
UidGenerator是什么
UidGenerator是百度开源的一款分布式高性能的唯一ID生成器,更详细的情况可以查看官网集成文档
uid-generator是基于Twitter开源的snowflake算法实现的一款唯一主键生成器(数据库表的主键要求全局唯一是相当重要的)。要求java8及以上版本。
snowflake算法
Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。
将long的64位分为3部分,时间戳、工作机器id和序列号,位数分配如下:
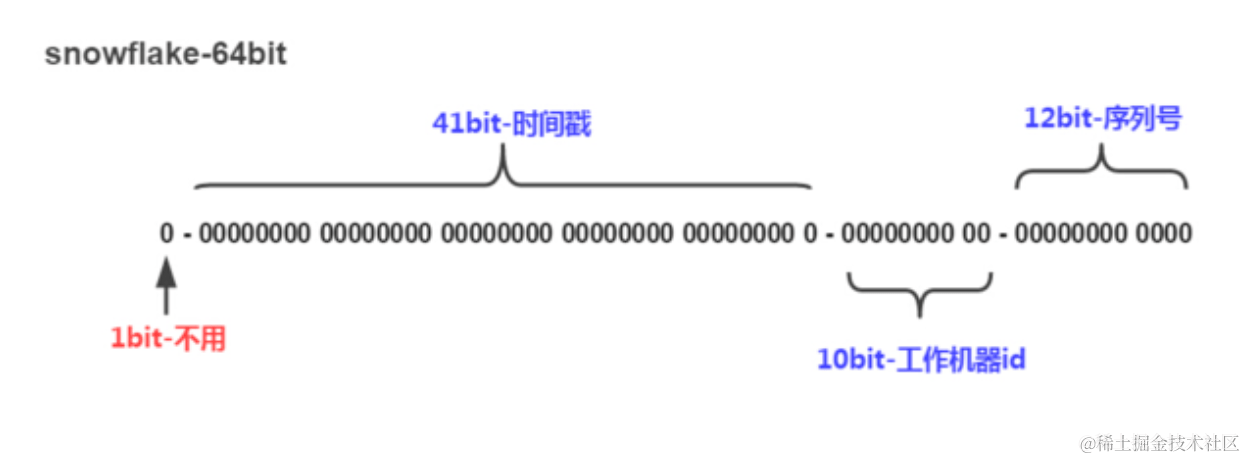
时间戳部分的时间单位一般为毫秒,也就是说1台工作机器1毫秒可产生4096个id(2的12次方)。
UidGenerator算法
与原始的snowflake算法不同,uid-generator支持自定义时间戳、工作机器id和序列号等各部分的位数,以应用于不同场景。

- sign(1bit):固定1bit符号标识,即生成的UID为正数。
- delta seconds (28 bits):当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年
- worker id (22 bits):机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
- sequence (13 bits):每秒下的并发序列,13 bits可支持每秒8192个并发。
这些字段的长度可以根据具体的应用需要进行动态的调整,满足总长度为64位即可。
Snowflake和UidGenerator的对比
百度的worker id的生成策略和美团的生成策略不太一样,美团的snowflake主要利用本地配置的port和IP来唯一确定一个workid,美团的这种生成方式还是可以由于手工配置错误造成port重复,最终产生重复ID的风险,百度的这种生成方式每次都是新增的,可能会一段时间后worker id用完的情况,人工配置错误的可能性很小了。
源码分析
DefaultUidGenerator
DefaultUidGenerator的产生id的方法与基本上就是常见的snowflake算法实现,仅有一些不同,如以秒为为单位而不是毫秒。DefaultUidGenerator的产生id的方法如下。
protectedsynchronizedlongnextId(){long currentSecond =getCurrentSecond();if(currentSecond < lastSecond){long refusedSeconds = lastSecond - currentSecond;thrownewUidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds);}if(currentSecond == lastSecond){
sequence =(sequence +1)& bitsAllocator.getMaxSequence();if(sequence ==0){
currentSecond =getNextSecond(lastSecond);}}else{
sequence =0L;}
lastSecond = currentSecond;return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence);}
nextId方法主要负责ID的生成,这种实现方式很简单,如果毫秒数未发生变化,在序列号加一即可,毫秒数发生变化,重置Sequence为0(Leaf文章中讲过,重置为0会造成如果利用这个ID分表的时候,并发量不大的时候,sequence字段会一直为0等,会出现数据倾斜)
CachedUidGenerator
CachedUidGenerator支持缓存生成的id。
- 【采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费】
- 【UidGenerator通过借用未来时间来解决sequence天然存在的并发限制】
基本实现原理
正如名字体现的那样,这是一种缓存型的ID生成方式,当剩余ID不足的时候,会异步的方式重新生成一批ID缓存起来,后续请求的时候直接的时候直接返回现成的ID即可。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
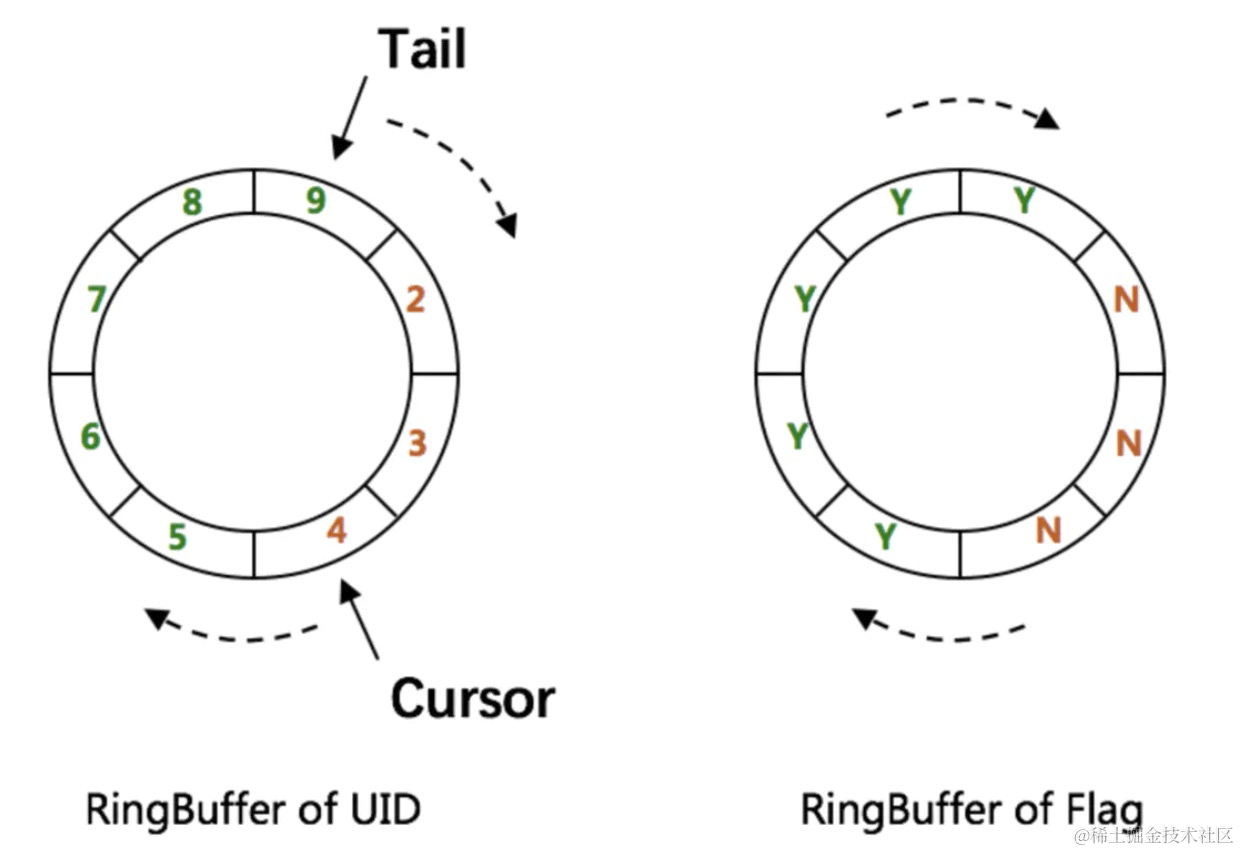
使用RingBuffer缓存生成的id。RingBuffer是个环形数组,默认大小为8192个,里面缓存着生成的id。
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
获取id
会从ringbuffer中拿一个id,支持并发获取
publiclonggetUID(){try{return ringBuffer.take();}catch(Exception e){LOGGER.error("Generate unique id exception. ", e);thrownewUidGenerateException(e);}}
RingBuffer缓存已生成的id
