
目录
一、数据集介绍
user_data.csv是一份用户行为数据,时间区间为2017-11-25到2017-12-03,总计29132493条记录,大小为1.0G,包含5个字段。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下: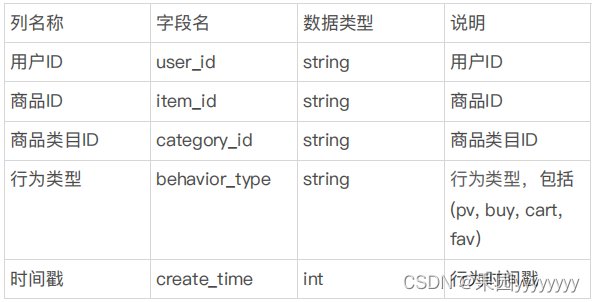
用户行为类型共有四种,它们分别是: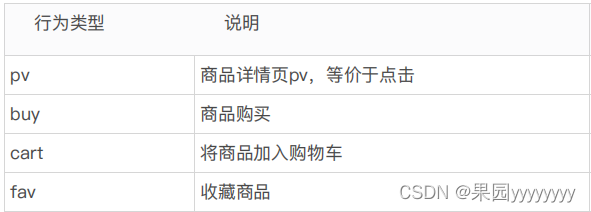
二、数据处理
1. 数据导入
将数据加载到hive,然后通过hive对数据进行处理。
(1)上传new_data.csv文件至虚拟机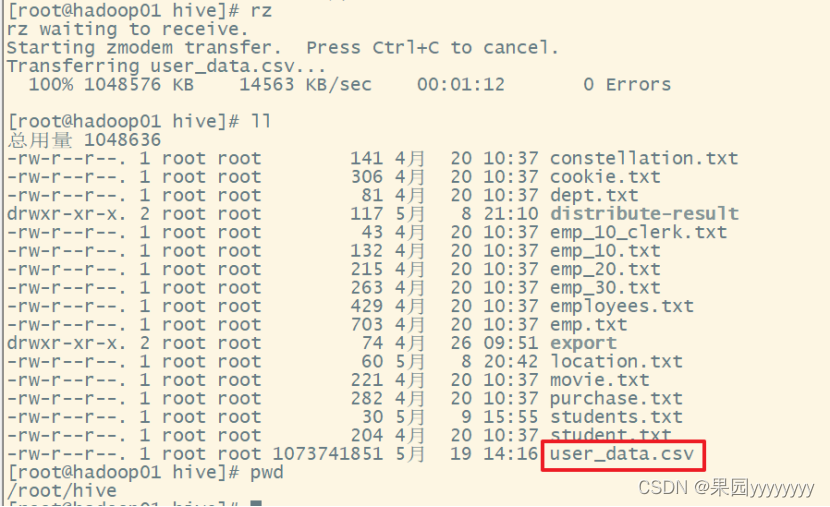
(2)创建user_db数据库
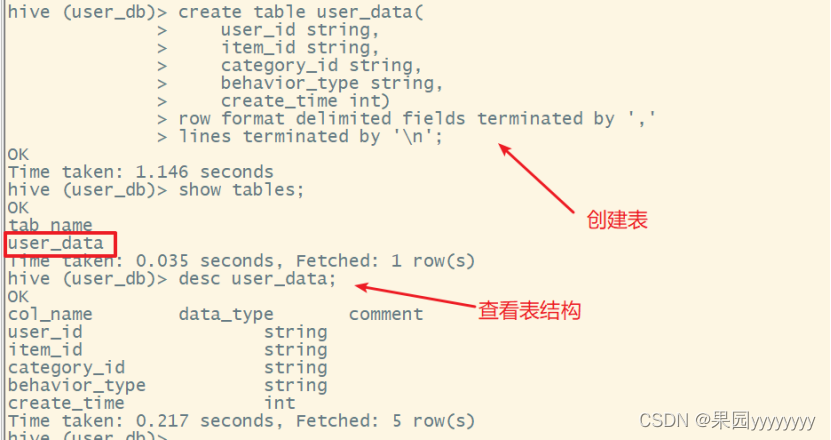
create database user_db;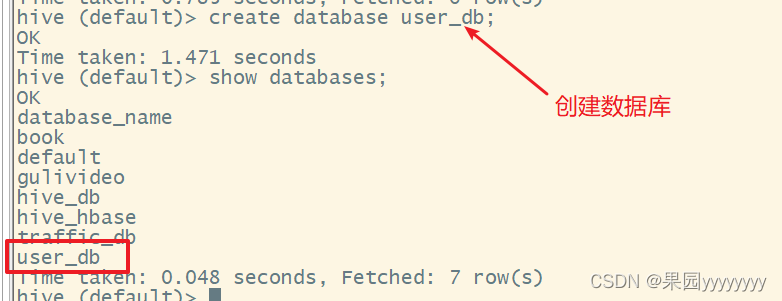
(3)创建user_data表
createtable user_data(
user_id string,
item_id string,
category_id string,
behavior_type string,
create_time int)row format delimited fieldsterminatedby','linesterminatedby'\n';
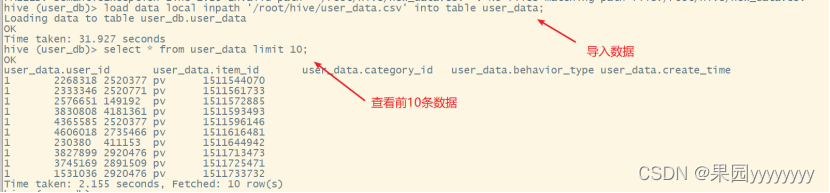
(4)将new_data.csv文件中的数据导入到user_data表中
load data local inpath '/root/hive/user_data.csv' into table user_data;
2. 数据清洗
数据处理主要包括:删除重复值,时间戳格式化,删除异常值。
- 创建user_data_new表,为其添加时间字符串字段
- 数据清洗,去掉完全重复的数据
- 数据清洗,时间戳格式化成datetime。要用到from_unixtime函数。
- 查看时间是否有异常值
- 数据清洗,去掉时间异常的数据
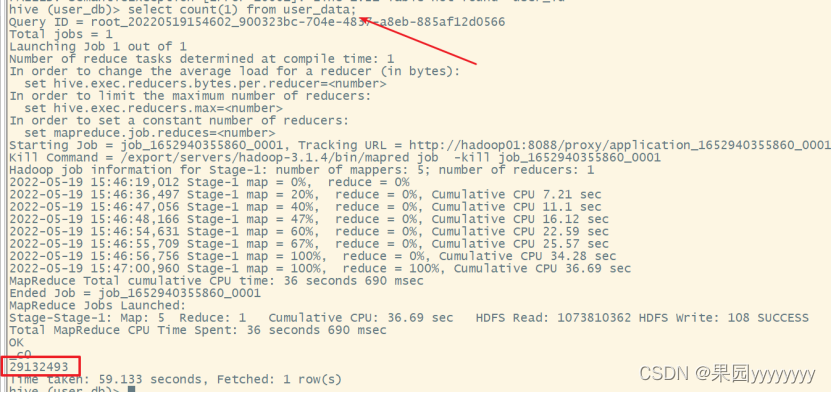
