
文章目录
一. hive sync tool工具介绍
使用DataSource writer或HoodieDeltaStreamer写入数据支持将表的最新模式同步到Hive metastore,这样查询就可以获得新的列和分区。在这种情况下,最好从命令行或在一个独立的jvm中运行,Hudi提供了一个HiveSyncTool,一旦你构建了Hudi -hive模块,就可以如下所示调用它。以下是我们如何同步上述Datasource Writer写入的表到Hive metastore。
语法:
cd hudi-hive
./run_sync_tool.sh --jdbc-url jdbc:hive2:\/\/hiveserver:10000 --user hive --pass hive --partitioned-by partition --base-path <basePath> --database default --table <tableName>
二. 问题排查
hudi自身带的 hive sync tool会存在一定的问题,直接运行会报各种各样不同的错误。
修改
vim run_sync_tool.sh
- 解决hadoop依赖问题 注释这两行
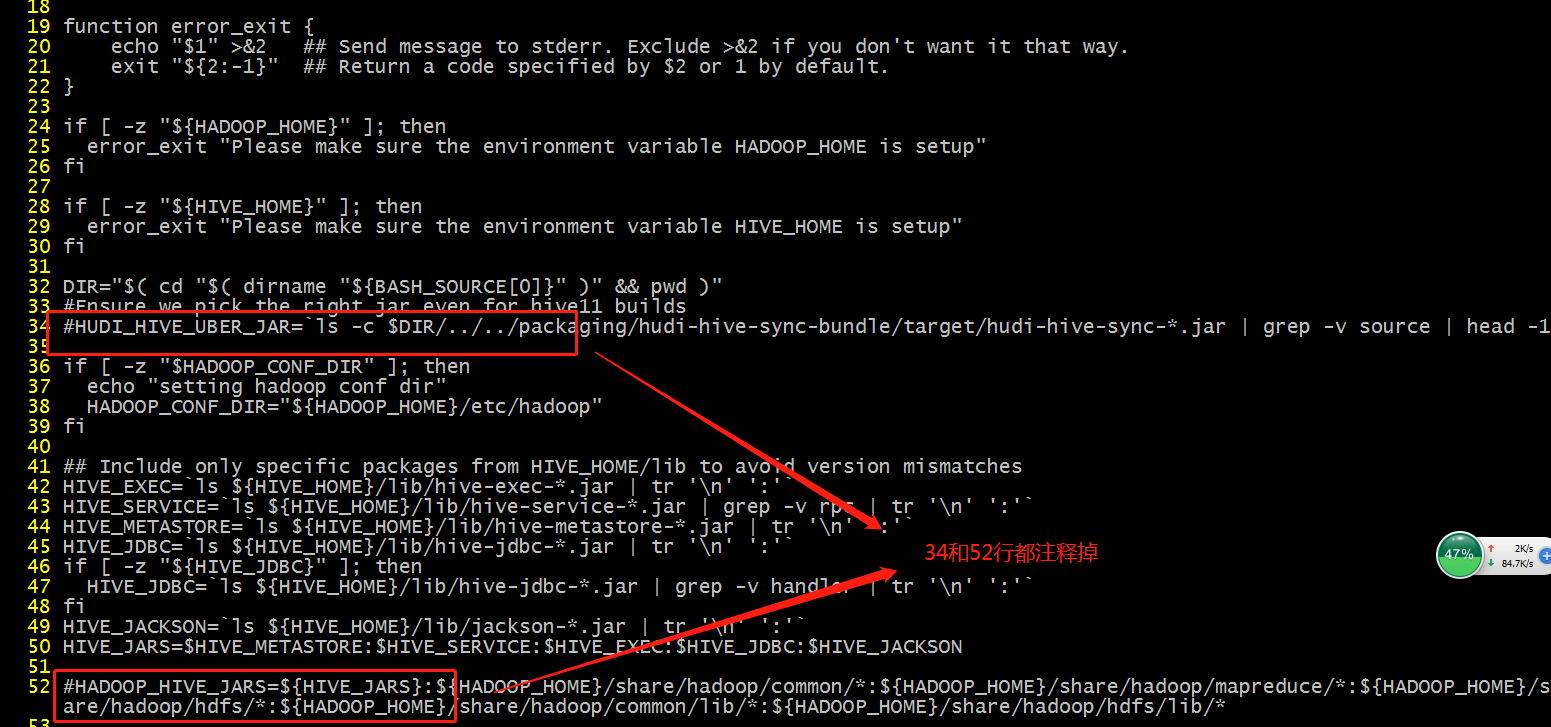
新增两行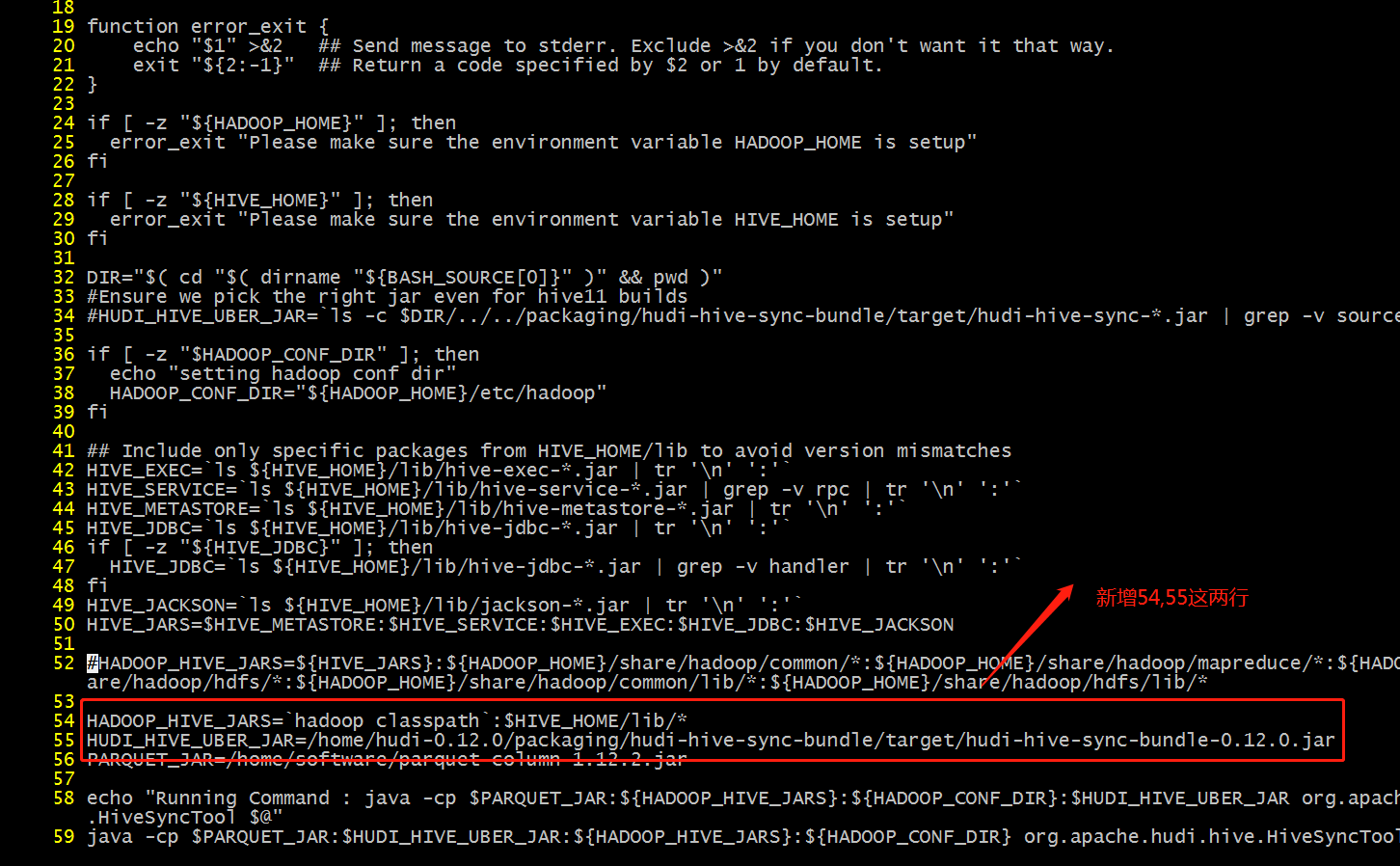
- 解决Parquet冲突 上传到/home/software目录
wget https://repo.maven.apache.org/maven2/org/apache/parquet/parquet-column/1.12.2/parquet-column-1.12.2.jar
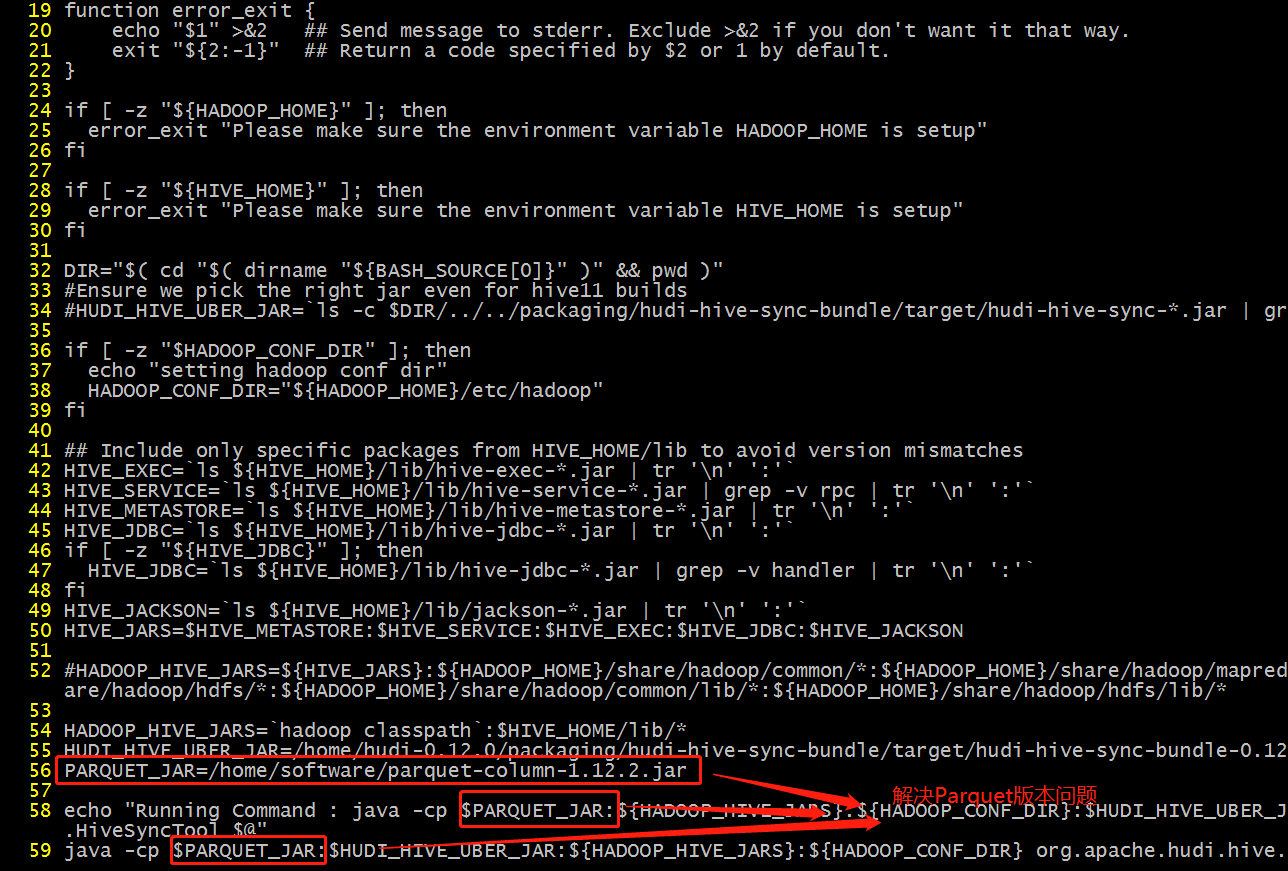
