
背景
Apache Flink 是一个开源的流处理和批处理框架,具有高吞吐量、低延迟的流式引擎,支持事件时间处理和状态管理,以及确保在机器故障时的容错性和一次性语义。Flink 的核心是一个分布式流数据处理引擎,支持 Java、Scala、Python 和 SQL 编程语言,可以在集群或云环境中执行数据流程序。它提供了 DataStream API 用于处理有界或无界数据流,DataSet API 用于处理有界数据集,以及 Table API 和 SQL 接口用于关系型流和批处理。目前 Flink 最新已经迭代至 1.20 版本,在此过程中不光是 Flink 框架,插件本身也有部分 API 以及配置存在变更,本文主要针对较高版本的 1.17 Flink Pulsar 插件进行测试验证,目前 Flink 版本如下: https://nightlies.apache.org/flink/
部署 Flink
设置 Flink 环境配置
参考 Flink 1.17 官方文档,部署 Flink Docker 版本 https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/resource-providers/standalone/docker/#getting-started
首先配置 Flink 集群 JobManager 和 TaskManager 环境信息,注意由于 Connector Pulsar 会使用到堆外内存,并且默认任务的堆外内存为 0,因此此处需要显式声明堆外内存大小 taskmanager.memory.task.off-heap.size,这里设置为 1GB https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/memory/mem_setup_tm/#configure-off-heap-memory-direct-or-native
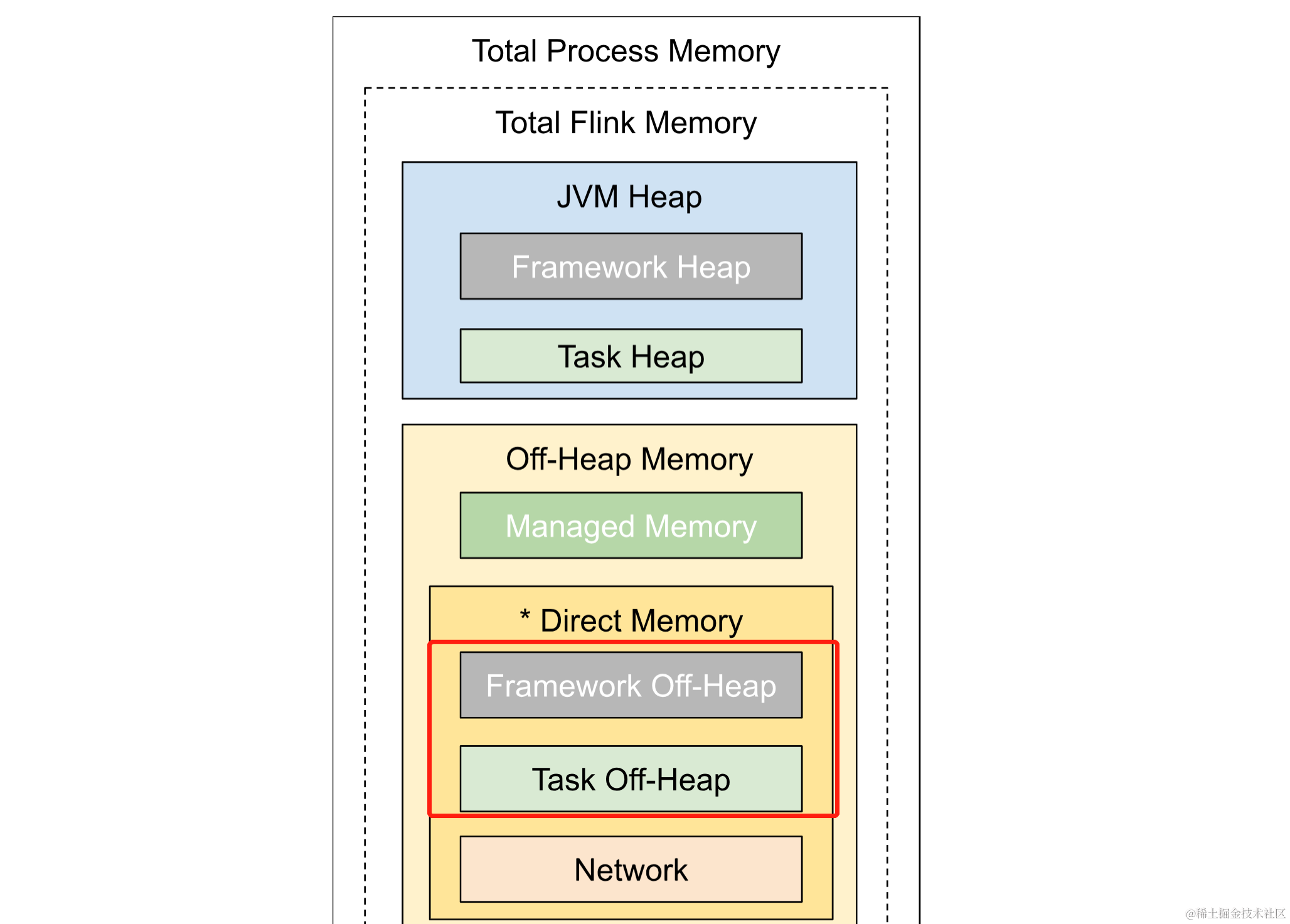
$ FLINK_PROPERTIES=$'\njobmanager.rpc.address:
jobmanager\ntaskmanager.memory.task.offheap.size:
1gb\ntaskmanager.memory.process.size: 4gb'
$ docker network create flink-network
部署 JobManager
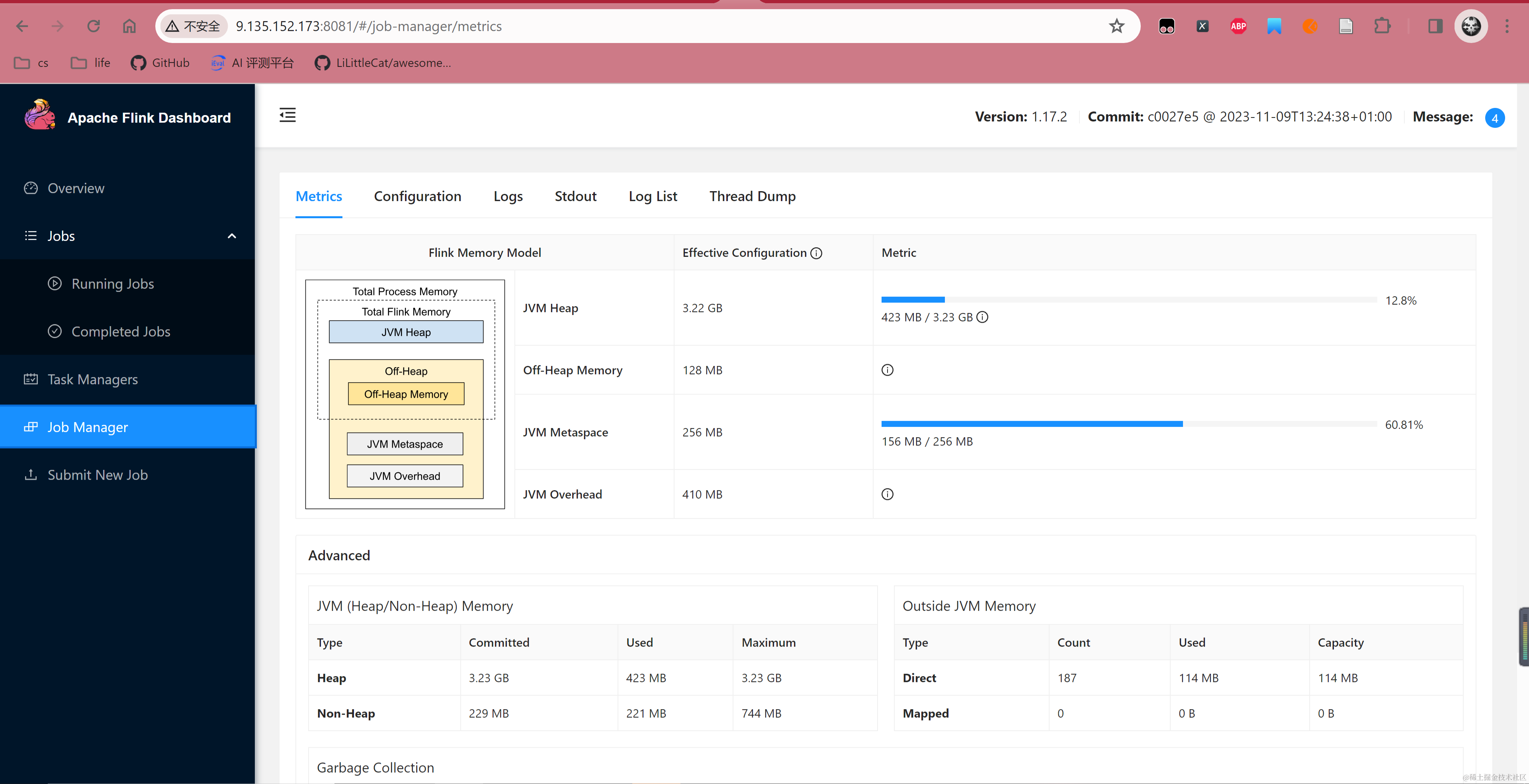
配置环境变量后部署 JobManager,这里默认映射端口为 8081,部署后登录 8081 端口可以看到 Flink Dashboard 信息。
$ docker run \
--rm \
--name=jobmanager \
--network flink-network \
--publish 8081:8081 \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:1.17.2-scala_2.12 jobmanager
部署 TaskManager
JobManager 是维护协调任务的组件,部署 JobManager 后还需要部署具体运行任务的 TaskManager。
$ docker run \
--rm \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:1.17.2-scala_2.12 taskmanager
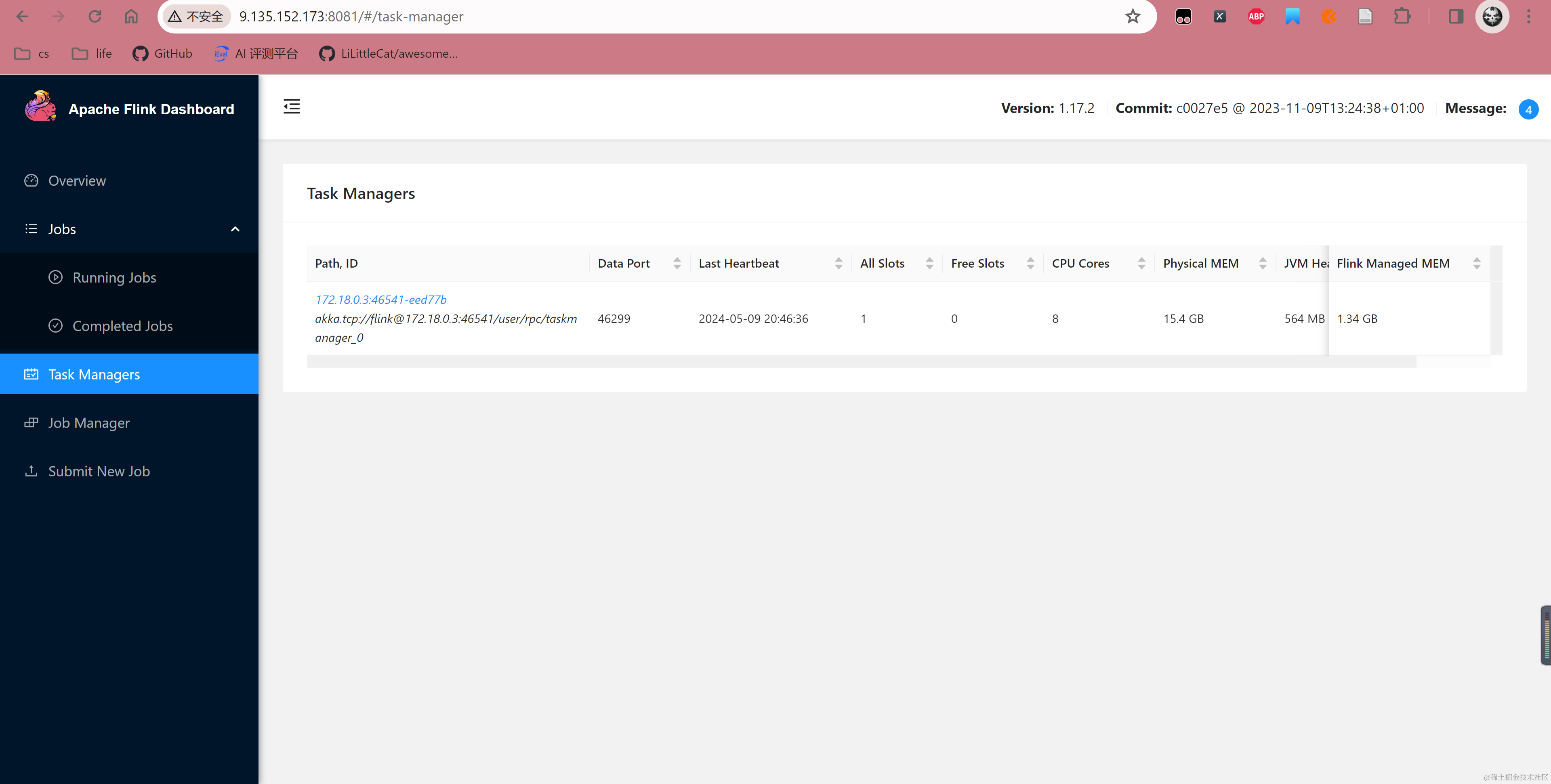
运行 TaskManager 后,可以在 8081 JobManager 控制台看到 TaskManager 已经被成功注册,至此 Flink Docker 组件部署完成。
下载 Flink Cli
在本地编译打包 Pulsar 任务后,还需要使用 Flink Cli 提交本地任务到 Flink Docker 集群,从下方网址下载与当前 Docker 版本一致的 Flink 二进制文件并且解压到本地。 https://flink.apache.org/downloads/
Demo:Topic 复制
参考 Flink Pulsar Connector 社区文档和 Oceanus 相关文档,Demo 使用 1.17 版本 Flink SDK 将命名空间的一个 Topic 消息全部复制到另一个 Topic 中,Demo 主要展示 Flink Connector 的基础用法,没有使用自定义序列化器及反序列化器,而是使用的是 Connector 内置的 String 序列化器。 https://cloud.tencent.com/document/product/849/85885#pulsar-source-.E5.92.8C-sink-.E7.A4.BA.E4.BE.8B https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/pulsar/#apache-pulsar-connector
主要逻辑
核心逻辑见下方代码,首先使用 ParameterTool 工具解析命令行中传入的参数,之后根据参数信息使用 Connector Source 和 Sink Builder 方法创建一个从 InputTopic 中获取消息发送到 OutputTopic 的 Flink Stream。
public static void main(String[] args) throws Exception {
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
if (parameterTool.getNumberOfParameters() < 2) {
System.err.println("Missing parameters!");
return;
}
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(60000);
env.getConfig().setGlobalJobParameters(parameterTool);
