
最近在搞软件工程课程设计,做了一个在线考试系统,为了弄到题库数据,简单利用了python中的selenium库实现对python123平台自动登录并获取相应的选择试题。
实现自动登录并获取题目
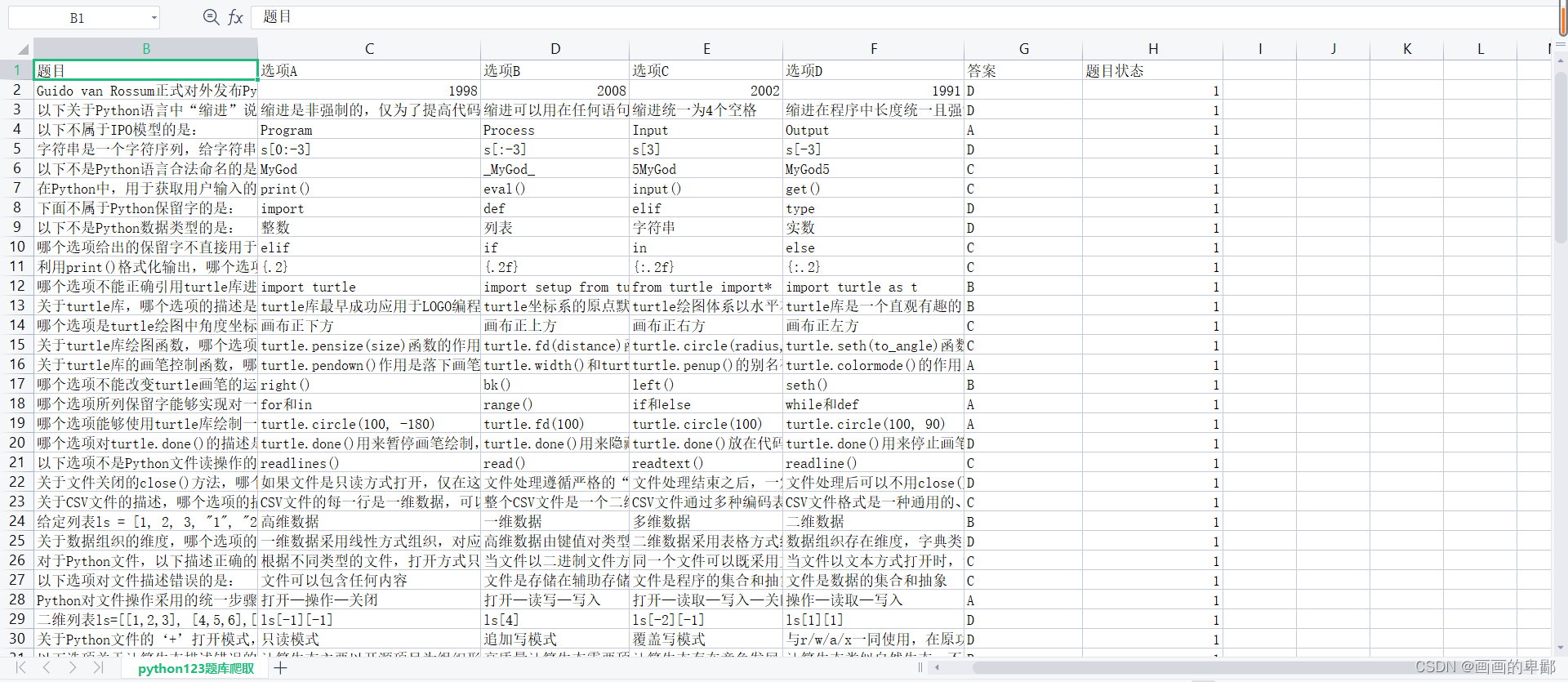
只针对了自己所做过的选择题进行爬取,然后把所得数据存储在excel表格中。
from time import sleep
from selenium.webdriver import Chrome
import csv
datelist = []
def get_element():
web.get("https://www.python123.io/index/login")
uername = web.find_element_by_xpath(
'//*[@id="links"]/div[1]/div[2]/div/div[1]/div[1]/div/div[1]/div/div[1]/div[2]/form/div[1]/div/input')
passworld = web.find_element_by_xpath(
'//*[@id="links"]/div[1]/div[2]/div/div[1]/div[1]/div/div[1]/div/div[1]/div[2]/form/div[2]/div/input')
uername.send_keys('******') # python123官网的用户名
passworld.send_keys('******') # python123的账户密码
login = web.find_element_by_xpath(
'//*[@id="links"]/div[1]/div[2]/div/div[1]/div[1]/div/div[1]/div/div[1]/div[2]/div[3]/div[1]/button')
login.click()
sleep(2)
#选择课程
web.find_element_by_xpath(
'//*[@id="app"]/div/div[1]/div[1]/div[1]/nav/div[2]/div[1]/a[2]').click()
sleep(2)
#选择对应的课
web.find_element_by_xpath(
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div[1]/div[2]/div/div/div/figure/img').click()
sleep(2)
#选择课程任务
web.find_element_by_xpath(
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div/div/div[1]/div/div/div/div[1]/div[3]/a[2]').click()
sleep(2)
def parse_questionlist(datelist):
#获取题目信息
list = web.find_elements_by_css_selector('div[class="card-content is-clipped"]')
for li in list:
date = []
timu = li.find_element_by_css_selector('div[class="mce-content-body"]').text # 题目信息
#print(timu)
date.append(timu)
xuanxiang = li.find_elements_by_css_selector('div[class="content content"]')
for xuan in xuanxiang:
Choose = xuan.find_element_by_css_selector('div[class="mce-content-body"]').text # 选项
date.append(Choose)
#print(Choose)
answer = li.find_element_by_css_selector('div.answers.rightanswer > span:nth-child(4)').text # 答案
date.append(answer)
#print(answer)
datelist.append(date)
return datelist
def piliang_sava():
#每个测试对应的selector
num = [
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[1]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[2]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[3]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[4]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[5]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[6]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[7]/div',
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[2]/div/div/div/div/div[2]/div[2]/div/div[8]/div'
]
# 退出
for i in range(0,8):
# 选择测试
sleep(5)
web.find_element_by_xpath(num[i]).click()
sleep(5)
# 查看选择题
web.find_element_by_xpath(
'//*[@id="group-wrapper"]/div/div[2]/div[1]/div/a[4]').click()
parse_questionlist(datelist)
sleep(5)
web.find_element_by_xpath(
'//*[@id="app"]/div/div[1]/div[1]/div[2]/section/div/div/div[1]/div/div/div/ul[2]/li[2]/a').click()
return datelist
def sava_data(datelist):
f = open('python123题库爬取.csv','w',encoding='utf-8-sig',newline="")
csv_write = csv.writer(f)
csv_write.writerow(['题目', '选项A', '选项B', '选项C', '选项D','答案','题目状态'])
for data in datelist:
csv_write.writerow([data[0], data[1], data[2], data[3], data[4],data[5],'1'])
f.close()
if __name__ == '__main__':
web = Chrome()
web.maximize_window()
get_element()
tiku = piliang_sava()
#print(tiku)
sava_data(tiku)
ps:初学python,可能有些地方不足,希望大家指点!
本文转载自: https://blog.csdn.net/qidou5/article/details/125556958
版权归原作者 画画的卑鄙 所有, 如有侵权,请联系我们删除。
版权归原作者 画画的卑鄙 所有, 如有侵权,请联系我们删除。