三. 实操
代码:
cd /home/hudi-0.12.0/hudi-sync/hudi-hive-sync
./run_sync_tool.sh --jdbc-url jdbc:hive2:\/\/hp5:10000 --base-path hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc5 --database test --table flink_hudi_mysql_cdc5
运行记录: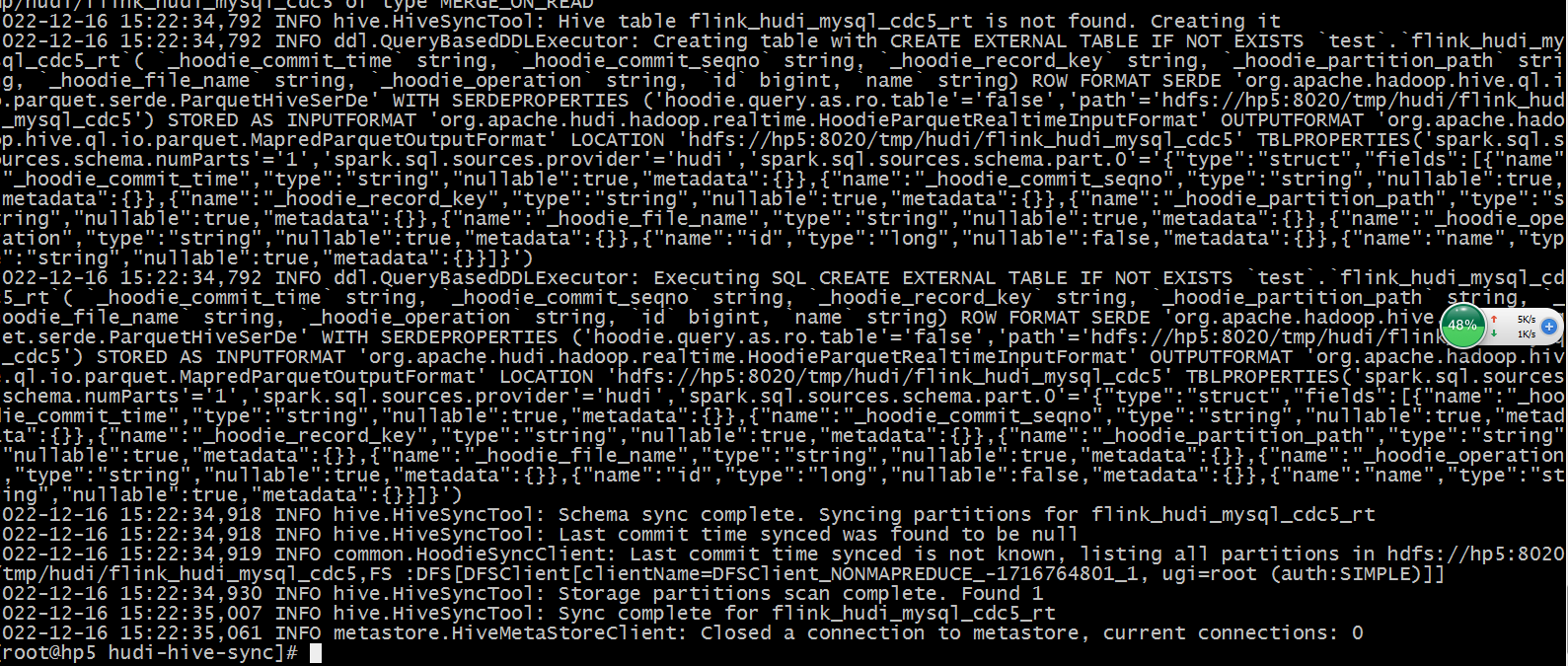
Flink SQL 查看建表语句:
Flink SQL> show create table flink_hudi_mysql_cdc5;
CREATE TABLE `hive_catalog`.`hudidb`.`flink_hudi_mysql_cdc5` (