String brokerServiceUrl =
parameterTool.getRequired("broker-service-url");
String inputTopic =
parameterTool.getRequired("input-topic");
String outputTopic =
parameterTool.getRequired("output-topic");
String subscriptionName =
parameterTool.get("subscription-name", "testDuplicate");
String token = parameterTool.getRequired("token");
// source
PulsarSource<String> source = PulsarSource.builder()
.setServiceUrl(brokerServiceUrl)
.setStartCursor(StartCursor.latest())
.setTopics(inputTopic)
.setDeserializationSchema(new
SimpleStringSchema())
.setSubscriptionName(subscriptionName)
.setAuthentication("org.apache.pulsar.client.impl.auth.AuthenticationToken", token)
.build();
DataStream<String> stream = env.fromSource(source,
WatermarkStrategy.noWatermarks(), "Pulsar Source");
// sink
PulsarSink<String> sink = PulsarSink.builder()
.setServiceUrl(brokerServiceUrl)
.setTopics(outputTopic)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setAuthentication("org.apache.pulsar.client.impl.auth.AuthenticationToken", token)
.setConfig(PulsarSinkOptions.PULSAR_BATCHING_ENABLED, false)
.setSerializationSchema(new
SimpleStringSchema())
.build();
stream.sinkTo(sink);
env.execute("Pulsar Streaming Message Duplication");
}
验证
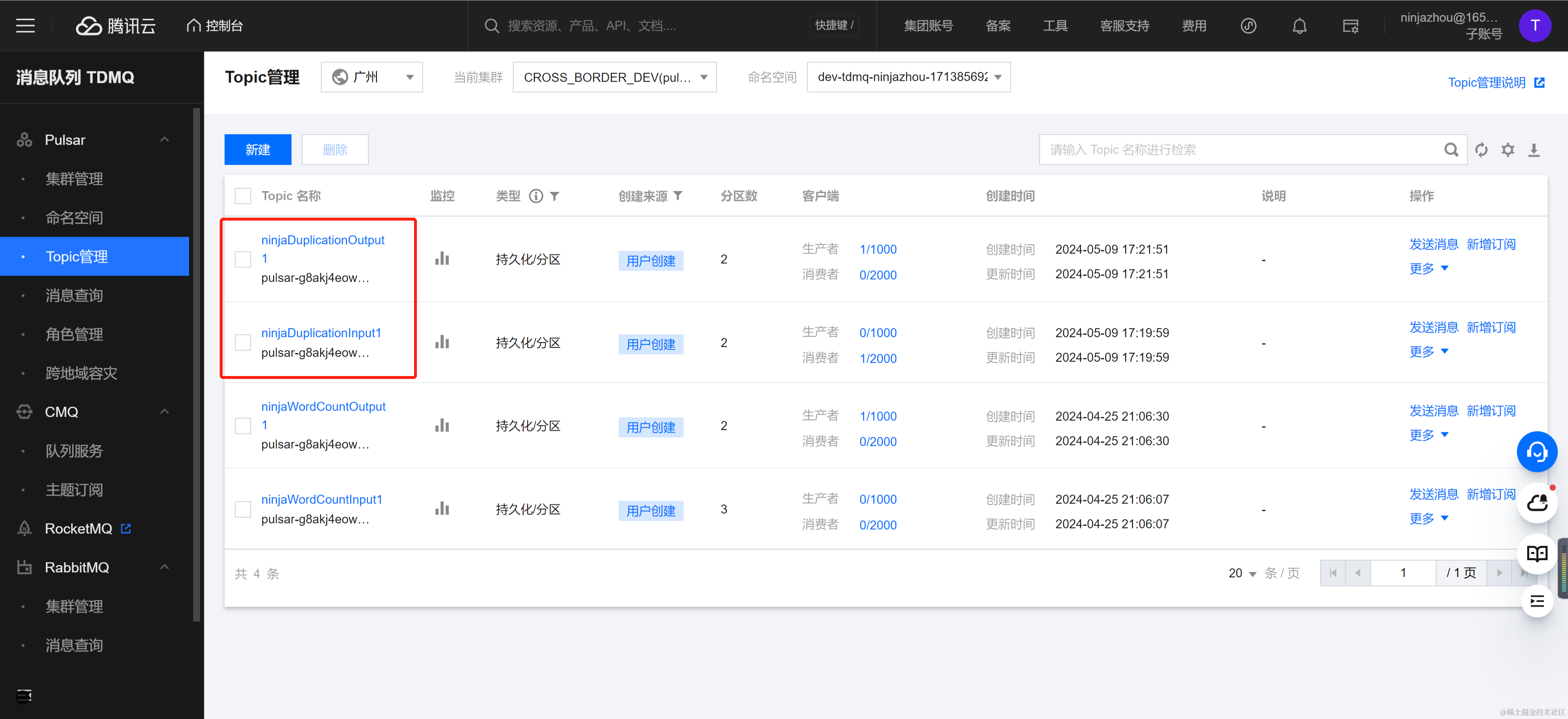
在 TDMQ Pulsar 版控制台创建流入 Topic NinjaDuplicationInput1 和流出 Topic NinjaDuplicationOutput1。
代码编译为 Jar 包后,本地上传 Jar 包到 Flink Docker,从角色管理界面获取具有生产和消费角色的 token,命令如下所示:
/usr/local/services/flink/flink-1.17.2 #
/usr/local/services/flink/flink-1.17.2/bin/flink run
/tmp/wordCount/pulsar-flink-examples-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
--broker-service-url http://pulsar-xxxxx \
--input-topic
pulsar-g8akj4eow8z8/dev-tdmq-ninjazhou-1713856927/ninjaDuplicationInput1 \
--outputtopic
pulsarg8akj4eow8z8/devtdmqninjazhou1713856927/ninjaDuplicationOutput1 \
--subscription-name ninjaTest1 \
--token
eyJrZXlJZCI6InB1bHNhci1nOGFrajRlb3c4ejgiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJwdWxzYXItZzhha2o0ZW93OHo4X2Rldi10ZG1xLW5pbmphemhvdS0xNzEzODU2OTI3LWRldmNsb3VkIn0.O89TuTl0PMca7tLN9aGvHvqt7QZ9yMrJh1z3VOz7EVc
Job has been submitted with JobID
c1bdab89c01ef16e00579bd2c6648859
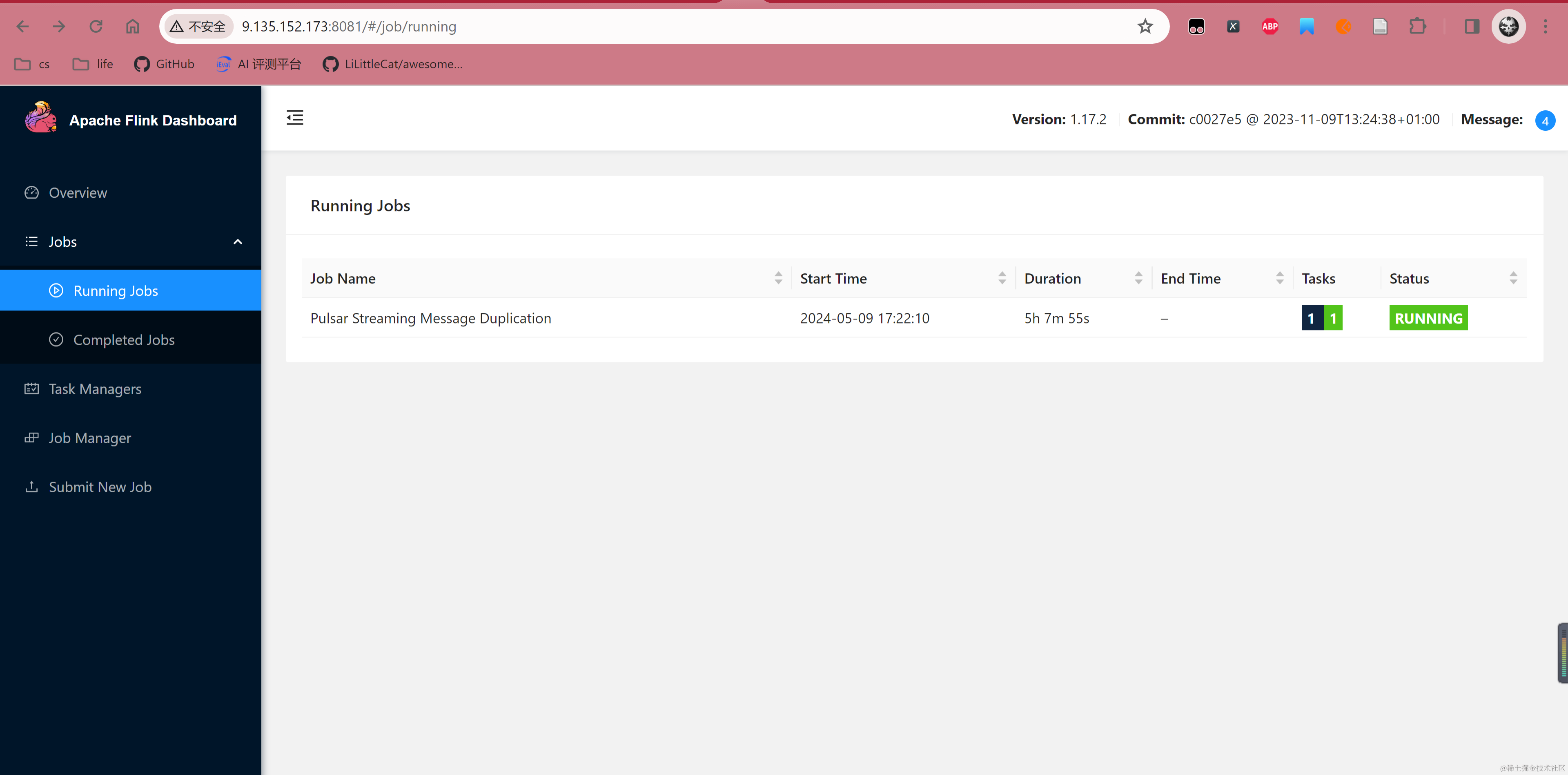
提交任务后,可以看到 Flink Dashboard 出现对应任务,并且状态处于 Running。
在命令行往 NinjaDuplicationInput1 Topic 发送消息。
/usr/local/services/pulsar/apache-pulsar-2.9.5/bin/pulsar-client \
--url http://pulsar-xxxxxx \
--auth-params token:eyJrZXlJZCI6InB1bHNhci1nOGFrajRlb3c4ejgiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJwdWxzYXItZzhha2o0ZW93OHo4X2Rldi10ZG1xLW5pbmphemhvdS0xNzEzODU2OTI3LWRldmNsb3VkIn0.O89TuTl0PMca7tLN9aGvHvqt7QZ9yMrJh1z3VOz7EVc \