RingBuffer为环形数组,默认容量为sequence可容纳的最大值(8192个),可以通过boostPower参数设置大小。几个重要的数据结构,采用了RingBuffer的方式来缓存相关UID信息。
tail指针、Cursor指针用于环形数组上读写slot:
Tail指针
指向当前最后一个可用的UID位置:表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy
Cursor指针
指向下一个获取UID的位置,其一定是小于Tail:表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
Tail - Cursor表示的是现在可用的UID数量,当可用UID数量小于一定阈值的时候会重新添加一批新的UID在RingBuffer中。
填充id
- RingBuffer填充时机 - 程序启动时,将RingBuffer填充满,缓存着8192个id- 在调用getUID()获取id时,检测到RingBuffer中的剩余id个数小于总个数的50%,将RingBuffer填充满,使其缓存8192个id。- 定时填充(可配置是否使用以及定时任务的周期)
因为delta seconds部分是以秒为单位的,所以1个worker 1秒内最多生成的id书为8192个(2的13次方)。从上可知,支持的最大qps为8192,所以通过缓存id来提高吞吐量。
为什么叫借助未来时间?
因为每秒最多生成8192个id,当1秒获取id数多于8192时,RingBuffer中的id很快消耗完毕,在填充RingBuffer时,生成的id的delta seconds 部分只能使用未来的时间。(因为使用了未来的时间来生成id,所以上面说的是,【最多】可支持约8.7年)
注意:这里的RingBuffer不是Disruptor框架中的RingBuffer,但是借助了很多Disruptor中RingBuffer的设计思想,比如使用缓存行填充解决伪共享问题。
填充RingBuffer
publicvoidpaddingBuffer(){LOGGER.info("Ready to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);if(!running.compareAndSet(false,true)){LOGGER.info("Padding buffer is still running. {}", ringBuffer);return;}boolean isFullRingBuffer =false;while(!isFullRingBuffer){List uidList = uidProvider.provide(lastSecond.incrementAndGet());for(Long uid : uidList){
isFullRingBuffer =!ringBuffer.put(uid);if(isFullRingBuffer){break;}}}
running.compareAndSet(true,false);LOGGER.info("End to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);}
生成id(上面代码中的uidProvider.provide调用的就是这个方法)
protectedListnextIdsForOneSecond(long currentSecond){int listSize =(int) bitsAllocator.getMaxSequence()+1;List uidList =newArrayList<>(listSize);long firstSeqUid = bitsAllocator.allocate(currentSecond - epochSeconds, workerId,0L);for(int offset =0; offset < listSize; offset++){
uidList.add(firstSeqUid + offset);}return uidList;}
RingBuffer的代码
publicclassRingBuffer{privatestaticfinalLoggerLOGGER=LoggerFactory.getLogger(RingBuffer.class);privatestaticfinalintSTART_POINT=-1;privatestaticfinallongCAN_PUT_FLAG=0L;privatestaticfinallongCAN_TAKE_FLAG=1L;publicstaticfinalintDEFAULT_PADDING_PERCENT=50;privatefinalint bufferSize;privatefinallong indexMask;privatefinallong[] slots;privatefinalPaddedAtomicLong[] flags;privatefinalAtomicLong tail =newPaddedAtomicLong(START_POINT);privatefinalAtomicLong cursor =newPaddedAtomicLong(START_POINT);privatefinalint paddingThreshold;privateRejectedPutBufferHandler rejectedPutHandler =this::discardPutBuffer;privateRejectedTakeBufferHandler rejectedTakeHandler =this::exceptionRejectedTakeBuffer;privateBufferPaddingExecutor bufferPaddingExecutor;
