个类的信息; - 程序运行时,可以通过反射创建任意一个类的实例,并访问该实例的成员; - 程序运行时,可以通过反射机制生成一个类的动态代理类或动态代理对象。 加分回答 Java的反射机制在实际项目中应用广泛,常见的应用场景有: - 使用JDBC时,如果要创建数据库的连接,则需要先通过反射机制加载数据库的驱动程序; - 多数框架都支持注解/XML配置,从配置中解析出来的类是字符串,需要利用反射机制实例化; - 面向切面编程(AOP)的实现方案,是在程序运行时创建目标对象的代理类,这必须由反射机制来实现。
请你说说ArrayList和LinkedList的区别
思路:
得分点 数据结构、访问效率 标准回答 1. ArrayList的实现是基于数组,LinkedList的实现是基于双向链表。 2. 对于随机访问ArrayList要优于LinkedList,ArrayList可以根据下标以O(1)时间复杂度对元素进行随机访问,而LinkedList的每一个元素都依靠地址指针和它后一个元素连接在一起,查找某个元素的时间复杂度是O(N)。 3. 对于插入和删除操作,LinkedList要优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,不需要像ArrayList那样重新计算大小或者是更新索引。 4. LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
你知道哪些线程安全的集合?
思路:
得分点 Collections、java.util.concurrent (JUC) 标准回答 java.util包下的集合类中,大部分都是非线程安全的,但也有少数的线程安全的集合类,例如Vector、Hashtable,它们都是非常古老的API。虽然它们是线程安全的,但是性能很差,已经不推荐使用了。对于这个包下非线程安全的集合,可以利用Collections工具类,该工具类提供的synchronizedXxx()方法,可以将这些集合类包装成线程安全的集合类。 从JDK 1.5开始,并发包下新增了大量高效的并发的容器,这些容器按照实现机制可以分为三类。第一类是以降低锁粒度来提高并发性能的容器,它们的类名以Concurrent开头,如ConcurrentHashMap。第二类是采用写时复制技术实现的并发容器,它们的类名以CopyOnWrite开头,如CopyOnWriteArrayList。第三类是采用Lock实现的阻塞队列,内部创建两个Condition分别用于生产者和消费者的等待,这些类都实现了BlockingQueue接口,如ArrayBlockingQueue。 加分回答 Collections还提供了如下三类方法来返回一个不可变的集合,这三类方法的参数是原有的集合对象,返回值是该集合的“只读”版本。通过Collections提供的三类方法,可以生成“只读”的Collection或Map。 emptyXxx():返回一个空的不可变的集合对象 singletonXxx():返回一个只包含指定对象的不可变的集合对象 unmodifiableXxx():返回指定集合对象的不可变视图
请你说说ConcurrentHashMap
思路:
得分点 数组+链表+红黑树、锁的粒度 标准回答 在JDK8中,ConcurrentHashMap的底层数据结构与HashMap一样,也是采用“数组+链表+红黑树”的形式。同时,它又采用锁定头节点的方式降低了锁粒度,以较低的性能代价实现了线程安全。底层数据结构的逻辑可以参考HashMap的实现,下面我重点介绍它的线程安全的实现机制。 1. 初始化数组或头节点时,ConcurrentHashMap并没有加锁,而是CAS的方式进行原子替换(原子操作,基于Unsafe类的原子操作API)。 2. 插入数据时会进行加锁处理,但锁定的不是整个数组,而是槽中的头节点。所以,ConcurrentHashMap中锁的粒度是槽,而不是整个数组,并发的性能很好。 3. 扩容时会进行加锁处理,锁定的仍然是头节点。并且,支持多个线程同时对数组扩容,提高并发能力。每个线程需先以CAS操作抢任务,争抢一段连续槽位的数据转移权。抢到任务后,该线程会锁定槽内的头节点,然后将链表或树中的数据迁移到新的数组里。 4. 查找数据时并不会加锁,所以性能很好。另外,在扩容的过程中,依然可以支持查找操作。如果某个槽还未进行迁移,则直接可以从旧数组里找到数据。如果某个槽已经迁移完毕,但是整个扩容还没结束,则扩容线程会创建一个转发节点存入旧数组,届时查找线程根据转发节点的提示,从新数组中找到目标数据。 加分回答 ConcurrentHashMap实现线程安全的难点在于多线程并发扩容,即当一个线程在插入数据时,若发现数组正在扩容,那么它就会立即参与扩容操作,完成扩容后再插入数据到新数组。在扩容的时候,多个线程共同分担数据迁移任务,每个线程负责的迁移数量是