--auth-plugin org.apache.pulsar.client.impl.auth.AuthenticationToken \
produce \
-m "i am the bone of my sword" \
-n 5 \
pulsar-g8akj4eow8z8/dev-tdmq-ninjazhou-1713856927/ninjaDuplicationInput1
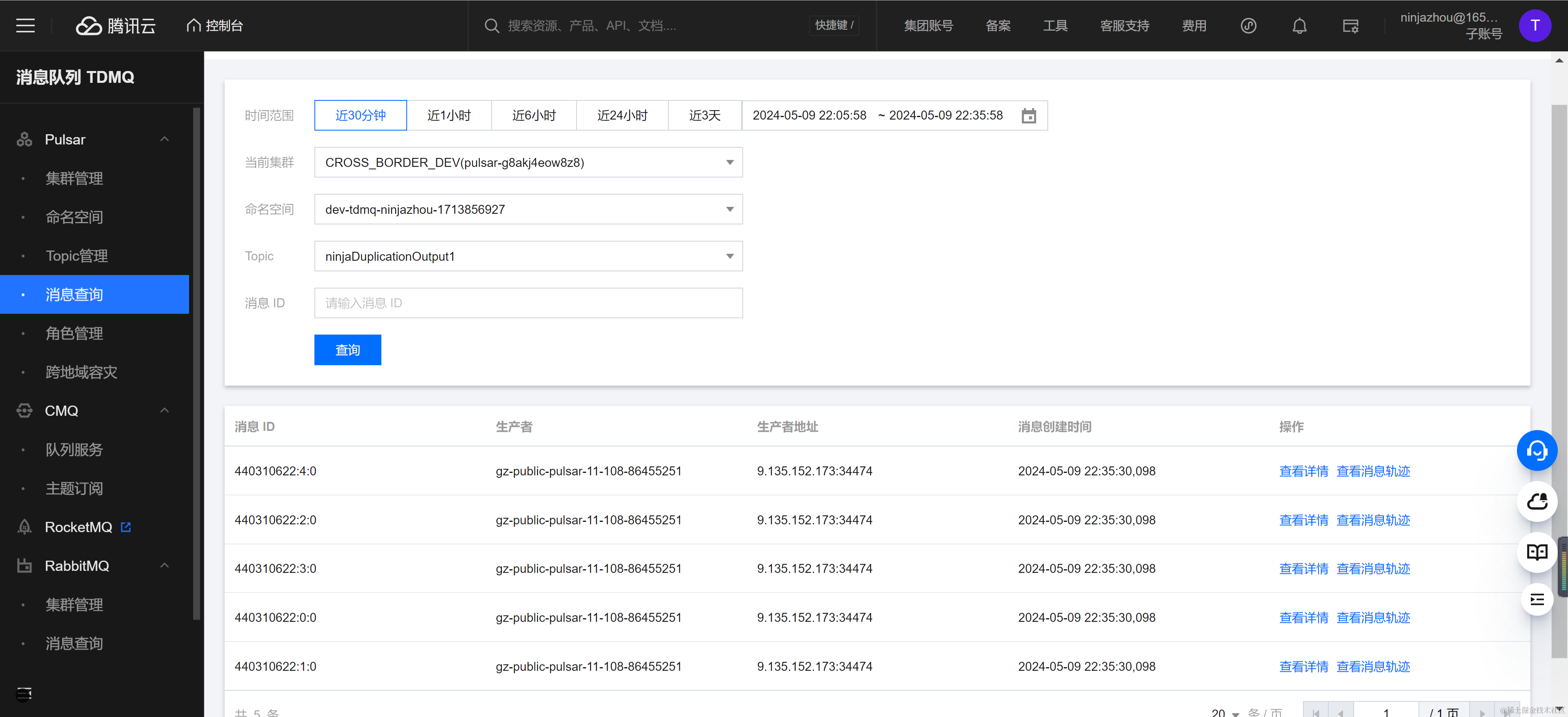
消息发送完成后,可以在消息查询控制台观察到目标 Topic NinjaDuplicationOutput1 也出现了五条消息,并且消息内容和发送消息一致。
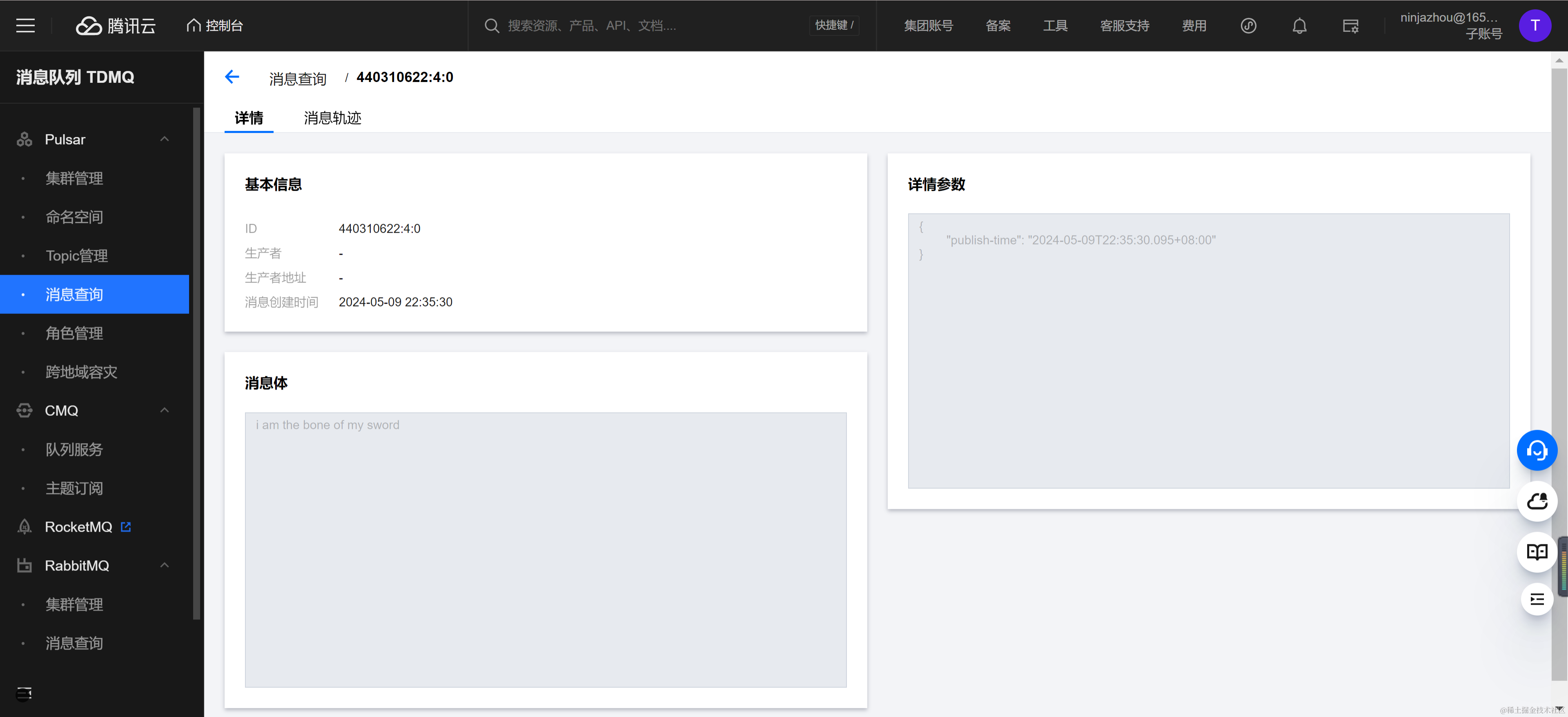
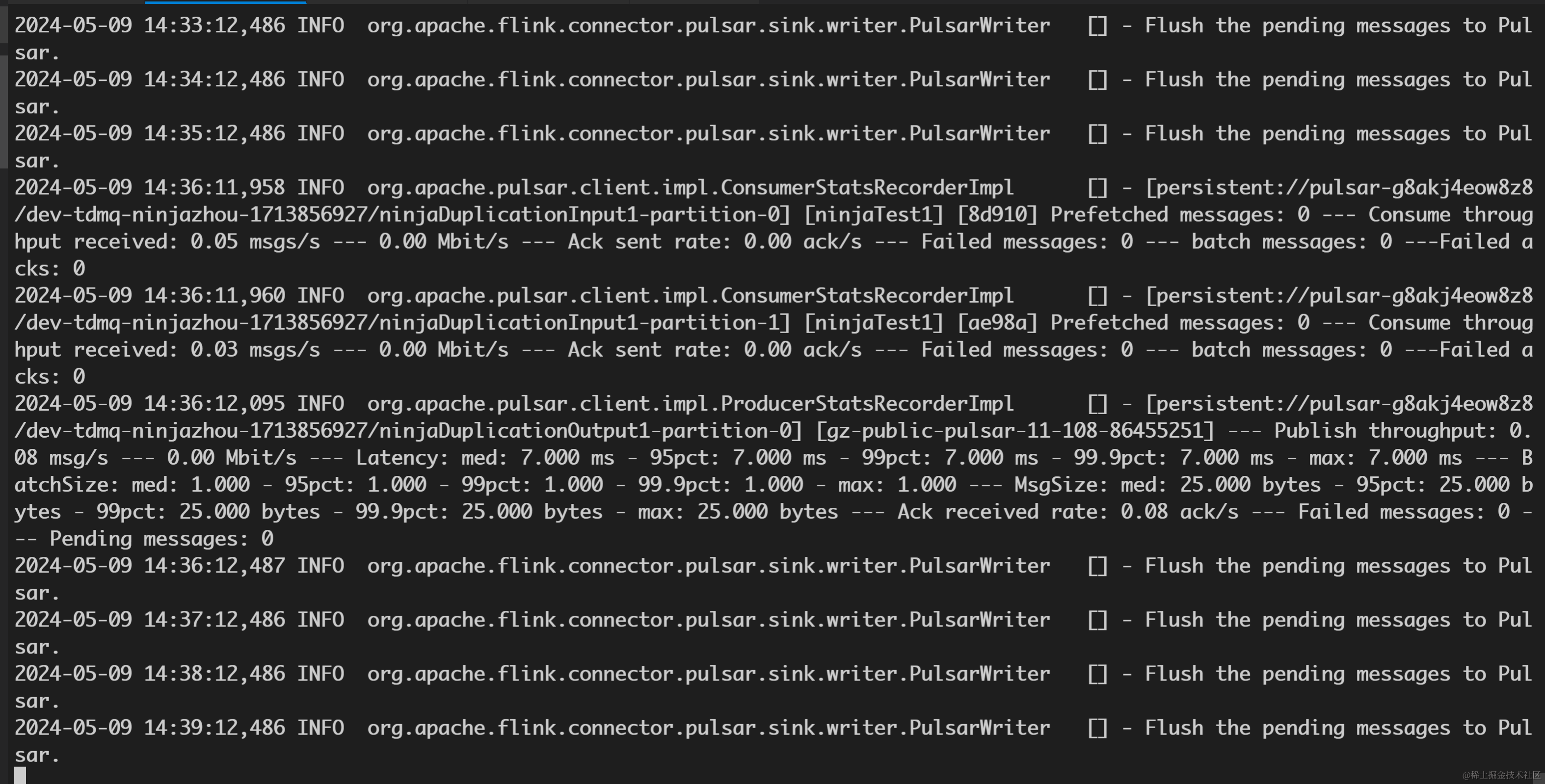
查看 Docker TaskManager 标准输出也能观察到 Sink 往目标 Topic 发送消息的日志。
Demo:单词计数
单词计数作为 Flink 中最常见的 Demo,能够比较好的阐述 Flink 的流处理思想。此 Demo 参考 StreamNative 的 Demo,使用 1.17 Flink SDK,将 Pulsar Topic 作为源和目标资源,统计源 Topic 消息中每个时间窗口各个单词出现的次数,并且将结果投递到目标 Topic 中。 https://github.com/streamnative/examples/blob/master/pulsar-flink/README.md
主要逻辑
整体 Demo 项目文件见下方链接 pulsar-flink-example.zip 核心逻辑见下方代码,首先使用 ParameterTool 工具解析命令行中传入的参数,之后使用 Flink 内置的反序列化器解析消息体为字符串,在数据处理部分使用系统时间窗口统计时间窗内流入的消息,并且对于每个出现的单词汇聚生成 WordCount 对象,最后使用自定义的序列化器,将 WordCount 对象序列化为 Json 字节数组,投递到目标 Topic 中。 目前 TDMQ pulsar Connector 支持 Pulsar Schema、Flink Schema 以及自定义序列化器三种方法将 Java 对象序列化为 Pulsar Sink 的字节数组消息体。推荐代码使用自定义序列化器的方式序列化定义的 WordCount 对象
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/pulsar/#serializer
还需要注意默认 Sink 配置是开启 Batch Send 模式的,在控制台消息查询时,Batch Message 只会查询到 Batch 中的第一条消息,不利于对照消息数量,Demo 中关闭了 Batch Send 功能。
/**
* 参考 streamNative pulsar flink demo
* <a href="https://github.com/streamnative/examples/tree/master/pulsar-flink">pulsar-flink example</a>
* 由于上方链接的 streamNative flink demo 使用 1.10.1 版本 flink 以及 2.4.17 版本 pulsar connector,
* 与当前 1.20 社区版本的 flink 和 pulsar connector api 已经存在部分 api 差异
* 因此本 demo 使用 1.17 flink 版本进行重构
* <a href="https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/resource-providers/standalone/overview/">1.17 flink doc</a>
* <p>
* demo 统计时间窗口内源 topic 所有消息中每个单词出现频率次数
* 并且将统计结果按照每个单词对应一条消息的格式,序列化后消息后投递到目标 topic 中
*
*/
public class PulsarStreamingWordCount {
private static final Logger LOG = LoggerFactory.getLogger(PulsarStreamingWordCount.class);
public static void main(String[] args) throws Exception
{
// 解析任务传参
// 默认使用 authToken 方式鉴权
final ParameterTool parameterTool =
ParameterTool.fromArgs(args);
if (parameterTool.getNumberOfParameters() < 2) {
System.err.println("Missing parameters!");
return;
}
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(60000);
env.getConfig().setGlobalJobParameters(parameterTool);
String brokerServiceUrl =
parameterTool.getRequired("broker-service-url");
String inputTopic =
parameterTool.getRequired("input-topic");
String outputTopic =
parameterTool.getRequired("output-topic");
String subscriptionName =
parameterTool.get("subscription-name", "WordCountTest");
String token = parameterTool.getRequired("token");
int timeWindowSecond = parameterTool.getInt("time-window", 60);