- 查看 behavior_type 是否有异常值(1)查看数据量
selectcount(1)from user_data;
(2)数据去重
insert overwrite table user_data
select user_id,item_id,category_id,behavior_type,create_time
from user_data
groupby user_id,item_id,category_id,behavior_type,create_time;
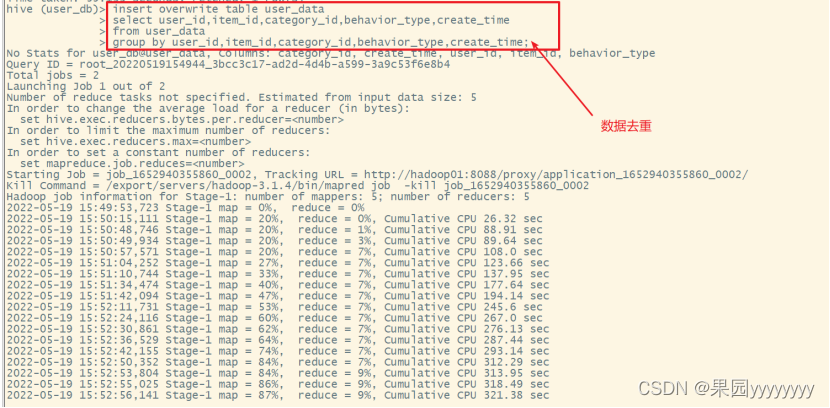
 可以看到有11条重复数据,已经去除。
可以看到有11条重复数据,已经去除。
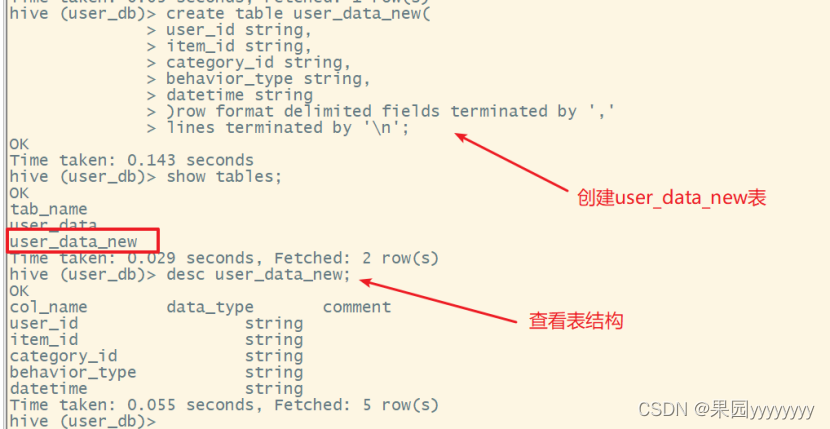
(3)创建user_data_new表,为其添加时间字符串字段
createtable user_data_new(
user_id string,
item_id string,
category_id string,
behavior_type string,datetime string
)row format delimited fieldsterminatedby','linesterminatedby'\n';
 (4)时间格式转换
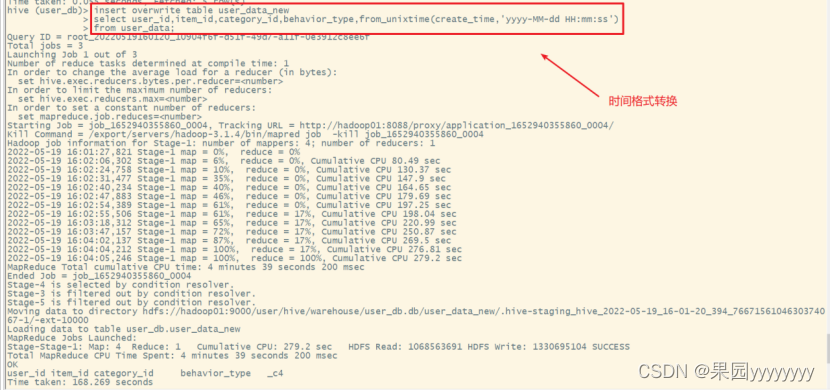
(4)时间格式转换
insert overwrite table user_data_new
select user_id,item_id,category_id,behavior_type,from_unixtime(create_time,'yyyy-MM-dd HH:mm:ss')from user_data;

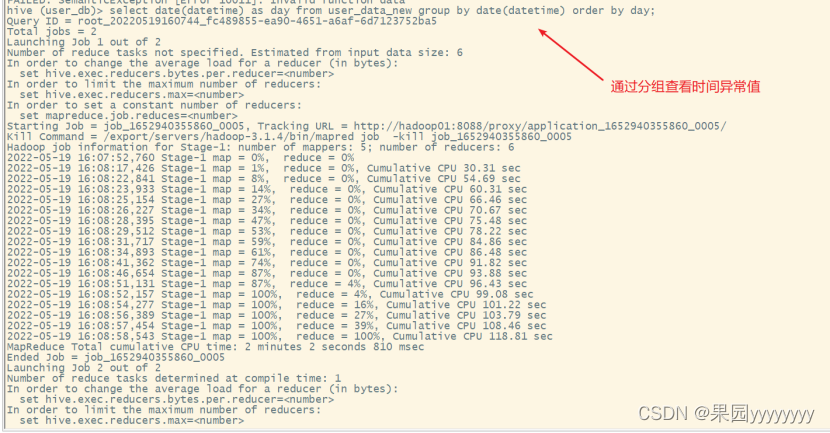
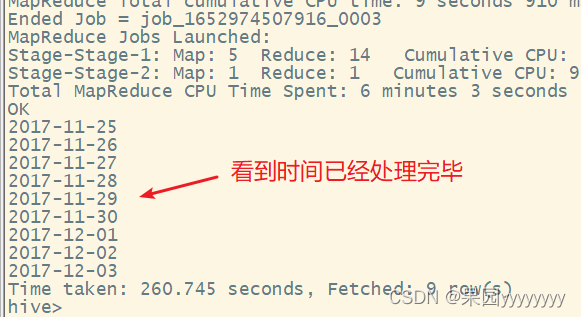
(5)查看时间异常值
selectdate(datetime)asdayfrom user_data_new groupbydate(datetime)orderbyday;

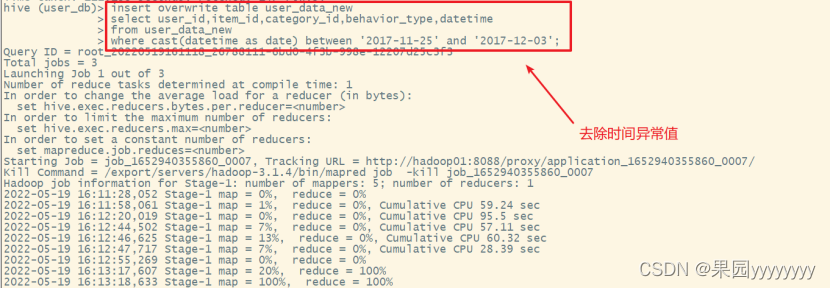
(6)去除时间异常值