`id` BIGINT NOT NULL,
`name` VARCHAR(100),
CONSTRAINT `PK_3386` PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'write.precombine.field' = 'name',
'compaction.async.enabled' = 'false',
'hoodie.datasource.write.recordkey.field' = 'id',
'path' = 'hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc5',
'connector' = 'hudi',
'changelog.enabled' = 'true',
'table.type' = 'MERGE_ON_READ'
)
Hive端查看建表语句: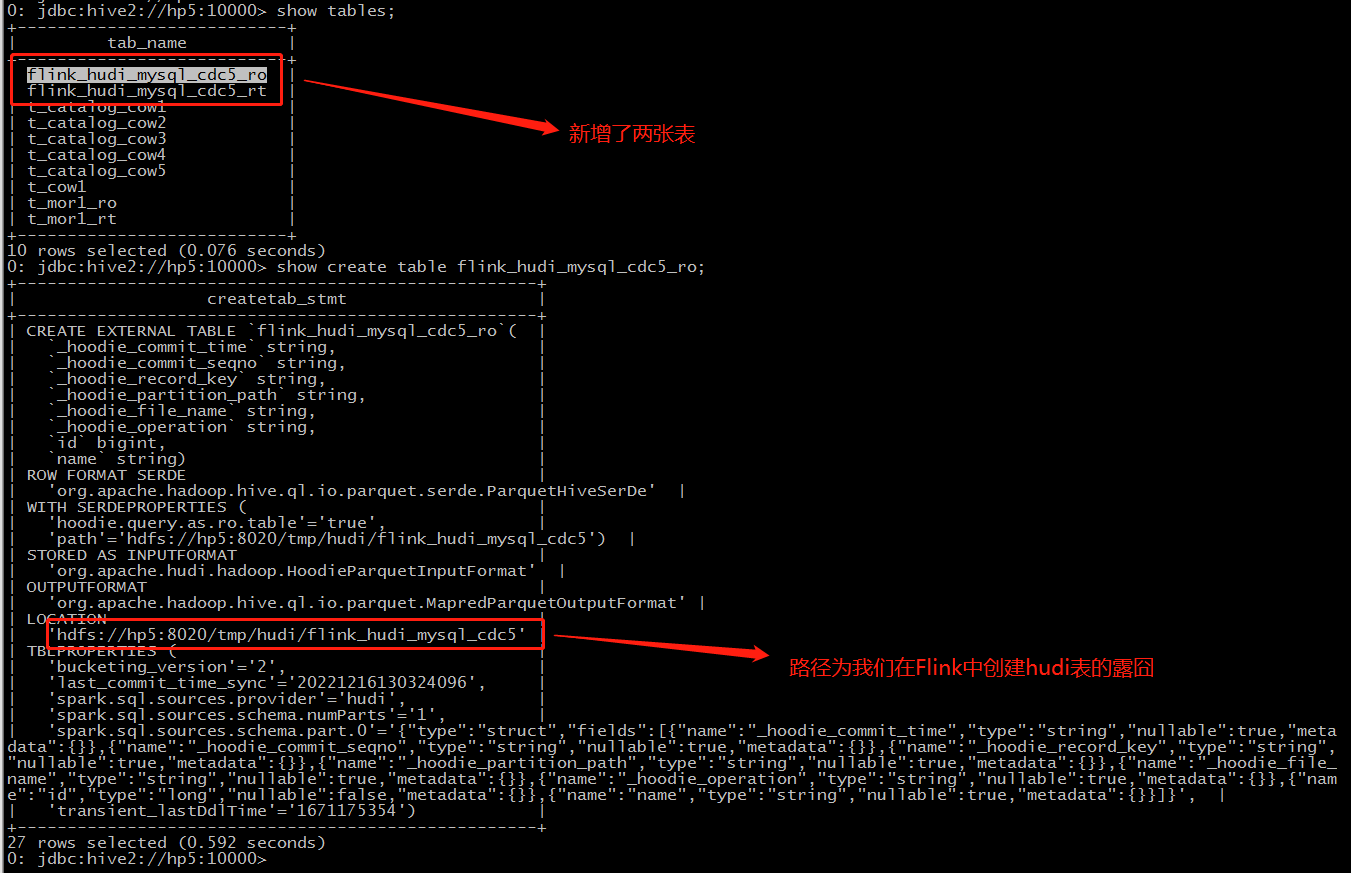

MySQL 端持续插入数据:
DELIMITER//CREATEPROCEDURE p5()BEGINdeclare l_n1 intdefault21;while l_n1 <=10000000DOinsertinto mysql_cdc (id,name)values(l_n1,concat('test',l_n1));set l_n1 = l_n1 +1;endwhile;END;//DELIMITER;
参考:
本文转载自: https://blog.csdn.net/u010520724/article/details/128897246
版权归原作者 只是甲 所有, 如有侵权,请联系我们删除。
版权归原作者 只是甲 所有, 如有侵权,请联系我们删除。