// source
PulsarSource<String> source =
PulsarSource.builder()
.setServiceUrl(brokerServiceUrl)
.setStartCursor(StartCursor.latest())
.setTopics(inputTopic)
// 此处将 message 中的 payload 序列化成字符串类型
// 目前 source 只支持解析消息 payload 中的内容,将 payload 中的内容解析成 pulsar schema 对象或者自定义的 class 对象
// 而无法解析 message 中 properties 中的其他属性,例如 publish_time
// 如果需要解析 message 中的 properties,需要在继承类中实现 PulsarDeserializationSchema.getProducedType() 方法
// getProducedType 这个方法实现较为繁琐,需要声明每个反序列化后的属性
//
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/pulsar/#deserializer
.setDeserializationSchema(new
SimpleStringSchema())
.setSubscriptionName(subscriptionName)
.setAuthentication("org.apache.pulsar.client.impl.auth.AuthenticationToken", token)
.build();
// 由于此处没有使用消息体中的时间,即没有使用消息的 publish_time
// 因此此处使用 noWatermark 模式,使用 taskManager 的时间作为时间窗口
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Pulsar Source");
// process
// 解析 source 中每行消息,通过空格分割成单个单词,之后进行汇聚处理并且初始化成 WordCount 结构体
// 这里使用 TumblingProcessingTimeWindows,即使用当前 taskManager 系统时间计算时间窗口
DataStream<WordCount> wc = stream
.flatMap((FlatMapFunction<String, WordCount>) (line, collector) -> {
LOG.info("current line = {}, word list = {}", line, line.split("\\s"));
for (String word : line.split("\\s")) {
collector.collect(new
WordCount(word, 1, null));
}
})
.returns(WordCount.class)
.keyBy(WordCount::getWord)
.window(TumblingProcessingTimeWindows.of(Time.seconds(timeWindowSecond)))
.reduce((ReduceFunction<WordCount>) (c1, c2) -> {
WordCount reducedWordCount = new WordCount(c1.getWord(), c1.getCount() + c2.getCount(), null);
LOG.info("previous [{}] [{}], current wordCount {}", c1, c2, reducedWordCount);
return reducedWordCount;
});
// sink
// 目前 1.17 flink 序列化提供了两种已经实现的方法,一种是使用 pulsar 内置 schema,另一种是使用 flink 的 schema
// 但由于目前 tdmq pulsar 提供的是 2.9 版本的 pulsar,对于 schema 支持还不够完善
// 此处使用 flink PulsarSerializationSchema<T> 提供的接口,当前主要需要实现 serialize(IN element, PulsarSinkContext sinkContext) 方法
// 将传入的 IN 对象自定义序列化为 byte 数组
// https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/pulsar/#serializer
PulsarSink<WordCount> sink = PulsarSink.builder()
.setServiceUrl(brokerServiceUrl)
.setTopics(outputTopic)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setAuthentication("org.apache.pulsar.client.impl.auth.AuthenticationToken", token)
.setConfig(PulsarSinkOptions.PULSAR_BATCHING_ENABLED, false)
.setSerializationSchema(new PulsarSerializationSchema<WordCount>() {
private ObjectMapper objectMapper;
@Override
public void open(
SerializationSchema.InitializationContext initializationContext,
PulsarSinkContext sinkContext,
SinkConfiguration sinkConfiguration)
throws Exception {
objectMapper = new ObjectMapper();
}
@Override