insert overwrite table user_data_new
select user_id,item_id,category_id,behavior_type,datetimefrom user_data_new
where cast(datetimeasdate)between'2017-11-25'and'2017-12-03';
 (9)查看behavior_type是否有异常值
(9)查看behavior_type是否有异常值
select behavior_type from user_data_new groupby behavior_type;

三、数据分析可视化
1. 用户流量及购物情况
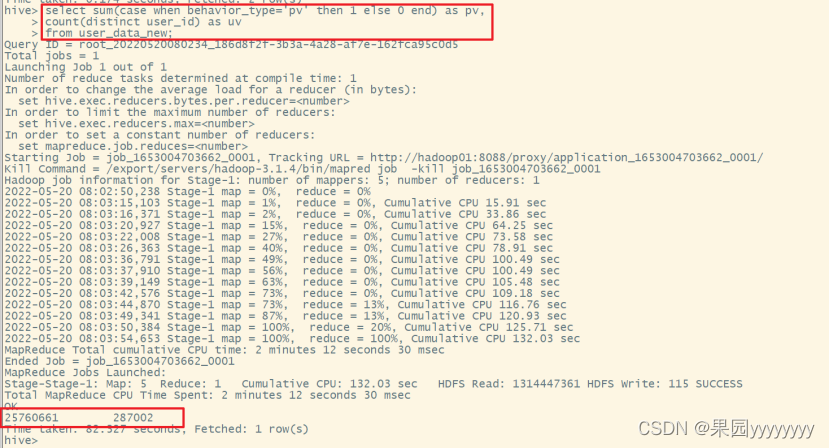
(1)总访问量PV,总用户量UV
selectsum(casewhen behavior_type='pv'then1else0end)as pv,count(distinct user_id)as uv
from user_data_new;
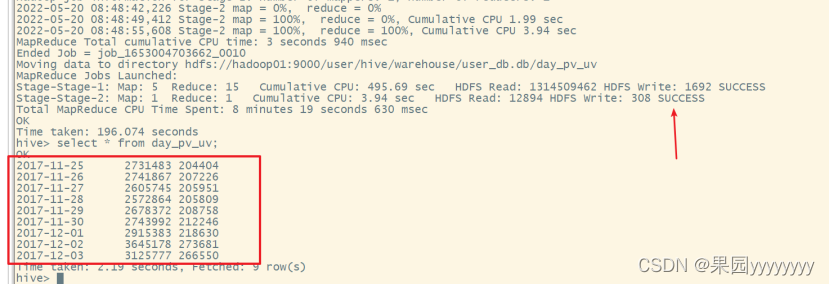
(2)日均访问量,日均用户量
① 统计日均访问量,日均用户量,并加工到day_pv_uv表中
createtable day_pv_uv asselect cast(datetimeasdate)asday,sum(casewhen behavior_type='pv'then1else0end)as pv,count(distinct user_id)as uv
from user_data_new
groupby cast(datetimeasdate)orderbyday;
② 将得到的数据通过sqoop迁移至mysql
- 在mysql中创建数据库和表
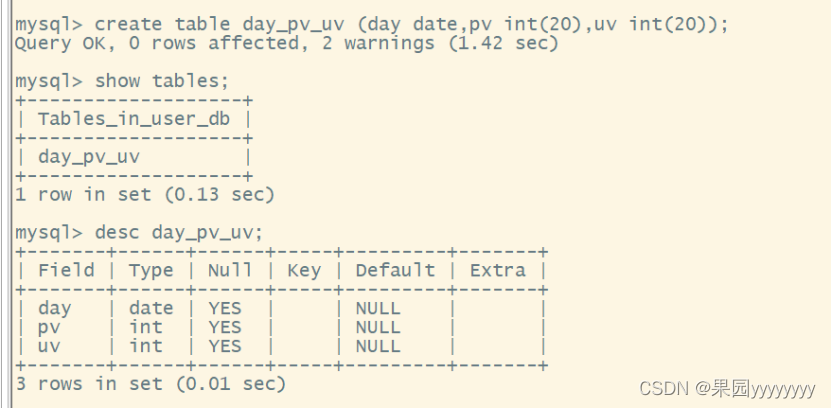
createtable day_pv_uv (daydate,pv int(20),uv int(20));
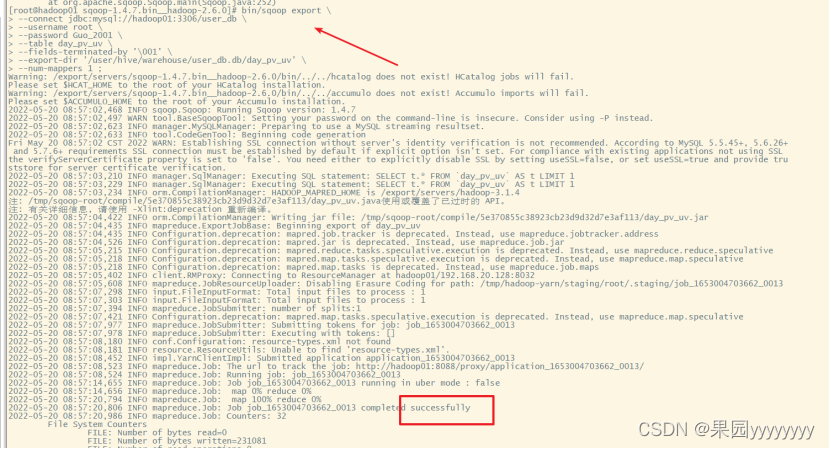
- sqoop数据迁移
bin/sqoop export \
--connect jdbc:mysql://hadoop01:3306/user_db \
--username root \
