
transformer 彻底改变了自然语言处理,并在神经机器翻译,分类和命名实体识别等领域进行了重大改进。最初,transformer 在时间序列领域很难应用。但是在过去的一年半中,出现了一些用于时间序列分类和预测的transformer 变体。我们已经看到了诸如时间融合,卷积,双阶段注意力模型以及更多尝试进入时间序列的模型。最新的Informer模型建立在这一趋势的基础上,并合并了几个新的组件。
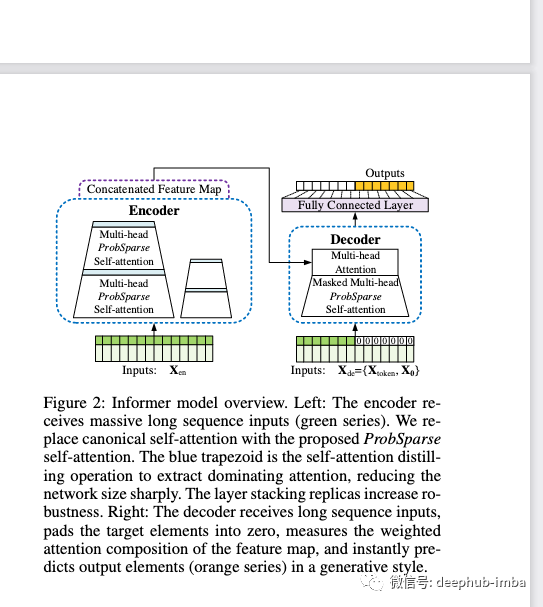
Informer旨在改善自我注意机制,减少记忆使用,加快推理速度。Informer同时利用了transformer 编码器层和(掩码)transformer 解码器层。该解码器可以有效地在一次前向传递中预测长序列。当预测长序列时,这一特性有助于加快推理速度。Informer模型采用概率注意机制来预测长序列。Informer还包括学习嵌入相关的时间特征。这允许模型生成一个有效的基于任务的时间表示。最后,Informer同样可以根据任务的复杂性堆栈n个级别的编码器和解码器。
概率vs全注意力
为了减少自注意的时间复杂性,作者引入了概率注意。与传统的O(L²)相比,这种概率注意力机制实现了O(L log L)复杂度。传统的自注意存在这样的问题:只有少数k、v对注意力分数起主要作用。这意味着大多数计算出来的点积实际上毫无价值。稀疏注意力 ProbSparse允许每个k只关注主要的查询q,而不是所有的查询。这使模型仅能为查询/值张量的一小部分计算进行昂贵的运算。特别是ProbSparse机制还具有一个因素,可以指定预测。该因数控制着您减少注意力计算的程度。
基准数据集测试
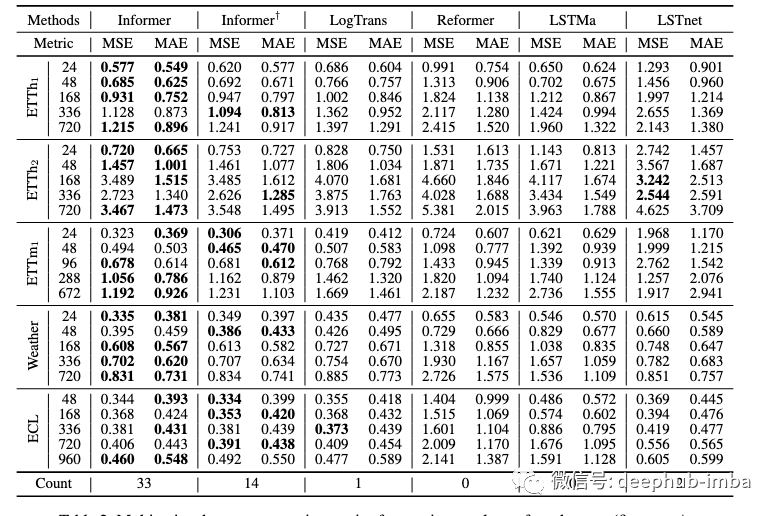
作者在几个主要与电力预测有关的时间序列数据集上对Informer进行了基准测试:特别是电力变压器和用电负荷。他们测试了预测几个不同时间间隔数据的模型,包括在天气预报数据集上测试了模型。他们使用MSE和MAE作为评估指标,并将Informer的性能与其他几种transformer 变型以及流行的LSTM模型进行比较。
将模型移植到流量预测中
尽管与我们的完整transformer模型和Informer模型有相似之处,但将模型移到我们的框架中是一个挑战,原因有几个。最大的问题与我们的训练循环和数据加载器如何将数据传递给模型有关。因此,重构核心功能需要花费大量时间
我们一共做了以下调整
- 增加了详细的解释核心组件的文档字符串
- 重构了几个函数,以改善代码的整洁性和体系结构
- 像其他流量预测模型一样,允许在多个目标之间进行交换
我们仍在用我们的格式验证模型是否能再现原始论文的结果。然而,我们希望很快就能完成。
我们现在有几个关于如何在流量预测中使用Informer进行时间序列预测的教程。您可以访问这个Kaggle 代码(https://www.kaggle.com/isaacmg/pytorch-time-series-forecasting-with-the-informer),以获得使用Informer的快速教程。
论文地址:https://arxiv.org/abs/2012.07436
本文作者:Isaac Godfried
原为地址:https://towardsdatascience.com/adding-the-informer-model-to-flow-forecast-f866bbe472f0
deephub翻译组