public PulsarMessage<?> serialize(WordCount wordCount, PulsarSinkContext sinkContext) {
// 此处将 wordCount 添加处理时间后,将 wordCount 使用 json 方式序列化为 byte 数组
// 以便能够直接查看消息体内容
byte[] wordCountBytes;
wordCount.setSinkDateTime(LocalDateTime.now().toString());
try {
wordCountBytes = objectMapper.writeValueAsBytes(wordCount);
} catch (Exception exception) {
wordCountBytes = exception.getMessage().getBytes();
}
return PulsarMessage.builder(wordCountBytes).build();
}
})
.build();
wc.sinkTo(sink);
env.execute("Pulsar Streaming WordCount");
}
}
验证
在 TDMQ Pulsar 版控制台创建流入 Topic NinjaWordCountInput1 和流出 Topic NinjaWordCountOutput1。
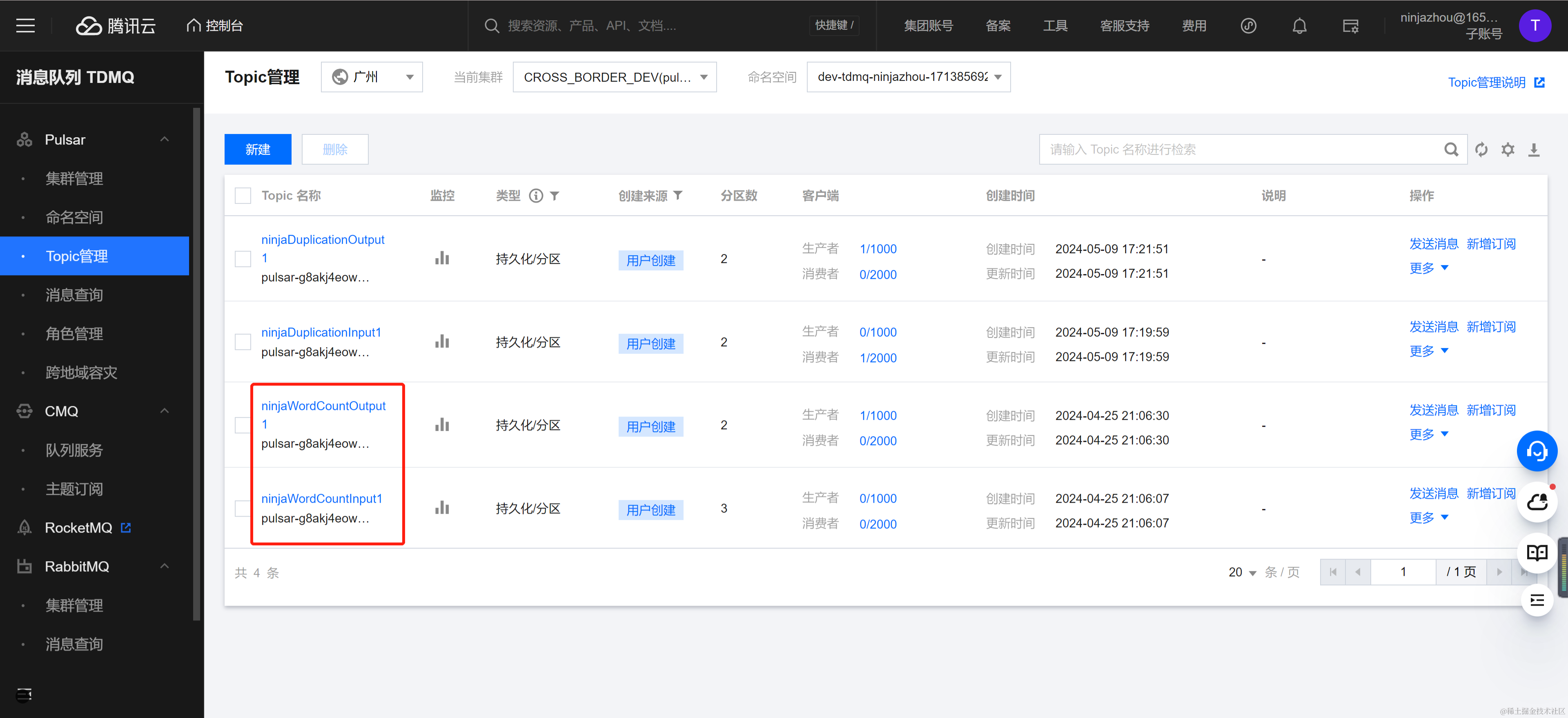
代码编译为 Jar 包后,本地上传 Jar 包到 Flink Docker,从角色管理界面获取具有生产和消费角色的 Token,命令如下所示。
/usr/local/services/flink/flink-1.17.2 # /usr/local/services/flink/flink-1.17.2/bin/flink run /tmp/wordCount/pulsar-flink-examples-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
--broker-service-url http://pulsar-xxxx \
--input-topic pulsar-g8akj4eow8z8/dev-tdmq-ninjazhou-1713856927/ninjaWordCountInput1 \
--output-topic pulsar-g8akj4eow8z8/dev-tdmq-ninjazhou-1713856927/ninjaWordCountOutput1 \
--subscription-name ninjaTest3 \
--token eyJrZXlJZCI6InB1bHNhci1nOGFrajRlb3c4ejgiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJwdWxzYXItZzhha2o0ZW93OHo4X2Rldi10ZG1xLW5pbmphemhvdS0xNzEzODU2OTI3LWRldmNsb3VkIn0.O89TuTl0PMca7tLN9aGvHvqt7QZ9yMrJh1z3VOz7EVc
Job has been submitted with JobID 6f608d95506f96c3eac012386f840655
提交任务后,可以看到 Flink Dashboard 出现对应任务,并且状态处于 Running。
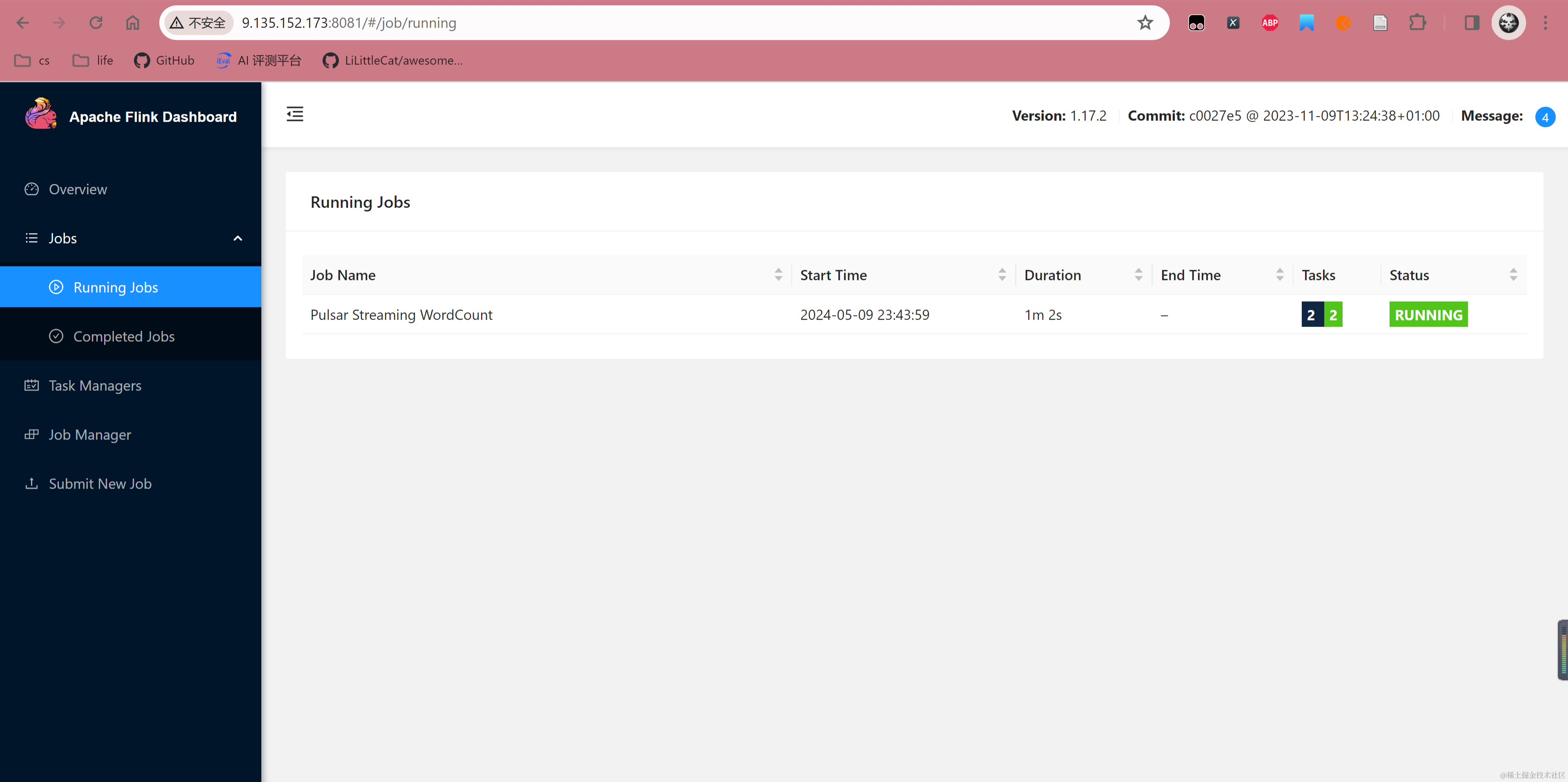
在命令行往 NinjaWordCountInput1 Topic 发送消息,此处一共发送两批消息,第一批发送 i am the bone of my sword 5 次,第二批发送 Test1 3 次。
/usr/local/services/pulsar/apache-pulsar-2.9.5/bin/pulsar-client \
--url http://pulsar-xxx \
--auth-params token:eyJrZXlJZCI6InB1bHNhci1nOGFrajRlb3c4ejgiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJwdWxzYXItZzhha2o0ZW93OHo4X2Rldi10ZG1xLW5pbmphemhvdS0xNzEzODU2OTI3LWRldmNsb3VkIn0.O89TuTl0PMca7tLN9aGvHvqt7QZ9yMrJh1z3VOz7EVc \
--auth-plugin org.apache.pulsar.client.impl.auth.AuthenticationToken \
produce \
-m "i am the bone of my sword" \
-n 5 \
pulsar-g8akj4eow8z8/dev-tdmq-ninjazhou-1713856927/ninjaWordCountInput1
/usr/local/services/pulsar/apache-pulsar-2.9.5/bin/pulsar-client \
--url http://pulsar-g8akj4eow8z8.sap-8ywks40k.tdmq.ap-gz.qcloud.tencenttdmq.com:8080 \
--auth-params token:eyJrZXlJZCI6InB1bHNhci1nOGFrajRlb3c4ejgiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJwdWxzYXItZzhha2o0ZW93OHo4X2Rldi10ZG1xLW5pbmphemhvdS0xNzEzODU2OTI3LWRldmNsb3VkIn0.O89TuTl0PMca7tLN9aGvHvqt7QZ9yMrJh1z3VOz7EVc \
--auth-plugin org.apache.pulsar.client.impl.auth.AuthenticationToken \
produce \
-m "test1" \
-n 3 \