--password Guo_2001 \
--table day_pv_uv \
--fields-terminated-by '\001' \
--export-dir'/user/hive/warehouse/user_db.db/day_pv_uv' \
--num-mappers 1
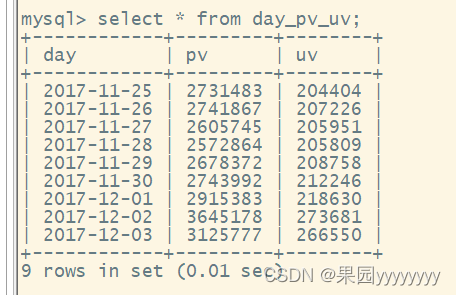
- 查看迁移后的数据
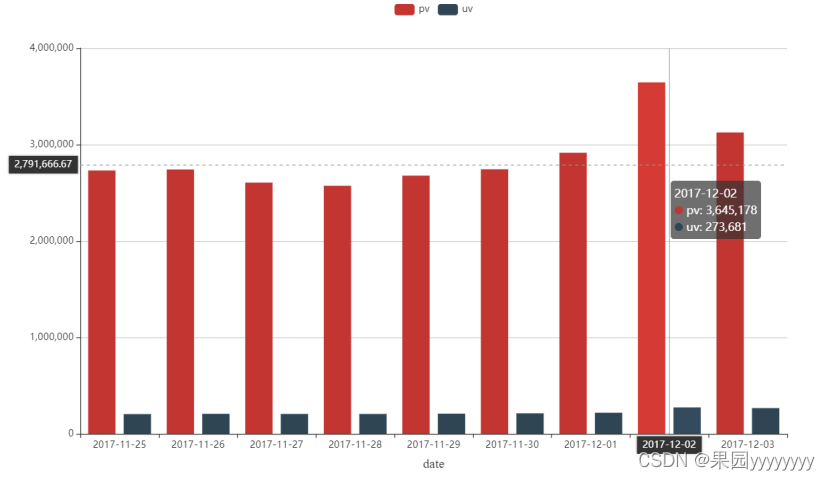
 ③ 利用python读取mysql数据并可视化
③ 利用python读取mysql数据并可视化 - pymysql读取数据
import pymysql
# 读取mysql数据
daylist =[]
pvlist =[]
uvlist =[]
conn = pymysql.connect(host='192.168.20.128',
port=3306,
user='root',
password='Guo_2001',
db='user_db',
charset='utf8')
cursor = conn.cursor()try:
sql_name =""" SELECT day FROM day_pv_uv """
cursor.execute(sql_name)
days = cursor.fetchall()for i inrange(0,len(days)):
daylist.append(days[i][0])# print(daylist)
sql_num =""" SELECT pv FROM day_pv_uv """
cursor.execute(sql_num)
pvs = cursor.fetchall()for i inrange(0,len(pvs)):
pvlist.append(pvs[i][0])# print(pvlist)
sql_num =""" SELECT uv FROM day_pv_uv """
cursor.execute(sql_num)
uvs = cursor.fetchall()for i inrange(0,len(uvs)):
uvlist.append(uvs[i][0])# print(uvlist)except:print("未查询到数据!")
