
文章目录
前言
在上文我们曾小小的提到过,在
索引失效
的情况下,MySQL会把
所有聚集索引记录和间隙
都锁上,我们称之为
锁表
,或叫
行锁升表锁
.
那么对于
行锁升表锁
,有的同学误以为行锁 升级变成了 表锁,但实际上
锁的类型并没有发生变化
✍️,还是行锁! 只是表的所有聚集索引记录都被加上了行锁, 看起来像表锁, 所以提前澄清一下, 举个例子:
假设,表中有10万多条记录
行锁升表锁会给10万多条索引记录加行锁, 锁的粒度小, 但开销非常大,示意图如下:
- 直接加
表锁只会加1个表锁,锁的粒度大, 但开销非常小,示意图如下:
OK, 相信已经澄清了~ 那么对于
行锁升表锁
, 我们应该如何避免呢? 如果真被行锁锁表了又该如何分析排查呢? 别着急, 我们一步一步来, 干货满满, 建议先
收藏
!后面如果有需要了, 直接能找到这里来看.
哪些场景会造成行锁升表锁?
兵法有云:知己知彼,百战不殆!
所以在说如何避免之前,我们提前说一下哪些场景会造成行锁升表锁,建议还未看过前面两文的小伙伴先了解一下加锁规则:
【MySQL】说透锁机制(一)行锁 加锁规则 之 等值查询
【MySQL】说透锁机制(二)行锁 加锁规则 之 范围查询(你知道会锁表吗?)
那么对于看过前两篇文章的小伙伴,应该已经猜到了,场景肯定和
索引
有关!
没错, 就是 **
无索引
或
索引失效
!**
那么原因呢? 你想过这里的原因吗?
**
解读
:因为InnoDB引擎的 3种行锁算法(Record Lock、Gap Lock、Next-key Lock),都是锁定的索引,当触发X锁(写锁)的where条件无索引 或 索引失效** 时, 查找的方式就会变成全表扫描,也就是扫描所有的聚集索引记录,到这我想大家都应该看懂了,但是可能还有个疑问,
为什么要把不匹配的记录也加锁呢?
这里是针对于
默认
的事务隔离级别:
可重复读(RR)
事务隔离级别来说的, 因为在RR隔离级别下,需要解决
不可重复读
和
幻读
问题, 所以
在遍历扫描聚集索引记录
时, 为了
防止
扫描过的索引被其它事务修改(
不可重复读问题
) 或 间隙被其它事务插入记录(
幻读问题
), 从而导致数据不一致, 所以MySQL的解决方案就是
把所有扫描过的索引记录和间隙都锁上
, 这也就 发生了我们看到的
锁表
!💪💪💪
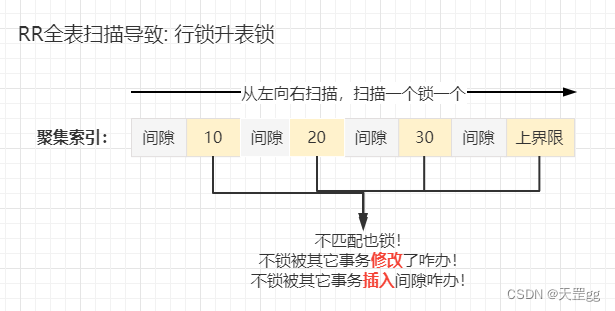
展开来说:
无索引
例如, 下面这个sql的
remark列 不是索引列
, 如果按remark更新就是无索引更新.
update ct set abc =1where remark ='阿根廷';
索引失效
索引失效的情况有很多, 我们本文不分析为什么失效, 也不会列举出所有失效的场景, 因为那不是本节的重点(我会考虑单独安排一篇详细讲解)。 这里直接用
explain
说话:
- explain 返回的
key不是你期望的索引, 而是PRIMARY; - explain 返回的
type是index或all
如果同时满足上面这两个条件, 那么就说明索引失效了!