代码层面的优化
代码中通过字节的填充,来避免伪共享的产生。
多核处理器处理相互独立的变量时,一旦这些变量处于同一个缓存行,不同变量的操作均会造成这一个缓存行失效,影响缓存的实际效果,造成很大的缓存失效的性能问题。下面图中线程处理不同的两个变量,但这两个变量的修改都会造成整个整个缓存行的失效,导致无效的加载、失效,出现了伪共享的问题
RingBuffer中通过定义一个PaddedAtomicLong来独占一个缓存行,代码中的实现填充可能需要根据具体的执行系统做一些调整,保证其独占一个缓存行即可。
take先关id的源码
下面我们来看下如何获取相关的UID
publiclongtake(){long currentCursor = cursor.get();long nextCursor = cursor.updateAndGet(old -> old == tail.get()? old : old +1);Assert.isTrue(nextCursor >= currentCursor,"Curosr can't move back");long currentTail = tail.get();if(currentTail - nextCursor < paddingThreshold){LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail,
nextCursor, currentTail - nextCursor);
bufferPaddingExecutor.asyncPadding();}if(nextCursor == currentCursor){
rejectedTakeHandler.rejectTakeBuffer(this);}int nextCursorIndex =calSlotIndex(nextCursor);Assert.isTrue(flags[nextCursorIndex].get()==CAN_TAKE_FLAG,"Curosr not in can take status");long uid = slots[nextCursorIndex];
flags[nextCursorIndex].set(CAN_PUT_FLAG);return uid;}
通过AtomicLong.updateAndGet来避免对整个方法进行加锁,获取一个可以访问的UID的游标值,根据这个下标获取slots中相关的uid直接返回 缓存中可用的uid(Tail - Cursor)小于一定阈值的时候,需要启动另外一个线程来生成一批UID UID 的生成
public synchronized boolean put(long uid) { long currentTail = tail.get(); long currentCursor = cursor.get();
long distance = currentTail -(currentCursor == START_POINT ?0: currentCursor);if(distance == bufferSize -1){
rejectedPutHandler.rejectPutBuffer(this, uid);returnfalse;}
int nextTailIndex =calSlotIndex(currentTail +1);if(flags[nextTailIndex].get()!= CAN_PUT_FLAG){
rejectedPutHandler.rejectPutBuffer(this, uid);returnfalse;}
slots[nextTailIndex]= uid;
flags[nextTailIndex].set(CAN_TAKE_FLAG);
tail.incrementAndGet();returntrue;}
获取Tail的下标值,如果缓存区满的话直接调用RejectedPutHandler.rejectPutBuffer方法 未满的话将UID放置在slots数组相应的位置上,同时将Flags数组相应的位置改为CAN_TAKE_FLAG CachedUidGenerator通过缓存的方式预先生成一批UID列表,可以解决UID获取时候的耗时,但这种方式也有不好点,一方面需要耗费内存来缓存这部分数据,另外如果访问量不大的情况下,提前生成的UID中的时间戳可能是很早之前的,DefaultUidGenerator应该在大部分的场景中就可以满足相关的需求了。
填充缓存行解决"伪共享"
关于伪共享,可以参考这篇文章《伪共享(false sharing),并发编程无声的性能杀手》
privatefinalPaddedAtomicLong[] flags;privatefinalAtomicLong tail =newPaddedAtomicLong(START_POINT);privatefinalAtomicLong cursor =newPaddedAtomicLong(START_POINT)
PaddedAtomicLong的设计