conn.rollback()finally:
conn.close()
- pyecharts可视化
import pyecharts.options as opts
from pyecharts.charts import Bar, Line
bar =(
Bar(init_opts=opts.InitOpts(width="1100px", height="600px")).set_global_opts(title_opts=opts.TitleOpts(title="每日访问情况")).add_xaxis(xaxis_data=daylist).add_yaxis(
series_name="pv",
y_axis=pvlist,
label_opts=opts.LabelOpts(is_show=False),).add_yaxis(
series_name="uv",
y_axis=uvlist,
label_opts=opts.LabelOpts(is_show=False),).set_global_opts(
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"),
xaxis_opts=opts.AxisOpts(
name='date',
name_location='middle',
name_gap=30,
name_textstyle_opts=opts.TextStyleOpts(
font_family='Times New Roman',
font_size=16,# 标签字体大小)),
yaxis_opts=opts.AxisOpts(
type_="value",
axislabel_opts=opts.LabelOpts(formatter="{value}"),
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),)))
bar.render("折线图-柱状图多维展示.html")
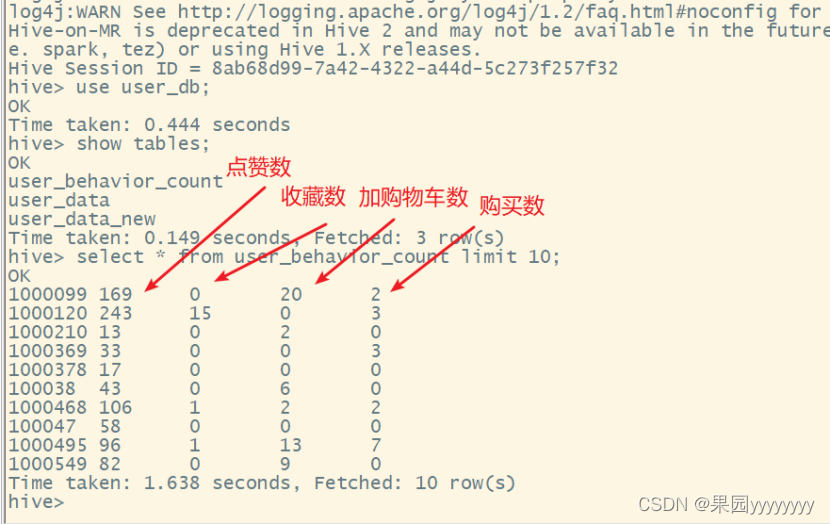
(3)每个用户的购物情况,加工到 user_behavior_count表中
createtable user_behavior_count asselect user_id,sum(casewhen behavior_type='pv'then1else0end)as pv,sum(casewhen behavior_type='fav'then1else0end)as fav,sum(casewhen behavior_type='cart'then1else0end)as cart,sum(casewhen behavior_type='buy'then1else0end)as buy
from user_data_new
groupby user_id;
(4)统计复购率
复购率:产生两次或两次以上购买的用户占购买用户的比例
selectsum(casewhen buy>1then1else0end)/sum(casewhen buy>0then1else0end)from user_behavior_count;
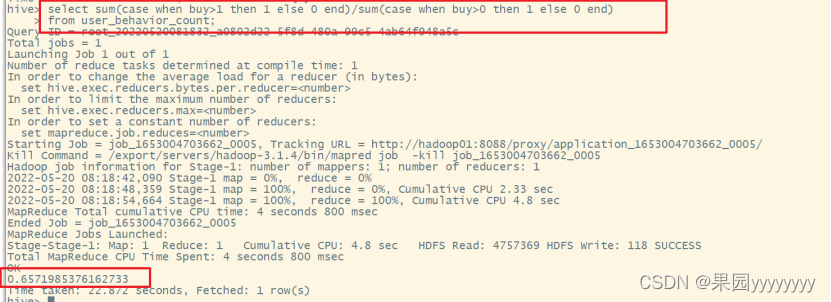
可以看到复购率为0.65,还是不错的。
2. 用户行为转化率
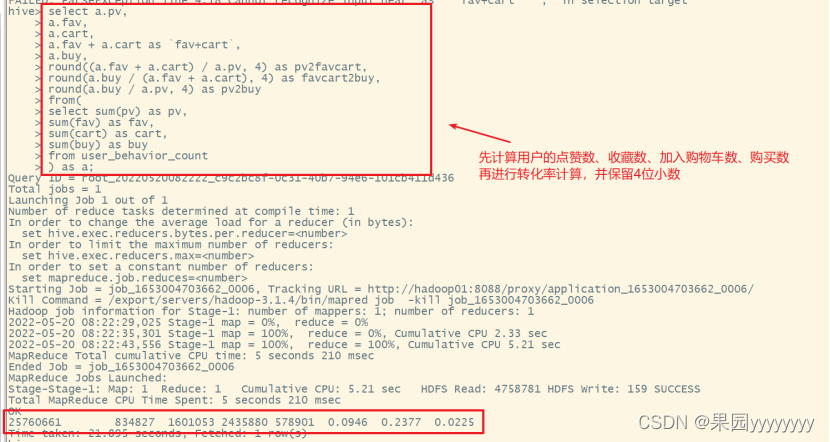
(1)统计各环节转化率
点击/(加购物车+收藏)/购买,各环节转化率
select a.pv,
a.fav,
a.cart,
a.fav + a.cart as`fav+cart`,
a.buy,round((a.fav + a.cart)/ a.pv,4)as pv2favcart,round(a.buy /(a.fav + a.cart),4)as favcart2buy,round(a.buy / a.pv,4)as pv2buy
from(selectsum(pv)as pv,sum(fav)as fav,sum(cart)as cart,sum(buy)as buy
from user_behavior_count
)as a;
(2)用户行为转化漏斗可视化
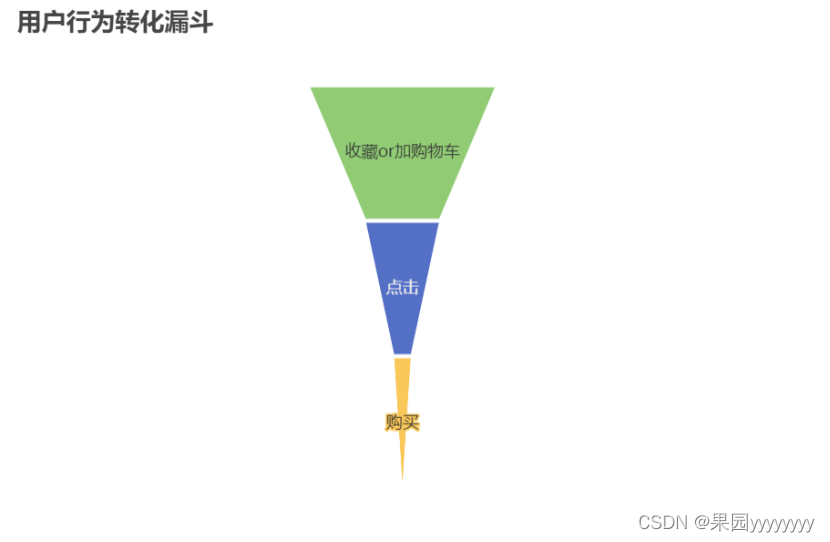
从漏斗图中可以看到,收藏和加购物车的用户行为是最多的,而购买最少,也符合实际。
3. 用户行为习惯
(1)一天的活跃时段分布