对于索引失效列几个常见的场景简单说明一下:
- 复合索引未遵循最左前缀原则
例如,我新建一个复合索引:
abc列
和
name列
,如下:
ALTERTABLE`lock_test`.`ct`ADDINDEX`idx_abc_name`(`abc`,`name`);
但更新sql语句未按照最左前缀, 直接按`name=`更新,这样就会**导致索引失效**:
update ct set abc =1where name ='阿根廷';
看一下explain的结果:
- like以%开头
例如,我新建一个普通索引:
name列
:
ALTERTABLE`lock_test`.`ct`ADDINDEX`idx_name`(`name`);
但更新sql语句使用了 like以%开头,这样也会导致索引失效:
update ct set abc =1where name like'%阿根廷';
看一下explain的结果:
- MySQL成本计算分析认为全表扫描成本更低时
这是比较特殊的情况.
同样的SQL, 传入的参数不同, explain的结果也不同
, 有时会走索引, 但有时索引又失效! 😫
这里的原因:因为根据
传入的参数不同 导致 结果集不同
, 在正式扫描之前,MySQL会进行
成本计算
,计算走哪个索引更快!结果一算,发现走索引还不如全表扫描快, 那么这时即使你用的是索引列等值 也不会走索引,会走全表扫描,这也就导致了索引失效!
关于成本计算, 它是先计算不同索引的I/0成本和CPU成本, 然后进行对比, 哪个成本低就采用哪个索引来执行! 当然, 成本计算并不会真实执行, 所以速度非常快, 在上文【范围查询】时曾给过一个小的示例说明,这里不再重复赘述!
当然,索引失效的情况还有很多, 这里只是举几个例子让大家学会用explain分析, 如果不够过瘾,我后面紧接着会更新索引相关文章!记得关注我哦!
如何避免?
此时, 咱们已经清楚的知道了 可能造成 行锁升表锁 的场景,那么应对起来也就更有底气了,我的
建议
是:
- 禁止where条件使用
无索引列进行更新/删除 这是我们最应该做到的!除了会锁表,性能也是真的不好! - 尽可能使用
聚集索引进行更新/删除 这是我们能做到的最优做法! - 确实需要使用
非聚集索引进行更新/删除,需要确认: - 使用explain检查是否会索引失效!- 避免对 索引列 进行类型转换、函数、运算符等会造成升级的情况!- 尽可能减少检索条件范围, 范围越大就越可能被MySQL成本计算太高,从而导致索引失效! - 尽可能控制事务大小,减少锁定时间 涉及事务加锁的sql语句尽可能放在事务最后执行!
- 推荐使用读已提交(RC)事务隔离级别
这条非常重要!对于读已提交(RC)事务隔离级别,由于没有间隙锁(Gap Lock),所以它的加锁规则相当简单,都是针对匹配索引记录加Record Lock,因为不用解决不可重复读和幻读问题,所以也就不存在 锁表了。 > 前面两文咱们说的都是基于可重复读(RR)事务隔离级别,因为引入了>> 间隙锁(Gap Lock)>> ,所以情况变的复杂, 而在RC下, 情况变的简单.
如何分析排查?
咱们只能做到尽可能避免, 根据墨菲定律:
只要有可能 就一定会发生!
所以我们必须掌握
锁表
应该如何
分析排查
!
查看
InnoDB_row_lock%
相关变量
showstatuslike'innodb_row_lock%';

字段说明Innodb_row_lock_current_waits当前正在等待锁定的数量Innodb_row_lock_time
等待总时长
: 从系统启动到现在锁定总时间长度Innodb_row_lock_time_avg
等待平均时长
: 每次等待所花平均时间Innodb_row_lock_time_max从系统启动到现在等待最长的一次所花时间Innodb_row_lock_waits
等待总次数
: 系统启动后到现在总共等待的次数
从上述值,我们可以看出我们行锁的整体情况,有助于我们分析。
查看
INFORMATION_SCHEMA
系统库
我们可以通过 INFORMATION_SCHEMA系统库提供的:查看
事务
、
锁
、
锁等待
的 数据表 来分析.