publicclassPaddedAtomicLongextendsAtomicLong{privatestaticfinallong serialVersionUID =-3415778863941386253L;publicvolatilelong p1, p2, p3, p4, p5, p6 =7L;publicPaddedAtomicLong(){super();}publicPaddedAtomicLong(long initialValue){super(initialValue);}publiclongsumPaddingToPreventOptimization(){return p1 + p2 + p3 + p4 + p5 + p6;}}
Spring Boot工程集成全局唯一ID生成器 UidGenerator
基础工程创建
官网集成文档
创建数据表
执行如下SQL
DROPTABLEIFEXISTS WORKER_NODE;CREATETABLE WORKER_NODE
(
ID BIGINTNOTNULLAUTO_INCREMENTCOMMENT'auto increment id',
HOST_NAME VARCHAR(64)NOTNULLCOMMENT'host name',
PORT VARCHAR(64)NOTNULLCOMMENT'port',TYPEINTNOTNULLCOMMENT'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATENOTNULLCOMMENT'launch date',
MODIFIED TIMESTAMPNOTNULLCOMMENT'modified time',
CREATED TIMESTAMPNOTNULLCOMMENT'created time',PRIMARYKEY(ID))COMMENT='DB WorkerID Assigner for UID Generator',ENGINE=INNODB;
在使用的数据库中创建表WORKER_NODE。(如果数据库版本较低,需要将TIMESTAMP类型换成datetime(3),一劳永逸的做法就是直接将TIMESTAMP换成datetime(3))
引入Maven依赖
<dependencies><dependency><groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency><groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.0version>
dependency>
<dependency><groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency><groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
<version>8.0.12version>
dependency>
<dependency><groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.9version>
dependency>
<dependency><groupId>com.baidu.fsggroupId>
<artifactId>uid-generatorartifactId>
<version>1.0.0-SNAPSHOTversion>
dependency>
dependencies>
互联网jar包引入(本文用的是此方式)
在maven仓库只找到了一个jar包。
<dependency><groupId>com.xfvape.uidgroupId>
<artifactId>uid-generatorartifactId>
<version>0.0.4-RELEASEversion>
dependency>
排除冲突的依赖
uid-generator中依赖了logback和mybatis。一般在项目搭建过程中,springboot中已经有了logback依赖,mybatis会作为单独的依赖引入。如果版本和uid-generator中的依赖不一致的话,就会导致冲突。为了防止出现这些问题,直接排除一劳永逸。
<dependency><groupId>com.baidu.fsggroupId>
<artifactId>uid-generatorartifactId>
<version>1.0.0-SNAPSHOTversion>
<exclusions><exclusion><groupId>org.mybatisgroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
排除冲突的依赖如下:(使用本地项目引入的方式也需要排除以下依赖)
<dependency><groupId>com.xfvape.uidgroupId>
<artifactId>uid-generatorartifactId>
<version>0.0.4-RELEASEversion>
<exclusions><exclusion><groupId>org.mybatisgroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