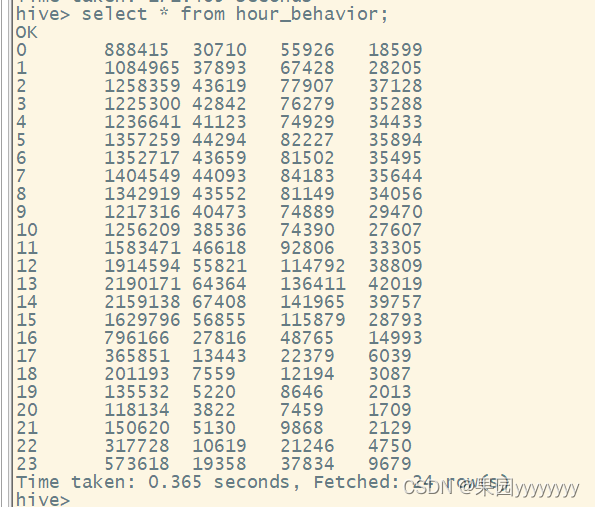
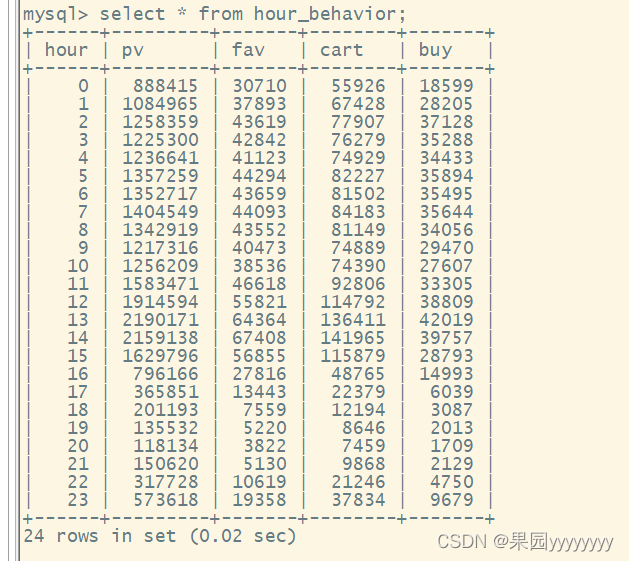
① 统计每天24小时内的行为数据,并加工到hour_behavior表中
createtable hour_behavior asselecthour(datetime)ashour,sum(casewhen behavior_type ='pv'then1else0end)as pv,sum(casewhen behavior_type ='fav'then1else0end)as fav,sum(casewhen behavior_type ='cart'then1else0end)as cart,sum(casewhen behavior_type ='buy'then1else0end)as buy
from user_data_new
groupbyhour(datetime)orderbyhour;
② 将得到的数据通过sqoop迁移至mysql
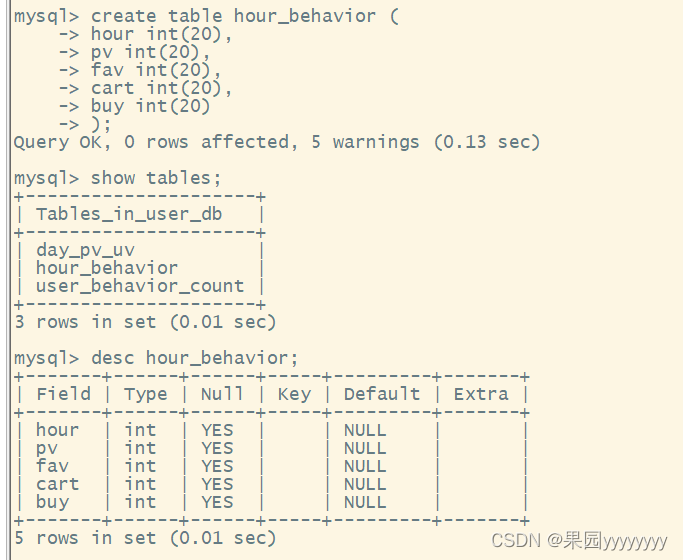
- 在mysql中创建表
createtable hour_behavior (hourint(20),
pv int(20),
fav int(20),
cart int(20),
buy int(20));
- sqoop数据迁移
bin/sqoop export \
--connect jdbc:mysql://hadoop01:3306/user_db \
--username root \
--password Guo_2001 \
--table hour_behavior \
--fields-terminated-by '\001' \
--export-dir'/user/hive/warehouse/user_db.db/hour_behavior' \
--num-mappers 1
- 查看迁移后的数据
 ③ 利用python读取mysql数据并可视化
③ 利用python读取mysql数据并可视化 - pymysql读取数据
import pymysql
# 读取mysql数据
hourlist =[]
pvlist =[]
favlist =[]
cartlist =[]
buylist =[]
conn = pymysql.connect(host='192.168.20.128',
port=3306,
user='root',
password='Guo_2001',
db='user_db',
charset='utf8')
cursor = conn.cursor()try:
sql_name =""" SELECT hour FROM hour_behavior """
cursor.execute(sql_name)
hours = cursor.fetchall()for i inrange(0,len(hours)):
hourlist.append(hours[i][0])
sql_num =""" SELECT pv FROM hour_behavior """
cursor.execute(sql_num)
pvs = cursor.fetchall()for i inrange(0,len(pvs)):
pvlist.append(pvs[i][0])
sql_num =""" SELECT fav FROM hour_behavior """
cursor.execute(sql_num)
favs = cursor.fetchall()for i inrange(0,len(favs)):
favlist.append(favs[i][0])
sql_num =""" SELECT cart FROM hour_behavior """
cursor.execute(sql_num)
carts = cursor.fetchall()for i inrange(0,len(carts)):
cartlist.append(carts[i][0])
sql_num =""" SELECT buy FROM hour_behavior """
cursor.execute(sql_num)
buys = cursor.fetchall()for i inrange(0,len(buys)):
buylist.append(buys[i][0])except:print("未查询到数据!")
