
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
这篇论文也是batch normalization的作者所写的,主要是针对小的mini-batch 会影响normalization效果这个问题作出修复,如果你的BN效果不好,可以试试这个方法。
在继续我们下面话题前,我假定您对Batch Normalization(BN)相当熟悉,以及了解它如何帮助更快地收敛到问题的最优解?
如果你不了解,让我们简要总结一下BN:
- 每个batch的均值和方差来代替整体训练集的均值和方差
- 它有助于减少内部协变量偏移 (ICS),因此激活的输入分布保持更稳定。
- BN 让我们不太注意参数的规模及其初始化。
- 它允许我们使用更高的学习率,这有助于我们加快训练速度。
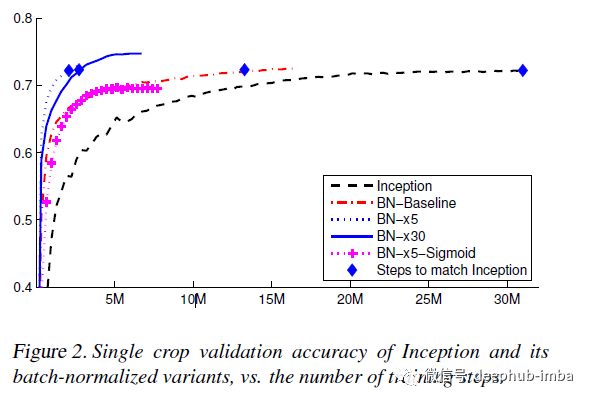
正如我们在上面看到的,BN 在加速收敛到最优解的过程中非常有用和有效。但是在过程中有什么缺点?我们将尝试通过本文来理解它。并了解Batch Renormalization如何帮助解决该问题?
正如 Sergey Ioffe 在 Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models 中总结的那样,“它有望提高任何使用Batch norm的模型的性能”。我们试图理解为什么会这样。
我们知道,BN里面用每个batch的均值和方差来代替整体训练集的均值和方差。虽然它使BN强大;这也是其缺点的来源。这里有个隐藏的前提是每个batch必须从各个类中均匀采样,否则batch内的均值和方差和训练样本整体的均值和方差是会存在较大差异的。
因为,随着我们减少批量的大小,我们用来标准化输入的均值和方差会变得不那么准确。这些不准确与深度相结合,这会影响模型的质量。并且论文还指出,非 iid 小批量会对使用 batchnorm 的模型产生不良影响。
为了解决这个问题,BN 论文的一位作者亲自向我们介绍了 Batch Renormalization,它通过保留 BN 的优点(例如对参数初始化和训练效率不敏感)来消除上述 BN 的差异。
Batch Renormalization与BN有何不同?
正如我们所知,在BN中,移动平均数是在训练期间的最后几个小批量中计算的并且只用于推断。但是Batch Renorm在训练期间使用这些移动平均数和方差进行校正。
Batch Renormalization是对网络的一种扩充,它为每个BN层增加了一个线性变换来逼近数据的真实分布。
假设我们有一个Minibatch,并且想要使用Minibatch统计数据或它们的移动平均数据对一个特定的节点x进行标准化,那么这两种标准化的结果通过一个仿射变换关联起来。
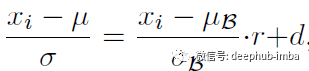
当
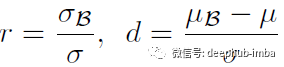
时,上述等式左右两边是完全等价的。
在实际应用中,我们将参数 r 和 d 视为固定的。在训练阶段,我们通过保持 r = 1 和 d = 0 来单独启动 batchnorm 进行一定次数的迭代,然后在一定范围内逐渐改变这些参数。这是Batch Renormalization算法:

随着我们减少小批量的大小,Batch Renormalization比使用 BN 的网络显着提高了网络的准确性。论文还指出,当 Minibatch 中的示例不是相同且独立地采样(iid)时,BN 的性能会很差。
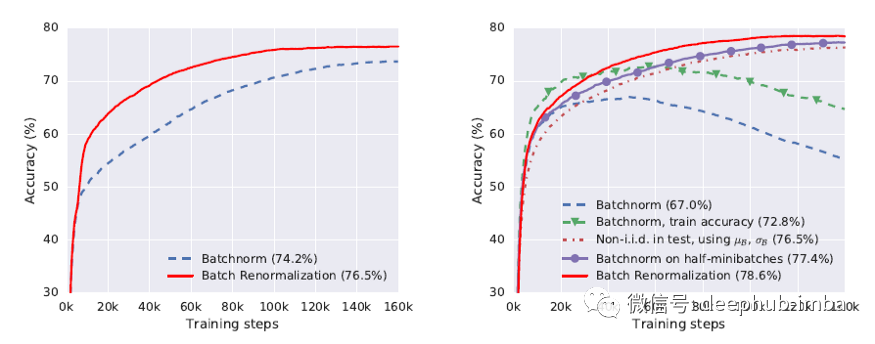
最后总结:
- Batch Renormalization 减少了对小批量中其他样本的依赖,并保留了 BN 的好处。
- 它在使用小批量时效果很好。
- 它为 BN 上的非 iid 示例提供了显着的结果。
论文地址:arxiv1702.03275
喜欢就关注一下吧:
点个 在看 你最好看!********** **********