我这里用的是mybatis-plus,mybatis-plus官方要求的是,如果要使用mybatis-plus,就不能再单独引入mybatis了,所以我这里也是必须排除mybatis的。
配置SpringBoot核心配置
修改配置文件application.properties(注意MySQL地址、数据库名称账户等于之前建表的保持一致)
server.port=9999
spring.datasource.url=jdbc:mysql://*.*.*.*:3306/baiduUidGenerator?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=*
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.configuration.map-underscore-to-camel-case=true
@MapperScan的dao层接口扫描:
核心对象装配为spring的bean。
uid-generator提供了两种生成器: DefaultUidGenerator、CachedUidGenerator。
如对UID生成性能有要求, 请使用CachedUidGenerator。这里装配CachedUidGenerator,DefaultUidGenerator装配方式是一样的。
自定义DisposableWorkerIdAssigner
将源码DisposableWorkerIdAssigner类加入到自己的项目中,并将其中的mapper方法修改成自己项目中的方法与启动类同级目录新建DisposableWorkerIdAssigner内容如下
publicclassDisposableWorkerIdAssignerimplementsWorkerIdAssigner{privatestaticfinalLoggerLOGGER=LoggerFactory.getLogger(DisposableWorkerIdAssigner.class);privateWorkerNodeMapper workerNodeMapper;publiclongassignWorkerId(){WorkerNodeEntity workerNodeEntity =buildWorkerNode();
workerNodeMapper.addWorkerNode(workerNodeEntity);LOGGER.info("Add worker node:"+ workerNodeEntity);return workerNodeEntity.getId();}privateWorkerNodeEntitybuildWorkerNode(){WorkerNodeEntity workerNodeEntity =newWorkerNodeEntity();if(DockerUtils.isDocker()){
workerNodeEntity.setType(WorkerNodeType.CONTAINER.value());
workerNodeEntity.setHostName(DockerUtils.getDockerHost());
workerNodeEntity.setPort(DockerUtils.getDockerPort());}else{
workerNodeEntity.setType(WorkerNodeType.ACTUAL.value());
workerNodeEntity.setHostName(NetUtils.getLocalAddress());
workerNodeEntity.setPort(System.currentTimeMillis()+"-"+RandomUtils.nextInt(100000));}return workerNodeEntity;}}
publicclassUidGeneratorConfig{publicDisposableWorkerIdAssignerdisposableWorkerIdAssigner(){DisposableWorkerIdAssigner disposableWorkerIdAssigner =newDisposableWorkerIdAssigner();return disposableWorkerIdAssigner;}publicCachedUidGeneratorinitCachedUidGenerator(WorkerIdAssigner workerIdAssigner){CachedUidGenerator cachedUidGenerator =newCachedUidGenerator();
cachedUidGenerator.setWorkerIdAssigner(workerIdAssigner);
cachedUidGenerator.setBoostPower(3);
cachedUidGenerator.setPaddingFactor(50);
cachedUidGenerator.setScheduleInterval(60L);return cachedUidGenerator;}}
详细配置信息控制
publicDefaultUidGeneratordefaultUidGenerator(WorkerIdAssigner disposableWorkerIdAssigner){DefaultUidGenerator defaultUidGenerator =newDefaultUidGenerator();