conn.rollback()finally:
conn.close()
- pyecharts可视化
from pyecharts.charts import Line
# 堆叠柱状图绘制
line=Line()
line.add_xaxis(hourlist)
line.add_yaxis('点赞数',pvlist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.add_yaxis('收藏数',favlist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.add_yaxis('加购物车数',cartlist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.add_yaxis('购买数',buylist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.set_global_opts(title_opts=opts.TitleOpts(title="用户一天24小时的活跃时段分布"))
line.render_notebook()
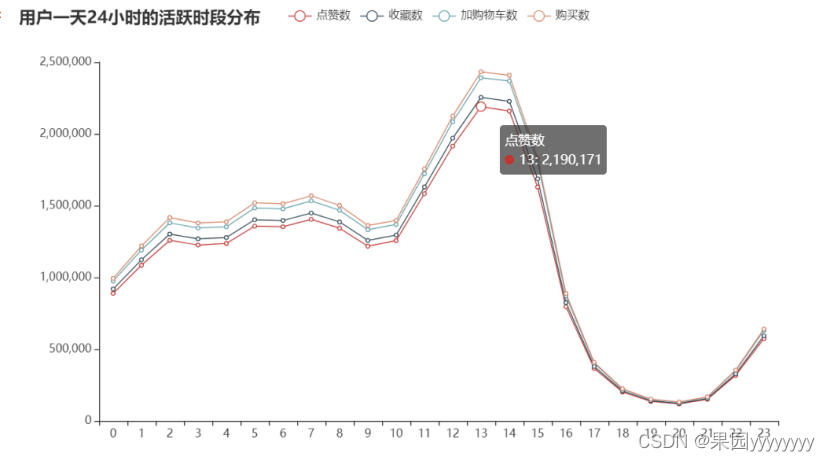
从图中可以看到一天24小时中,13和14时用户处于最活跃的状态,而19-21时用户的活跃次数并不高,当然此时也处于睡觉时间,符合实际情况。
(2)一周用户的活跃分布
① 统计一周七天内的行为数据,并加工到week_behavior表中
createtable week_behavior asselect pmod(datediff(datetime,'1920-01-01')-3,7)as weekday,sum(casewhen behavior_type ='pv'then1else0end)as pv,sum(casewhen behavior_type ='fav'then1else0end)as fav,sum(casewhen behavior_type ='cart'then1else0end)as cart,sum(casewhen behavior_type ='buy'then1else0end)as buy
from user_data_new
wheredate(datetime)between'2017-11-27'and'2017-12-03'groupby pmod(datediff(datetime,'1920-01-01')-3,7)orderby weekday;
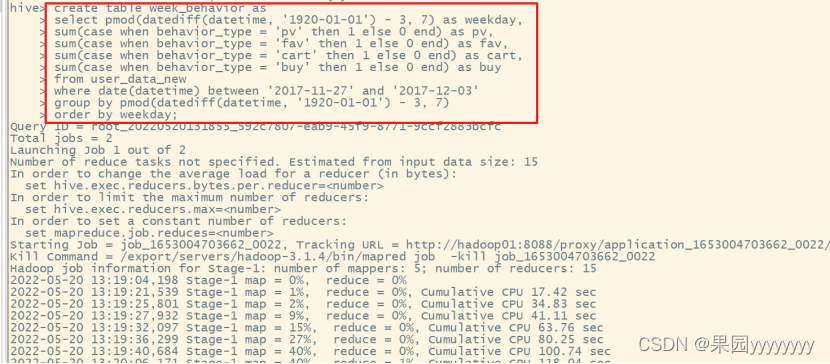

② 将得到的数据通过sqoop迁移至mysql
- 在mysql中创建表
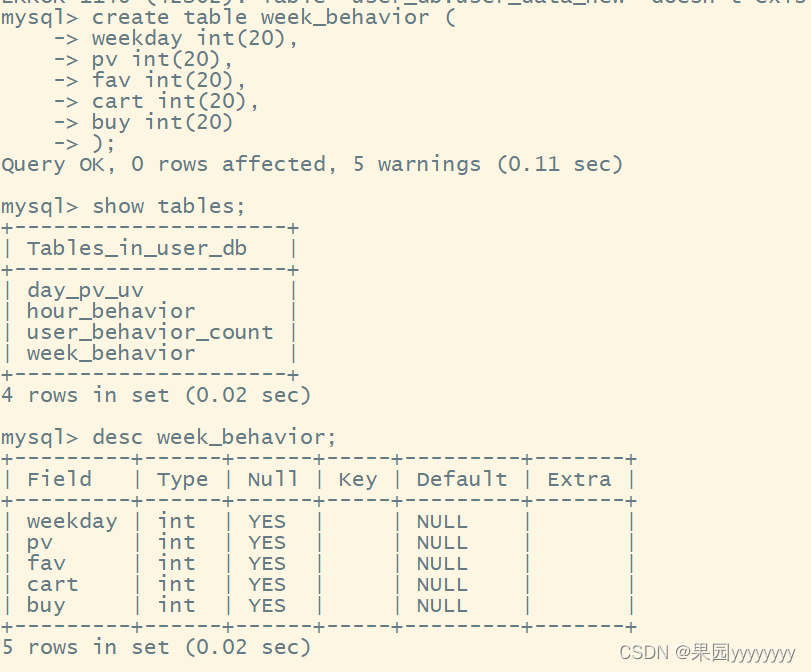
createtable week_behavior (
weekday int(20),
pv int(20),
fav int(20),
cart int(20),
buy int(20));
- sqoop数据迁移
bin/sqoop export \
--connect jdbc:mysql://hadoop01:3306/user_db \
--username root \
--password Guo_2001 \
--table week_behavior \
--fields-terminated-by '\001' \
--export-dir'/user/hive/warehouse/user_db.db/week_behavior' \
--num-mappers 1
- 查看迁移后的数据
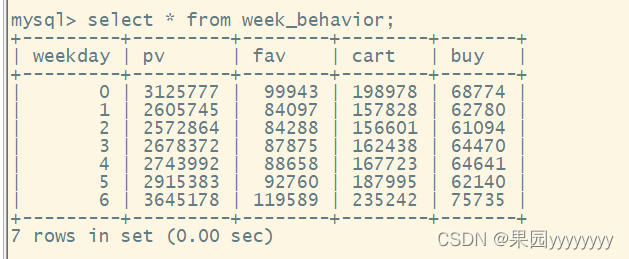 ③ 利用python读取mysql数据并可视化
③ 利用python读取mysql数据并可视化 - pymysql读取数据