pulsar-g8akj4eow8z8/dev-tdmq-ninjazhou-1713856927/ninjaWordCountInput1
消息发送完成后,可以在消息查询控制台观察到目标 Topic NinjaWordCountOutput1 出现了 8 条消息。
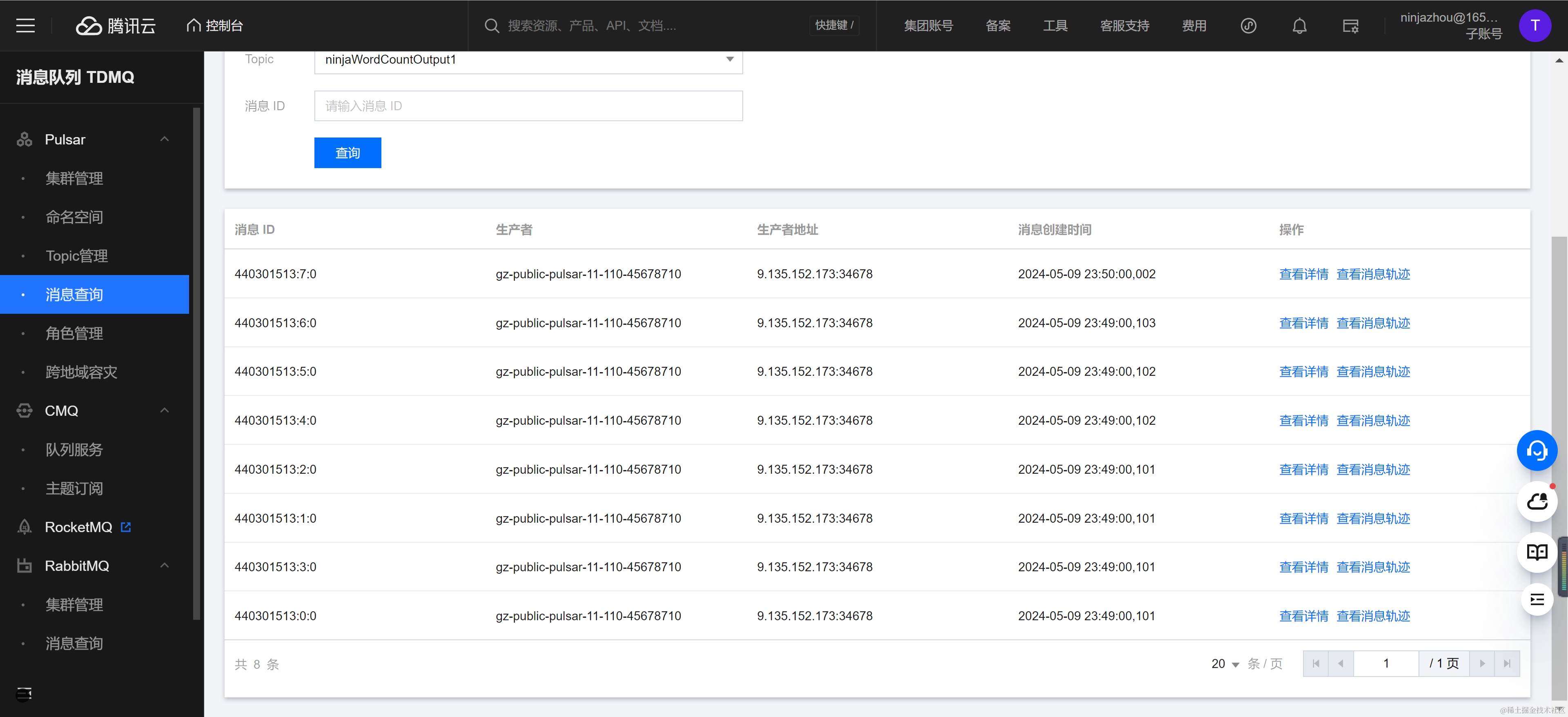
每条消息为单词名称,单词出现的次数,单词处理的时间点的 Json 字节数组,下图为 am 单词的消息结构,可以发现出现数量与投递消息数吻合,证明任务运行正常。
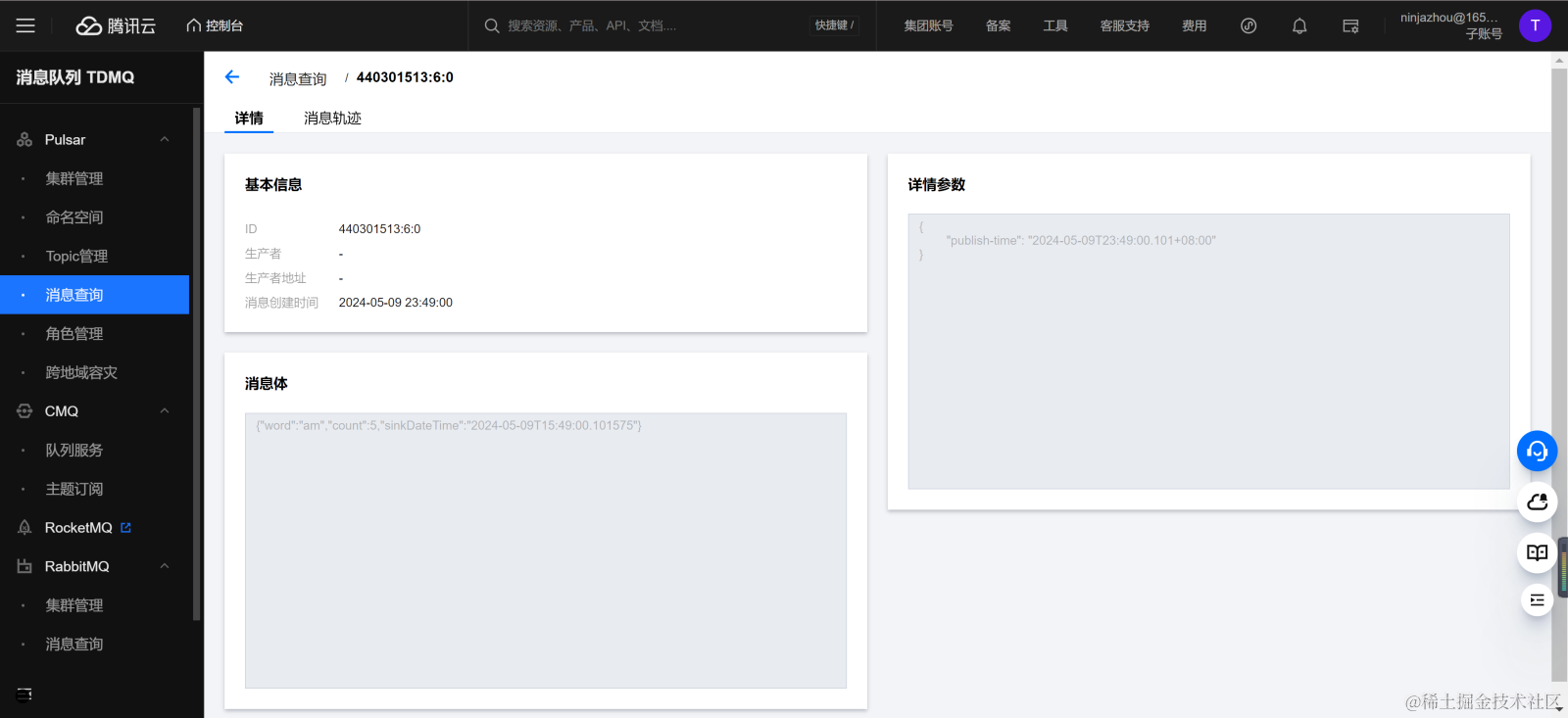
查看 TaskManager 可以看出消息体,以及每次解析的消息过程。
Flink Connector 用法总结
版本选择
目前 Flink 插件生产和消费经过调研,在不进行管控改造以及非标操作的情况下,能满足基本的 TDMQ Pulsar 版使用需求。截至现在 Apache Flink 已经发布 1.20 版本,目前推荐使用 Apache Flink 1.15-1.17 对应 Pulsar Connector,不推荐使用 1.15 以下版本,1.18 及以上版本可以参考 1.17 版本使用。
下面介绍 1.15 和 1.17 版本 Pulsar Flink Connector 主要配置。Flink 版本对应的 Flink Connector 依赖可以在 Pulsar Connector Dependencies 处获取。https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/pulsar/#dependency
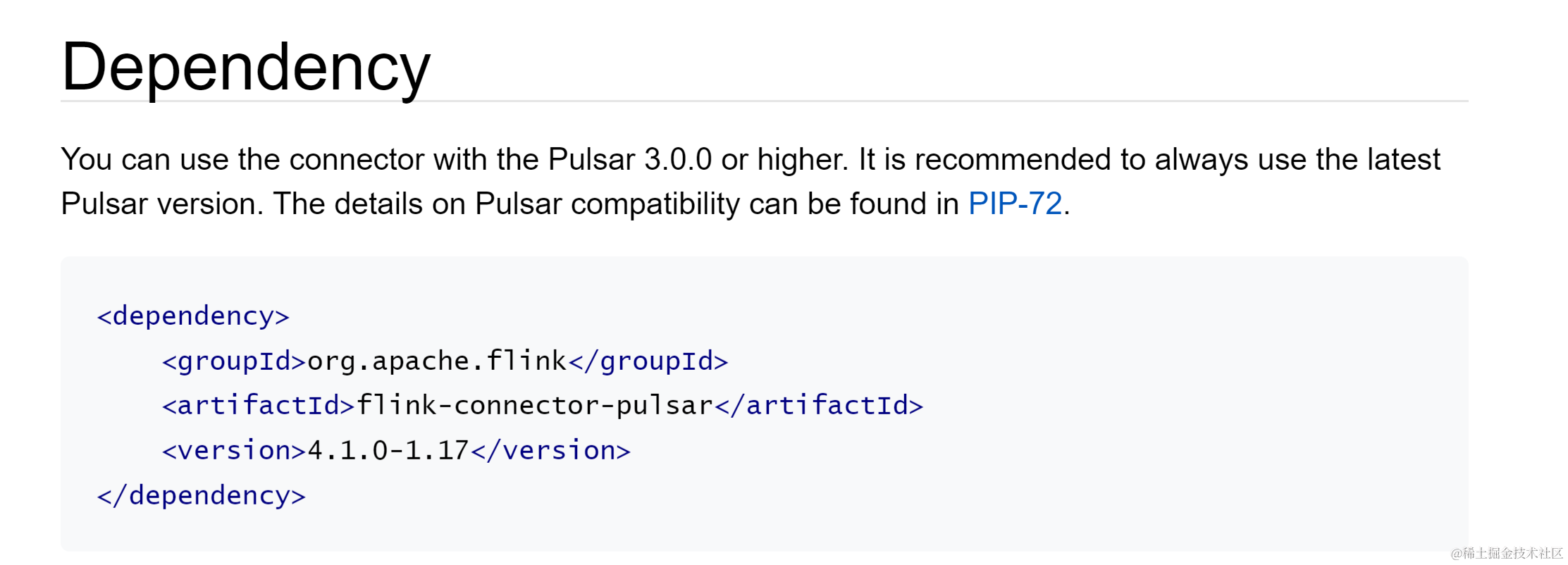
各个版本文档链接: https://nightlies.apache.org/flink/
1.17 Flink Pulsar Connector
代码依赖
Java 项目中引入相关依赖,以 Maven 工程为例,在 pom.xml 添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.17.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-pulsar</artifactId>
<version>4.1.0-1.17</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.2</version>
</dependency>
Source 代码示例
PulsarSource<String> source = PulsarSource.builder()
.setServiceUrl(brokerServiceUrl)
.setStartCursor(StartCursor.latest())
.setTopics(inputTopic)
.setDeserializationSchema(new SimpleStringSchema())
.setSubscriptionName(subscriptionName)
.setAuthentication("org.apache.pulsar.client.impl.auth.AuthenticationToken", token)
.build();
Source 参数说明
Connector Source 全部参数可参考 官方文档 ,下表是常用配置参数。
参数名称描述setServiceUrlTDMQ Pulsar 版接入地址,例如 http://pulsar-xxx:8080setStartCursor任务起始 topic 位点,目前支持 earliest,latest,消息 id 以及消息时间位点四种配置。需要注意如果任务对应订阅已经存在,则会优先直接使用订阅位点setTopicstopic 名称,例如 pulsar-xxxxx/dev-tdmq-ninjazhou-1713856927/ninjaWordCountInput1setDeserializationSchema反序列化消息schema,此处建议使用 Flink 内置的字符串反序列化器 SimpleStringSchema,或者使用 Pulsar 的字符串反序列化器 StringSchema,将消息转换成字符串后,再在业务代码中将字符串转换成自定义的对象setSubscriptionName订阅名称setAuthentication鉴权类,目前 tdmq pulsar 统一使用 jwt token 方式鉴权,因此此处固定填写为 setAuthentication(“org.apache.pulsar.client.impl.auth.AuthenticationToken”, )。token 填写 TDMQ 控制台角色秘钥,需要保证秘钥拥有对应 topic 消费权限
sink 代码示例
PulsarSink<String> sink = PulsarSink.builder()
.setServiceUrl(brokerServiceUrl)
.setTopics(outputTopic)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setAuthentication("org.apache.pulsar.client.impl.auth.AuthenticationToken", token)
.setSerializationSchema(new SimpleStringSchema())
.build();
Sink 参数说明
Connector Sink 全部参数可参考 官方文档 ,下表是常用配置参数。