-- 查看事务select*from INFORMATION_SCHEMA.INNODB_TRX;-- 查看锁select*from INFORMATION_SCHEMA.INNODB_LOCKS;-- 查看锁等待select*from INFORMATION_SCHEMA.INNODB_LOCK_WAITS;-- 查看连接情况select*from INFORMATION_SCHEMA.PROCESSLIST;
- 通过 INNODB_LOCK_WAITS 可以找出
阻塞的事务id和锁id
-- 查看锁等待select*from INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
字段说明requesting_trx_id请求的事务idrequested_lock_id请求的锁idblocking_trx_id阻塞的事务idblocking_lock_id阻塞的锁id
我这里模拟一个锁等待,然后查询,可以清晰的看到
谁阻塞了谁
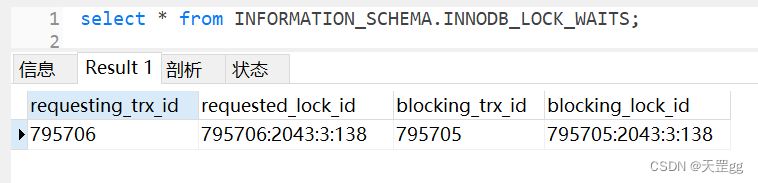
温馨提示:只有发生锁等待才有数据
- 通过 INNODB_LOCKS 可以查看
上锁的详细信息
-- 查看锁select*from INFORMATION_SCHEMA.INNODB_LOCKS;
这和我们通过
show engine innodb status\G;
看到的结果类似, 略…, 也是只有发生阻塞才会有数据.
- 通过 INNODB_TRX 可以查看
事务的状态、阻塞开始时间、阻塞的sql、线程id等等
-- 查看事务select*from INFORMATION_SCHEMA.INNODB_TRX;
这个表很关键
, 对于我们排查来说必不可少, 一些关键字段说明如下:
字段说明trx_id事务idtrx_state事务状态,LOCK WAIT代表发生了锁等待trx_started事务开始时间trx_requested_lock_id请求锁id, 事务当前正在等待锁的标识,可以join关联INNODB_LOCKS.lock_idtrx_wait_started事务开始锁等待的时间trx_weight事务的权重trx_mysql_thread_id事务线程 ID,可以join关联PROCESSLIST.IDtrx_query事务正在执行的 SQL 语句trx_operation_state事务当前操作状态trx_isolation_level当前事务的隔离级别
当发生阻塞时,我们来看一下数据:
一目了然,哪个SQL从什么时间开始阻塞,线程id是多少,看的一清二楚.
- 通过 PROCESSLIST 可以查看
连接情况
-- 查看连接情况select*from INFORMATION_SCHEMA.PROCESSLIST;
通过这个表,我们可以定位到事务所在的主机.
字段说明ID线程ID, 可以JOIN INNODB_TRX.trx_requested_lock_idUSER连接用户HOST连接主机 ip:portDB连接的数据库
- 如何kill某个事务?
通过对上面的表进行查询, 当我们发现某个事务阻塞了很多事务, 并且执行时间很长时, 我们可以手动中止它,
只需要找到INNODB_TRX.trx_mysql_thread_id
,然后调用kill命令:
kill {INNODB_TRX.trx_mysql_thread_id}
总结
本文主要介绍了:
- 哪些场景会造成行锁升表锁
无索引或索引失效 - 如何避免 建议中最重要的一条:尽可能使用
读已提交(RC)事务隔离级别 - 如何分析排查 最重要的两个分析表:
INFORMATION_SCHEMA.INNODB_TRX、INFORMATION_SCHEMA.INNODB_LOCK_WAITS,以及手动中止kill {INNODB_TRX.trx_mysql_thread_id}
最后
如果感觉不错,欢迎订阅本专栏,后面还有更详细的MySQL知识陆续放出。
关注我 天罡gg 分享更多干货: https://blog.csdn.net/scm_2008
大家的「关注 + 点赞 + 收藏」就是我创作的最大动力!谢谢大家的支持,我们下文见!
版权归原作者 天罡gg 所有, 如有侵权,请联系我们删除。