import pymysql
# 读取mysql数据
weeklist =[]
pvlist =[]
favlist =[]
cartlist =[]
buylist =[]
conn = pymysql.connect(host='192.168.20.128',
port=3306,
user='root',
password='Guo_2001',
db='user_db',
charset='utf8')
cursor = conn.cursor()try:
sql_name =""" SELECT weekday FROM week_behavior """
cursor.execute(sql_name)
weeks = cursor.fetchall()for i inrange(0,len(weeks)):
weeklist.append(weeks[i][0])
sql_num =""" SELECT pv FROM week_behavior """
cursor.execute(sql_num)
pvs = cursor.fetchall()for i inrange(0,len(pvs)):
pvlist.append(pvs[i][0])
sql_num =""" SELECT fav FROM week_behavior """
cursor.execute(sql_num)
favs = cursor.fetchall()for i inrange(0,len(favs)):
favlist.append(favs[i][0])
sql_num =""" SELECT cart FROM week_behavior """
cursor.execute(sql_num)
carts = cursor.fetchall()for i inrange(0,len(carts)):
cartlist.append(carts[i][0])
sql_num =""" SELECT buy FROM week_behavior """
cursor.execute(sql_num)
buys = cursor.fetchall()for i inrange(0,len(buys)):
buylist.append(buys[i][0])except:print("未查询到数据!")
conn.rollback()finally:
conn.close()
- pyecharts可视化
from pyecharts.charts import Line
# 堆叠这些线图绘制
line=Line()
line.add_xaxis(weeklist)
line.add_yaxis('点赞数',pvlist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.add_yaxis('收藏数',favlist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.add_yaxis('加购物车数',cartlist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.add_yaxis('购买数',buylist,stack="stack1",label_opts=opts.LabelOpts(is_show=False))
line.set_global_opts(title_opts=opts.TitleOpts(title="一周用户的活跃分布"))
line.render_notebook()
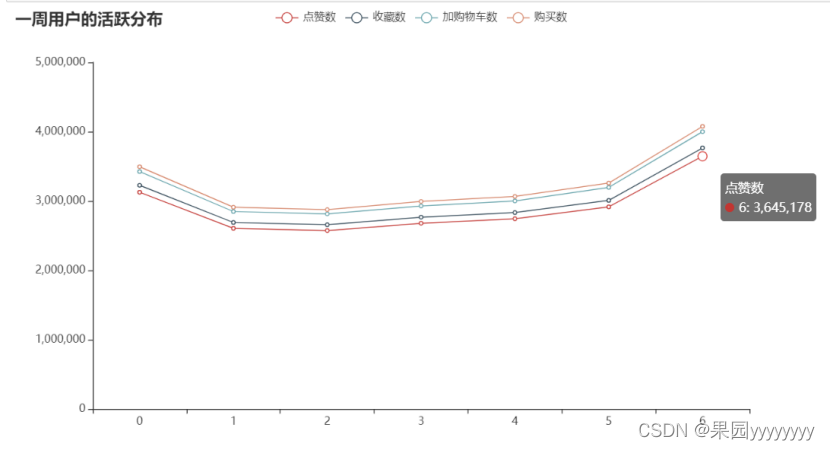
从图中可以看到,在一周中,周日是用户最活跃的一天,休息日不管是从点赞量、收藏量、加购物车量还是购买量来看都是处于最高的位置。
版权归原作者 果园yyyyyyyy 所有, 如有侵权,请联系我们删除。