参数名称描述setServiceUrlTDMQ Pulsar 版接入地址,例如 http://pulsar-xxx:8080setTopicstopic 名称,例如 pulsar-xxxx/dev-tdmq-ninjazhou-1713856927/ninjaWordCountOutput1setSerializationSchema序列化器,将变量序列化为字节数组。推荐自定义实现序列化参数接口,见下文注意事项setDeliveryGuarantee传输可靠性保证,官方可选参数为 NONE,AT_LEAST_ONCE,EXACTLY_ONCE。由于 EXACTLY_ONCE 需要事务保证,此处只建议填写 AT_LEAST_ONCE,NONEsetAuthentication鉴权类,目前 TDMQ Pulsar 版统一使用 jwt token 方式鉴权,因此此处固定填写为 setAuthentication(“org.apache.pulsar.client.impl.auth.AuthenticationToken”, )。token 填写 TDMQ 控制台角色秘钥,需要保证秘钥拥有对应 topic 生产权限
1.15 flink pulsar connector
代码依赖
Java 项目中引入相关依赖,以 Maven 工程为例,在 pom.xml 添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.15.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-pulsar</artifactId>
<version>1.15.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.15.4</version>
</dependency>
Source 代码示例
PulsarSource<String> source = PulsarSource.builder()
.setServiceUrl(brokerServiceUrl)
.setAdminUrl(brokerServiceUrl)
.setStartCursor(StartCursor.latest())
.setTopics(inputTopic)
.setDeserializationSchema(PulsarDeserializationSchema.flinkSchema(new SimpleStringSchema()))
.setSubscriptionName(subscriptionName)
.setSubscriptionType(SubscriptionType.Exclusive)
.setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME, "org.apache.pulsar.client.impl.auth.AuthenticationToken")
.setConfig(PulsarOptions.PULSAR_AUTH_PARAMS, token)
.setConfig(PulsarSourceOptions.PULSAR_ENABLE_AUTO_ACKNOWLEDGE_MESSAGE, true)
.build();
Source 参数说明
connector source 全部参数可参考 官方文档 ,下表是常用配置参数。
参数名称描述setServiceUrlTDMQ Pulsar 版接入地址,例如 http://pulsar-xxxxx:8080setStartCursor任务起始 topic 位点,目前支持 earliest,latest,消息 id 以及消息时间位点四种配置。需要注意如果任务对应订阅已经存在,则会优先直接使用订阅位点setTopicstopic 名称,例如 pulsar-xxxx/ninjaWordCountInput1setDeserializationSchema反序列化消息 schema,此处建议使用 Flink 内置的字符串反序列化器 SimpleStringSchema,或者使用 Pulsar 的字符串反序列化器 StringSchema,将消息转换成字符串后,再在业务代码中将字符串转换成自定义的对象setSubscriptionName订阅名称setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME)鉴权类,目前 TDMQ Pulsar 版统一使用 jwt token 方式鉴权,因此此处固定填写为 setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME,“org.apache.pulsar.client.impl.auth.AuthenticationToken”)setConfig(PulsarOptions.PULSAR_AUTH_PARAMS)鉴权值,目前TDMQ Pulsar 版 统一使用 jwt token 方式鉴权,因此此处固定填写为 setConfig(PulsarOptions.PULSAR_AUTH_PARAMS, ),token 填写 tdmq 控制台角色秘钥,需要保证秘钥拥有对应 topic 消费权限setAdminUrl管控接入点地址,低版本 connector 需要使用此参数执行创建事务,修改 cursor 位点等管控操作,此处传入地址与 setServiceUrl 中相同setSubscriptionType低版本 connector 需要指定订阅类型,而高版本默认使用 Exclusive 模式创建订阅。由于 shared 模式依赖事务 ack 消息,并且 pulsar connector 在初始化时已经会将分区 topic 的每个分区都创建 flink 分片,此时使用 shared 模式意义不大,因此在高版本中已经把 shared 模式去除。具体可以参考 [FLINK-30413] Drop Shared and Key_Shared subscription support in Pulsar connector - ASF JIRA 此处只推荐 Exclusive 或 Failover 订阅模式setConfig(PulsarSourceOptions.PULSAR_ENABLE_AUTO_ACKNOWLEDGE_MESSAGE)如果不开启该参数,插件会依赖事务提交 ack 信息,否则在 Exclusive 和 Failover 订阅模式下会按照 autoCommitCursorInterval 设置的时间间隔自动 ack 拉取的消息,这里需要设置为 setConfig(PulsarSourceOptions.PULSAR_ENABLE_AUTO_ACKNOWLEDGE_MESSAGE, true)