(数组长度 >>> 3) / CPU核心数
。 也就是说,为线程分配的迁移任务,是充分考虑了硬件的处理能力的。多个线程依据硬件的处理能力,平均分摊一部分槽的迁移工作。另外,如果计算出来的迁移数量小于16,则强制将其改为16,这是考虑到目前服务器领域主流的CPU运行速度,每次处理的任务过少,对于CPU的算力也是一种浪费。
说说你了解的线程同步方式
思路:
得分点 synchronized、Lock 标准回答 Java主要通过加锁的方式实现线程同步,而锁有两类,分别是synchronized和Lock。 synchronized可以加在三个不同的位置,对应三种不同的使用方式,这三种方式的区别是锁对象不同: 1. 加在普通方法上,则锁是当前的实例(this)。 2. 加在静态方法上,则锁是当前类的Class对象。 3. 加在代码块上,则需要在关键字后面的小括号里,显式指定一个对象作为锁对象。 不同的锁对象,意味着不同的锁粒度,所以我们不应该无脑地将它加在方法前了事,尽管通常这可以解决问题。而是应该根据要锁定的范围,准确的选择锁对象,从而准确地确定锁的粒度,降低锁带来的性能开销。 synchronized是比较早期的API,在设计之初没有考虑到超时机制、非阻塞形式,以及多个条件变量。若想通过升级的方式让synchronized支持这些相对复杂的功能,则需要大改它的语法结构,不利于兼容旧代码。因此,JDK的开发团队在1.5引入了Lock接口,并通过Lock支持了上述的功能。Lock支持的功能包括:支持响应中断、支持超时机制、支持以非阻塞的方式获取锁、支持多个条件变量(阻塞队列)。 加分回答 synchronized采用“CAS+Mark Word”实现,为了性能的考虑,并通过锁升级机制降低锁的开销。在并发环境中,synchronized会随着多线程竞争的加剧,按照如下步骤逐步升级:无锁、偏向锁、轻量级锁、重量级锁。 Lock则采用“CAS+volatile”实现,其实现的核心是AQS。AQS是线程同步器,是一个线程同步的基础框架,它基于模板方法模式。在具体的Lock实例中,锁的实现是通过继承AQS来实现的,并且可以根据锁的使用场景,派生出公平锁、不公平锁、读锁、写锁等具体的实现。
String、StringBuffer、Stringbuilder有什么区别
得分点 字符串是否可变,StringBuffer、StringBuilder线程安全问题 标准回答 Java中提供了String,StringBuffer两个类来封装字符串,并且提供了一系列方法来操作字符串对象。 String是一个不可变类,也就是说,一个String对象创建之后,直到这个对象销毁为止,对象中的字符序列都不能被改变。 StringBuffer对象则代表一个字符序列可变的字符串,当一个StringBuffer对象被创建之后,我们可以通过StringBuffer提供的append()、insert()、reverse()、setCharAt()、setLength()、等方法来改变这个字符串对象的字符序列。当通过StringBuffer得到期待中字符序列的字符串时,就可以通过toString()方法将其转换为String对象。 StringBuilder类是JDK1.5中新增的类,他也代表了字符串对象。和StringBuffer类相比,它们有共同的父类
AbstractStringBuilder
,二者无论是构造器还是方法都基本相同,不同的一点是,StringBuilder没有考虑线程安全问题,也正因如此,StringBuilder比StringBuffer性能略高。因此,如果是在单线程下操作大量数据,应优先使用StringBuilder类;如果是在多线程下操作大量数据,应优先使用StringBuilder类。
结束语🏆🏆🏆
🔥推荐一款模拟面试、刷题神器网站
点击注册即可
牛客刷题网
1、算法篇(398题):面试必刷100题、算法入门、面试高频榜单
2、SQL篇(82题):快速入门、SQL必知必会、SQL进阶挑战、面试真题
3、大厂笔试真题:字节跳动、美团、百度、腾讯…
版权归原作者 桃花键神 所有, 如有侵权,请联系我们删除。