
🙆♂️🙆♂️ 写在前面
🏠 个人主页:csdn春和
📚 推荐专栏:更多专栏尽在主页!
Scala专栏(spark必学语言 已完结)
JavaWeb专栏(从入门到实战超详细!!!)
SSM专栏 (更新中…)
📖 本期文章:大数据技术之——zookeeper的安装部署
如果对您有帮助还请三连支持,定会一 一回访!🙋🏻♂️
📌本文目录
大数据技术之—— Zookeeper的安装
一、本地模式安装部署
1.1、安装前准备
1、安装jdk 确保已将安装好了jdk
2、拷贝zookeeper安装包到linux系统
3、解压到指定目录
解压到指定的目录
tar -zxvf apache-zookeeper-3.5.7- bin.tar.gz -C /opt/module/
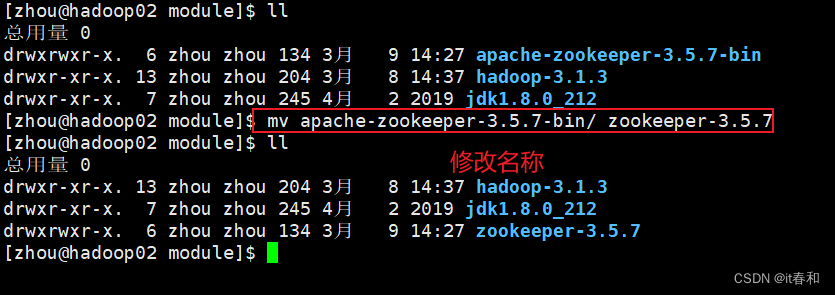
修改名称(由于名称太长,可不修改直接下一步):
mv apache-zookeeper-3.5.7 -bin/ zookeeper-3.5.7
1.2、修改配置
1、将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为zoo.cfg
mv zoo_sample.cfg zoo.cfg
2、打开 zoo.cfg 文件,修改 dataDir 路径:
vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper-3.5.7/zkData

3、在/opt/module/zookeeper-3.5.7/这个目录上创建 zkData 文件夹
mkdir zkData
1.3、操作zookeeper
(1)启动 Zookeeper
bin/zkServer.sh start
(2)查看进程是否启动
jps

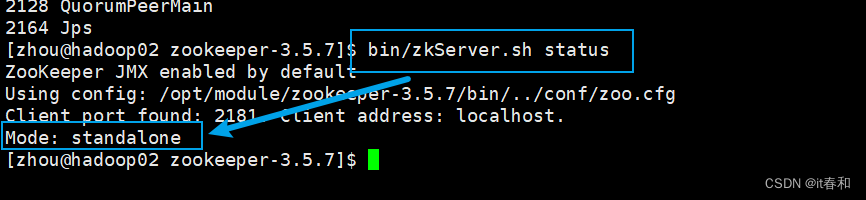
(3)查看状态
bin/zkServer.sh status
(4)启动客户端
bin/zkCli.sh
(5)退出客户端:
quit
(6)停止 Zookeeper
bin/zkServer.sh stop
1.4、配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
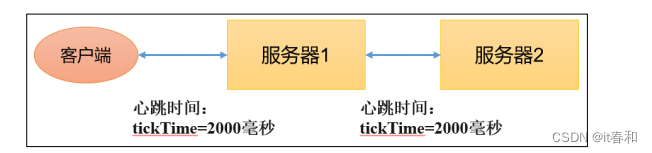
1、tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
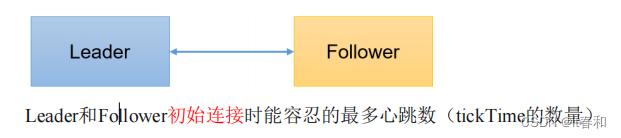
2、initLimit = 10:LF初始通信时限
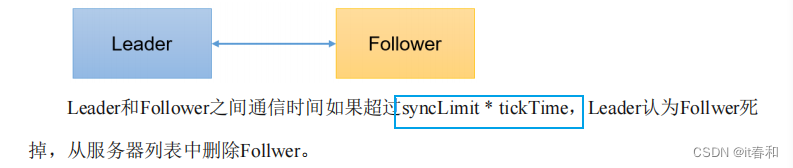
3、syncLimit = 5:LF同步通信时限
4、dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录
5、clientPort = 2181:客户端连接端口,通常不做修改。
二、zookeeper集群安装
1、集群规划
在hadoop02、hadoop03 hadoop04上部署zookeeper
2、解压安装
因为已经在hadoop02上安装过zookeeper了
在hadoop02上的zkData目录下创建一个myid的文件
vi myid
在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
3、将zookeeper·分发到其他两台机器上
并分别在 hadoop03、hadoop04 上修改 myid 文件中内容为 3、4
xsync zookepper-3.5.7