Sink 代码示例
PulsarSink<String> sink = PulsarSink.builder()
.setServiceUrl(brokerServiceUrl)
.setAdminUrl(brokerServiceUrl)
.setTopics(outputTopic)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME, "org.apache.pulsar.client.impl.auth.AuthenticationToken")
.setConfig(PulsarOptions.PULSAR_AUTH_PARAMS, token)
.setSerializationSchema(PulsarSerializationSchema.flinkSchema(new SimpleStringSchema()))
.build();
Sink 参数说明
Connector Sink 全部参数可参考 官方文档 ,下表是常用配置参数。
参数名称描述setServiceUrlTDMQ Pulsar 版接入地址,例如 http://pulsar-xxxx:8080setTopicstopic 名称,例如 pulsar-xxxx/dev-tdmq-ninjazhou-1713856927/ninjaWordCountOutput1setSerializationSchema序列化器,将变量序列化为字节数组。推荐自定义实现序列化参数接口,见下文注意事项setDeliveryGuarantee传输可靠性保证,官方可选参数为 NONE,AT_LEAST_ONCE,EXACTLY_ONCE。由于 EXACTLY_ONCE 需要事务保证,此处只建议填写 AT_LEAST_ONCE,NONEsetAdminUrl管控接入点地址,低版本 connector 需要使用此参数执行创建事务,修改 cursor 位点等管控操作,此处传入地址与 setServiceUrl 中相同setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME)鉴权类,目前 TDMQ Pulsar 版统一使用 jwt token 方式鉴权,因此此处固定填写为 setConfig(PulsarOptions.PULSAR_AUTH_PLUGIN_CLASS_NAME,“org.apache.pulsar.client.impl.auth.AuthenticationToken”)setConfig(PulsarOptions.PULSAR_AUTH_PARAMS)鉴权值,目前 TDMQ Pulsar 版统一使用 jwt token 方式鉴权,因此此处固定填写为 setConfig(PulsarOptions.PULSAR_AUTH_PARAMS, ),token 填写 TDMQ 控制台角色秘钥,需要保证秘钥拥有对应 topic 生产权限
注意事项
由于 Connector Pulsar 会使用到堆外内存,并且默认任务的堆外内存为 0,因此执行 Pulsar Job 需要显式声明堆外内存大小 taskmanager.memory.task.off-heap.size,例如 1gb。
SetSerializationSchema 反序列化提供了两种已经实现的方法,一种是使用 Pulsar 内置 Schema,另一种是使用 Flink 的 Schema。但这两种方法都会造成业务代码与 Schema 耦合。目前建议实现 PulsarSerializationSchema 接口,主要需要实现 Serialize(IN element, PulsarSinkContext sinkContext) 方法,将传入的 IN 对象自定义序列化为 Byte 数组。
目前 Sink 默认开启 Enable_batch 批量投递模式,会将消息打包后投递。如果想要关闭批量投递功能,可以配置 SetConfig(PulsarSinkOptions.PULSAR_BATCHING_ENABLED, False)。
Flink 时间窗口支持两种 时间获取方式 ,一种直接使用任务的系统时间 ProcessTime,另一种是事件自带时间 EventTime。但目前 Source 只支持解析消息 Payload 中的内容,将 Payload 中的内容解析成 Pulsar Schema 对象或者自定义的 Class 对象,而无法解析 Message 中 Properties 中的其他属性,例如 消息上传时间 Publish_time。如果需要解析 message 中的 Properties,根据文档 需要在继承类中 实现 PulsarDeserializationSchema.getProducedType() 方法。这个方法实现较为繁琐,需要声明每个反序列化后的属性,因此目前建议直接使用 ProcessTime 作为时间窗口时间。
1.16 及以下版本 Flink Source 的 SetSubscriptionType 方法还保留了 Shared 和 Key_shared 订阅模式,这两种订阅模式依赖事务 ACK 消息,并且只有当任务 checkpoint 更新时才会统一提交事务和 ACK。但由于目前 TDMQ Pulsar 没有开放事务功能,因此当前不能同时配置 SetSubscriptionType(SubscriptionType.Shared) 和 SetConfig(PulsarSourceOptions.PULSAR_ENABLE_AUTO_ACKNOWLEDGE_MESSAGE, False) 参数。
Oceanus 内置 Pulsar Connector 是基于 StreamNative 版本,适配 flink 1.13-1.14 版本的 connector,这两个版本较老,与新版本存在较多 API 不兼容,如果使用 Oceanus 内置版本 Pulsar Connector 与高版本 Flink,可能需要较多代码改造。
版权归原作者 腾讯云中间件 所有, 如有侵权,请联系我们删除。