defaultUidGenerator.setWorkerIdAssigner(disposableWorkerIdAssigner);
defaultUidGenerator.setTimeBits(32);
defaultUidGenerator.setWorkerBits(22);
defaultUidGenerator.setSeqBits(9);
defaultUidGenerator.setEpochStr("2020-01-01");return defaultUidGenerator;}publicCachedUidGeneratorcachedUidGenerator(WorkerIdAssigner disposableWorkerIdAssigner){CachedUidGenerator cachedUidGenerator =newCachedUidGenerator();
cachedUidGenerator.setWorkerIdAssigner(disposableWorkerIdAssigner);
cachedUidGenerator.setTimeBits(32);
cachedUidGenerator.setWorkerBits(22);
cachedUidGenerator.setSeqBits(9);
cachedUidGenerator.setEpochStr("2020-01-01");
cachedUidGenerator.setBoostPower(3);
cachedUidGenerator.setScheduleInterval(60L);return cachedUidGenerator;}
mapper服务接口
与启动类同级目录新建WorkerNodeMapper内容如下
publicinterfaceWorkerNodeMapper{WorkerNodeEntitygetWorkerNodeByHostPort(String host,String port);voidaddWorkerNode(WorkerNodeEntity workerNodeEntity);}
WorkerNodeMapper
<mappernamespace="org.zxp.uidgeneratortest.WorkerNodeMapper"><resultMapid="workerNodeRes"type="com.baidu.fsg.uid.worker.entity.WorkerNodeEntity"><idcolumn="ID"jdbcType="BIGINT"property="id"/><resultcolumn="HOST_NAME"jdbcType="VARCHAR"property="hostName"/><resultcolumn="PORT"jdbcType="VARCHAR"property="port"/><resultcolumn="TYPE"jdbcType="INTEGER"property="type"/><resultcolumn="LAUNCH_DATE"jdbcType="DATE"property="launchDate"/><resultcolumn="MODIFIED"jdbcType="TIMESTAMP"property="modified"/><resultcolumn="CREATED"jdbcType="TIMESTAMP"property="created"/>
resultMap>
<insertid="addWorkerNode"useGeneratedKeys="true"keyProperty="id"parameterType="com.baidu.fsg.uid.worker.entity.WorkerNodeEntity">
INSERT INTO WORKER_NODE
(HOST_NAME,
PORT,
TYPE,
LAUNCH_DATE,
MODIFIED,
CREATED)
VALUES (
#{hostName},
#{port},
#{type},
#{launchDate},
NOW(),
NOW())
insert>
<selectid="getWorkerNodeByHostPort"resultMap="workerNodeRes">
SELECT
ID,
HOST_NAME,
PORT,
TYPE,
LAUNCH_DATE,
MODIFIED,
CREATED
FROM
WORKER_NODE
WHERE
HOST_NAME = #{host} AND PORT = #{port}
select>
mapper>
创建UidGenService逻辑类
publicclassUidGenService{privateUidGenerator uidGenerator;publiclonggetUid(){return uidGenerator.getUID();}}
分享资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Yf1KiFl-1692670384862)(https://pic.imgdb.cn/item/64d0dc6a1ddac507cc857b30.png)]
获取以上资源请访问开源项目 点击跳转
版权归原作者 夏壹-10分分享 所有, 如有侵权,请联系我们删除。