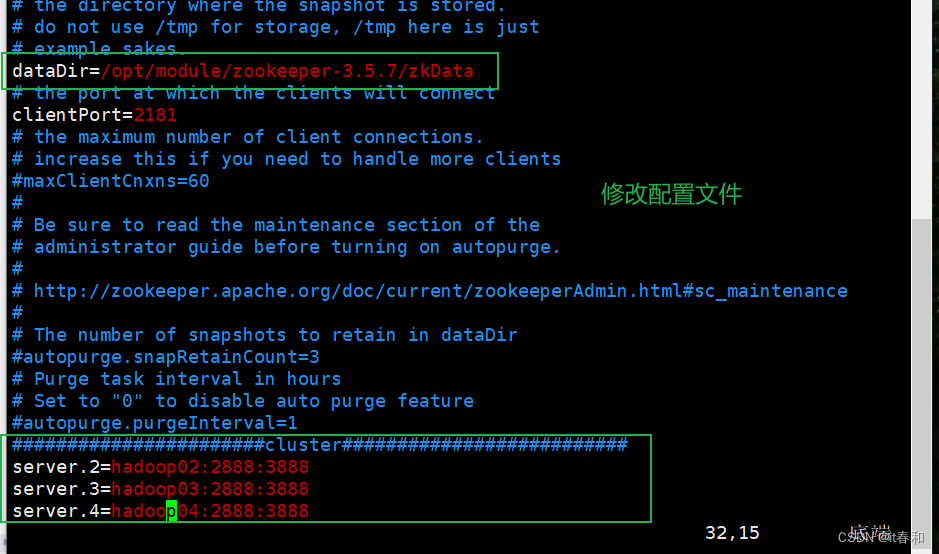
4、配置zoo.cfg文件
【1】重命名/opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
【2】打开 zoo.cfg 文件
【3】配置
#修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
#增加如下配置
#######################cluster##########################
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
server.4=hadoop04:2888:3888
【4】配置参数解读
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据 就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比
较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的
Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5、同步zoo.cfg文件
xsync zoo.cfg
6、集群操作
分别启动zookeeper
[zhou@hadoop02 zookeeper-3.5.7]$ bin/zkServer.sh start
[zhou@hadoop03 zookeeper-3.5.7]$ bin/zkServer.sh start
[zhou@hadoop04 zookeeper-3.5.7]$ bin/zkServer.sh start
查看状态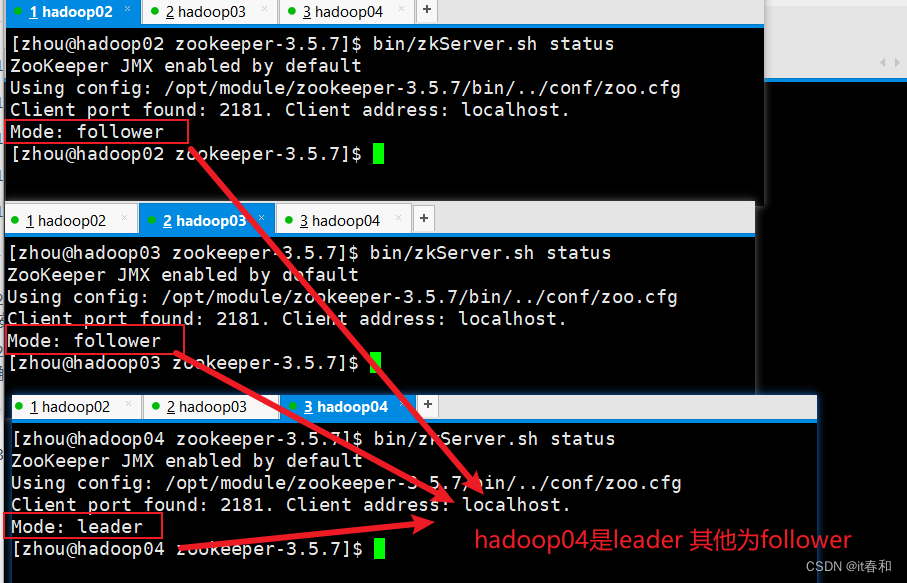
7、zookeeper集群启动脚本
1、在 hadoop02 的/home/zhou/bin 目录下创建脚本
vim zk.sh
#!/bin/bashcase$1in"start"){foriin hadoop02 hadoop03 hadoop04
doecho ---------- zookeeper $i 启动 ------------
ssh$i"/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"done};;"stop"){foriin hadoop02 hadoop03 hadoop04
doecho ---------- zookeeper $i 停止 ------------
ssh$i"/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"done};;"status"){foriin hadoop02 hadoop03 hadoop04
doecho ---------- zookeeper $i 状态 ------------
ssh$i"/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"done};;esac
增加脚本的执行权限
chmode u+x zk.sh
分发 xsync zk.sh
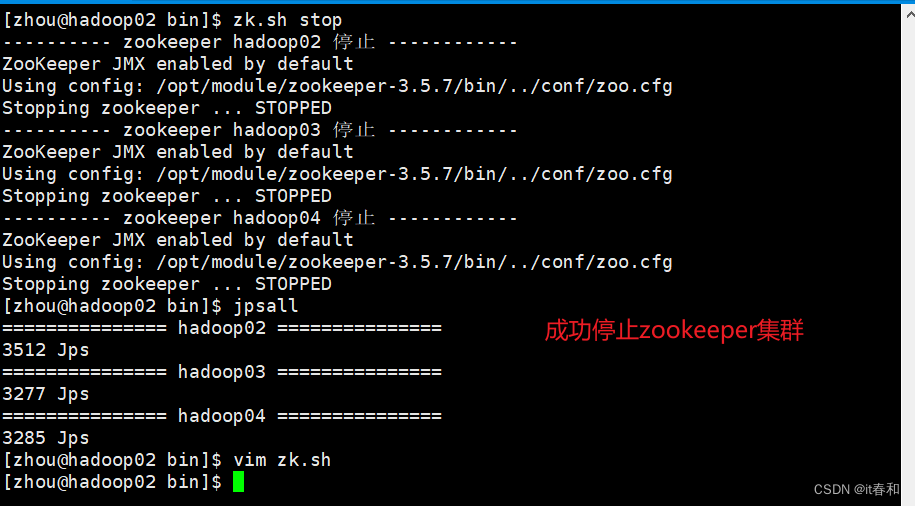
测试
zk.sh stop
停止zookeeper集群
zk.sh start
启动zookeeper集群
zk.sh status
查看zookeeper集群状态
版权归原作者 it春和 所有, 如有侵权,请联系我们删除。